




 本文介绍如何使用Python和wxPython创建一个简单的PDF内容搜索工具,通过PyMuPDF处理PDF并构建用户界面,方便查找和提取PDF中的特定内容。
本文介绍如何使用Python和wxPython创建一个简单的PDF内容搜索工具,通过PyMuPDF处理PDF并构建用户界面,方便查找和提取PDF中的特定内容。
简介:
在日常工作和学习中,我们可能需要查找和提取PDF文件中的特定内容。本文将介绍如何使用Python编程语言和wxPython图形用户界面库来实现一个简单的PDF内容搜索工具。我们将使用PyMuPDF模块来处理PDF文件,并结合wxPython构建一个用户友好的界面。
C:\pythoncode\new\pdffindcontent.py
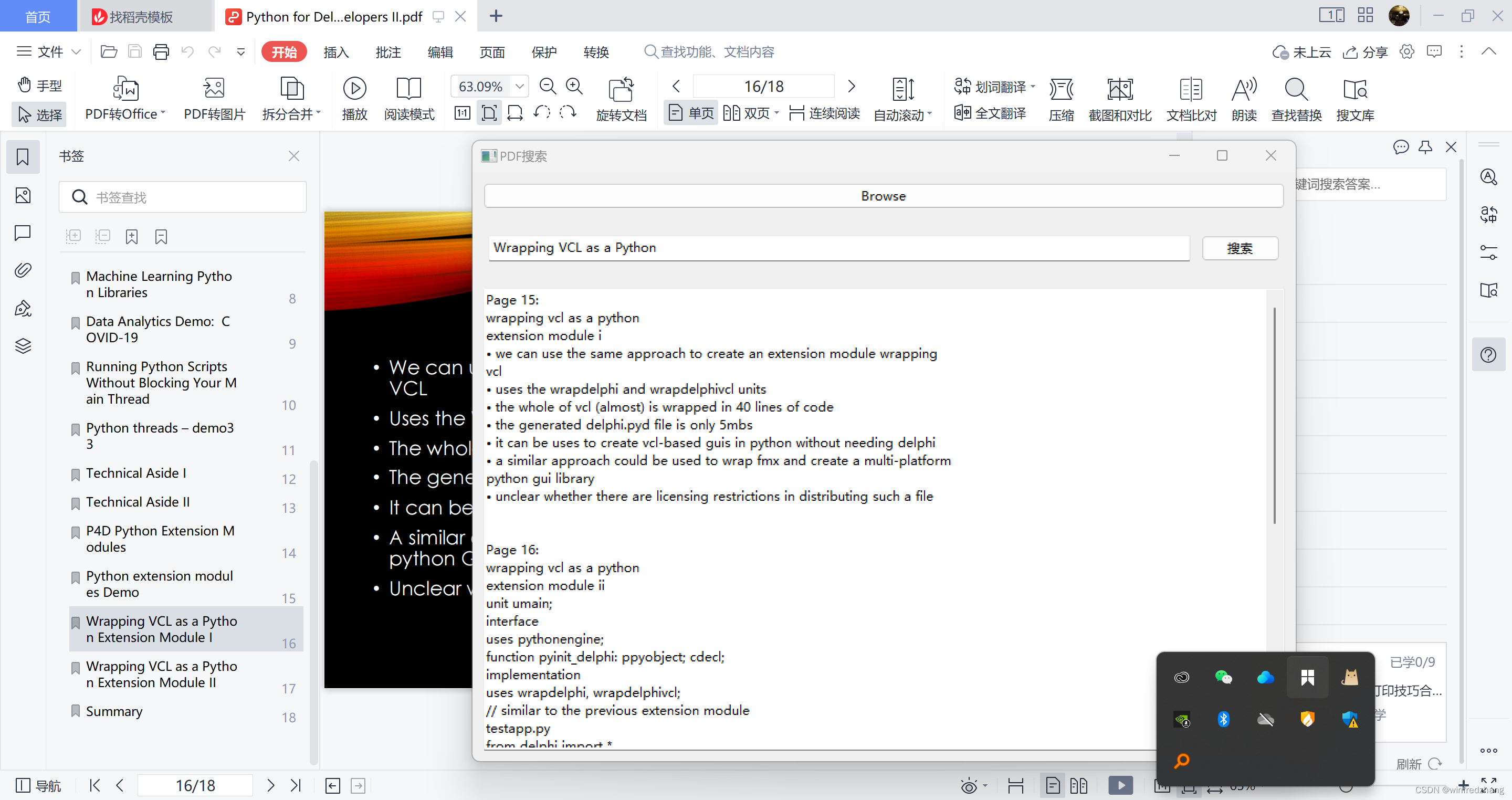
准备工作
在开始之前,请确保已经安装了Python和相应的模块。可以使用pip来安装wxPython和PyMuPDF模块,具体安装方法可以参考官方文档。
创建GUI界面
我们首先需要创建一个GUI界面,以便用户选择要搜索的PDF文件并输入要查找的内容。我们使用wxPython库来创建界面。
def __init__(self, parent, title):
super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
# 选择文件按钮
file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST)
file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected)
vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10)
# 输入框和按钮
hbox = wx.BoxSizer(wx.HORIZONTAL)
self.search_text = wx.TextCtrl(panel)
search_button = wx.Button(panel, label='搜索')
search_button.Bind(wx.EVT_BUTTON, self.on_search)
hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









