database/sql包
初始化
database/sql标准库提供了用于处理sql相关的操作的接口,而接口的实现则交给了数据库驱动
- 好处在于写代码逻辑的时候,不用考虑后端的具体数据库,即使迁移数据库类型的时候,也只需要迁移相应的驱动即可,而不用修改代码
- 使用数据库时,除了
database/sql包本身,必须要引入想使用的特定数据库驱动
database/sql的职责
- 通过驱动程序打开和关闭实际的底层数据库的连接
- 管理一个连接池
sql.Open()不建立与数据库的任何连接,也不会验证驱动连接参数,它只是准备数据库抽象以供以后使用
- 首次真正的连接数据库将在第一次需要时惰性建立
- 如果你想立即检查数据库是否可用(例如,是否可以建立网络连接、是否有权限登陆),请使用
db.Ping()来执行此操作
sql.DB表示数据库抽象, 被设计为长期存在的对象
- 不要经常
Open()和Close()数据库对象 - 应该在需要是把
sql.DB对象作为参数,或赋值给全局变量
连接池配置
db.SetMaxOpenConns(n int) 设置打开数据库的最大连接数
- 包括正在使用的连接和连接池中空闲的连接
- 如果申请一个连接时连接池已经没有了连接或者连接数达到了最大连接数,该调用将会被block,直到有可用的连接才会返回
- 设置这个值可以避免并发太高导致出现
too many connections的错误 - 该函数的默认设置是0,表示无限制
db.SetMaxIdleConns(n int)设置连接池中保持的的最大空闲连接数
- 默认设置是0,表示连接池不会保持连接状态
- 即当连接释放回到连接池的时候,连接将会被关闭
- 保持空闲连接的存活会占用一定内存
MaxIdleConns应该始终小于或等于MaxOpenConns
- 更多的空闲连接数是没有意义的,因为最多也就能拿到所有打开的连接,剩余的空闲连接依然保持的空闲
db.SetConnMaxLifetime(t time.Duration) 设置连接被复用的最大时间
- 注意并不是连接空闲时间,而是从连接建立开始的时间
- 超过时限后连接就会被强制回收,目的是保证连接活性
db.SetConnMaxIdleTime(t time.Duration) 设置空闲连接保持的最大时间
MySQL 侧会强制kill掉长时间空闲的连接
- 因此该时间必须小于
wait_timeout,否则可能拿到的连接是无效的
sql.DB会将自动重试2次坏连接,之后将从池中删除坏连接并创建新连接

操作
db.Prepare用于将被多次使用的语句
- 因为一次操作实际上和数据库有三次往返: 准备, 执行和关闭
- 在该语句中可以定义占位符,这样可以避免SQL注入攻击
- 在MySQL中参数占位符为
?; 在PostgreSql中为$N; 在Oracle中为:param
- 如果你只想执行一个语句但忽略结果,应该使用
db.Exec()而不是db.Query()
- 例如
INSERT, UPDATE, DELETE操作 - 因为
Query将返回一个sql.Rows,它保持一个数据库连接,直到sql.Rows被主动关闭
rows.Next()方法被设计用来迭代
- 迭代到最后一行数据之后,会触发一个
io.EOF的信号
- 会自动调用
rows.Close方法释放连接; 然后返回false - 此时
for rows.Next(){}循环将会结束退出
- 如果
rows.Next()循环不是由于查询完毕而自动退出,连接不会释放
- 垃圾回收器最终会关闭底层的
net.Conn,但这可能需要很长时间
rows.Close()是一种无害的操作,如果它已经关闭,所以你可以多次调用它
- 请注意首先检查错误,如果没有错误再调用
rows.Close(),否则会导致运行时的panic
rows.Scan会帮我们自动进行类型转换
- 比如有个数据库字段的类型是
VARCHAR,而他的值是一个数字,例如"1"
- 如果我们定义目标变量是string,则赋值后目标变量是数字string
- 如果声明的目标变量是数字类型,那么scan会自动调用
strconv.ParseInt()或者strconv.ParseInt()方法将字段转换成和声明的目标变量一致的类型
- 如果有些字段无法转换成功则会返回错误,因此在调用
rows.Scan后都需要检查错误
- 如果你不知道查询将返回多少列,则可以使用
Columns()来查询列名称列表
- 你可以检查此列表的长度以查看有多少列,并且可以将切片传递给具有正确数值的
Scan() - 对于不定字段查询,我们可以定义一个map的key和value用来表示数据库一条记录的row的值,通过
rows.Columns得到的col作为map的key值 - 如果你不知道这些列或者它们的类型,你应该使用
sql.RawBytes
cols, err := rows.Columns()
if err != nil{
panic(err)
}
vals := make([][]byte, len(cols))
scans := make([]interface{}, len(cols))
for i := range vals{
scans[i] = &vals[i]
}
var results []map[string]string
for rows.Next(){
err = rows.Scan(scans...)
if err != nil{
panic(err)
}
row := make(map[string]string)
for k, v := range vals{
key := cols[k]
row[key] = string(v)
}
results = append(results, row)
}
事务
tx对象保证后续所有操作都在同一个连接上执行,也是把所有操作绑定到单个连接的唯一方法
- 如需要修改连接状态并以此为基础处理多个语句,即使不希望使用事务,也必须在一个
tx对象上操作
- 例如,创建仅在一个连接中可见的临时表、设置MySQL变量、更改连接超时设置等
db中准备好的stmt不能在事务中使用,因为被绑定到了不同连接
- 在事务中没有办法批处理语句

错误处理
- 不必手动检查或者尝试处理连接失败的情况
- 当你进行数据库操作的时如果连接失败了,
database/sql会自动尝试重连2次(maxBadConnRetries) - 仍然无法重连的情况下会自动从连接池再获取一个或者新建另外一个
rows.Scan在出现转换类型失败的时候会返回错误- 来自
rows.Err()的错误不应该被忽略
- 例如循环可能会由于查询时间过长等原因提前退出
- 这种情况在
Next内是不会有错误的,也不会自动回收连接
- 对于
db.QueryRow(),有一个特殊的错误常量,称为sql.ErrNoRows,当结果为空时,它将从QueryRow()返回
- 这在大多数情况下需要作为特殊情况来处理
- 空的结果通常不被应用程序代码认为是错误的,但如果不检查错误是不是这个特殊常量,那么会导致意想不到的错误
原理
- 接口定义
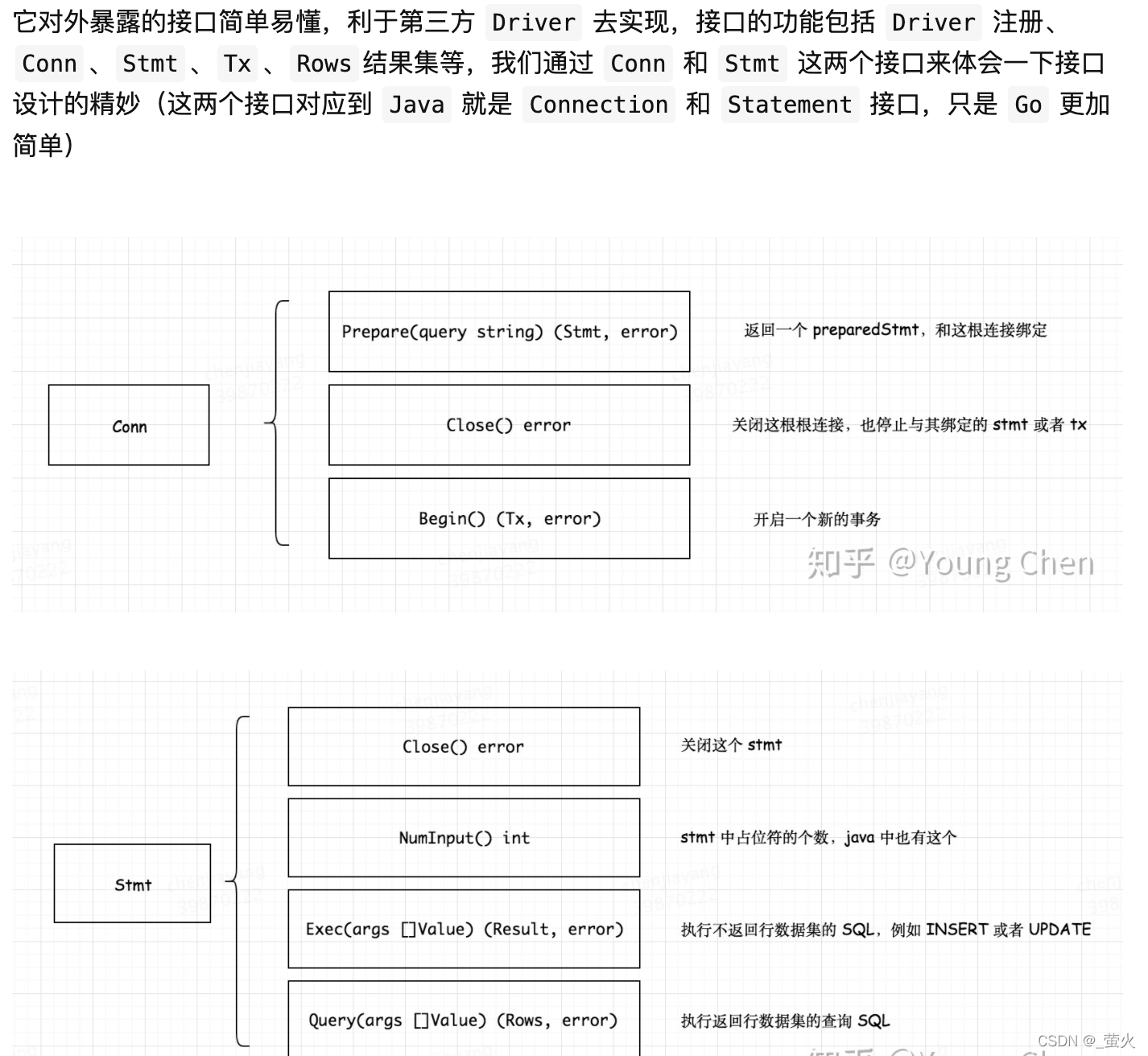
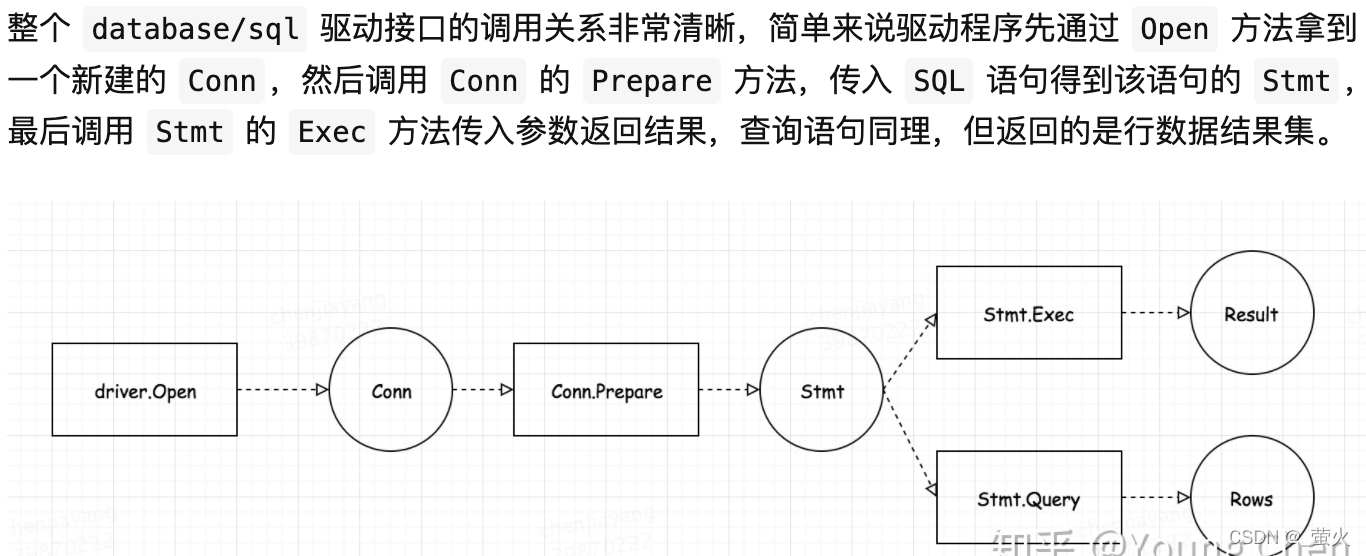
- 调用关系
GORM
- 支持的数据库: MySQL, PostgreSQL, SQlite, SQL Server
- GORM 倾向于约定,而不是配置
- 表名是结构体名称的复数形式
- 通过给结构体添加
TableName() string方法自定义表名
- 列名是字段名的蛇形小写
- 可以通过结构体tag重设:
gorm:"column:<new name>"
- 主键默认为
ID字段
- 可以通过结构体tag重设:
gorm:"primary_key"
- gorm的使用方式是链式操作,很多函数都返回
*DB这个结构








 本文介绍了Golang中的database/sql包,包括初始化、连接池配置、操作、事务和错误处理。讨论了如何使用数据库连接池,如何设置最大连接数、最大空闲连接数和连接复用时间。此外,还提到了操作数据库语句、预编译语句以防止SQL注入,以及事务处理。最后,文章简要概述了GORM库在数据库操作中的应用。
本文介绍了Golang中的database/sql包,包括初始化、连接池配置、操作、事务和错误处理。讨论了如何使用数据库连接池,如何设置最大连接数、最大空闲连接数和连接复用时间。此外,还提到了操作数据库语句、预编译语句以防止SQL注入,以及事务处理。最后,文章简要概述了GORM库在数据库操作中的应用。

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









