







原文:
annas-archive.org/md5/ddd311fd2802b8b875714761e8af3c7e译者:飞龙
前言
深度学习是机器学习的一个子集,基于多层神经网络,能够解决自然语言处理、图像分类等领域中的特别难以处理的大规模问题。本书讲解了技术和分析部分的复杂性,以及如何在 Apache Spark 上实现深度学习解决方案的速度。
本书从解释 Apache Spark 和深度学习的基本原理开始(如何为深度学习设置 Spark、分布式建模的原则以及不同类型的神经网络)。然后,讲解在 Spark 上实现一些深度学习模型,如 CNN、RNN 和 LSTM。读者将通过实践体验所需的步骤,并对所面临的复杂性有一个总体的了解。在本书的过程中,将使用流行的深度学习框架,如 DeepLearning4J(主要)、Keras 和 TensorFlow,来实现和训练分布式模型。
本书的使命如下:
-
创建一本关于实现可扩展、高效的 Scala(在某些情况下也包括 Python)深度学习解决方案的实践指南
-
通过多个代码示例让读者对使用 Spark 感到自信
-
解释如何选择最适合特定深度学习问题或场景的模型
本书的目标读者
如果你是 Scala 开发人员、数据科学家或数据分析师,想要学习如何使用 Spark 实现高效的深度学习模型,那么这本书适合你。了解核心机器学习概念并具备一定的 Spark 使用经验将有所帮助。
本书内容
第一章,Apache Spark 生态系统,提供了 Apache Spark 各模块及其不同部署模式的全面概述。
第二章,深度学习基础,介绍了深度学习的基本概念。
第三章,提取、转换、加载,介绍了 DL4J 框架,并展示了来自多种来源的训练数据 ETL 示例。
第四章,流式处理,展示了使用 Spark 和 DL4J DataVec 进行数据流处理的示例。
第五章,卷积神经网络,深入探讨了 CNN 的理论及通过 DL4J 实现模型。
第六章,循环神经网络,深入探讨了 RNN 的理论及通过 DL4J 实现模型。
第七章,在 Spark 中训练神经网络,解释了如何使用 DL4J 和 Spark 训练 CNN 和 RNN。
第八章,监控和调试神经网络训练,讲解了 DL4J 提供的在训练时监控和调整神经网络的功能。
第九章,解释神经网络输出,介绍了一些评估模型准确性的技术。
第十章,在分布式系统上部署,讲解了在配置 Spark 集群时需要考虑的一些事项,以及在 DL4J 中导入和运行预训练 Python 模型的可能性。
第十一章,NLP 基础,介绍了自然语言处理(NLP)的核心概念。
第十二章,文本分析与深度学习,涵盖了通过 DL4J、Keras 和 TensorFlow 进行 NLP 实现的一些示例。
第十三章,卷积,讨论了卷积和物体识别策略。
第十四章,图像分类,深入讲解了一个端到端图像分类 Web 应用程序的实现。
第十五章,深度学习的未来,尝试概述未来深度学习的前景。
为了最大程度地利用本书
本书的实践部分需要具备 Scala 编程语言的基础知识。具备机器学习的基本知识也有助于更好地理解深度学习的理论。对于 Apache Spark 的初步知识或经验并不是必要的,因为第一章涵盖了关于 Spark 生态系统的所有内容。只有在理解可以在 DL4J 中导入的 Keras 和 TensorFlow 模型时,需要对 Python 有较好的了解。
为了构建和执行本书中的代码示例,需要 Scala 2.11.x、Java 8、Apache Maven 和你选择的 IDE。
下载示例代码文件
你可以通过你的账户在www.packt.com下载本书的示例代码文件。如果你在其他地方购买了本书,你可以访问www.packt.com/support并注册,代码文件将通过邮件直接发送给你。
你可以通过以下步骤下载代码文件:
-
在www.packt.com登录或注册。
-
选择“支持”标签。
-
点击“代码下载与勘误”。
-
在搜索框中输入书名,并按照屏幕上的指示操作。
下载文件后,请确保使用最新版本的以下工具解压或提取文件:
-
WinRAR/7-Zip for Windows
-
Zipeg/iZip/UnRarX for Mac
-
7-Zip/PeaZip for Linux
本书的代码包也托管在 GitHub 上,网址为github.com/PacktPublishing/Hands-On-Deep-Learning-with-Apache-Spark。如果代码有更新,将会在现有的 GitHub 仓库中进行更新。
我们还有来自丰富书籍和视频目录的其他代码包,您可以访问 github.com/PacktPublishing/。快去看看吧!
下载彩色图片
我们还提供了一个 PDF 文件,其中包含本书中使用的截图/图表的彩色版本。您可以在此下载:www.packtpub.com/sites/default/files/downloads/9781788994613_ColorImages.pdf。
使用的约定
本书中使用了许多文本约定。
CodeInText:表示文本中的代码单词、数据库表名、文件夹名、文件名、文件扩展名、路径名、虚拟网址、用户输入和 Twitter 账号。示例如下:“将下载的 WebStorm-10*.dmg 磁盘镜像文件挂载为系统中的另一个磁盘。”
一段代码的设置如下:
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.master(master)
.getOrCreate()
当我们希望引起您对某一代码块中特定部分的注意时,相关的行或项会以粗体显示:
-------------------------------------------
Time: 1527457655000 ms
-------------------------------------------
(consumer,1)
(Yet,1)
(another,1)
(message,2)
(for,1)
(the,1)
任何命令行输入或输出如下所示:
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
粗体:表示一个新术语、重要单词或您在屏幕上看到的词汇。例如,菜单或对话框中的单词会像这样出现在文本中。示例如下:“从管理面板中选择系统信息。”
警告或重要提示以这种方式出现。
提示和技巧以这种方式出现。
与我们联系
我们欢迎读者的反馈。
一般反馈:如果您对本书的任何方面有疑问,请在您的邮件主题中注明书名,并通过customercare@packtpub.com联系我们。
勘误:虽然我们已经尽力确保内容的准确性,但错误还是会发生。如果您在本书中发现错误,我们将不胜感激,恳请您向我们报告。请访问 www.packt.com/submit-errata,选择您的书籍,点击“勘误提交表单”链接,并填写相关信息。
盗版:如果您在互联网上遇到任何非法的我们作品的复制品,无论其形式如何,我们将不胜感激,若您能提供具体位置或网站名称。请通过copyright@packt.com与我们联系,并附上相关链接。
如果您有兴趣成为作者:如果您在某个领域有专长并且有兴趣撰写或贡献一本书,请访问 authors.packtpub.com。
评论
请留下评论。阅读并使用本书后,为什么不在您购买书籍的网站上留下评价呢?潜在读者可以看到并利用您的公正意见来做出购买决策,Packt 可以了解您对我们产品的看法,作者也能看到您对他们书籍的反馈。谢谢!
如需了解更多关于 Packt 的信息,请访问 packt.com。
第一章:Apache Spark 生态系统
Apache Spark (spark.apache.org/) 是一个开源的快速集群计算平台。最初由加利福尼亚大学伯克利分校的 AMPLab 创建,后来其源代码被捐赠给了 Apache 软件基金会 (www.apache.org/)。Spark 因其计算速度非常快而广受欢迎,因为数据被加载到分布式内存(RAM)中,分布在集群中的各台机器上。数据不仅可以快速转换,还可以根据需要进行缓存,适用于多种用例。与 Hadoop MapReduce 相比,当数据能够放入内存时,Spark 的程序运行速度快达 100 倍,或者在磁盘上快 10 倍。Spark 支持四种编程语言:Java、Scala、Python 和 R。本书仅涵盖 Scala (www.scala-lang.org/) 和 Python (www.python.org/) 的 Spark API(以及深度学习框架)。
本章将涵盖以下主题:
-
Apache Spark 基础知识
-
获取 Spark
-
Resilient Distributed Dataset(RDD)编程
-
Spark SQL、Datasets 和 DataFrames
-
Spark Streaming
-
使用不同管理器的集群模式
Apache Spark 基础知识
本节将介绍 Apache Spark 的基础知识。在进入下一个章节之前,熟悉这里呈现的概念非常重要,因为后续我们将探索可用的 API。
如本章导言所述,Spark 引擎在集群节点的分布式内存中处理数据。以下图表显示了一个典型 Spark 作业处理信息的逻辑结构:
图 1.1
Spark 以以下方式执行作业:
图 1.2
Master控制数据的分区方式,并利用数据局部性,同时跟踪所有在Slave机器上的分布式数据计算。如果某台 Slave 机器不可用,该机器上的数据会在其他可用机器上重新构建。在独立模式下,Master 是单点故障。章节中关于使用不同管理器的集群模式部分涵盖了可能的运行模式,并解释了 Spark 中的容错机制。
Spark 包含五个主要组件:
图 1.3
这些组件如下:
-
核心引擎。
-
Spark SQL:结构化数据处理模块。
-
Spark Streaming:这是对核心 Spark API 的扩展。它允许实时数据流处理。其优势包括可扩展性、高吞吐量和容错性。
-
MLib:Spark 机器学习库。
-
GraphX:图形和图并行计算算法。
Spark 可以访问存储在不同系统中的数据,如 HDFS、Cassandra、MongoDB、关系型数据库,还可以访问如 Amazon S3 和 Azure Data Lake Storage 等云存储服务。
获取 Spark
现在,让我们动手实践 Spark,以便深入了解核心 API 和库。在本书的所有章节中,我将引用 Spark 2.2.1 版本,然而,这里展示的多个示例应适用于 2.0 版本及更高版本。我会在示例仅适用于 2.2+ 版本时做出说明。
首先,你需要从官方网站下载 Spark(spark.apache.org/downloads.html)。下载页面应该是这样的:
图 1.4
你需要安装 JDK 1.8+ 和 Python 2.7+ 或 3.4+(如果你需要使用这些语言进行开发)。Spark 2.2.1 支持 Scala 2.11。JDK 需要在你的用户路径系统变量中存在,或者你可以设置用户的 JAVA_HOME 环境变量指向 JDK 安装目录。
将下载的压缩包内容解压到任何本地目录。然后,进入 $SPARK_HOME/bin 目录。在那里,你会找到 Scala 和 Python 的交互式 Spark shell。它们是熟悉这个框架的最佳方式。在本章中,我将展示你可以通过这些 shell 运行的示例。
你可以使用以下命令运行一个 Scala shell:
$SPARK_HOME/bin/spark-shell.sh
如果没有指定参数,Spark 会假设你在本地以独立模式运行。以下是控制台的预期输出:
Spark context Web UI available at http://10.72.0.2:4040
Spark context available as 'sc' (master = local[*], app id = local-1518131682342).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Web 用户界面可以通过以下 URL 访问:http://<host>:4040。
它将给你以下输出:
图 1.5
在这里,你可以查看作业和执行器的状态。
从控制台启动的输出中,你会注意到有两个内建变量,sc和spark是可用的。sc表示SparkContext(spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.SparkContext),在 Spark < 2.0 中,这是每个应用的入口点。通过 Spark 上下文(及其专用版本),你可以从数据源获取输入数据,创建和操作 RDD(spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RDD),并获取 2.0 之前 Spark 的主要抽象。RDD 编程部分将详细介绍这一主题和其他操作。从 2.0 版本开始,引入了一个新的入口点SparkSession(spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.SparkSession),以及一个新的主数据抽象——Dataset(spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset)。后续章节将介绍更多细节。SparkContext仍然是 Spark API 的一部分,确保与不支持 Spark 会话的现有框架兼容,但项目的方向是将开发重点转向使用SparkSession。
这是一个如何读取和操作文本文件,并使用 Spark shell 将其放入 Dataset 的例子(该例子使用的文件是 Spark 分发包中示例资源的一部分):
scala> spark.read.textFile("/usr/spark-2.2.1/examples/src/main/resources/people.txt")
res5: org.apache.spark.sql.Dataset[String] = [value: string]
结果是一个包含文件行的 Dataset 实例。你可以对这个 Dataset 进行多种操作,比如统计行数:
scala> res5.count()
res6: Long = 3
你还可以获取 Dataset 的第一行:
scala> res5.first()
res7: String = Michael, 29
在这个例子中,我们使用了本地文件系统中的路径。在这种情况下,所有工作节点都应该能从相同路径访问该文件,因此你需要将文件复制到所有工作节点,或者使用一个网络挂载的共享文件系统。
要关闭一个 shell,你可以输入以下命令:
:quit
要查看所有可用的 shell 命令列表,输入以下命令:
scala> :help
所有命令都可以缩写,例如,使用:he代替:help。
以下是命令列表:
| 命令 | 目的 |
|---|---|
:edit <id>|<line> | 编辑历史记录 |
:help [command] | 打印总结或命令特定的帮助 |
:history [num] | 显示历史记录(可选的num是要显示的命令数量) |
:h? <string> | 搜索历史记录 |
:imports [name name ...] | 显示导入历史,标识名称的来源 |
:implicits [-v] | 显示作用域中的implicits |
:javap <path|class> | 反汇编文件或类名 |
:line <id>|<line> | 将行放置在历史记录的末尾 |
:load <path> | 解释文件中的行 |
:paste [-raw] [path] | 进入粘贴模式或粘贴文件 |
:power | 启用高级用户模式 |
:quit | 退出解释器 |
:replay [options] | 重置repl和所有先前命令上的replay |
:require <path> | 将jar添加到类路径 |
:reset [options] | 将repl重置为初始状态,忘记所有会话条目 |
:save <path> | 将可重放会话保存到文件中 |
:sh <command line> | 运行 Shell 命令(结果为implicitly => List[String]) |
:settings <options> | 更新编译器选项,如果可能的话;参见reset |
:silent | 禁用或启用自动打印结果 |
:type [-v] <expr> | 显示表达式的类型而不评估它 |
:kind [-v] <expr> | 显示表达式的种类 |
:warnings | 显示最近一行的抑制警告 |
与 Scala 一样,Python 也有交互式 shell。您可以使用以下命令运行它:
$SPARK_HOME/bin/pyspark.sh
内置变量名为spark,代表SparkSession可用。您可以像 Scala shell 一样做同样的事情:
>>> textFileDf = spark.read.text("/usr/spark-2.2.1/examples/src/main/resources/people.txt")
>>> textFileDf.count()
3
>>> textFileDf.first()
Row(value='Michael, 29')
与 Java 和 Scala 不同,Python 更加动态,且类型不是强制的。因此,在 Python 中,DataSet是DataSet[Row],但您可以称之为 DataFrame,以便与 Pandas 框架的 DataFrame 概念保持一致(pandas.pydata.org/)。
要关闭 Python shell,您可以输入以下内容:
quit()
在 Spark 中运行代码的选择不仅限于交互式 shell。也可以实现独立的应用程序。以下是在 Scala 中读取和操作文件的示例:
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val logFile = "/usr/spark-2.2.1/examples/src/main/resources/people.txt"
val spark = SparkSession.builder.master("local").appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}
应用程序应该定义一个main()方法,而不是扩展scala.App。注意创建SparkSession的代码:
val spark = SparkSession.builder.master("local").appName("Simple Application").getOrCreate()
它遵循生成器工厂设计模式。
在结束程序执行之前,始终显式关闭会话:
spark.stop()
要构建应用程序,您可以使用您选择的构建工具(Maven、sbt或Gradle),添加来自 Spark 2.2.1 和 Scala 2.11 的依赖项。生成 JAR 文件后,您可以使用$SPARK_HOME/bin/spark-submit命令执行它,指定 JAR 文件名、Spark 主 URL 和一系列可选参数,包括作业名称、主类、每个执行器使用的最大内存等。
同样的独立应用也可以在 Python 中实现:
from pyspark.sql import SparkSession
logFile = "YOUR_SPARK_HOME/README.md" # Should be some file on your system
spark = SparkSession.builder().appName(appName).master(master).getOrCreate()
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
spark.stop()
这可以保存在.py文件中,并通过相同的$SPARK_HOME/bin/spark-submit命令提交以执行。
RDD 编程
通常,每个 Spark 应用程序是一个驱动程序,运行为其实现的逻辑并在集群上执行并行操作。根据前面的定义,核心 Spark 框架提供的主要抽象是 RDD。它是一个不可变的分布式数据集合,数据在集群中的机器上进行分区。对 RDD 的操作可以并行执行。
对 RDD 有两种类型的操作:
-
转换
-
行动
转换(transformation)是对 RDD 的操作,产生另一个 RDD,而 行动(action)则是触发某些计算的操作,并将结果返回给主节点,或将结果持久化到存储系统中。转换是惰性执行的——直到调用行动才会执行。这里就是 Spark 的强大之处——Spark 的主节点和驱动程序都记住了已经应用于 RDD 的转换操作,因此如果一个分区丢失(例如,一个从节点宕机),它可以很容易地在集群的其他节点上重新构建。 |
以下表格列出了 Spark 支持的常见转换:
| 转换 | 目的 |
|---|---|
map(func) | 通过对源 RDD 的每个数据元素应用 func 函数,返回一个新的 RDD。 |
filter(func) | 通过选择那些 func 函数返回 true 的数据元素,返回一个新的 RDD。 |
flatMap(func) | 这个转换类似于 map:不同之处在于,每个输入项可以映射到零个或多个输出项(应用的 func 函数应该返回一个 Seq)。 |
union(otherRdd) | 返回一个新的 RDD,包含源 RDD 和 otherRdd 参数中元素的并集。 |
distinct([numPartitions]) | 返回一个新的 RDD,仅包含源 RDD 中的唯一元素。 |
groupByKey([numPartitions]) | 当对一个包含 (K, V) 对的 RDD 调用时,它返回一个 (K, Iterable) 对的 RDD。默认情况下,输出 RDD 的并行度取决于源 RDD 的分区数。你可以传递一个可选的 numPartitions 参数来设置不同的分区数。 |
reduceByKey(func, [numPartitions]) | 当对一个包含 (K, V) 对的 RDD 调用时,它返回一个 (K, V) 对的 RDD,其中每个键的值通过给定的 func 函数进行聚合,该函数的类型必须为 (V, V) => V。与 groupByKey 转换相同,reduce 操作的分区数可以通过可选的 numPartitions 第二个参数进行配置。 |
sortByKey([ascending], [numPartitions]) | 当对一个包含 (K, V) 对的 RDD 调用时,它返回一个按键排序的 (K, V) 对的 RDD,排序顺序根据布尔值 ascending 参数来指定(升序或降序)。输出 RDD 的分区数量可以通过可选的 numPartitions 第二个参数进行配置。 |
join(otherRdd, [numPartitions]) | 当应用于类型为 (K, V) 和 (K, W) 的 RDD 时,它返回一个 (K, (V, W)) 对的 RDD,为每个键提供所有元素对。它支持左外连接、右外连接和全外连接。输出 RDD 的分区数量可以通过可选的 numPartitions 参数进行配置。 |
以下表格列出了 Spark 支持的一些常见操作:
| 操作 | 目的 |
|---|---|
reduce(func) | 使用给定函数 func 聚合 RDD 的元素(此函数接受两个参数并返回一个结果)。为了确保计算时的正确并行性,reduce 函数 func 必须是交换律和结合律成立的。 |
collect() | 返回 RDD 中所有元素作为一个数组传递给驱动程序。 |
count() | 返回 RDD 中元素的总数。 |
first() | 返回 RDD 中的第一个元素。 |
take(n) | 返回一个包含 RDD 中前 n 个元素的数组。 |
foreach(func) | 对 RDD 中的每个元素执行 func 函数。 |
saveAsTextFile(path) | 将 RDD 的元素以文本文件的形式写入指定目录(通过 path 参数指定绝对路径),支持本地文件系统、HDFS 或其他 Hadoop 支持的文件系统。此功能仅适用于 Scala 和 Java。 |
countByKey() | 这个操作仅适用于类型为 (K, V) 的 RDD——它返回一个 (K, Int) 对的哈希映射,其中 K 是源 RDD 的键,值是该键 K 的计数。 |
现在,让我们通过一个示例理解转换和操作的概念,该示例可以在 Scala shell 中执行——它找到输入文本文件中最常用的 N 个单词。以下图示展示了这一问题的潜在实现:
图 1.6
让我们将其转换为代码。
首先,让我们将文本文件的内容加载到一个字符串类型的 RDD 中:
scala> val spiderman = sc.textFile("/usr/spark-2.2.1/tests/spiderman.txt")
spiderman: org.apache.spark.rdd.RDD[String] = /usr/spark-2.2.1/tests/spiderman.txt MapPartitionsRDD[1] at textFile at <console>:24
然后,我们将应用必要的转换和操作:
scala> val topWordCount = spiderman.flatMap(str=>str.split(" ")).filter(!_.isEmpty).map(word=>(word,1)).reduceByKey(_+_).map{case(word, count) => (count, word)}.sortByKey(false)
topWordCount: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[9] at sortByKey at <console>:26
这里,我们有以下内容:
-
flatMap(str=>str.split(" ")): 将每一行拆分为单个单词 -
filter(!_.isEmpty): 移除空字符串 -
map(word=>(word,1)): 将每个单词映射为键值对 -
reduceByKey(_+_): 聚合计数 -
map{case(word, count) => (count, word)}: 反转(word, count)对为(count, word) -
sortByKey(false): 按降序排序
最后,将输入内容中使用频率最高的五个单词打印到控制台:
scala> topWordCount.take(5).foreach(x=>println(x))
(34,the)
(28,and)
(19,of)
(19,in)
(16,Spider-Man)
相同的功能也可以在 Python 中通过以下方式实现:
from operator import add
spiderman = spark.read.text("/usr/spark-2.2.1/tests/spiderman.txt")
lines = spiderman.rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add) \
.map(lambda x: (x[1],x[0])) \
.sortByKey(False)
结果当然与 Scala 示例相同:
>> counts.take(5)
[(34, 'the'), (28, 'and'), (19, 'in'), (19, 'of'), (16, 'Spider-Man')]
Spark 可以在执行操作时将 RDD(以及数据集)持久化到内存中。在 Spark 中,持久化和缓存是同义词。持久化 RDD 时,集群中的每个节点会将需要计算的 RDD 分区存储在内存中,并在对相同的 RDD(或通过一些转换从其派生的 RDD)进行进一步操作时重用这些分区。这就是为什么后续操作执行得更快的原因。可以通过调用 RDD 的 persist() 方法来标记一个 RDD 进行持久化。当第一次对它执行操作时,它会被保存在集群节点的内存中。Spark 缓存是容错的——这意味着,如果由于某种原因丢失了 RDD 的所有分区,它将通过创建它的转换重新计算这些分区。持久化的 RDD 可以使用不同的存储级别来存储。可以通过将一个 StorageLevel 对象传递给 RDD 的 persist() 方法来设置级别。以下表格列出了所有可用的存储级别及其含义:
| 存储级别 | 用途 |
|---|---|
MEMORY_ONLY | 这是默认的存储级别。它将 RDD 存储为反序列化的 Java 对象在内存中。在 RDD 无法完全放入内存的情况下,一些分区不会被缓存,需要时会动态重新计算。 |
MEMORY_AND_DISK | 它首先将 RDD 存储为反序列化的 Java 对象在内存中,但当 RDD 无法完全放入内存时,它会将部分分区存储在磁盘上(这是与 MEMORY_ONLY 之间的主要区别),并在需要时从磁盘中读取。 |
MEMORY_ONLY_SER | 它将 RDD 存储为序列化的 Java 对象。与 MEMORY_ONLY 相比,这种方式更节省空间,但在读取操作时 CPU 占用更高。仅适用于 JVM 语言。 |
MEMORY_AND_DISK_SER | 类似于 MEMORY_ONLY_SER(将 RDD 存储为序列化的 Java 对象),主要区别在于,对于无法完全放入内存的分区,它将其存储到磁盘中。仅适用于 JVM 语言。 |
DISK_ONLY | 仅将 RDD 分区存储在磁盘中。 |
MEMORY_ONLY_2、MEMORY_AND_DISK_2 等 | 与前两种级别(MEMORY_ONLY 和 MEMORY_AND_DISK)相同,但每个分区会在两个集群节点上复制。 |
OFF_HEAP | 类似于 MEMORY_ONLY_SER,但它将数据存储在堆外内存中(假设启用了堆外内存)。使用此存储级别时需要小心,因为它仍处于实验阶段。 |
当一个函数被传递给 Spark 操作时,它会在远程集群节点上执行,该节点将处理函数中使用的所有变量的单独副本。执行完成后,这些变量将被复制到每台机器上。当变量传回驱动程序时,远程机器上的变量不会被更新。支持跨任务的一般读写共享变量是低效的。
然而,在 Spark 中有两种有限类型的共享变量可供使用,适用于两种常见的使用模式——广播变量和累加器。
Spark 编程中最常见的操作之一是对 RDD 执行连接操作,根据给定的键整合数据。在这些情况下,可能会有大量的数据集被发送到执行分区的从属节点进行连接。可以很容易地理解,这种情况会导致巨大的性能瓶颈,因为网络 I/O 的速度比内存访问慢 100 倍。为了解决这个问题,Spark 提供了广播变量,可以将其广播到从属节点。节点上的 RDD 操作可以快速访问广播变量的值。Spark 还尝试使用高效的广播算法来分发广播变量,以减少通信开销。广播变量是通过调用SparkContext.broadcast(v)方法从变量v创建的。广播变量是v的一个封装,其值可以通过调用value方法获取。以下是一个可以通过 Spark shell 运行的 Scala 示例:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
在创建后,广播变量broadcastVar可以在集群中执行的任何函数中使用,但初始值v除外,因为这可以防止v被多次发送到所有节点。为了确保所有节点都能获得相同的广播变量值,v在broadcastVar广播后不能被修改。
下面是相同示例的 Python 代码:
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>
>>> broadcastVar.value
[1, 2, 3]
为了在 Spark 集群的执行器之间聚合信息,应该使用accumulator变量。由于它们通过一个结合性和交换性的操作进行添加,因此可以有效支持并行计算。Spark 本地支持数值类型的累加器——可以通过调用SparkContext.longAccumulator()(用于累加Long类型的值)或SparkContext.doubleAccumulator()(用于累加Double类型的值)方法来创建它们。
然而,也可以通过编程方式为其他类型提供支持。任何在集群上运行的任务都可以使用add方法向累加器添加值,但它们无法读取累加器的值——这个操作只允许驱动程序执行,它可以使用累加器的value方法。以下是 Scala 中的代码示例:
scala> val accum = sc.longAccumulator("First Long Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some
(First Long Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
[Stage 0:> (0 + 0) / 8]
scala> accum.value
res1: Long = 10
在这种情况下,已经创建了一个累加器,并给它分配了一个名称。可以创建没有名称的累加器,但具有名称的累加器将在修改该累加器的阶段的 Web UI 中显示:
图 1.7
这对于理解运行阶段的进度很有帮助。
相同的 Python 示例如下:
>>> accum = sc.accumulator(0)
>>> accum
Accumulator<id=0, value=0>
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
>>> accum.value
10
Python 不支持在 Web UI 中跟踪累加器。
请注意,Spark 仅在action内部更新累加器。当重新启动任务时,累加器只会更新一次。对于transformation,情况则不同。
Spark SQL、Datasets 和 DataFrames
Spark SQL 是用于结构化数据处理的 Spark 模块。这个 API 和 RDD API 的主要区别在于,提供的 Spark SQL 接口可以更好地了解数据和执行计算的结构。这些额外的信息被 Spark 内部利用,通过 Catalyst 优化引擎进行额外的优化,这个执行引擎无论使用哪种 API 或编程语言,都是相同的。
Spark SQL 通常用于执行 SQL 查询(即使这不是唯一的使用方式)。无论使用 Spark 支持的哪种编程语言来封装 SQL 代码,查询的结果都会以Dataset的形式返回。Dataset 是一个分布式数据集合,它作为接口在 Spark 1.6 中被引入。它结合了 RDD 的优势(如强类型和应用有用的 lambda 函数的能力)与 Spark SQL 优化执行引擎(Catalyst,databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html)的优势。你可以通过从 Java/Scala 对象开始并通过常规的函数式转换来操作 Dataset。Dataset API 在 Scala 和 Java 中可用,而 Python 不支持它。然而,由于 Python 语言的动态特性,很多 Dataset API 的优势在 Python 中已经可以使用。
从 Spark 2.0 开始,DataFrame 和 Dataset API 已合并为 Dataset API,因此DataFrame只是一个已经被组织成命名列的 Dataset,在概念上等同于 RDBMS 中的表,但其底层优化更佳(作为 Dataset API 的一部分,Catalyst 优化引擎也在幕后为 DataFrame 工作)。你可以从不同的数据源构建 DataFrame,例如结构化数据文件、Hive 表、数据库表和 RDD 等。与 Dataset API 不同,DataFrame API 可以在任何 Spark 支持的编程语言中使用。
让我们开始动手实践,以便更好地理解 Spark SQL 背后的概念。我将展示的第一个完整示例是基于 Scala 的。启动一个 Scala Spark shell,以交互方式运行以下代码。
让我们使用people.json作为数据源。作为此示例的资源之一,包含在 Spark 分发包中的文件可用于创建一个 DataFrame,这是一个行的 Dataset(spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Row):
val df = spark.read.json("/opt/spark/spark-2.2.1-bin-hadoop2.7/examples/src/main/resources/people.json")
你可以将 DataFrame 的内容打印到控制台,检查它是否符合你的预期:
scala> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
在执行 DataFrame 操作之前,你需要导入隐式转换(例如将 RDD 转换为 DataFrame),并使用$符号:
import spark.implicits._
现在,你可以以树状格式打印 DataFrame 模式:
scala> df.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
选择单一列(例如name):
scala> df.select("name").show()
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
过滤数据:
scala> df.filter($"age" > 27).show()
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
然后添加一个groupBy子句:
scala> df.groupBy("age").count().show()
+----+-----+
| age|count|
+----+-----+
| 19| 1|
|null| 1|
| 30| 1|
+----+-----+
选择所有行并递增一个数字字段:
scala> df.select($"name", $"age" + 1).show()
+-------+---------+
| name|(age + 1)|
+-------+---------+
|Michael| null|
| Andy| 31|
| Justin| 20|
+-------+---------+
你可以通过SparkSession的sql函数以编程方式运行 SQL 查询。该函数返回查询结果的 DataFrame,在 Scala 中是Dataset[Row]。让我们考虑与前面示例相同的 DataFrame:
val df = spark.read.json("/opt/spark/spark-2.2.1-bin-hadoop2.7/examples/src/main/resources/people.json")
你可以将其注册为 SQL 临时视图:
df.createOrReplaceTempView("people")
然后,你可以在此处执行 SQL 查询:
scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> sqlDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
在 Python 中也可以执行相同的操作:
>>> df = spark.read.json("/opt/spark/spark-2.2.1-bin-hadoop2.7/examples/src/main/resources/people.json")
结果如下:
>> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
>>> df.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
>>> df.select("name").show()
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
>>> df.filter(df['age'] > 21).show()
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
>>> df.groupBy("age").count().show()
+----+-----+
| age|count|
+----+-----+
| 19| 1|
|null| 1|
| 30| 1|
+----+-----+
>>> df.select(df['name'], df['age'] + 1).show()
+-------+---------+
| name|(age + 1)|
+-------+---------+
|Michael| null|
| Andy| 31|
| Justin| 20|
+-------+---------+
>>> df.createOrReplaceTempView("people")
>>> sqlDF = spark.sql("SELECT * FROM people")
>>> sqlDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
Spark SQL 和 Datasets 的其他功能(数据源、聚合、自包含应用等)将在第三章中介绍,提取、转换、加载。
Spark Streaming
Spark Streaming 是另一个 Spark 模块,扩展了核心 Spark API,并提供了一种可扩展、容错和高效的方式来处理实时流数据。通过将流数据转换为微批次,Spark 的简单批处理编程模型也可以应用于流式用例中。这个统一的编程模型使得将批处理和交互式数据处理与流式处理相结合变得容易。支持多种数据摄取源(例如 Kafka、Kinesis、TCP 套接字、S3 或 HDFS 等流行源),并且可以使用 Spark 中任何高级函数来处理从这些源获取的数据。最终,处理过的数据可以持久化到关系数据库、NoSQL 数据库、HDFS、对象存储系统等,或通过实时仪表板进行消费。没有什么可以阻止其他高级 Spark 组件(如 MLlib 或 GraphX)应用于数据流:
图 1.8
以下图表展示了 Spark Streaming 的内部工作原理——它接收实时输入数据流并将其划分为批次;这些批次由 Spark 引擎处理,生成最终的批量结果:
图 1.9
Spark Streaming 的高级抽象是DStream(Discretized Stream的简称),它是对连续数据流的封装。从内部来看,DStream 是作为一系列 RDD 的序列来表示的。DStream 包含它依赖的其他 DStream 的列表、将输入 RDD 转换为输出 RDD 的函数,以及调用该函数的时间间隔。DStream 可以通过操作现有的 DStream 来创建,例如应用 map 或 filter 函数(这分别内部创建了MappedDStreams和FilteredDStreams),或者通过从外部源读取数据(在这些情况下,基类是InputDStream)。
让我们实现一个简单的 Scala 示例——一个流式单词计数自包含应用程序。此类所用的代码可以在与 Spark 发行版一起捆绑的示例中找到。要编译和打包它,你需要将 Spark Streaming 的依赖项添加到你的Maven、Gradle或sbt项目描述文件中,还需要添加来自 Spark Core 和 Scala 的依赖项。
首先,我们需要从SparkConf和StreamingContext(它是任何流式功能的主要入口点)开始创建:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
批处理间隔已设置为 1 秒。表示来自 TCP 源的流数据的 DStream 可以通过ssc流上下文创建;我们只需要指定源的主机名和端口,以及所需的存储级别:
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
返回的lines DStream 是将从服务器接收到的数据流。每条记录将是我们希望分割为单个单词的单行文本,从而指定空格字符作为分隔符:
val words = lines.flatMap(_.split(" "))
然后,我们将对这些单词进行计数:
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
words DStream 被映射(一个一对一的转换)为一个(word, 1)对的 DStream,随后通过减少操作得到每批数据中单词的频率。最后的命令会每秒打印生成的计数。DStream 中的每个 RDD 包含来自某个时间间隔的数据——对 DStream 应用的任何操作都转换为对底层 RDD 的操作:
图 1.10
在设置好所有转换后,使用以下代码开始处理:
ssc.start()
ssc.awaitTermination()
在运行此示例之前,首先需要运行netcat(一个在大多数类 Unix 系统中找到的小工具)作为数据服务器:
nc -lk 9999
然后,在另一个终端中,你可以通过传递以下参数来启动示例:
localhost 9999
任何在终端中输入并通过netcat服务器运行的行都会被计数,并且每秒在应用程序屏幕上打印一次。
无论nc是否在运行此示例的系统中不可用,你都可以在 Scala 中实现自己的数据服务器:
import java.io.DataOutputStream
import java.net.{ServerSocket, Socket}
import java.util.Scanner
object SocketWriter {
def main(args: Array[String]) {
val listener = new ServerSocket(9999)
val socket = listener.accept()
val outputStream = new DataOutputStream(socket.getOutputStream())
System.out.println("Start writing data. Enter close when finish");
val sc = new Scanner(System.in)
var str = ""
/**
* Read content from scanner and write to socket.
*/
while (!(str = sc.nextLine()).equals("close")) {
outputStream.writeUTF(str);
}
//close connection now.
outputStream.close()
listener.close()
}
}
相同的自包含应用程序在 Python 中可能如下所示:
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingNetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
DStreams 支持 RDD 大部分可用的转换功能。这意味着输入 DStream 中的数据可以像 RDD 中的数据一样被修改。下表列出了 Spark DStreams 支持的一些常见转换:
| 转换 | 用途 |
|---|---|
map(func) | 返回一个新的 DStream。func映射函数应用于源 DStream 的每个元素。 |
flatMap(func) | 与map相同。唯一的区别是新 DStream 中的每个输入项可以映射到 0 个或多个输出项。 |
filter(func) | 返回一个新的 DStream,只包含源 DStream 中func过滤函数返回 true 的元素。 |
repartition(numPartitions) | 用于通过创建不同数量的分区来设置并行度。 |
union(otherStream) | 返回一个新的 DStream。它包含源 DStream 和输入的 otherDStream DStream 中元素的并集。 |
count() | 返回一个新的 DStream。它包含通过计算每个 RDD 中元素的数量而得到的单一元素 RDD。 |
reduce(func) | 返回一个新的 DStream。它包含通过应用 func 函数(该函数应该是结合性和交换性的,以便支持正确的并行计算)在源中每个 RDD 上聚合得到的单一元素 RDD。 |
countByValue() | 返回一个新的 DStream,包含 (K, Long) 对,其中 K 是源元素的类型。每个键的值表示其在源中每个 RDD 中的频率。 |
reduceByKey(func, [numTasks]) | 返回一个新的 DStream,包含 (K, V) 对(对于源 DStream 中的 (K, V) 对)。每个键的值通过应用 func 函数来进行聚合。为了进行分组,此转换使用 Spark 默认的并行任务数(在本地模式下是 2,而在集群模式下由 config 属性 spark.default.parallelism 确定),但可以通过传递可选的 numTasks 参数来更改此数值。 |
join(otherStream, [numTasks]) | 返回一个新的 DStream,包含 (K, (V, W)) 对,当它分别应用于两个 DStream,其中一个包含 (K, V) 对,另一个包含 (K, W) 对时。 |
cogroup(otherStream, [numTasks]) | 返回一个新的 DStream,包含 (K, Seq[V], Seq[W]) 元组,当它分别应用于两个 DStream,其中一个包含 (K, V) 对,另一个包含 (K, W) 对时。 |
transform(func) | 返回一个新的 DStream。它将 RDD 到 RDD 的 func 函数应用于源中的每个 RDD。 |
updateStateByKey(func) | 返回一个新的状态 DStream。新 DStream 中每个键的状态通过将输入函数 func 应用于先前的状态和该键的新值来更新。 |
窗口计算由 Spark Streaming 提供。如以下图所示,它们允许你在滑动数据窗口上应用转换:
图 1.11
当一个窗口在源 DStream 上滑动时,所有在该窗口内的 RDD 都会被考虑并转换,生成返回的窗口化 DStream 的 RDD。看一下上面图示的具体例子,基于窗口的操作应用于三个时间单位的数据,并且它以两为滑动步长。任何使用的窗口操作都需要指定两个参数:
-
窗口长度:窗口的持续时间
-
滑动间隔:窗口操作执行的间隔时间
这两个参数必须是源 DStream 批次间隔的倍数。
让我们看看这个方法如何应用于本节开始时介绍的应用场景。假设你想要每隔 10 秒钟生成一次过去 60 秒数据的字数统计。需要在过去 60 秒的 DStream 中对(word, 1)对应用 reduceByKey 操作。这可以通过 reduceByKeyAndWindow 操作来实现。转换为 Scala 代码如下:
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(60), Seconds(10))
对于 Python,代码如下:
windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 60, 10)
以下表列出了 Spark 为 DStreams 支持的一些常见窗口操作:
| 转换 | 目的 |
|---|---|
window(windowLength, slideInterval) | 返回一个新的 DStream。它基于源数据的窗口化批次。 |
countByWindow(windowLength, slideInterval) | 返回源 DStream 中元素的滑动窗口计数(基于 windowLength 和 slideInterval 参数)。 |
reduceByWindow(func, windowLength, slideInterval) | 返回一个新的单元素 DStream。它是通过在滑动时间间隔内聚合源 DStream 中的元素,并应用 func 减少函数来创建的(为了支持正确的并行计算,func 必须是结合性和交换性的)。 |
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 返回一个新的由(K, V)对组成的 DStream(与源 DStream 相同的 K 和 V)。每个键的值通过在滑动窗口中对批次(由 windowLength 和 slideInterval 参数定义)应用 func 输入函数来聚合。并行任务的数量在本地模式下为 2(默认),而在集群模式下由 Spark 配置属性 spark.default.parallelism.numTask 给出,这是一个可选参数,用于指定自定义任务数量。 |
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 这是 reduceByKeyAndWindow 转换的一个更高效版本。这次,当前窗口的减少值是通过使用前一个窗口的减少值逐步计算出来的。通过减少进入窗口的新数据,同时对离开窗口的旧数据进行逆减少,来实现这一点。请注意,这种机制只有在 func 函数有相应的逆减少函数 invFunc 时才能工作。 |
countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 返回一个由(K, Long)对组成的 DStream(与源 DStream 组成的(K, V)对相同)。返回的 DStream 中每个键的值是其在给定滑动窗口内的频率(由 windowLength 和 slideInterval 参数定义)。numTask 是一个可选参数,用于指定自定义任务数量。 |
使用不同管理器的集群模式
以下图示展示了 Spark 应用程序在集群上如何运行。它们是由SparkContext对象在Driver Program中协调的独立进程集。SparkContext连接到Cluster Manager,后者负责在各个应用程序之间分配资源。一旦SparkContext连接,Spark 将在集群节点上获取执行器。
执行器是执行计算并存储给定 Spark 应用程序数据的进程。SparkContext将应用程序代码(Scala 的 JAR 文件或 Python 的.py 文件)发送到执行器。最后,它将运行任务发送到执行器:
图 1.12
为了将不同的应用程序彼此隔离,每个 Spark 应用程序都会获得自己的执行进程。这些进程会在整个应用程序的运行期间保持活跃,并以多线程模式运行任务。缺点是无法在不同的 Spark 应用程序之间共享数据——为了共享数据,数据需要持久化到外部存储系统。
Spark 支持不同的集群管理器,但它与底层类型无关。
执行时,驱动程序必须能从工作节点的网络地址访问,因为它必须监听并接受来自执行器的连接请求。由于它负责在集群上调度任务,因此应尽量将其执行在接近工作节点的地方,即在同一个局域网中(如果可能)。
以下是当前在 Spark 中支持的集群管理器:
-
Standalone:一种简单的集群管理器,便于设置集群。它包含在 Spark 中。
-
Apache Mesos:一个开源项目,用于管理计算机集群,开发于加利福尼亚大学伯克利分校。
-
Hadoop YARN:从 Hadoop 2 版本开始提供的资源管理器。
-
Kubernetes:一个开源平台,提供面向容器的基础设施。Spark 中的 Kubernetes 支持仍处于实验阶段,因此可能尚未准备好用于生产环境。
独立模式
对于独立模式,您只需要将编译版本的 Spark 放置在集群的每个节点上。所有集群节点需要能够解析其他集群成员的主机名,并且能够相互路由。Spark 主节点的 URL 可以在所有节点的$SPARK_HOME/conf/spark-defaults.conf文件中进行配置:
spark.master spark://<master_hostname_or_IP>:7077
然后,需要在所有节点的$SPARK_HOME/conf/spark-env.sh文件中指定 Spark 主节点的主机名或 IP 地址,如下所示:
SPARK_MASTER_HOST, <master_hostname_or_IP>
现在,可以通过执行以下脚本启动一个独立的主服务器:
$SPARK_HOME/sbin/start-master.sh
一旦主节点完成,Web UI 将可以通过http://<master_hostname_or_IP>:8080 URL 访问。从这里可以获得用于启动工作节点的主节点 URL。现在可以通过执行以下脚本启动一个或多个工作节点:
$SPARK_HOME/sbin/start-slave.sh <master-spark-URL>
每个工作节点启动后都会有自己的 Web UI,其 URL 为 http://<worker_hostname_or_IP>:8081。
工作节点的列表,以及它们的 CPU 数量和内存等信息,可以在主节点的 Web UI 中找到。
这样做的方法是手动运行独立集群。也可以使用提供的启动脚本。需要创建一个 $SPARK_HOME/conf/slaves 文件作为初步步骤。该文件必须包含所有要启动 Spark 工作节点的机器的主机名,每行一个。在 Spark 主节点与 Spark 从节点之间需要启用无密码SSH(即安全外壳)以允许远程登录,从而启动和停止从节点守护进程。然后,可以使用以下 shell 脚本启动或停止集群,这些脚本位于 $SPARK_HOME/sbin 目录中:
-
start-master.sh:启动一个主节点实例 -
start-slaves.sh:在conf/slaves文件中指定的每台机器上启动一个从节点实例 -
start-slave.sh:启动单个从节点实例 -
start-all.sh:同时启动主节点和多个从节点 -
stop-master.sh:停止通过sbin/start-master.sh脚本启动的主节点 -
stop-slaves.sh:停止conf/slaves文件中指定节点上的所有从节点实例 -
stop-all.sh:停止主节点及其从节点
这些脚本必须在将运行 Spark 主节点的机器上执行。
可以通过以下方式运行一个交互式 Spark shell 对集群进行操作:
$SPARK_HOME/bin/spark-shell --master <master-spark-URL>
可以使用 $SPARK_HOME/bin/spark-submit 脚本将已编译的 Spark 应用程序提交到集群。Spark 当前支持独立集群的两种部署模式:客户端模式和集群模式。在客户端模式下,驱动程序和提交应用程序的客户端在同一进程中启动,而在集群模式下,驱动程序从其中一个工作进程启动,客户端进程在提交应用程序后立即退出(无需等待应用程序完成)。
当通过 spark-submit 启动应用程序时,其 JAR 文件会自动分发到所有工作节点。应用程序依赖的任何附加 JAR 文件应通过 jars 标志指定,并使用逗号作为分隔符(例如,jars, jar1, jar2)。
如在Apache Spark 基础知识一节中提到的,独立模式下,Spark 主节点是单点故障。这意味着如果 Spark 主节点宕机,Spark 集群将停止工作,所有当前提交或正在运行的应用程序将失败,并且无法提交新的应用程序。
可以使用 Apache ZooKeeper (zookeeper.apache.org/) 来配置高可用性,ZooKeeper 是一个开源且高度可靠的分布式协调服务,或者可以通过 Mesos 或 YARN 部署为集群,这部分将在接下来的两节中讨论。
Mesos 集群模式
Spark 可以在由 Apache Mesos(mesos.apache.org/)管理的集群上运行。Mesos 是一个跨平台、云提供商无关、集中式且容错的集群管理器,专为分布式计算环境设计。其主要特性包括资源管理和隔离,以及跨集群的 CPU 和内存调度。它可以将多个物理资源合并为单个虚拟资源,这与传统的虚拟化不同,传统虚拟化将单个物理资源分割为多个虚拟资源。使用 Mesos,可以构建或调度诸如 Apache Spark 之类的集群框架(尽管不仅限于此)。下图展示了 Mesos 的架构:
图 1.13
Mesos 由主守护程序和框架组成。主守护程序管理每个集群节点上运行的代理守护程序,而 Mesos 框架在代理上运行任务。主守护程序通过提供资源来实现对框架的细粒度资源共享(包括 CPU 和 RAM)。它根据给定的组织策略决定向每个框架提供多少可用资源。为了支持各种策略集,主使用模块化架构通过插件机制轻松添加新的分配模块。一个 Mesos 框架由两个组件组成 — 调度程序注册自己以接收主提供的资源,执行程序在代理节点上启动以执行框架的任务。尽管主决定向每个框架提供多少资源,但框架的调度程序负责选择要使用的提供的资源。框架一旦接受提供的资源,就会向 Mesos 传递它想要在这些资源上执行的任务的描述。Mesos 随后在相应的代理上启动这些任务。
使用 Mesos 部署 Spark 集群以取代 Spark Master Manager 的优势包括以下几点:
-
在 Spark 和其他框架之间进行动态分区
-
在多个 Spark 实例之间进行可扩展分区
Spark 2.2.1 设计用于与 Mesos 1.0.0+配合使用。在本节中,我不会描述部署 Mesos 集群的步骤 — 我假设 Mesos 集群已经可用并正在运行。在 Mesos 主节点的 Web UI 上,端口为5050,验证 Mesos 集群准备好运行 Spark:
图 1.14
检查 Agents 标签中是否存在所有预期的机器。
要从 Spark 使用 Mesos,需要在 Mesos 本身可以访问的位置提供 Spark 二进制包,并且需要配置 Spark 驱动程序程序以连接到 Mesos。或者,也可以在所有 Mesos 从节点上安装 Spark,然后配置 spark.mesos.executor.home 属性(默认值为 $SPARK_HOME)以指向该位置。
Mesos 主节点的 URL 形式为 mesos://host:5050,对于单主节点的 Mesos 集群,或者对于使用 Zookeeper 的多主节点 Mesos 集群,形式为 mesos://zk://host1:2181,host2:2181,host3:2181/mesos。
以下是如何在 Mesos 集群上启动 Spark shell 的示例:
$SPARK_HOME/bin/spark-shell --master mesos://127.0.0.1:5050 -c spark.mesos.executor.home=`pwd`
一个 Spark 应用程序可以按以下方式提交到 Mesos 管理的 Spark 集群:
$SPARK_HOME/bin/spark-submit --master mesos://127.0.0.1:5050 --total-executor-cores 2 --executor-memory 3G $SPARK_HOME/examples/src/main/python/pi.py 100
YARN 集群模式
YARN (hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html),它是在 Apache Hadoop 2.0 中引入的,带来了在可扩展性、高可用性和对不同范式的支持方面的显著改进。在 Hadoop 版本 1 的 MapReduce 框架中,作业执行由几种类型的进程控制——一个名为 JobTracker 的单一主进程协调集群中运行的所有作业,并将 map 和 reduce 任务分配给 TaskTrackers,这些是运行分配任务的从属进程,并定期将进度报告给 JobTracker。拥有一个单一的 JobTracker 成为可扩展性的瓶颈。最大集群规模略超过 4000 个节点,并且并发任务数限制为 40,000。此外,JobTracker 是单点故障,并且唯一可用的编程模型是 MapReduce。
YARN 的基本思想是将资源管理和作业调度或监控的功能拆分为独立的守护进程。其思路是拥有一个全局的ResourceManager和每个应用程序的ApplicationMaster(App Mstr)。一个应用程序可以是一个单独的作业,也可以是作业的有向无环图(DAG)。以下是 YARN 架构的示意图:
图 1.15
ResourceManager 和 NodeManager 组成了 YARN 框架。ResourceManager 决定所有运行应用程序的资源使用,而 NodeManager 是运行在集群中任何机器上的代理,负责通过监控容器的资源使用(包括 CPU 和内存)并向 ResourceManager 报告。ResourceManager 由两个组件组成——调度器和 ApplicationsManager。调度器是负责分配资源给各种正在运行的应用程序的组件,但它不对应用程序状态进行监控,也不提供重启失败任务的保证。它是根据应用程序的资源需求来进行调度的。
ApplicationsManager 接受作业提交,并提供在任何故障时重新启动 App Mstr 容器的服务。每个应用程序的 App Mstr 负责与调度程序协商适当的资源容器,并监视其状态和进度。YARN 作为通用调度程序,支持用于 Hadoop 集群的非 MapReduce 作业(如 Spark 作业)。
在 YARN 上提交 Spark 应用程序
要在 YARN 上启动 Spark 应用程序,需要设置 HADOOP_CONF_DIR 或 YARN_CONF_DIR 环境变量,并指向包含 Hadoop 集群客户端配置文件的目录。这些配置用于连接到 YARN ResourceManager 和写入 HDFS。此配置分发到 YARN 集群,以便 Spark 应用程序使用的所有容器具有相同的配置。在 YARN 上启动 Spark 应用程序时,有两种部署模式可用:
-
Cluster mode:在此情况下,Spark Driver 在由 YARN 在集群上管理的应用程序主进程内运行。客户端在启动应用程序后可以完成其执行。
-
Client mode:在此情况下,Driver 和客户端在同一个进程中运行。应用程序主进程仅用于从 YARN 请求资源的目的。
与其他模式不同,在 YARN 模式中,Master 的地址是从 Hadoop 配置中检索的 ResourceManager 的地址。因此,master 参数的值始终为 yarn。
您可以使用以下命令在集群模式下启动 Spark 应用程序:
$SPARK_HOME/bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] <app jar> [app options]
在集群模式下,由于 Driver 运行在与客户端不同的机器上,SparkContext.addJar 方法无法使用客户端本地的文件。唯一的选择是使用 launch 命令中的 jars 选项包含它们。
在客户端模式下启动 Spark 应用程序的方法相同——deploy-mode 选项值需要从 cluster 更改为 client。
Kubernetes 集群模式
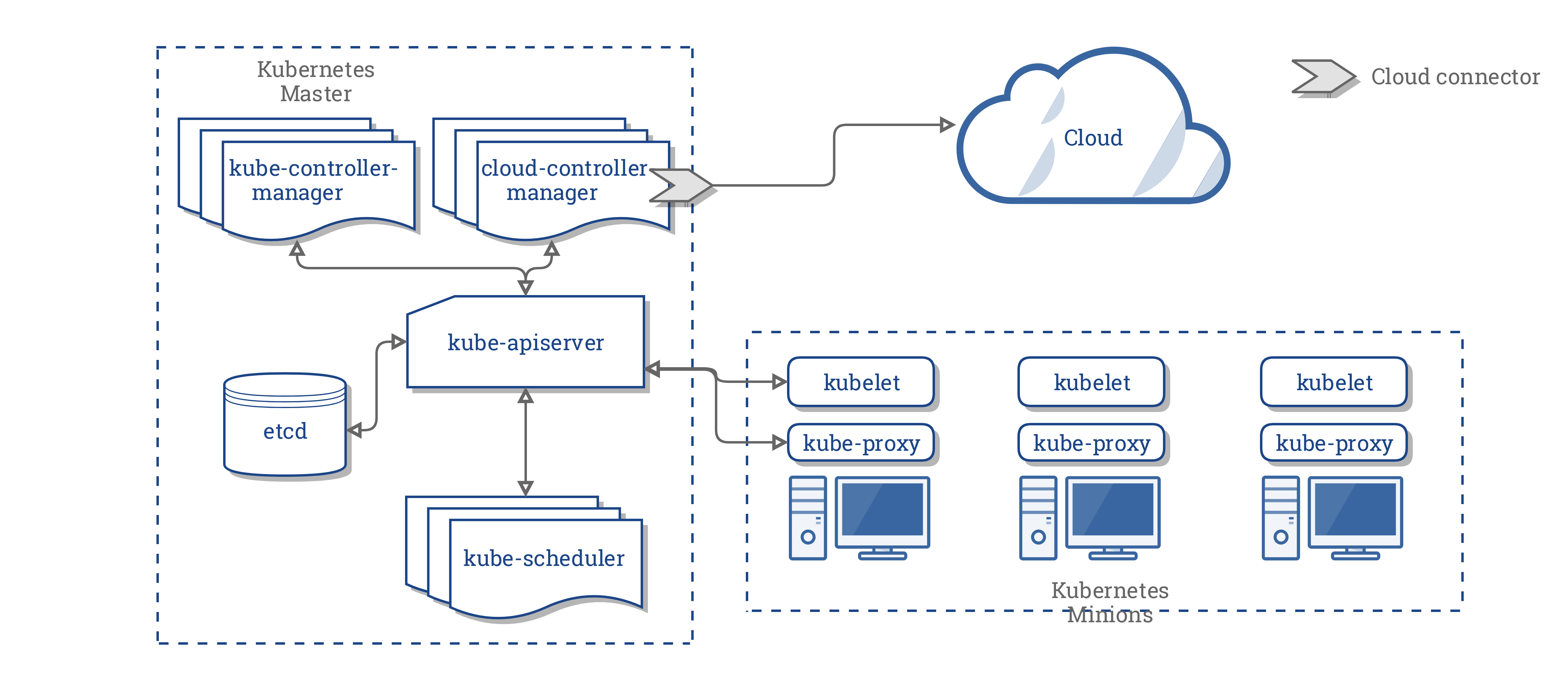
Kubernetes (kubernetes.io/) 是一个开源系统,用于自动化部署、扩展和管理容器化应用程序。它最初由 Google 实施,于 2014 年开源。以下是 Kubernetes 的主要概念:
-
Pod:这是可以创建和管理的最小计算可部署单元。Pod 可以看作是一个或多个共享网络和存储空间的容器组,还包含如何运行这些容器的规范。
-
Deployment:这是一个抽象层,其主要目的是声明应该同时运行多少个 Pod 的副本。
-
Ingress:这是与在 Pod 中运行的服务通信的开放通道。
-
Node:这是集群中单个机器的表示。
-
持久卷:它提供一个文件系统,可以挂载到集群,而不与任何特定节点关联。这是 Kubernetes 持久化信息(数据、文件等)的方法。
以下图(来源:d33wubrfki0l68.cloudfront.net/518e18713c865fe67a5f23fc64260806d72b38f5/61d75/images/docs/post-ccm-arch.png)展示了 Kubernetes 架构:
图 1.16
Kubernetes 架构的主要组件如下:
-
云控制器管理器:它运行 Kubernetes 控制器
-
控制器:共有四个——节点、路由、服务和 PersistentVolumeLabels
-
Kubelets:运行在节点上的主要代理
提交 Spark 作业到 Kubernetes 集群可以通过 spark-submit 直接完成。Kubernetes 要求我们提供可以部署到 pod 中容器的 Docker (www.docker.com/) 镜像。从 2.3 版本开始,Spark 提供了一个 Dockerfile ($SPARK_HOME/kubernetes/dockerfiles/Dockerfile,也可以根据特定应用需求进行定制) 和一个脚本 ($SPARK_HOME/bin/docker-image-tool.sh),用于构建和发布将用于 Kubernetes 后端的 Docker 镜像。以下是通过提供的脚本构建 Docker 镜像的语法:
$SPARK_HOME/bin/docker-image-tool.sh -r <repo> -t my-tag build
以下是使用相同脚本将镜像推送到 Docker 仓库的语法:
$SPARK_HOME/bin/docker-image-tool.sh -r <repo> -t my-tag push
作业可以通过以下方式提交:
$SPARK_HOME/bin/spark-submit \
--master k8s://https://<k8s_hostname>:<k8s_port> \
--deploy-mode cluster \
--name <application-name> \
--class <package>.<ClassName> \
--conf spark.executor.instances=<instance_count> \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/<sparkjob>.jar
Kubernetes 要求应用程序名称仅包含小写字母数字字符、连字符和点,并且必须以字母数字字符开头和结尾。
以下图展示了提交机制的工作方式:
图 1.17
以下是发生的事情:
-
Spark 创建了一个在 Kubernetes pod 中运行的驱动程序
-
驱动程序创建执行器,执行器也运行在 Kubernetes pod 中,然后连接到它们并执行应用程序代码
-
执行结束时,执行器 pod 会终止并被清理,而驱动程序 pod 会继续保留日志,并保持完成状态(意味着它不再使用集群的计算或内存资源),在 Kubernetes API 中(直到最终被垃圾回收或手动删除)
总结
在本章中,我们熟悉了 Apache Spark 及其主要模块。我们开始使用可用的 Spark shell,并使用 Scala 和 Python 编程语言编写了第一个自包含的应用程序。最后,我们探索了在集群模式下部署和运行 Spark 的不同方法。到目前为止,我们学到的所有内容都是理解从第三章 提取、转换、加载 及之后主题所必需的。如果你对所呈现的任何主题有疑问,我建议你在继续之前回过头再阅读一遍本章。
在下一章,我们将探索深度学习(DL)的基础知识,重点介绍多层神经网络的某些具体实现。
第二章:深度学习基础
在本章中,我将介绍深度学习(DL)的核心概念,它与机器学习(ML)和人工智能(AI)的关系,各种类型的多层神经网络,以及一些现实世界中的实际应用。我将尽量避免数学公式,并保持描述的高层次,不涉及代码示例。本章的目的是让读者了解深度学习的真正含义以及它能做什么,而接下来的章节将更详细地讲解这一内容,并提供大量 Scala 和 Python 中的实际代码示例(这些编程语言可以使用)。
本章将涵盖以下主题:
-
深度学习概念
-
深度神经网络 (DNNs)
-
深度学习的实际应用
介绍深度学习
深度学习是机器学习(ML)的一个子集,可以解决特别困难和大规模的问题,应用领域包括自然语言处理 (NLP)和图像分类。DL 这个术语有时与 ML 和 AI 互换使用,但 ML 和 DL 都是 AI 的子集。AI 是更广泛的概念,它通过 ML 来实现。DL 是实现 ML 的一种方式,涉及基于神经网络的算法:
图 2.1
人工智能(AI)被认为是机器(它可以是任何计算机控制的设备或机器人)执行通常与人类相关的任务的能力。该概念于 20 世纪 50 年代提出,目的是减少人类的互动,从而让机器完成所有工作。这个概念主要应用于开发那些通常需要人类智力过程和/或从过去经验中学习的系统。
机器学习(ML)是一种实现人工智能(AI)的方法。它是计算机科学的一个领域,使计算机系统能够从数据中学习,而不需要显式编程。基本上,它使用算法在数据中寻找模式,然后使用能够识别这些模式的模型对新数据进行预测。下图展示了训练和构建模型的典型过程:
图 2.2
机器学习可以分为三种类型:
-
有监督学习算法,使用标注数据
-
无监督学习算法,从未标注数据中发现模式
-
半监督学习,使用两者的混合(标注数据和未标注数据)
截至写作时,有监督学习是最常见的机器学习算法类型。有监督学习可以分为两类——回归和分类问题。
下图展示了一个简单的回归问题:
图 2.3
如你所见,图中有两个输入(或特征),大小和价格,它们被用来生成曲线拟合线,并对房产价格进行后续预测。
以下图表展示了一个监督分类的示例:
图 2.4
数据集标记了良性(圆圈)和恶性(叉号)肿瘤,针对乳腺癌患者。一个监督分类算法通过拟合一条直线将数据分为两类。然后,基于该直线分类,未来的数据将被分类为良性或恶性。前述图表中的情况只有两个离散输出,但也有可能存在超过两种分类的情况。
在监督学习中,带标签的数据集帮助算法确定正确答案,而在无监督学习中,算法提供未标记的数据集,依赖于算法本身来发现数据中的结构和模式。在以下图表中(右侧的图表可以在 leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/Images/supervised_unsupervised.png 查看),没有提供关于每个数据点的含义信息。我们要求算法以独立于监督的方式发现数据中的结构。一个无监督学习算法可能会发现数据中有两个不同的簇,然后在它们之间进行直线分类:
图 2.5
**深度学习(DL)是指多层神经网络的名称,这些网络由输入和输出之间的多个隐藏层节点组成。DL 是人工神经网络(ANNs)**的细化版,模拟了人类大脑的学习方式(尽管并不完全相同)以及解决问题的方法。ANNs 由一个互联的神经元群体组成,类似于人脑中神经元的工作方式。以下图示表示 ANN 的通用模型:
图 2.6
神经元是人工神经网络(ANN)的基本单元。它接收一定数量的输入(x[i]),对其进行计算,然后最终将输出发送到同一网络中的其他神经元。权重(w[j]),或参数,表示输入连接的强度——它们可以是正值或负值。网络输入可以按以下公式计算:
y[in] = x[1] X w[1] + x[2] X w[2] + x[3] X w[3] + … + x[n] X w[n]
输出可以通过对网络输入应用激活函数来计算:
y = f(y[in])
激活函数使人工神经网络(ANN)能够建模复杂的非线性模式,而简单的模型可能无法正确表示这些模式。
以下图示表示一个神经网络:
图 2.7
第一层是输入层——这是将特征输入网络的地方。最后一层是输出层。任何不属于输入层或输出层的中间层都是隐藏层。之所以称为 DL,是因为神经网络中存在多个隐藏层,用来解决复杂的非线性问题。在每一层中,任何单个节点都会接收输入数据和一个权重,并将一个置信度分数输出给下一层的节点。这个过程会一直进行,直到到达输出层。这个分数的误差会在该层计算出来。然后,误差会被发送回去,调整网络的权重,从而改进模型(这被称为反向传播,并发生在一个叫做梯度下降的过程中,我们将在第六章中讨论,循环神经网络)。神经网络有许多变种——更多内容将在下一部分介绍。
在继续之前,最后一个观察点。你可能会想,为什么 AI、ML 和 DL 背后的大多数概念已经存在了几十年,但在过去的 4 到 5 年才被炒作起来?有几个因素加速了它们的实施,并使其从理论走向现实应用:
-
更便宜的计算:在过去几十年中,硬件一直是 AI/ML/DL 的制约因素。近期硬件(结合改进的工具和软件框架)以及新计算模型(包括围绕 GPU 的模型)的进步,加速了 AI/ML/DL 的采用。
-
更大的数据可用性:AI/ML/DL 需要大量的数据来进行学习。社会的数字化转型正在提供大量原始材料,推动快速发展。大数据如今来自多种来源,如物联网传感器、社交和移动计算、智能汽车、医疗设备等,这些数据已经或将被用于训练模型。
-
更便宜的存储:可用数据量的增加意味着需要更多的存储空间。硬件的进步、成本的降低和性能的提高使得新存储系统的实现成为可能,而这一切都没有传统关系型数据库的限制。
-
更先进的算法:更便宜的计算和存储使得更先进的算法得以开发和训练,这些算法在解决特定问题时,如图像分类和欺诈检测,展现了令人印象深刻的准确性。
-
更多、更大规模的投资:最后但同样重要的是,人工智能的投资不再仅仅局限于大学或研究机构,而是来自许多其他实体,如科技巨头、政府、初创公司和各行各业的大型企业。
DNN 概述
如前一节所述,DNN 是一种在输入层和输出层之间具有多个隐藏层的人工神经网络(ANN)。通常,它们是前馈网络,其中数据从输入层流向输出层,不会回传,但 DNN 有不同的变种——其中,最具实际应用的是卷积神经网络(CNNs)和递归神经网络(RNNs)。
CNNs
CNNs 最常见的应用场景都与图像处理相关,但并不限于其他类型的输入,无论是音频还是视频。一个典型的应用场景是图像分类——网络接收图像输入,以便对数据进行分类。例如,当你给它一张狮子图片时,它输出狮子,当你给它一张老虎图片时,它输出老虎,依此类推。之所以使用这种网络进行图像分类,是因为它相对于同领域的其他算法来说,预处理工作量较小——网络学习到的滤波器,传统算法是人工设计的。
作为一个多层神经网络,CNN 由输入层、输出层以及多个隐藏层组成。隐藏层可以是卷积层、池化层、全连接层和归一化层。卷积层对输入进行卷积运算(en.wikipedia.org/wiki/Convolution),然后将结果传递给下一个层。这个操作模拟了个体物理神经元对视觉刺激的响应生成方式。每个卷积神经元仅处理其感受野中的数据(感受野是指个体感官神经元的感官空间中,环境变化会改变该神经元的放电情况的特定区域)。池化层负责将一个层中神经元群的输出合并成下一层的单一神经元。池化有不同的实现方式——最大池化,使用来自前一层每个群体的最大值;平均池化,使用前一层任何神经元群的平均值;等等。全连接层则顾名思义,将一层中的每个神经元与另一层中的每个神经元连接起来。
CNN 并不会一次性解析所有训练数据,但它们通常从某种输入扫描器开始。例如,考虑一张 200 x 200 像素的图像作为输入。在这种情况下,模型没有一个包含 40,000 个节点的层,而是一个 20 x 20 的扫描输入层,该层使用原始图像的前 20 x 20 像素(通常从左上角开始)。一旦我们处理完该输入(并可能用它进行训练),我们就会使用下一个 20 x 20 像素输入(这一过程将在第五章,卷积神经网络中更详细地解释;这个过程类似于扫描仪的移动,每次向右移动一个像素)。请注意,图像并不是被分解成 20 x 20 的块,而是扫描仪在其上移动。然后,这些输入数据会通过一个或多个卷积层。每个卷积层的节点只需要与其邻近的节点工作——并不是所有的节点都互相连接。网络越深,它的卷积层越小,通常遵循输入的可分因子(如果我们从 20 的层开始,那么下一个层很可能是 10,接下来是 5)。通常使用 2 的幂作为可分因子。
以下图(由 Aphex34 制作,CC BY-SA 4.0,commons.wikimedia.org/w/index.php?curid=45679374)展示了 CNN 的典型架构:
图 2.8
RNN(循环神经网络)
RNNs 主要因许多 NLP 任务而流行(即使它们目前也被用于不同的场景,我们将在第六章,循环神经网络中讨论)。RNN 的独特之处是什么?它们的特点是单元之间的连接形成一个沿着序列的有向图。这意味着 RNN 可以展示给定时间序列的动态时间行为。因此,它们可以使用内部状态(记忆)来处理输入序列,而在传统神经网络中,我们假设所有输入和输出彼此独立。这使得 RNN 适用于某些场景,例如当我们想要预测句子中的下一个词时——知道它前面的词肯定更有帮助。现在,你可以理解为什么它们被称为“循环”——每个序列元素都执行相同的任务,且输出依赖于之前的计算。
RNNs 中有循环结构,允许信息保持,如下所示:
图 2.9
在前面的图示中,神经网络的一部分,H,接收一些输入,x,并输出一个值,o。一个循环允许信息从网络的一个步骤传递到下一个步骤。通过展开图中的 RNN,形成一个完整的网络(如以下图所示),它可以被看作是多个相同网络的副本,每个副本将信息传递给后续步骤:
图 2.10
在这里,x[t] 是时间步 t 的输入,H[t] 是时间步 t 的隐藏状态(代表网络的记忆),而 o[t] 是时间步 t 的输出。隐藏状态捕捉了所有前一步骤中发生的事情的信息。给定步骤的输出仅基于时间 t 的记忆进行计算。RNN 在每个步骤中共享相同的参数——这是因为每个步骤执行的是相同的任务,只是输入不同——大大减少了它需要学习的总参数数量。每个步骤的输出不是必需的,因为这取决于当前的任务。同样,并非每个时间步都需要输入。
RNN 最早在 1980 年代开发,直到最近才有了许多新的变种。以下是其中一些架构的列表:
-
全递归:每个元素与架构中的每个其他元素都有一个加权的单向连接,并且与自身有一个单一的反馈连接。
-
递归:相同的权重集在结构中递归地应用,这种结构类似于图形结构。在此过程中,结构会按拓扑排序进行遍历(
en.wikipedia.org/wiki/Topological_sorting)。 -
霍普菲尔德网络:所有的连接都是对称的。这种网络不适用于需要处理模式序列的场景,因为它只需要静态输入。
-
埃尔曼网络:这是一个三层网络,横向排列,外加一组所谓的上下文单元。中间的隐藏层与所有这些单元连接,权重固定为 1。在每个时间步,输入被前馈,然后应用一个学习规则。由于反向连接是固定的,隐藏单元的前一值会被保存在上下文单元中。这样,网络就能保持状态。正因如此,这种类型的 RNN 允许你执行一些标准多层神经网络无法完成的任务。
-
长短期记忆(LSTM):这是一种深度学习方法,防止反向传播的错误消失或梯度爆炸(这一点将在第六章,递归神经网络中详细讲解)。错误可以通过(理论上)无限数量的虚拟层向后流动。也就是说,LSTM 可以学习需要记住可能发生在几个时间步之前的事件的任务。
-
双向:通过连接两个 RNN 的输出,可以预测有限序列中的每个元素。第一个 RNN 从左到右处理序列,而第二个 RNN 则以相反的方向进行处理。
-
递归多层感知器网络:由级联子网络组成,每个子网络包含多个节点层。除最后一层(唯一可以有反馈连接的层)外,其他子网络都是前馈的。
第五章,卷积神经网络,以及第六章,递归神经网络,将详细讲解 CNN 和 RNN。
深度学习的实际应用
前两部分所介绍的深度学习概念和模型不仅仅是纯理论——实际上,已经有许多应用基于这些概念和模型得以实现。深度学习擅长识别非结构化数据中的模式;大多数应用场景与图像、声音、视频和文本等媒体相关。如今,深度学习已经应用于多个商业领域的众多场景,包括以下几种:
-
计算机视觉:在汽车工业、面部识别、动作检测和实时威胁检测等方面的应用。
-
自然语言处理(NLP):社交媒体情感分析、金融和保险中的欺诈检测、增强搜索和日志分析。
-
医学诊断:异常检测、病理识别。
-
搜索引擎:图像搜索。
-
物联网(IoT):智能家居、基于传感器数据的预测分析。
-
制造业:预测性维护。
-
营销:推荐引擎、自动化目标识别。
-
音频分析:语音识别、语音搜索和机器翻译。
还有许多内容在后续章节中会进一步介绍。
总结
本章介绍了深度学习(DL)的基础知识。这个概述保持了较高的层次,以帮助那些刚接触这一话题的读者,并为他们准备好迎接接下来章节中更详细和实践性的内容。
第三章:提取、转换、加载
训练和测试深度学习模型需要数据。数据通常存储在不同的分布式和远程存储系统中。你需要连接到数据源并执行数据检索,以便开始训练阶段,同时可能需要做一些准备工作再将数据输入模型。本章介绍了应用于深度学习的提取、转换、加载(ETL)过程的各个阶段。它涵盖了使用 DeepLearning4j 框架和 Spark 的若干用例,这些用例与批量数据摄取有关。数据流处理将在下一章介绍。
本章将涵盖以下主题:
-
通过 Spark 摄取训练数据
-
从关系型数据库中摄取数据
-
从 NoSQL 数据库摄取数据
-
从 S3 摄取数据
通过 Spark 摄取训练数据
本章的第一部分介绍了 DeepLearning4j 框架,并展示了使用该框架和 Apache Spark 从文件中摄取训练数据的一些用例。
DeepLearning4j 框架
在进入第一个示例之前,我们先简单介绍一下 DeepLearning4j(deeplearning4j.org/)框架。它是一个开源的(基于 Apache 2.0 许可证发布,www.apache.org/licenses/LICENSE-2.0)分布式深度学习框架,专为 JVM 编写。自最早版本起,DeepLearning4j 便与 Hadoop 和 Spark 集成,利用这些分布式计算框架加速网络训练。该框架用 Java 编写,因此与任何其他 JVM 语言(当然也包括 Scala)兼容,而底层计算则使用低级语言(如 C、C++和 CUDA)编写。DL4J 的 API 提供了在构建深度神经网络时的灵活性。因此,可以根据需要将不同的网络实现组合在一起,部署到基于分布式 CPU 或 GPU 的生产级基础设施上。DL4J 可以通过 Keras(keras.io/)导入来自大多数主流机器学习或深度学习 Python 框架(包括 TensorFlow 和 Caffe)的神经网络模型,弥合 Python 与 JVM 生态系统之间的差距,尤其是为数据科学家提供工具,同时也适用于数据工程师和 DevOps。Keras 代表了 DL4J 的 Python API。
DL4J 是模块化的。以下是构成该框架的主要库:
-
Deeplearning4j:神经网络平台核心
-
ND4J:JVM 版 NumPy(
www.numpy.org/) -
DataVec:用于机器学习 ETL 操作的工具
-
Keras 导入:导入在 Keras 中实现的预训练 Python 模型
-
Arbiter:用于多层神经网络超参数优化的专用库
-
RL4J:JVM 版深度强化学习实现
我们将从本章开始,探索 DL4J 及其库的几乎所有功能,并贯穿本书的其他章节。
本书中的 DL4J 参考版本是 0.9.1。
通过 DataVec 获取数据并通过 Spark 进行转化
数据可以来自多个来源,并且有多种类型,例如:
-
日志文件
-
文本文件
-
表格数据
-
图像
-
视频
在使用神经网络时,最终目标是将每种数据类型转换为多维数组中的数值集合。数据在被用于训练或测试神经网络之前,可能还需要预处理。因此,在大多数情况下,需要进行 ETL 过程,这是数据科学家在进行机器学习或深度学习时面临的一个有时被低估的挑战。这时,DL4J DataVec 库就发挥了重要作用。通过该库的 API 转换后的数据,转换为神经网络可理解的格式(向量),因此 DataVec 可以快速生成符合开放标准的向量化数据。
DataVec 开箱即用地支持所有主要类型的输入数据(文本、CSV、音频、视频、图像)及其特定的输入格式。它可以扩展以支持当前 API 版本中未涵盖的专业输入格式。你可以将 DataVec 的输入/输出格式系统与 Hadoop MapReduce 中的 InputFormat 实现进行类比,用于确定逻辑的 InputSplits 和 RecordReaders 实现的选择。它还提供 RecordReaders 来序列化数据。这个库还包括特征工程、数据清理和归一化的功能。它们可以处理静态数据和时间序列数据。所有可用的功能都可以通过 DataVec-Spark 模块在 Apache Spark 上执行。
如果你想了解更多关于前面提到的 Hadoop MapReduce 类的信息,你可以查看以下官方在线 Javadocs:
让我们来看一个 Scala 中的实际代码示例。我们想从一个包含电子商店交易的 CSV 文件中提取数据,并且该文件包含以下列:
-
DateTimeString -
CustomerID -
MerchantID -
NumItemsInTransaction -
MerchantCountryCode -
TransactionAmountUSD -
FraudLabel
然后,我们对这些数据进行一些转化操作。
首先,我们需要导入所需的依赖项(Scala、Spark、DataVec 和 DataVec-Spark)。以下是 Maven POM 文件的完整列表(当然,您也可以使用 SBT 或 Gradle):
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.1</spark.version>
<dl4j.version>0.9.1</dl4j.version>
<datavec.spark.version>0.9.1_spark_2</datavec.spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.datavec</groupId>
<artifactId>datavec-api</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.datavec</groupId>
<artifactId>datavec-spark_2.11</artifactId>
<version>${datavec.spark.version}</version>
</dependency>
</dependencies>
在 Scala 应用程序中的第一步是定义输入数据模式,如下所示:
val inputDataSchema = new Schema.Builder()
.addColumnString("DateTimeString")
.addColumnsString("CustomerID", "MerchantID")
.addColumnInteger("NumItemsInTransaction")
.addColumnCategorical("MerchantCountryCode", List("USA", "CAN", "FR", "MX").asJava)
.addColumnDouble("TransactionAmountUSD", 0.0, null, false, false) //$0.0 or more, no maximum limit, no NaN and no Infinite values
.addColumnCategorical("FraudLabel", List("Fraud", "Legit").asJava)
.build
如果输入数据是数值的并且格式正确,那么可以使用CSVRecordReader (deeplearning4j.org/datavecdoc/org/datavec/api/records/reader/impl/csv/CSVRecordReader.html)。然而,如果输入数据包含非数值字段,则需要进行模式转换。DataVec 使用 Apache Spark 执行转换操作。一旦我们有了输入模式,我们可以定义要应用于输入数据的转换。这个例子中描述了一些转换。例如,我们可以删除一些对我们的网络不必要的列:
val tp = new TransformProcess.Builder(inputDataSchema)
.removeColumns("CustomerID", "MerchantID")
.build
过滤MerchantCountryCode列以获取仅与美国和加拿大相关的记录,如下所示:
.filter(new ConditionFilter(
new CategoricalColumnCondition("MerchantCountryCode", ConditionOp.NotInSet, new HashSet(Arrays.asList("USA","CAN")))))
在此阶段,仅定义了转换,但尚未应用(当然,我们首先需要从输入文件中获取数据)。到目前为止,我们仅使用了 DataVec 类。为了读取数据并应用定义的转换,需要使用 Spark 和 DataVec-Spark API。
让我们首先创建SparkContext,如下所示:
val conf = new SparkConf
conf.setMaster(args[0])
conf.setAppName("DataVec Example")
val sc = new JavaSparkContext(conf)
现在,我们可以读取 CSV 输入文件并使用CSVRecordReader解析数据,如下所示:
val directory = new ClassPathResource("datavec-example-data.csv").getFile.getAbsolutePath
val stringData = sc.textFile(directory)
val rr = new CSVRecordReader
val parsedInputData = stringData.map(new StringToWritablesFunction(rr))
然后执行先前定义的转换,如下所示:
val processedData = SparkTransformExecutor.execute(parsedInputData, tp)
最后,让我们本地收集数据,如下所示:
val processedAsString = processedData.map(new WritablesToStringFunction(","))
val processedCollected = processedAsString.collect
val inputDataCollected = stringData.collect
输入数据如下所示:
处理后的数据如下所示:
这个示例的完整代码包含在书籍附带的源代码中。
使用 Spark 从数据库中进行训练数据摄取
有时数据之前已被其他应用程序摄入并存储到数据库中,因此您需要连接到数据库以便用于训练或测试目的。本节描述了如何从关系数据库和 NoSQL 数据库获取数据。在这两种情况下,都将使用 Spark。
从关系数据库中摄取数据
假设数据存储在 MySQL (dev.mysql.com/) 架构名称为 sparkdb 的表 sparkexample 中。这是该表的结构:
mysql> DESCRIBE sparkexample;
+-----------------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+-------------+------+-----+---------+-------+
| DateTimeString | varchar(23) | YES | | NULL | |
| CustomerID | varchar(10) | YES | | NULL | |
| MerchantID | varchar(10) | YES | | NULL | |
| NumItemsInTransaction | int(11) | YES | | NULL | |
| MerchantCountryCode | varchar(3) | YES | | NULL | |
| TransactionAmountUSD | float | YES | | NULL | |
| FraudLabel | varchar(5) | YES | | NULL | |
+-----------------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
它包含与 使用 Spark 进行训练数据摄取 中相同的数据,如下所示:
mysql> select * from sparkexample;
+-------------------------+------------+------------+-----------------------+---------------------+----------------------+------------+
| DateTimeString | CustomerID | MerchantID | NumItemsInTransaction | MerchantCountryCode | TransactionAmountUSD | FraudLabel |
+-------------------------+------------+------------+-----------------------+---------------------+----------------------+------------+
| 2016-01-01 17:00:00.000 | 830a7u3 | u323fy8902 | 1 | USA | 100 | Legit |
| 2016-01-01 18:03:01.256 | 830a7u3 | 9732498oeu | 3 | FR | 73.2 | Legit |
|... | | | | | | |
添加到 Scala Spark 项目中的依赖项如下所示:
-
Apache Spark 2.2.1
-
Apache Spark SQL 2.2.1
-
用于 MySQL 数据库发布的特定 JDBC 驱动程序
现在我们来实现 Scala 中的 Spark 应用程序。为了连接到数据库,我们需要提供所有必要的参数。Spark SQL 还包括一个数据源,可以使用 JDBC 从其他数据库读取数据,因此所需的属性与通过传统 JDBC 连接到数据库时相同;例如:
var jdbcUsername = "root"
var jdbcPassword = "secretpw"
val jdbcHostname = "mysqlhost"
val jdbcPort = 3306
val jdbcDatabase ="sparkdb"
val jdbcUrl = s"jdbc:mysql://${jdbcHostname}:${jdbcPort}/${jdbcDatabase}"
我们需要检查 MySQL 数据库的 JDBC 驱动是否可用,如下所示:
Class.forName("com.mysql.jdbc.Driver")
我们现在可以创建一个 SparkSession,如下所示:
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Spark MySQL basic example")
.getOrCreate()
导入隐式转换,如下所示:
import spark.implicits._
最终,你可以连接到数据库并将 sparkexample 表中的数据加载到 DataFrame,如下所示:
val jdbcDF = spark.read
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", s"${jdbcDatabase}.sparkexample")
.option("user", jdbcUsername)
.option("password", jdbcPassword)
.load()
Spark 会自动从数据库表中读取模式,并将其类型映射回 Spark SQL 类型。对 DataFrame 执行以下方法:
jdbcDF.printSchema()
它返回与表 sparkexample相同的模式;例如:
root
|-- DateTimeString: string (nullable = true)
|-- CustomerID: string (nullable = true)
|-- MerchantID: string (nullable = true)
|-- NumItemsInTransaction: integer (nullable = true)
|-- MerchantCountryCode: string (nullable = true)
|-- TransactionAmountUSD: double (nullable = true)
|-- FraudLabel: string (nullable = true)
一旦数据被加载到 DataFrame 中,就可以使用特定的 DSL 执行 SQL 查询,如下例所示:
jdbcDF.select("MerchantCountryCode", "TransactionAmountUSD").groupBy("MerchantCountryCode").avg("TransactionAmountUSD")
可以通过 JDBC 接口增加读取的并行性。我们需要根据 DataFrame 列值提供拆分边界。有四个选项可用(columnname,lowerBound,upperBound 和 numPartitions),用于指定读取时的并行性。它们是可选的,但如果提供其中任何一个,必须全部指定;例如:
val jdbcDF = spark.read
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", s"${jdbcDatabase}.employees")
.option("user", jdbcUsername)
.option("password", jdbcPassword)
.option("columnName", "employeeID")
.option("lowerBound", 1L)
.option("upperBound", 100000L)
.option("numPartitions", 100)
.load()
尽管本节中的示例参考了 MySQL 数据库,但它们适用于任何具有 JDBC 驱动的商业或开源关系型数据库。
从 NoSQL 数据库中获取数据
数据也可以来自 NoSQL 数据库。在本节中,我们将探讨实现代码,以便从 MongoDB (www.mongodb.com/) 数据库中消费数据。
sparkmdb 数据库中的 sparkexample 集合包含与 通过 DataVec 获取数据和通过 Spark 转换 以及 从关系型数据库获取数据 部分中的示例相同的数据,但以 BSON 文档的形式;例如:
/* 1 */
{
"_id" : ObjectId("5ae39eed144dfae14837c625"),
"DateTimeString" : "2016-01-01 17:00:00.000",
"CustomerID" : "830a7u3",
"MerchantID" : "u323fy8902",
"NumItemsInTransaction" : 1,
"MerchantCountryCode" : "USA",
"TransactionAmountUSD" : 100.0,
"FraudLabel" : "Legit"
}
/* 2 */
{
"_id" : ObjectId("5ae3a15d144dfae14837c671"),
"DateTimeString" : "2016-01-01 18:03:01.256",
"CustomerID" : "830a7u3",
"MerchantID" : "9732498oeu",
"NumItemsInTransaction" : 3,
"MerchantCountryCode" : "FR",
"TransactionAmountUSD" : 73.0,
"FraudLabel" : "Legit"
}
...
需要添加到 Scala Spark 项目的依赖项如下:
-
Apache Spark 2.2.1
-
Apache Spark SQL 2.2.1
-
Spark 2.2.0 的 MongoDB 连接器
我们需要创建一个 Spark 会话,如下所示:
val sparkSession = SparkSession.builder()
.master("local")
.appName("MongoSparkConnectorIntro")
.config("spark.mongodb.input.uri", "mongodb://mdbhost:27017/sparkmdb.sparkexample")
.config("spark.mongodb.output.uri", "mongodb://mdbhost:27017/sparkmdb.sparkexample")
.getOrCreate()
指定连接到数据库的方式。在创建会话后,可以使用它通过 com.mongodb.spark.MongoSpark 类从 sparkexample 集合加载数据,如下所示:
val df = MongoSpark.load(sparkSession)
返回的 DataFrame 具有与 sparkexample 集合相同的结构。使用以下指令:
df.printSchema()
它会打印出以下输出:
当然,检索到的数据就是数据库集合中的数据,如下所示:
df.collect.foreach { println }
它返回如下内容:
[830a7u3,2016-01-01 17:00:00.000,Legit,USA,u323fy8902,1,100.0,[5ae39eed144dfae14837c625]]
[830a7u3,2016-01-01 18:03:01.256,Legit,FR,9732498oeu,3,73.0,[5ae3a15d144dfae14837c671]]
...
还可以在 DataFrame 上运行 SQL 查询。我们首先需要创建一个 case 类来定义 DataFrame 的模式,如下所示:
case class Transaction(CustomerID: String,
MerchantID: String,
MerchantCountryCode: String,
DateTimeString: String,
NumItemsInTransaction: Int,
TransactionAmountUSD: Double,
FraudLabel: String)
然后我们加载数据,如下所示:
val transactions = MongoSpark.loadTransaction
我们必须为 DataFrame 注册一个临时视图,如下所示:
transactions.createOrReplaceTempView("transactions")
在我们执行 SQL 语句之前,例如:
val filteredTransactions = sparkSession.sql("SELECT CustomerID, MerchantID FROM transactions WHERE TransactionAmountUSD = 100")
使用以下指令:
filteredTransactions.show
它返回如下内容:
+----------+----------+
|CustomerID|MerchantID|
+----------+----------+
| 830a7u3|u323fy8902|
+----------+----------+
从 S3 获取数据
如今,训练和测试数据很可能托管在某些云存储系统中。在本节中,我们将学习如何通过 Apache Spark 从对象存储(如 Amazon S3(aws.amazon.com/s3/)或基于 S3 的存储(如 Minio,www.minio.io/))摄取数据。Amazon 简单存储服务(更常被称为 Amazon S3)是 AWS 云服务的一部分,提供对象存储服务。虽然 S3 可用于公共云,Minio 是一个高性能分布式对象存储服务器,兼容 S3 协议和标准,专为大规模私有云基础设施设计。
我们需要在 Scala 项目中添加 Spark 核心和 Spark SQL 依赖项,以及以下内容:
groupId: com.amazonaws
artifactId: aws-java-sdk-core
version1.11.234
groupId: com.amazonaws
artifactId: aws-java-sdk-s3
version1.11.234
groupId: org.apache.hadoop
artifactId: hadoop-aws
version: 3.1.1
它们是 AWS Java JDK 核心库和 S3 库,以及用于 AWS 集成的 Apache Hadoop 模块。
对于这个示例,我们需要已经在 S3 或 Minio 上创建了一个现有的存储桶。对于不熟悉 S3 对象存储的读者,存储桶类似于文件系统目录,用户可以在其中存储对象(数据及其描述的元数据)。然后,我们需要在该存储桶中上传一个文件,Spark 将需要读取该文件。此示例使用的文件通常可以从 MonitorWare 网站下载(www.monitorware.com/en/logsamples/apache.php)。它包含以 ASCII 格式记录的 HTTP 请求日志条目。为了这个示例,我们假设存储桶的名称是 dl4j-bucket,上传的文件名是 access_log。在我们的 Spark 程序中,首先要做的是创建一个 SparkSession,如下所示
val sparkSession = SparkSession
.builder
.master(master)
.appName("Spark Minio Example")
.getOrCreate
为了减少输出中的噪音,让我们将 Spark 的日志级别设置为 WARN,如下所示
sparkSession.sparkContext.setLogLevel("WARN")
现在 SparkSession 已创建,我们需要设置 S3 或 Minio 端点和凭据,以便 Spark 访问它,并设置其他一些属性,如下所示:
sparkSession.sparkContext.hadoopConfiguration.set("fs.s3a.endpoint", "http://<host>:<port>")
sparkSession.sparkContext.hadoopConfiguration.set("fs.s3a.access.key", "access_key")
sparkSession.sparkContext.hadoopConfiguration.set("fs.s3a.secret.key", "secret")
sparkSession.sparkContext.hadoopConfiguration.set("fs.s3a.path.style.access", "true")
sparkSession.sparkContext.hadoopConfiguration.set("fs.s3a.connection.ssl.enabled", "false")
sparkSession.sparkContext.hadoopConfiguration.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
这是为最小配置设置的属性的含义:
-
fs.s3a.endpoint:S3 或 Minio 端点。 -
fs.s3a.access.key:AWS 或 Minio 访问密钥 ID。 -
fs.s3a.secret.key:AWS 或 Minio 秘密密钥。 -
fs.s3a.path.style.access:启用 S3 路径风格访问,同时禁用默认的虚拟主机行为。 -
fs.s3a.connection.ssl.enabled:指定是否在端点启用了 SSL。可能的值是true和false。 -
fs.s3a.impl:所使用的S3AFileSystem实现类。
现在我们已经准备好从 S3 或 Minio 存储桶中读取access_log文件(或任何其他文件),并将其内容加载到 RDD 中,如下所示:
val logDataRdd = sparkSession.sparkContext.textFile("s3a://dl4j-bucket/access_log")
println("RDD size is " + logDataRdd.count)
还可以将 RDD 转换为 DataFrame,并按如下方式显示输出内容:
import sparkSession.implicits._
val logDataDf = logDataRdd.toDF
logDataDf.show(10, false)
这将提供以下输出:
一旦从存储在 S3 或 Minio 桶中的对象加载数据,就可以使用 Spark 对 RDD 和数据集的任何操作。
使用 Spark 进行原始数据转换
数据来自一个来源时,通常是原始数据。当我们谈论原始数据时,指的是那些无法直接用于训练或测试模型的数据格式。因此,在使用之前,我们需要将其整理。清理过程通过一个或多个转换步骤完成,才能将数据作为输入提供给特定的模型。
为了数据转换的目的,DL4J 的 DataVec 库和 Spark 提供了多种功能。此部分描述的一些概念已在通过 DataVec 进行数据摄取并通过 Spark 进行转换部分中探讨过,但现在我们将添加一个更复杂的使用案例。
为了理解如何使用 Datavec 进行数据转换,我们来构建一个用于网站流量日志分析的 Spark 应用程序。所使用的数据集可以从 MonitorWare 网站下载(www.monitorware.com/en/logsamples/apache.php)。这些数据是 ASCII 格式的 HTTP 请求日志条目,每个请求一行,包含以下列:
-
发出请求的主机。可以是主机名或互联网地址
-
一个时间戳,格式为DD/Mon/YYYY:HH:MM:SS,其中DD是日,Mon是月的名称,YYYY是年份,HH:MM:SS是使用 24 小时制的时间。时区为-0800
-
引号中的 HTTP 请求
-
HTTP 回复代码
-
回复中的字节总数
这是一个示例日志内容:
64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1" 401 12846
64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523
64.242.88.10 - - [07/Mar/2004:16:10:02 -0800] "GET /mailman/listinfo/hsdivision HTTP/1.1" 200 6291
64.242.88.10 - - [07/Mar/2004:16:11:58 -0800] "GET /twiki/bin/view/TWiki/WikiSyntax HTTP/1.1" 200 7352
在我们的应用程序中,首先要做的是定义输入数据的模式,如下所示:
val schema = new Schema.Builder()
.addColumnString("host")
.addColumnString("timestamp")
.addColumnString("request")
.addColumnInteger("httpReplyCode")
.addColumnInteger("replyBytes")
.build
启动一个 Spark 上下文,如下所示:
val conf = new SparkConf
conf.setMaster("local[*]")
conf.setAppName("DataVec Log Analysis Example")
val sc = new JavaSparkContext(conf)
加载文件,如下所示:
val directory = new ClassPathResource("access_log").getFile.getAbsolutePath
一个网页日志文件可能包含一些无效的行,这些行不符合前述的模式,因此我们需要加入一些逻辑来丢弃那些对我们的分析没有用的行,例如:
var logLines = sc.textFile(directory)
logLines = logLines.filter { (s: String) =>
s.matches("(\\S+) - - \\[(\\S+ -\\d{4})\\] \"(.+)\" (\\d+) (\\d+|-)")
}
我们应用正则表达式来过滤出符合预期格式的日志行。现在我们可以开始使用 DataVec 的RegexLineRecordReader(deeplearning4j.org/datavecdoc/org/datavec/api/records/reader/impl/regex/RegexLineRecordReader.html)来解析原始数据。我们需要定义一个regex来格式化这些行,如下所示:
val regex = "(\\S+) - - \\[(\\S+ -\\d{4})\\] \"(.+)\" (\\d+) (\\d+|-)"
val rr = new RegexLineRecordReader(regex, 0)
val parsed = logLines.map(new StringToWritablesFunction(rr))
通过 DataVec-Spark 库,还可以在定义转换之前检查数据质量。我们可以使用AnalyzeSpark(deeplearning4j.org/datavecdoc/org/datavec/spark/transform/AnalyzeSpark.html)类来实现这一目的,如下所示:
val dqa = AnalyzeSpark.analyzeQuality(schema, parsed)
println("----- Data Quality -----")
println(dqa)
以下是数据质量分析产生的输出:
----- Data Quality -----
idx name type quality details
0 "host" String ok StringQuality(countValid=1546, countInvalid=0, countMissing=0, countTotal=1546, countEmptyString=0, countAlphabetic=0, countNumerical=0, countWordCharacter=10, countWhitespace=0, countApproxUnique=170)
1 "timestamp" String ok StringQuality(countValid=1546, countInvalid=0, countMissing=0, countTotal=1546, countEmptyString=0, countAlphabetic=0, countNumerical=0, countWordCharacter=0, countWhitespace=0, countApproxUnique=1057)
2 "request" String ok StringQuality(countValid=1546, countInvalid=0, countMissing=0, countTotal=1546, countEmptyString=0, countAlphabetic=0, countNumerical=0, countWordCharacter=0, countWhitespace=0, countApproxUnique=700)
3 "httpReplyCode" Integer ok IntegerQuality(countValid=1546, countInvalid=0, countMissing=0, countTotal=1546, countNonInteger=0)
4 "replyBytes" Integer FAIL IntegerQuality(countValid=1407, countInvalid=139, countMissing=0, countTotal=1546, countNonInteger=139)
从中我们注意到,在139行(共1546行)中,replyBytes字段并不是预期的整数类型。以下是其中几行:
10.0.0.153 - - [12/Mar/2004:11:01:26 -0800] "GET / HTTP/1.1" 304 -
10.0.0.153 - - [12/Mar/2004:12:23:11 -0800] "GET / HTTP/1.1" 304 -
因此,第一个要进行的转换是清理replyBytes字段,将所有非整数条目替换为0。我们使用TransformProcess类,方法与通过 DataVec 进行数据摄取和通过 Spark 进行转换部分中的示例相同,如下所示:
val tp: TransformProcess = new TransformProcess.Builder(schema)
.conditionalReplaceValueTransform("replyBytes", new IntWritable(0), new StringRegexColumnCondition("replyBytes", "\\D+"))
然后,我们可以应用其他任何转换,例如按主机分组并提取汇总指标(计算条目数量、计算唯一请求和 HTTP 回复代码的数量、对replyBytes字段的值求和);例如:
.reduce(new Reducer.Builder(ReduceOp.CountUnique)
.keyColumns("host")
.countColumns("timestamp")
.countUniqueColumns("request", "httpReplyCode")
.sumColumns("replyBytes")
.build
)
重命名若干列,如下所示:
.renameColumn("count", "numRequests")
筛选出所有请求的字节总数少于 100 万的主机,如下所示:
.filter(new ConditionFilter(new LongColumnCondition("sum(replyBytes)", ConditionOp.LessThan, 1000000)))
.build
我们现在可以执行转换,如下所示:
val processed = SparkTransformExecutor.execute(parsed, tp)
processed.cache
我们还可以对最终数据进行一些分析,如下所示:
val finalDataSchema = tp.getFinalSchema
val finalDataCount = processed.count
val sample = processed.take(10)
val analysis = AnalyzeSpark.analyze(finalDataSchema, processed)
最终数据模式如下所示:
idx name type meta data
0 "host" String StringMetaData(name="host",)
1 "count(timestamp)" Long LongMetaData(name="count(timestamp)",minAllowed=0)
2 "countunique(request)" Long LongMetaData(name="countunique(request)",minAllowed=0)
3 "countunique(httpReplyCode)" Long LongMetaData(name="countunique(httpReplyCode)",minAllowed=0)
4 "sum(replyBytes)" Integer IntegerMetaData(name="sum(replyBytes)",)
以下显示结果计数为二:
[10.0.0.153, 270, 43, 3, 1200145]
[64.242.88.10, 452, 451, 2, 5745035]
以下代码显示了分析结果:
----- Analysis -----
idx name type analysis
0 "host" String StringAnalysis(minLen=10,maxLen=12,meanLen=11.0,sampleStDevLen=1.4142135623730951,sampleVarianceLen=2.0,count=2)
1 "count(timestamp)" Long LongAnalysis(min=270,max=452,mean=361.0,sampleStDev=128.69343417595164,sampleVariance=16562.0,countZero=0,countNegative=0,countPositive=2,countMinValue=1,countMaxValue=1,count=2)
2 "countunique(request)" Long LongAnalysis(min=43,max=451,mean=247.0,sampleStDev=288.4995667241114,sampleVariance=83232.0,countZero=0,countNegative=0,countPositive=2,countMinValue=1,countMaxValue=1,count=2)
3 "countunique(httpReplyCode)" Long LongAnalysis(min=2,max=3,mean=2.5,sampleStDev=0.7071067811865476,sampleVariance=0.5,countZero=0,countNegative=0,countPositive=2,countMinValue=1,countMaxValue=1,count=2)
4 "sum(replyBytes)" Integer IntegerAnalysis(min=1200145,max=5745035,mean=3472590.0,sampleStDev=3213722.538746928,sampleVariance=1.032801255605E13,countZero=0,countNegative=0,countPositive=2,countMinValue=1,countMaxValue=1,count=2)
摘要
本章探讨了通过 DeepLearning4j DataVec 库和 Apache Spark(核心模块和 Spark SQL 模块)框架从文件、关系型数据库、NoSQL 数据库和基于 S3 的对象存储系统摄取数据的不同方式,并展示了一些如何转换原始数据的示例。所有呈现的示例代表了批处理方式的数据摄取和转换。
下一章将专注于摄取和转换数据,以在流模式下训练或测试您的 DL 模型。
第四章:流处理
在上一章中,我们学习了如何使用批量 ETL 方法摄取和转换数据,以训练或评估模型。在大多数情况下,你会在训练或评估阶段使用这种方法,但在运行模型时,需要使用流式摄取。本章将介绍使用 Apache Spark、DL4J、DataVec 和 Apache Kafka 框架组合来设置流式摄取策略。与传统 ETL 方法不同,流式摄取框架不仅仅是将数据从源移动到目标。通过流式摄取,任何格式的进入数据都可以被同时摄取、转换和/或与其他结构化数据和先前存储的数据一起丰富,以供深度学习使用。
本章将涵盖以下主题:
-
使用 Apache Spark 进行流数据处理
-
使用 Kafka 和 Apache Spark 进行流数据处理
-
使用 DL4J 和 Apache Spark 进行流数据处理
使用 Apache Spark 进行流数据处理
在第一章《Apache Spark 生态系统》中,详细介绍了 Spark Streaming 和 DStreams。结构化流处理作为 Apache Spark 2.0.0 的 Alpha 版本首次推出,它最终从 Spark 2.2.0 开始稳定。
结构化流处理(基于 Spark SQL 引擎构建)是一个容错、可扩展的流处理引擎。流处理可以像批量计算一样进行,也就是说,在静态数据上进行计算,我们在第一章《Apache Spark 生态系统》中已经介绍过。正是 Spark SQL 引擎负责增量地和持续地运行计算,并在数据持续流入时最终更新结果。在这种情况下,端到端、精确一次和容错的保证是通过预写日志(WAL)和检查点实现的。
传统的 Spark Streaming 和结构化流处理编程模型之间的差异,有时不容易理解,尤其是对于第一次接触这个概念的有经验的 Spark 开发者来说。描述这种差异的最好方式是:你可以把它当作一种处理实时数据流的方式,将其看作一个持续追加的表(表可以被视为一个 RDBMS)。流计算被表达为一个标准的类批量查询(就像在静态表上发生的那样),但是 Spark 对这个无界表进行增量计算。
它的工作原理如下:输入数据流可以看作是输入表。每个到达数据流的数据项就像是向表中追加了一行新数据:
图 4.1:作为无界表的数据流
针对输入的查询会生成结果表。每次触发时,新的间隔行会追加到输入表中,然后更新结果表(如下图所示)。每当结果表更新时,更改后的结果行可以写入外部接收器。写入外部存储的输出有不同的模式:
-
完整模式:在这种模式下,整个更新后的结果表会被写入外部存储。如何将整个表写入存储系统取决于特定的连接器配置或实现。
-
追加模式:只有追加到结果表中的新行会被写入外部存储系统。这意味着可以在结果表中的现有行不期望更改的情况下应用此模式。
-
更新模式:只有在结果表中更新过的行会被写入外部存储系统。这种模式与完整模式的区别在于,它仅发送自上次触发以来发生变化的行:
图 4.2:结构化流处理的编程模型
现在,让我们实现一个简单的 Scala 示例——一个流式单词计数自包含应用程序,这是我们在第一章中使用的相同用例,Apache Spark 生态系统,但这次是针对结构化流处理。用于此类的代码可以在与 Spark 发行版捆绑的示例中找到。我们首先需要做的是初始化一个SparkSession:
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.master(master)
.getOrCreate()
然后,我们必须创建一个表示从连接到host:port的输入行流的 DataFrame:
val lines = spark.readStream
.format("socket")
.option("host", host)
.option("port", port)
.load()
lines DataFrame 表示无界表格。它包含流式文本数据。该表的内容是一个值,即一个包含字符串的单列。每一行流入的文本都会成为一行数据。
让我们将行拆分为单词:
val words = lines.as[String].flatMap(_.split(" "))
然后,我们需要统计单词数量:
val wordCounts = words.groupBy("value").count()
最后,我们可以开始运行查询,将运行计数打印到控制台:
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
我们会继续运行,直到接收到终止信号:
query.awaitTermination()
在运行此示例之前,首先需要运行 netcat 作为数据服务器(或者我们在第一章中用 Scala 实现的数据服务器,Apache Spark 生态系统):
nc -lk 9999
然后,在另一个终端中,你可以通过传递以下参数来启动示例:
localhost 9999
在运行 netcat 服务器时,终端中输入的任何一行都会被计数并打印到应用程序屏幕上。将会出现如下输出:
hello spark
a stream
hands on spark
这将产生以下输出:
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
| hello| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
| hello| 1|
| spark| 1|
| a| 1|
|stream| 1|
+------+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
| hello| 1|
| spark| 2|
| a| 1|
|stream| 1|
| hands| 1|
| on| 1|
+------+-----+
事件时间定义为数据本身所嵌入的时间。在许多应用场景中,例如物联网(IoT)环境,当每分钟设备生成的事件数量需要被检索时,必须使用数据生成的时间,而不是 Spark 接收到它的时间。在这种编程模型中,事件时间自然地被表达——每个来自设备的事件就是表中的一行,而事件时间是该行中的列值。这种范式使得基于窗口的聚合成为对事件时间列的特殊聚合类型。这样可以保证一致性,因为基于事件时间和基于窗口的聚合查询可以在静态数据集(例如设备事件日志)和流式数据上以相同方式进行定义。
根据前面的考虑,显而易见,这种编程模型自然地处理了基于事件时间的数据,这些数据可能比预期的到达时间晚。由于是 Spark 本身更新结果表,因此它可以完全控制在有迟到数据时如何更新旧的聚合,以及通过清理旧的聚合来限制中间数据的大小。从 Spark 2.1 开始,还支持水印(watermarking),它允许你指定迟到数据的阈值,并允许底层引擎相应地清理旧状态。
使用 Kafka 和 Spark 进行流式数据处理
使用 Spark Streaming 与 Kafka 是数据管道中常见的技术组合。本节将展示一些使用 Spark 流式处理 Kafka 的示例。
Apache Kafka
Apache Kafka (kafka.apache.org/) 是一个用 Scala 编写的开源消息代理。最初由 LinkedIn 开发,但它于 2011 年作为开源发布,目前由 Apache 软件基金会维护。
以下是你可能更倾向于使用 Kafka 而不是传统 JMS 消息代理的一些原因:
-
它很快:单个运行在普通硬件上的 Kafka 代理能够处理来自成千上万客户端的每秒数百兆字节的读写操作
-
出色的可扩展性:可以轻松且透明地进行扩展,且不会产生停机时间
-
持久性与复制:消息会被持久化存储在磁盘上,并在集群内进行复制,以防止数据丢失(通过设置适当的配置参数,你可以实现零数据丢失)
-
性能:每个代理能够处理数 TB 的消息而不会影响性能
-
它支持实时流处理
-
它可以轻松与其他流行的开源大数据架构系统(如 Hadoop、Spark 和 Storm)进行集成
以下是你应该熟悉的 Kafka 核心概念:
-
主题:这些是发布即将到来的消息的类别或源名称
-
生产者:任何发布消息到主题的实体
-
消费者:任何订阅主题并从中消费消息的实体
-
Broker:处理读写操作的服务
下图展示了典型的 Kafka 集群架构:
图 4.3:Kafka 架构
Kafka 在后台使用 ZooKeeper (zookeeper.apache.org/) 来保持其节点的同步。Kafka 提供了 ZooKeeper,因此如果主机没有安装 ZooKeeper,可以使用随 Kafka 捆绑提供的 ZooKeeper。客户端和服务器之间的通信通过一种高性能、语言无关的 TCP 协议进行。
Kafka 的典型使用场景如下:
-
消息传递
-
流处理
-
日志聚合
-
指标
-
网站活动跟踪
-
事件溯源
Spark Streaming 和 Kafka
要将 Spark Streaming 与 Kafka 配合使用,您可以做两件事:要么使用接收器,要么直接操作。第一种选择类似于从其他来源(如文本文件和套接字)进行流式传输——从 Kafka 接收到的数据会存储在 Spark 执行器中,并通过 Spark Streaming 上下文启动的作业进行处理。这不是最佳方法——如果发生故障,可能会导致数据丢失。这意味着,直接方式(在 Spark 1.3 中引入)更好。它不是使用接收器来接收数据,而是定期查询 Kafka 以获取每个主题和分区的最新偏移量,并相应地定义每个批次处理的偏移量范围。当处理数据的作业执行时,Kafka 的简单消费者 API 会被用来读取定义的偏移量范围(几乎与从文件系统读取文件的方式相同)。直接方式带来了以下优点:
-
简化的并行性:不需要创建多个输入 Kafka 流然后努力将它们统一起来。Spark Streaming 会根据 Kafka 分区的数量创建相应数量的 RDD 分区,这些分区会并行地从 Kafka 读取数据。这意味着 Kafka 和 RDD 分区之间是 1:1 映射,易于理解和调整。
-
提高效率:按照接收器方式,为了实现零数据丢失,我们需要将数据存储在 WAL 中。然而,这种策略效率低,因为数据实际上被 Kafka 和 WAL 各自复制了一次。在直接方式中,没有接收器,因此也不需要 WAL——消息可以从 Kafka 中恢复,只要 Kafka 保留足够的时间。
-
精确一次语义:接收器方法使用 Kafka 的高级 API 将消费的偏移量存储在 ZooKeeper 中。尽管这种方法(结合 WAL)可以确保零数据丢失,但在发生故障时,某些记录可能会被重复消费,这有一定的可能性。数据被 Spark Streaming 可靠接收和 ZooKeeper 跟踪的偏移量之间的不一致导致了这一点。采用直接方法时,简单的 Kafka API 不使用 ZooKeeper——偏移量由 Spark Streaming 本身在其检查点内进行跟踪。这确保了即使在发生故障时,每条记录也能被 Spark Streaming 确切地接收一次。
直接方法的一个缺点是它不更新 ZooKeeper 中的偏移量——这意味着基于 ZooKeeper 的 Kafka 监控工具将不会显示任何进度。
现在,让我们实现一个简单的 Scala 示例——一个 Kafka 直接词频统计。该示例适用于 Kafka 版本 0.10.0.0 或更高版本。首先要做的是将所需的依赖项(Spark Core、Spark Streaming 和 Spark Streaming Kafka)添加到项目中:
groupId = org.apache.spark
artifactId = spark-core_2.11
version = 2.2.1
groupId = org.apache.spark
artifactId = spark-streaming_2.11
version = 2.2.1
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-10_2.11
version = 2.2.1
此应用程序需要两个参数:
-
一个以逗号分隔的 Kafka 经纪人列表
-
一个以逗号分隔的 Kafka 主题列表,用于消费:
val Array(brokers, topics) = args
我们需要创建 Spark Streaming 上下文。让我们选择一个 5 秒的批次间隔:
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount").setMaster(master)
val ssc = new StreamingContext(sparkConf, Seconds(5))
现在,让我们创建一个包含给定经纪人和主题的直接 Kafka 流:
val topicsSet = topics.split(",").toSet
val kafkaParams = MapString, String
val messages = KafkaUtils.createDirectStreamString, String, StringDecoder, StringDecoder
我们现在可以实现词频统计,也就是从流中获取行,将其拆分成单词,统计单词数量,然后打印:
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
最后,让我们启动计算并保持其运行,等待终止信号:
ssc.start()
ssc.awaitTermination()
要运行此示例,首先需要启动一个 Kafka 集群并创建一个主题。Kafka 的二进制文件可以从官方网站下载(kafka.apache.org/downloads)。下载完成后,我们可以按照以下指示操作。
首先启动一个 zookeeper 节点:
$KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
它将开始监听默认端口,2181。
然后,启动一个 Kafka 经纪人:
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
它将开始监听默认端口,9092。
创建一个名为 packttopic 的主题:
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic packttopic
检查主题是否已成功创建:
$KAFKA_HOME/bin/kafka-topics.sh --list --zookeeper localhost:2181
主题名称 packttopic 应该出现在打印到控制台输出的列表中。
我们现在可以开始为新主题生成消息了。让我们启动一个命令行生产者:
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic packttopic
在这里,我们可以向生产者控制台写入一些消息:
First message
Second message
Third message
Yet another message for the message consumer
让我们构建 Spark 应用程序,并通过 $SPARK_HOME/bin/spark-submit 命令执行,指定 JAR 文件名、Spark 主 URL、作业名称、主类名称、每个执行器使用的最大内存和作业参数(localhost:9092 和 packttopic)。
每条被 Spark 作业消费的消息行输出将类似于以下内容:
-------------------------------------------
Time: 1527457655000 ms
-------------------------------------------
(consumer,1)
(Yet,1)
(another,1)
(message,2)
(for,1)
(the,1)
使用 DL4J 和 Spark 流式处理数据
在本节中,我们将应用 Kafka 和 Spark 进行数据流处理,以 DL4J 应用程序的使用情况场景为例。我们将使用的 DL4J 模块是 DataVec。
让我们考虑我们在Spark Streaming 和 Kafka部分中提出的示例。我们想要实现的是使用 Spark 进行直接 Kafka 流,并在数据到达后立即对其应用 DataVec 转换,然后在下游使用它。
让我们首先定义输入模式。这是我们从 Kafka 主题消费的消息所期望的模式。该模式结构与经典的Iris数据集(en.wikipedia.org/wiki/Iris_flower_data_set)相同:
val inputDataSchema = new Schema.Builder()
.addColumnsDouble("Sepal length", "Sepal width", "Petal length", "Petal width")
.addColumnInteger("Species")
.build
让我们对其进行转换(我们将删除花瓣字段,因为我们将基于萼片特征进行一些分析):
val tp = new TransformProcess.Builder(inputDataSchema)
.removeColumns("Petal length", "Petal width")
.build
现在,我们可以生成新的模式(在对数据应用转换之后):
val outputSchema = tp.getFinalSchema
此 Scala 应用程序的下一部分与Spark Streaming 和 Kafka部分中的示例完全相同。在这里,创建一个流上下文,使用5秒的批处理间隔和直接的 Kafka 流:
val sparkConf = new SparkConf().setAppName("DirectKafkaDataVec").setMaster(master)
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topicsSet = topics.split(",").toSet
val kafkaParams = MapString, String
val messages = KafkaUtils.createDirectStreamString, String, StringDecoder, StringDecoder
让我们获取输入行:
val lines = messages.map(_._2)
lines是一个DStream[String]。我们需要对每个 RDD 进行迭代,将其转换为javaRdd(DataVec 读取器所需),使用 DataVec 的CSVRecordReader,解析传入的逗号分隔消息,应用模式转换,并打印结果数据:
lines.foreachRDD { rdd =>
val javaRdd = rdd.toJavaRDD()
val rr = new CSVRecordReader
val parsedInputData = javaRdd.map(new StringToWritablesFunction(rr))
if(!parsedInputData.isEmpty()) {
val processedData = SparkTransformExecutor.execute(parsedInputData, tp)
val processedAsString = processedData.map(new WritablesToStringFunction(","))
val processedCollected = processedAsString.collect
val inputDataCollected = javaRdd.collect
println("\n\n---- Original Data ----")
for (s <- inputDataCollected.asScala) println(s)
println("\n\n---- Processed Data ----")
for (s <- processedCollected.asScala) println(s)
}
}
最后,我们启动流上下文并保持其活动状态,等待终止信号:
ssc.start()
ssc.awaitTermination()
要运行此示例,我们需要启动一个 Kafka 集群,并创建一个名为csvtopic的新主题。步骤与Spark Streaming 和 Kafka部分描述的示例相同。主题创建完成后,我们可以开始在其上生产逗号分隔的消息。让我们启动一个命令行生产者:
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic csvtopic
现在,我们可以将一些消息写入生产者控制台:
5.1,3.5,1.4,0.2,0
4.9,3.0,1.4,0.2,0
4.7,3.2,1.3,0.2,0
4.6,3.1,1.5,0.2,0
让我们构建 Spark 应用程序,并通过$SPARK_HOME/bin/spark-submit命令执行它,指定 JAR 文件名、Spark 主 URL、作业名称、主类名、每个执行程序可使用的最大内存以及作业参数(localhost:9092和csvtopic)。
每消费一行消息后,Spark 作业打印的输出将类似于以下内容:
4.6,3.1,1.5,0.2,0
---- Processed Data ----
4.6,3.1,0
此示例的完整代码可以在本书捆绑的源代码中找到,链接为github.com/PacktPublishing/Hands-On-Deep-Learning-with-Apache-Spark。
概要
为了完成我们在第三章中探索之后在训练、评估和运行深度学习模型时的数据摄入可能性的概述,提取、转换、加载,在本章中,我们探讨了在执行数据流处理时可用的不同选项。
本章总结了对 Apache Spark 特性的探讨。从下一章开始,重点将转向 DL4J 和其他一些深度学习框架的特性。这些特性将在不同的应用场景中使用,并将在 Spark 上进行实现。

















 4
4

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}