






 本文介绍了Hadoop的定义、发行版本及其优缺点。重点讲述了Hadoop的组成部分,包括HDFS、YARN和MapReduce。文章还讨论了Hadoop 1.x到2.x及2.x到3.x的主要变化,并概述了大数据技术生态系统中的关键组件,如Sqoop、Flume、Kafka、Storm、Spark、Oozie、Hbase、Hive、R语言和Mahout。
本文介绍了Hadoop的定义、发行版本及其优缺点。重点讲述了Hadoop的组成部分,包括HDFS、YARN和MapReduce。文章还讨论了Hadoop 1.x到2.x及2.x到3.x的主要变化,并概述了大数据技术生态系统中的关键组件,如Sqoop、Flume、Kafka、Storm、Spark、Oozie、Hbase、Hive、R语言和Mahout。
原文链接: Hadoop(一、Hadoop与大数据生态).
1、Hadoop是什么

2、Hadoop发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好(目前我所学习的版本)。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
其他的发行版本 :
-
Apache hadoop http://hadoop.apache.org/
-
Cloudera hadoop(CDH) https://www.cloudera.com/
-
Hortonworks hadoop(HDP) https://hortonworks.com
-
MapR https://mapr.com/
-
fusionInsight hadoop (华为大数据平台hadoop) http://carrier.huawei.com/cn/products/IT/cloud-computing/fusioninsight
-
Transwarp Data Hub (TDH 星环大数据平台) http://www.transwarp.cn/
-
Isilon (EMC hadoop)
-
biginsights (IBM hadoop)
3、Hadoop的优缺点
Hadoop的优点

Hadoop的缺点
1、Hadoop不适用于低延迟数据访问。
2、Hadoop不能高效存储大量小文件。
3、Hadoop不支持多用户写入并任意修改文件。
4、Hadoop 组成
1. HDFS(Hadoop Distributed File System): 分布式文件系统
HDFS架构概述

2. YARN(Yet Another Resource Negotiator): 资源管理调度系统
YARN架构概述
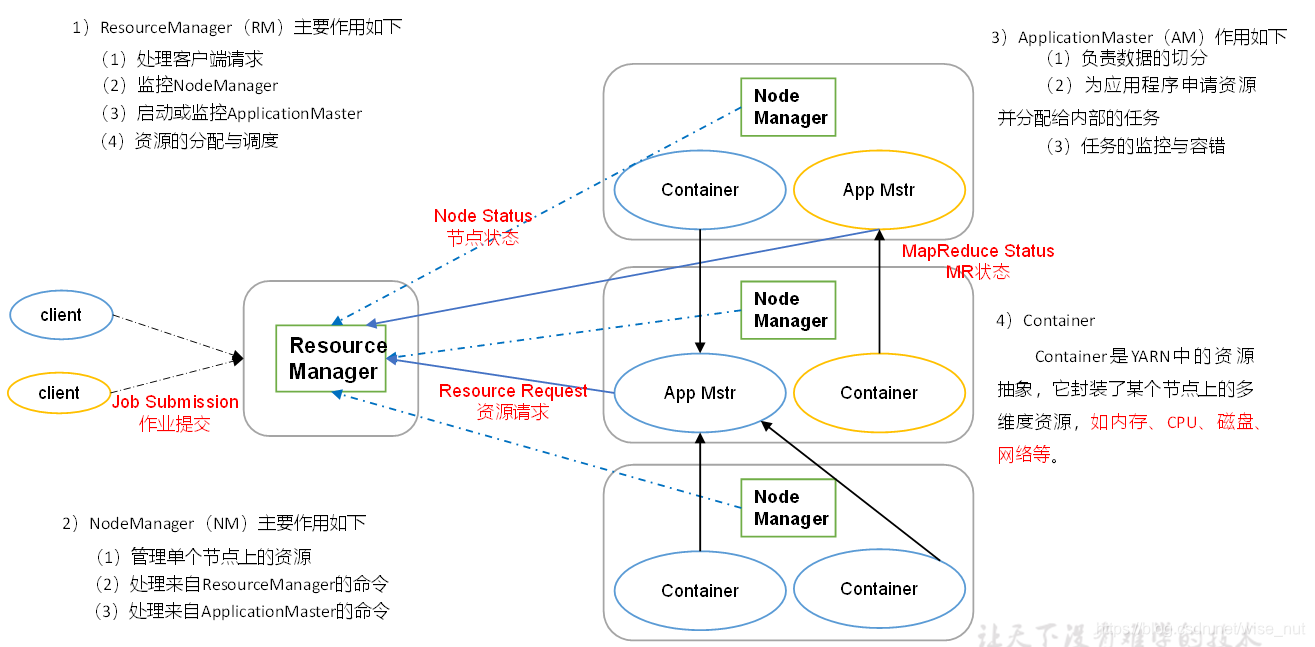
3. MapReduce:分布式运算框架
MapReduce架构概述
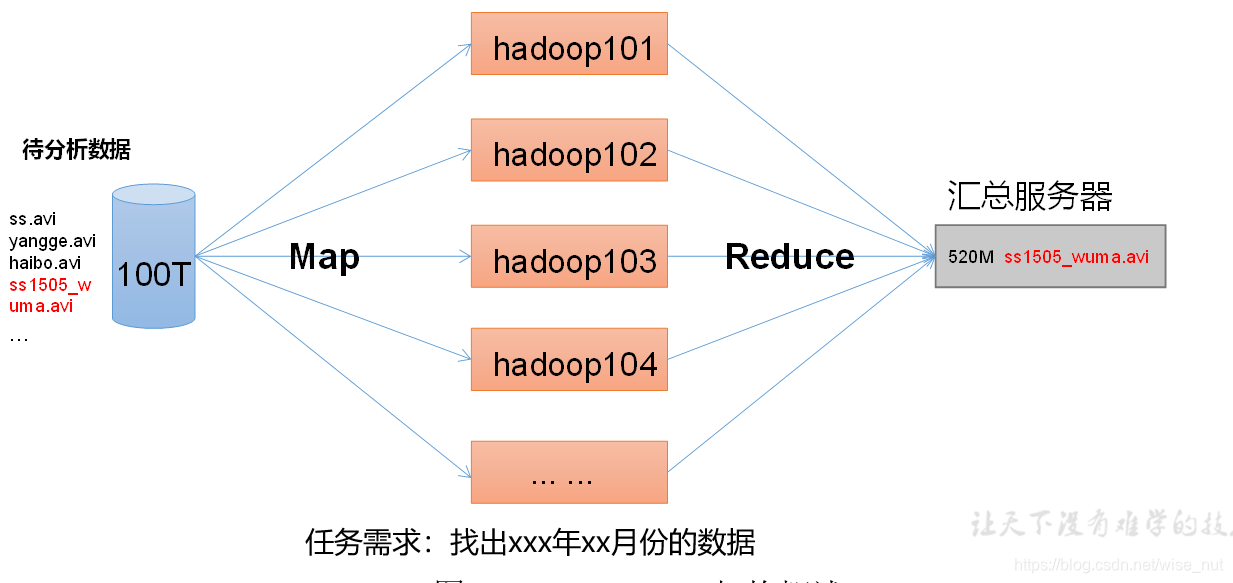
MapReduce将计算过程分为两个阶段:Map和Reduce,如图所示
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
5、Hadoop各版本区别(1.x、2.x、3.x版本)
链接: link.
目前工作中还是以Hadoop 2.0为主。
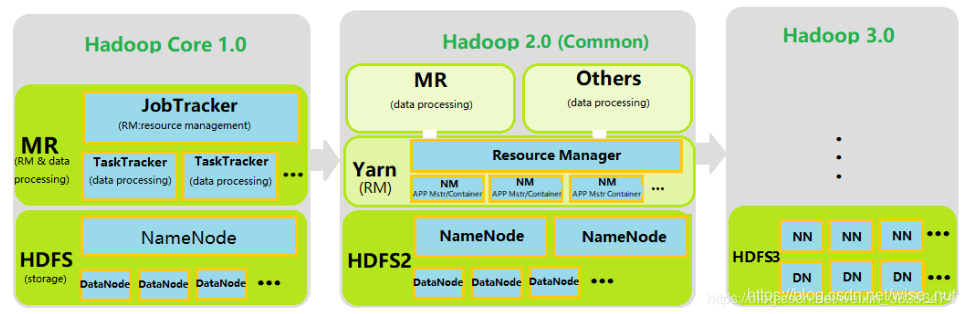
1.x 与 2.x :
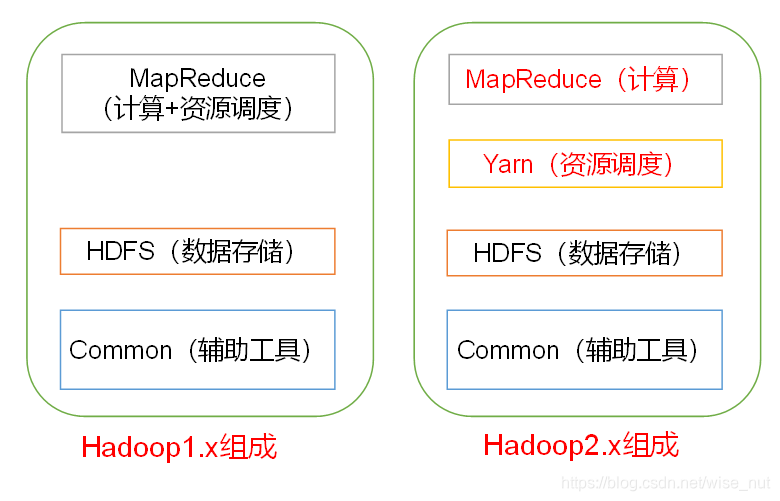
从M apReduce 角度来看:
-
Hadoop 1.x 时代,Hadoop中的MapReduce同时处理 业务逻辑运算 和 资源调度 :
由一个JobTracker和若干个TaskTracker两类服务组成,其中JobTracker负责资源管理和所有作业的控制,TaskTracker负责接收来自JobTracker的命令并执行它。所以MapReduce即是任务调度框架又是计算框架,Hadoop 1.x中会出现JobTracker大包大揽任务过重,而且存在单点故障问题,并且容易出现OOM (OutOfMemory) 内存溢出问题,资源分配不合理等问题。 -
Hadoop 2.x 时代,增加了Yarn只负责资源调度,MapReduce 只负责运算。
MASTER端由ResourceManager进行资源管理调度,有ApplicationMaster进行任务管理和任务监控。SLAVE端由NodeManager替代TaskTracker进行具体任务的执行,所以MapReduce 2.x只是一个计算框架,具体资源调度全部交给Yarn框架。
从 HDFS 角度来看:
4. Hadoop 2.x新增了HDFS HA机制,HA增加了standbynamenode进行热备份,解决了 Hadoop 1.x的单点故障问题。
5. Hadoop 2.x新增了HDFS federation,解决了HDFS水平可扩展能力。
允许有多个namenode独立运行组成联邦。每个datanode向所有name进行注册。
每个namenode维护一个命名空间卷(互相独立)上层通过一个挂载表组织来访问数据。
命名空间卷: 包括池块和命名空间元数据
块池: 逻辑概念,该命名空间文件的所有块;可能在不同机器上。
命名空间元数据: 命名空间元数据
2.x 与 3.x
Hadoop 2.x和Hadoop 3.x之间的主要区别在于新版本提供了更好的优化和可用性,以及某些体系结构改进。
HDFS改进:
支持erasure编码
支持超过两个namenode
数据均衡
多个服务端口发生变化
JDK版本的最低依赖从1.7变成了1.8
具体不同参考:链接: 大数据Hadoop2.x与Hadoop3.x相比较有哪些变化.
6、大数据技术生态体系
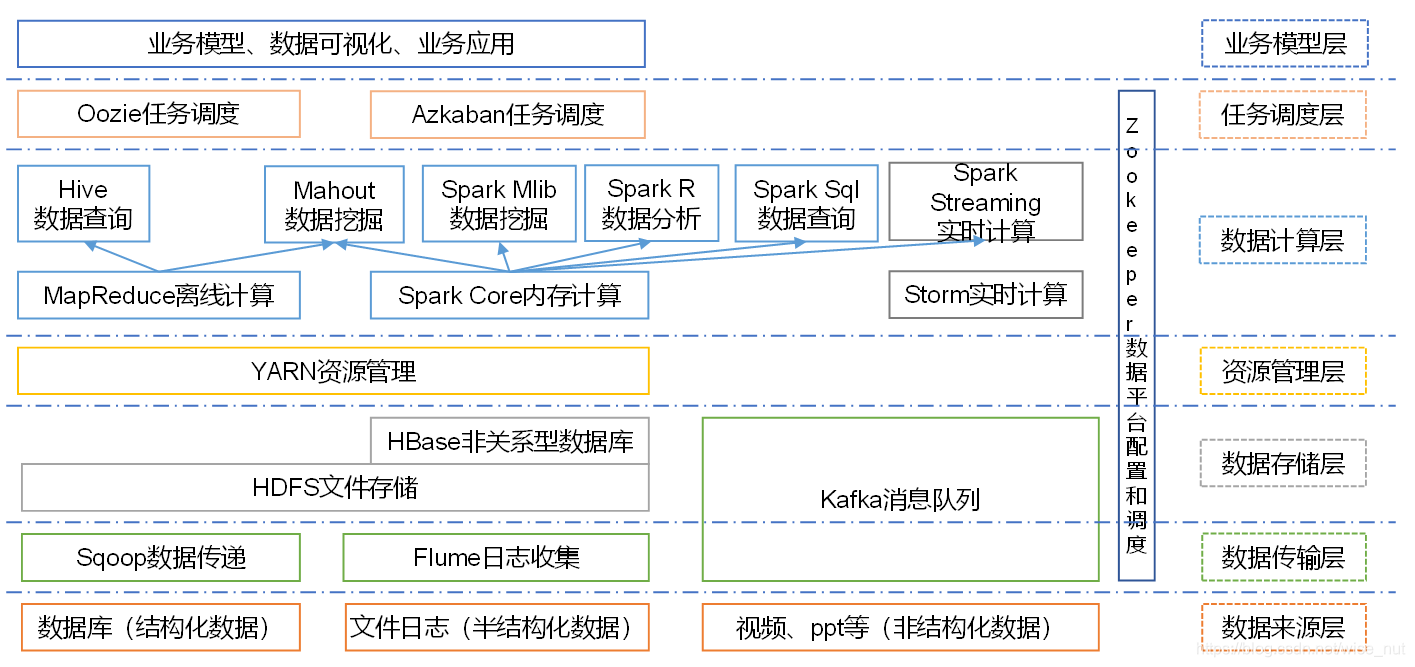
图中涉及的技术名词解释如下:
- Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
- Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。 - Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
- Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
- Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
- Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
- Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
- ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
7、大数据推荐系统框架图
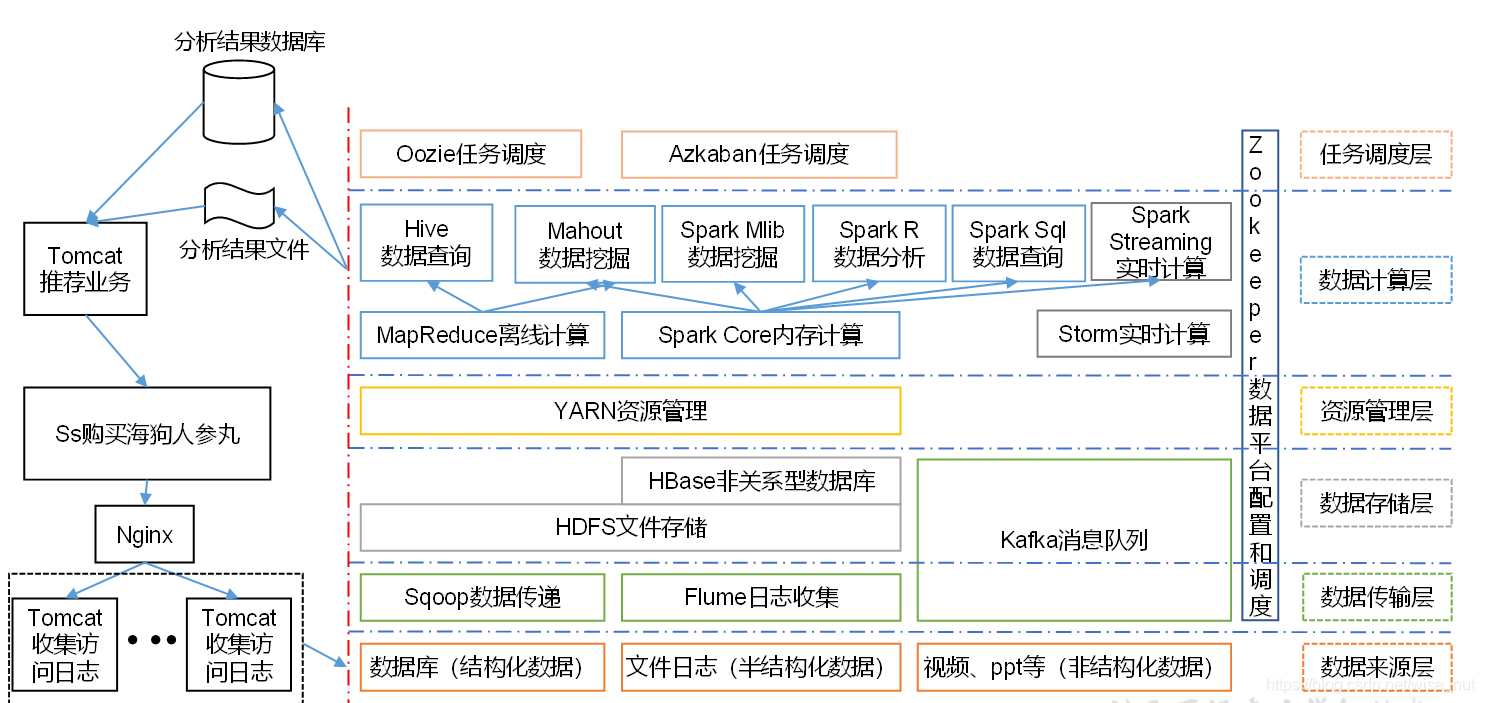
参考链接:
链接: 尚硅谷Hadoop教程(hadoop框架精讲).

















 2134
2134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









