



在处理大量PDF文件时,有时候我们可能需要对文件名进行批量修改。例如,我们可能需要将文件名中的特定文字删除或替换。今天,我将向大家介绍如何使用Python编写一个简单的程序,选择一个文件夹,并删除文件名中的指定文字。
C:\pythoncode\new\renamepdffilenname.py
准备工作
首先,我们需要安装wxPython模块,它是一个用于创建桌面应用程序的Python模块。你可以使用pip工具来安装它:
pip install wxPython
安装完成后,我们可以开始编写我们的程序了。
编写程序
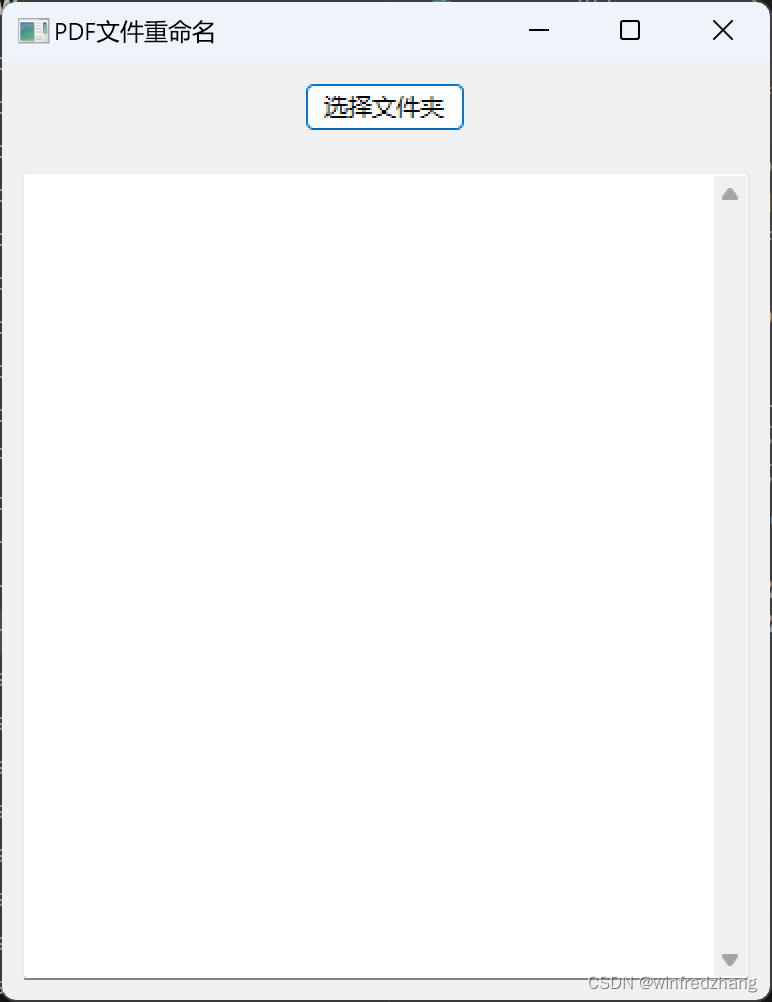
我们将使用Python和wxPython模块来创建一个简单的GUI程序。程序的主要功能是选择一个文件夹,并遍历该文件夹下的所有PDF文件,将文件名中的指定文字删除。
import os
import wx
class MyFrame(wx.Frame):
def __init__(self, parent, title):
super(MyFrame, self).__init__(parent, title=title)
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
choose_btn = wx.Button(panel, label='选择文件夹')
choose_btn.Bind(wx.EVT_BUTTON, self.on_choose_folder)
vbox.Add(choose_btn, proportion=0, flag=wx.ALL|wx.CENTER, border=10)
self.log_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY)
vbox.Add(self.log_text, proportion=1, flag=wx.EXPAND|wx.ALL, border=10)
panel.SetSizer(vbox)
self.Show()
def on_choose_folder(self, event):
dialog = wx.DirDialog(self, "选择文件夹", style=wx.DD_DEFAULT_STYLE | wx.DD_DIR_MUST_EXIST)
if dialog.ShowModal() == wx.ID_OK:
folder_path = dialog.GetPath()
self.process_pdf_files(folder_path)
dialog.Destroy()
def process_pdf_files(self, folder_path):
self.log_text.Clear()
self.log_text.AppendText("处理中...\n")
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.lower().endswith(".pdf"):
file_path = os.path.join(root, file)
new_file_name = file.replace("-优快云博客", "")
new_file_path = os.path.join(root, new_file_name)
try:
os.rename(file_path, new_file_path)
self.log_text.AppendText(f"重命名文件: {file_path} -> {new_file_path}\n")
except Exception as e:
self.log_text.AppendText(f"重命名文件时出错: {file_path}\n")
self.log_text.AppendText(f"错误信息: {str(e)}\n")
self.log_text.AppendText("处理完成!")
if __name__ == '__main__':
app = wx.App()
frame = MyFrame(None, "PDF文件重命名")
app.MainLoop()
运行程序
保存上述代码为一个Python脚本文件,然后运行该脚本。程序将启动一个GUI窗口,你可以点击按钮选择要处理的文件夹。
选择文件夹后,程序将遍历文件夹下的所有PDF文件,并删除文件名中的"-优快云博客"文字。处理结果将显示在程序窗口的日志文本框中。
总结
通过使用Python和wxPython模块,我们可以轻松地创建一个GUI程序,用于批量处理PDF文件名。这个程序可以帮助我们快速删除文件名中的特定文字,提高工作效率。

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









