






Hadoop搭建步骤:
一:准备阶段:
-
在每台机器修改主机名字:hostnamectl set-hostname hadoop1 hostnamectl set-hostname hadoop2 hostnamectl set-hostname hadoop3
2.在57(hadoop1)修改/etc/hosts
10.4.13.57 hadoop1
10.4.13.58 hadoop2
10.4.13.59 hadoop3
3.在主机免密登录,同时让主机能够免密访问从机
ssh-keygen -t rsa
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
单机master上的配置:
二:jdk环境变量配置
1.下载jdk
方法一:在centos7中使用wget JDK下载的网址
方法二:在window下载好后,使用xshell向虚拟机传输
说明:xshell需要安装 lrzsz才可以传输
yum install -y lrzsz
rz 弹出窗口,选择下载好的JDK包(rz windows向linux)
举例:sz (Linux文件向windows) sz /etc/profile
2.解压缩到目录
mkdir -p /opt/java
tar zxvf jdk-8u211-linux-x64.tar.gz -C /opt/java (解压缩命令待补充)
3.环境变量配置
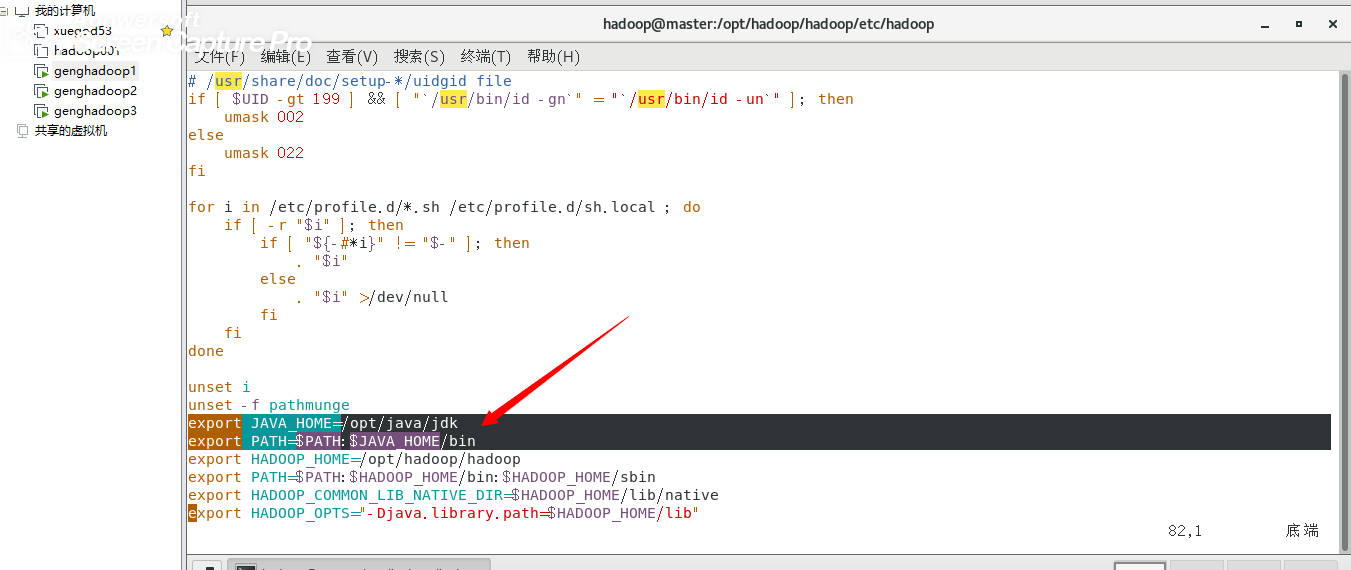
vim /etc/profile
末尾增加两行即可(注意我是将jdk-1.8..重命名成了jdk,JAVA_HOME路径是你的JDK解压后的全路径)
-----------------------------------------------
export JAVA_HOME=/opt/java/jdk
export PATH=$PATH:$JAVA_HOME/bin
--------------------------------------------------------
source /etc/profile
java -version
三:hadoop变量配置
1.hadoop下载
方法1: wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-aarch64.tar.gz
方法2:windows下载好后,通过下shell传输 细节参考jdk。
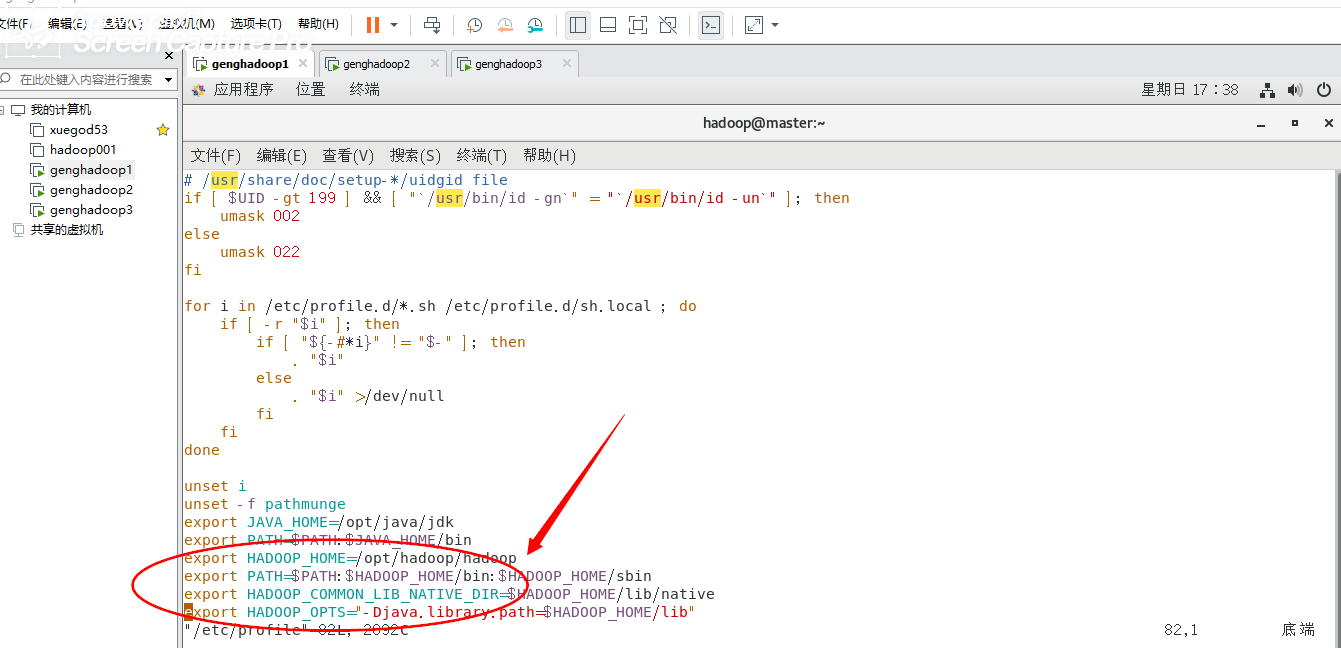
2.hadoop配置环境变量,vim /etc/profile
=======================================
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
=============================================
source /etc/profile
hadoop version
四.配置文件
我的hadoop安装路径 cd /opt/hadoop/hadoop
cd etc/hadoop 注意:这里的etc是相对路径
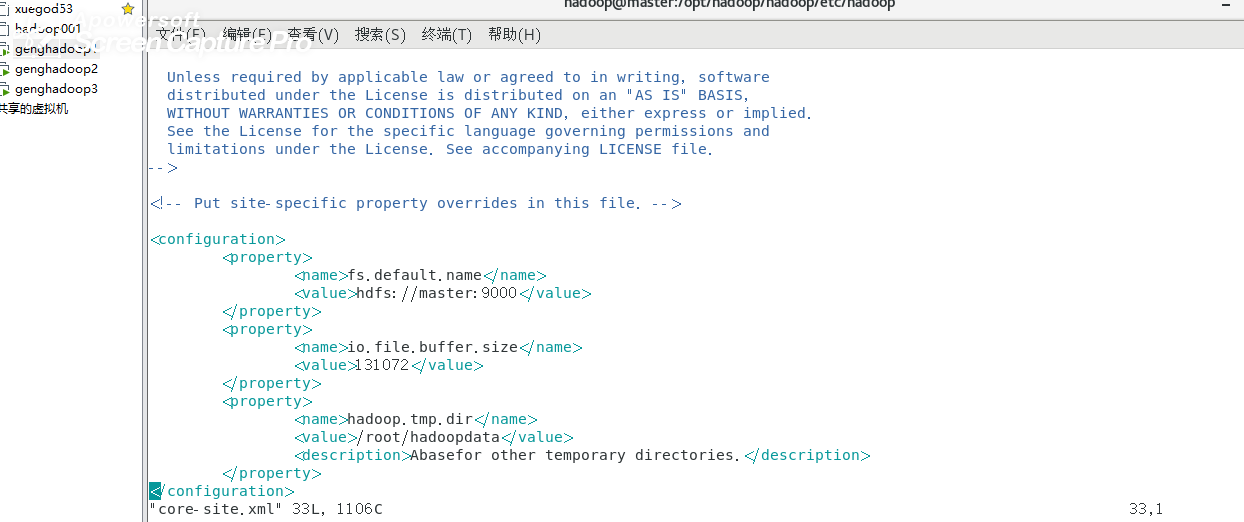
1 修改 core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopdata</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
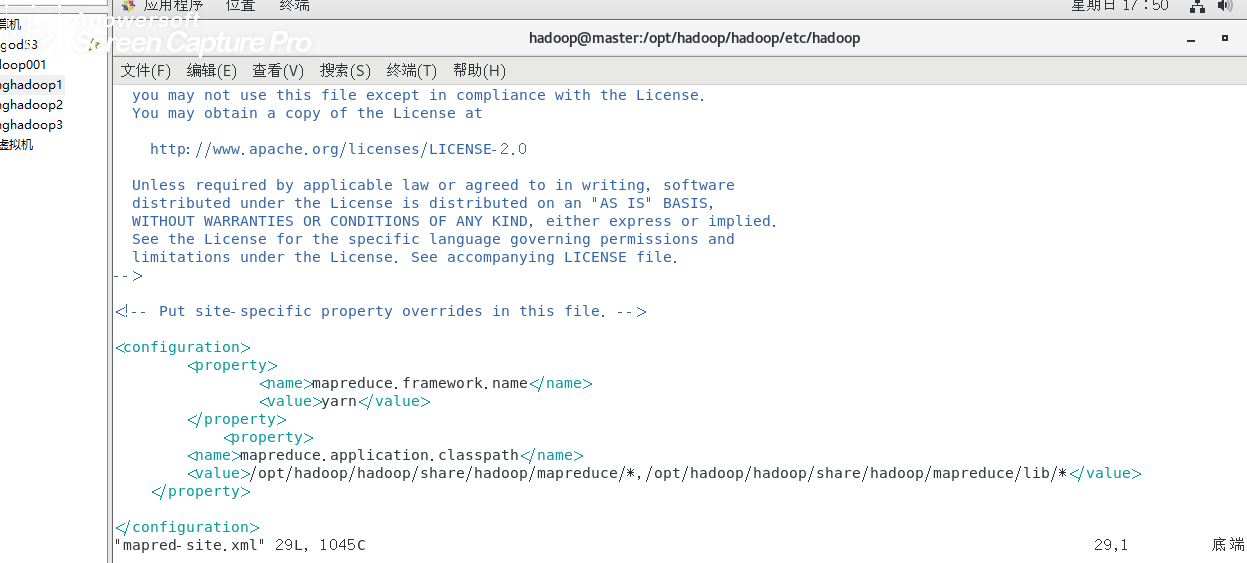
2修改vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name> <value>/opt/hadoop/hadoop/share/hadoop/mapreduce/*,/opt/hadoop/hadoop/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
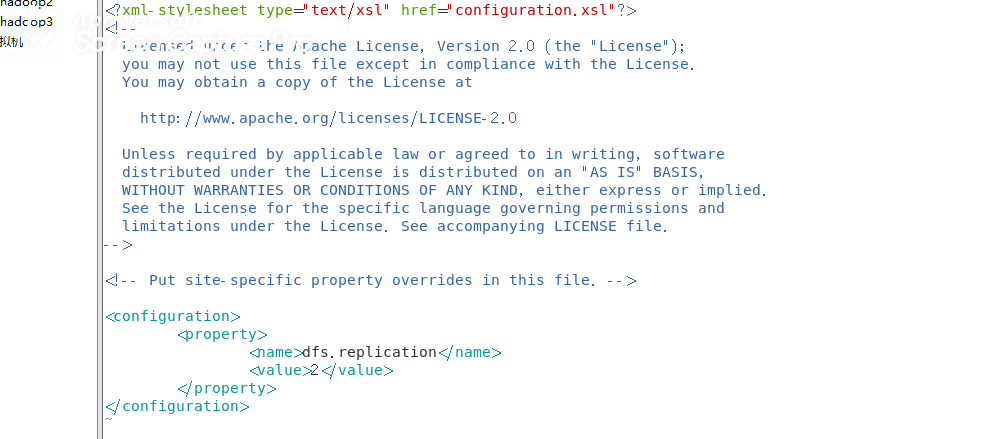
3修改vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4修改vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

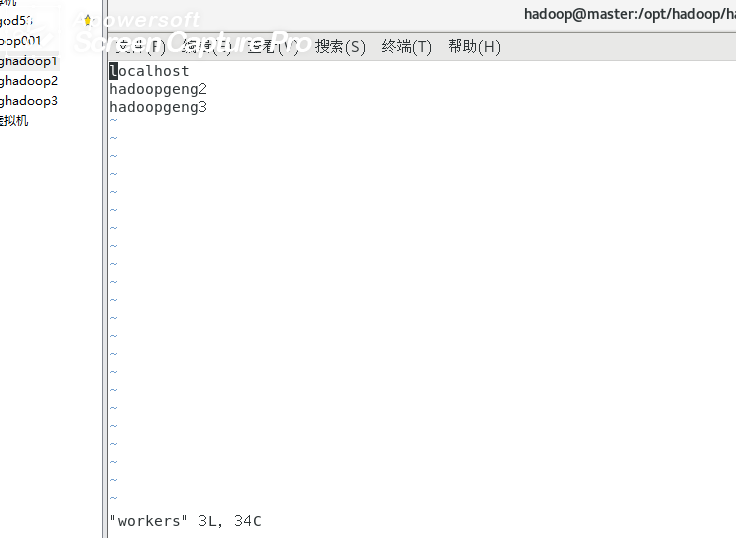
5 vim workers
6、对于start-dfs.sh和,添加下列参数:
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root 7 stop-dfs.sh文件 HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
8、对于start-yarn.sh和,添加下列参数:
9.stop-yarn.sh文件 YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
10:vim hadoop-env.sh
export JAVA_HOME=/opt/java/jdk

11.vim mapred-env.sh
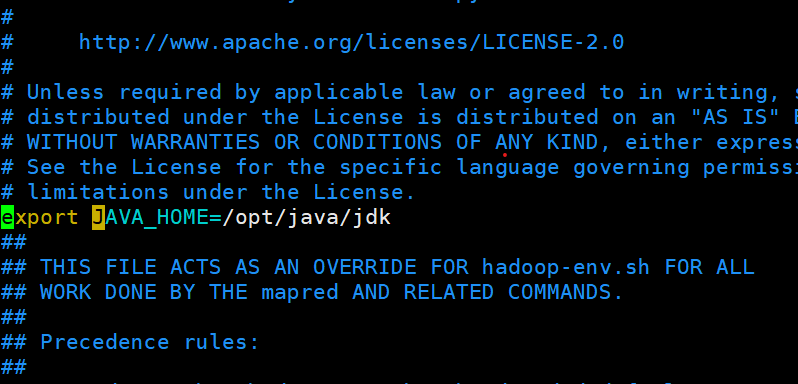
五:在master格式化:
hadoop namenode -format
六:复制到从机
-
scp /etc/hosts root@10.4.13.58:/etc/
或scp /etc/hosts root@hadoop2:/etc/
scp /etc/hosts root@10.4.13.59:/etc/
或scp /etc/hosts root@hadoop3:/etc/
-
在58,59上mkdir -p /opt/java
scp -r /opt/java/jdk root@10.4.13.58:/opt/java/
scp -r /opt/java/jdk root@10.4.13.59:/opt/java/
-
在58,59 mkdir -p /opt/hadoop
scp -r /opt/hadoop/hadoop root@10.4.13.58:/opt/hadoop/
scp -r /opt/hadoop/hadoop root@10.4.13.59:/opt/hadoop/
4. 把/etc/profile 复制到hadoop2(58),hadoop3(59)
scp /etc/profile root@10.4.13.58:/etc/
scp /etc/profile root@10.4.13.59:/etc/
去58,59上都执行source /etc/profile
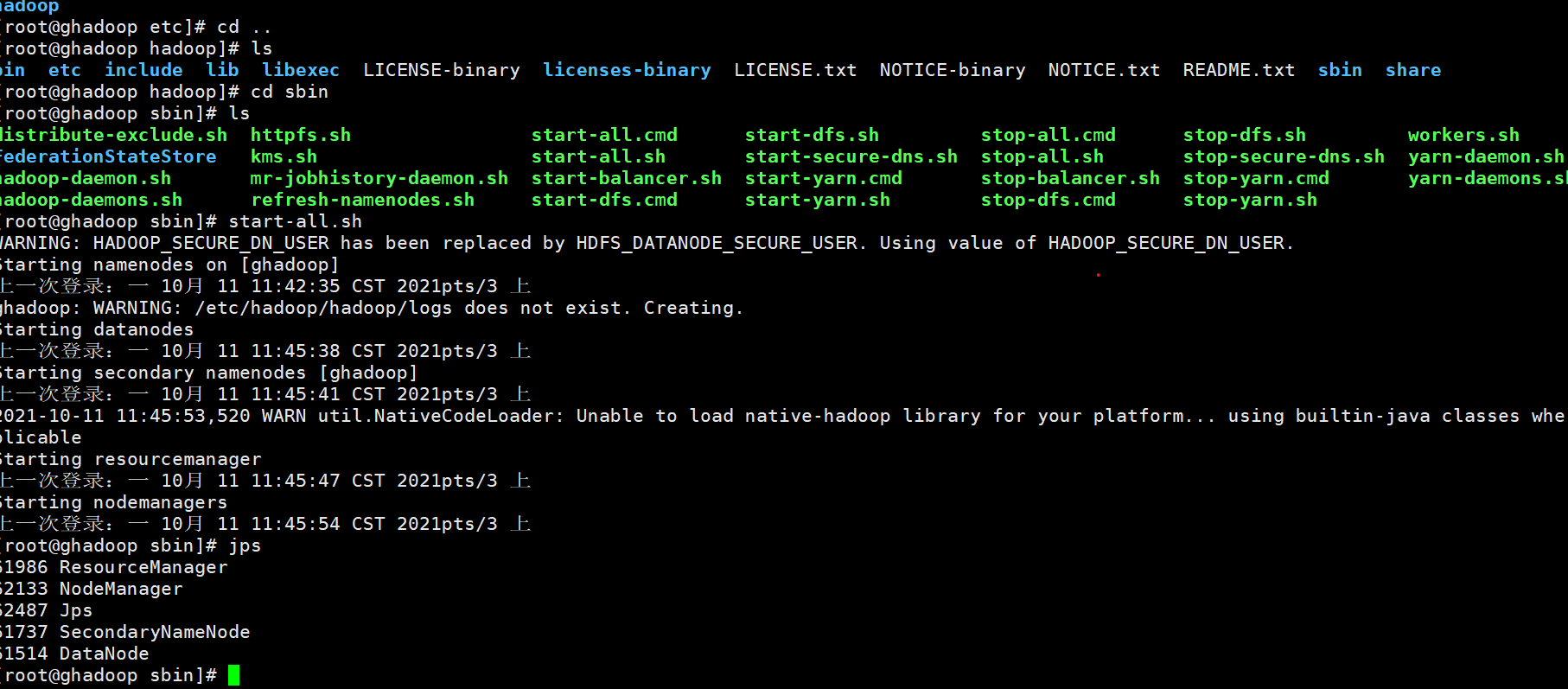
七:去主机57的sbin上面启动
start-all.sh
启动过之后jps
七:启动, start-all.sh
六:时钟同步
yum install -y ntp
crontab -e
*/1 * * * * /usr/bin/ntpdate ntp4.aliyun.com
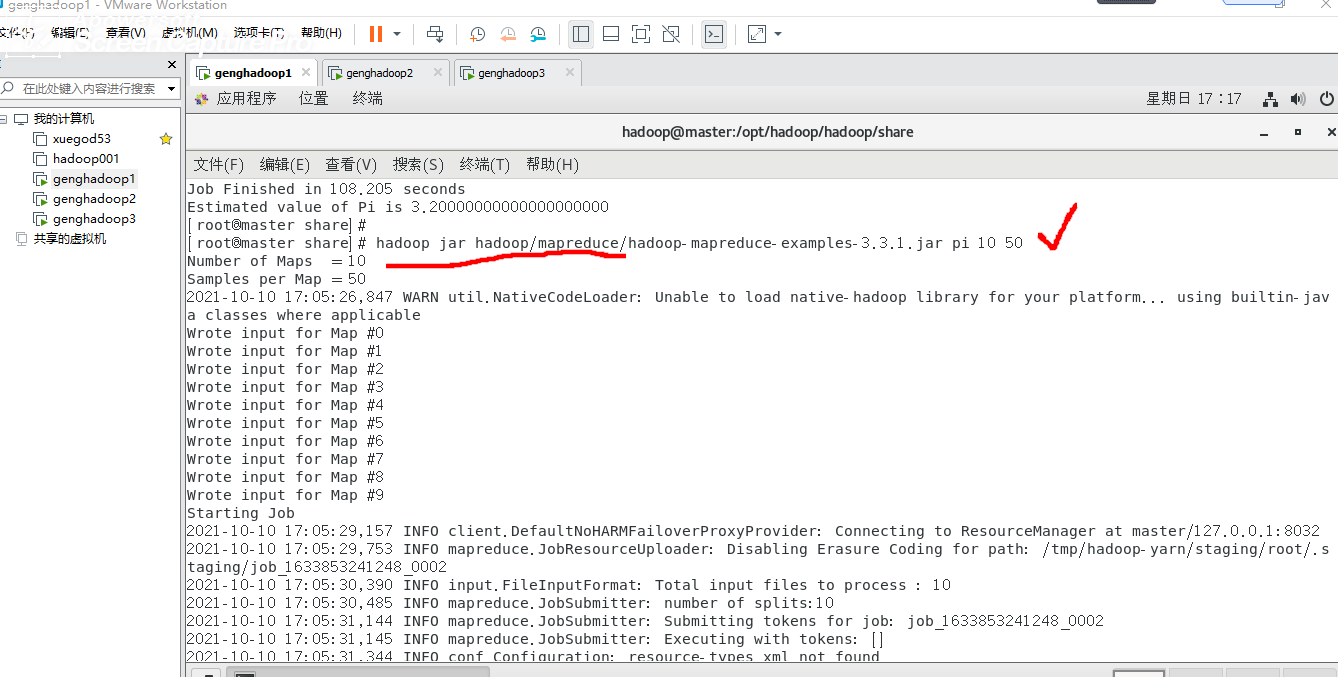
七:执行例子


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









