






🚀 个人主页 极客小俊
✍🏻 作者简介:程序猿、设计师、技术分享
🐋 希望大家多多支持, 我们一起学习和进步!
🏅 欢迎评论 ❤️点赞💬评论 📂收藏 📂加关注

多表查询
所谓的多表查询,顾名思义就是从多张表中查询和提取所需要的记录!
不管我们是学习的SQL Server还是MySQL它们都属于是一种关系数据库, 而所谓的关系数据库也就是能够允许我们根据两个表或多个表的字段之间的关系,从这些表中查询数据。
之前,我们在使用数据库的时候,都是查询的一张表,但是随着业务逻辑复杂度的增加,一张表也不能满足我们所有的场景~
所以我们会建立很多数据表, 但是这些数据表,彼此之间会存在一些关系, 也就是说表与表之间通常存在关联关系!
这些关系主要分为三种:一对一、 一对多(多对一)、多对多 这三种关系!~
在我们正式开始进行多表查询之前,我们必须先要理解这个概念,否则就不能正确的找到表与表之间的关系~
主键与外键
在我们讨论数据库表关系之前,我们先回忆一下主键与外键
在最开始我在讲解数据库设计的时候,也有讲它们彼此的作用,大家还记得吗?
主键和外键是数据库设计中非常重要的概念,它们主要的作用其实就是让数据的保持完整性和一致性
同时主键和外键也反映了业务实体之间的关系,有助于理解和维护数据库结构, 帮助我们在开发时, 避免编写违反业务规则的代码!
数据的完整性和一致性
让我们再次来回忆一下什么叫完整性和一致性?
前面我说过, 你可以简单理解为是一种让关联的两个表或多个表中相字段的值要保持一致的一种情况!
比如: 当外键所引用的主键值被修改或删除的时候,数据库系统会根据参照完整性规则, 如限制或级联策略,
那么外键所在表的相应记录也会进行相应的修改或删除 对吧~
有了这个规则之后,我们就可以执行以下操作了:
例如
更新:当主键表中的主键值被更新时,外键表中相应的外键值也必须被更新,以保持数据的一致性。
删除:当主键表中的记录被删除时,外键表中引用该主键值的记录也必须被删除或设置为NULL, 具体取决实际的开发需求和规则!
添加:在外键表中插入新记录时,外键的值必须存在于主键表中相应的主键值集合中,否则添加操作会被拒绝,也就是说数据库管理系统会自动检查主键和外键约束,防止一些不符合规则的数据进行插入或更新操作!
所以数据的完整性是用来确保数据库表之间的数据关系的正确性和一致性,防止数据孤立和数据不一致问题的出现!
就像是以下这个表一样!
如图
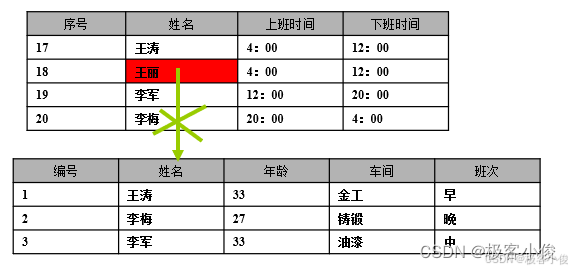
这里姓名字段显然是无法相互保证数据的正确性和一致性, 因为外键的值必须存在于主键表中相应的主键值集合中!
主键和外键其实是从物理层面来解决数据的一致性和完整性的问题, 也就是说它们通过物理层面的约束来确保数据的一致性和完整性。
这些约束不仅有助于防止数据错误和异常,还能够提高数据库的性能和可维护性。
在数据库设计和实现过程中,合理地使用主键和外键是确保数据质量和业务逻辑正确性非常重要!
题外话
那么这里就会有人要问了~~主键和外键 是必须创建吗??
其实并没有说一定要让你去创建这个主键和外键, 在多表查询的时候,要不要建立主键和外键 完全是取决于你对数据完整性的需求和业务逻辑进行分析和考虑之后下的决定!
从技术角度上说, 其实你可以在没有主键和外键的情况下进行多表查询 这是没什么影响的, 但这样做通常也不符合数据库设计的规范呀, 平常开发我们也是不推荐这样去干的, 原因刚刚上面已经说过了!
其实创建主键和外键还有其他好处,比如提高查询效率 , 我们的主键通常会有索引,这可以加快查询速度
并且外键也可以有索引,特别是在涉及大量数据的情况下有助于提高JOIN操作的性能, 这个我们后面说!
主键 (Primary Key)
主键的定义
主键是数据表中的一个或多个字段 创建而来的, 它的值是能够唯一标识表中的一条记录, 也就是说主键值在表中必须是唯一的,并且不能为空!
创建方式我们之间也已经讲过了,使用的是PRIMARY KEY关键字
当然有的时候根据需求和情况也会利用多个字段进行合并创建联合主键 或者叫 复合主键
举个栗子
在订单表中,订单ID和产品ID就可以组合成为复合主键,因为它们可以共同唯一标识一个订单中的某个产品
如下
CREATE TABLE Orders (
OrderID INT, --订单ID
ProductID INT, --产品ID
OrderDate DATETIME,
PRIMARY KEY (OrderID, ProductID)
);
还有比如说在一个学生表中,学号StudentID可以作为主键,因为它能够唯一标识一个学生 等等~这些都需要我们在实际应用开发中去仔细观察 哪些合适用于主键,哪些不合适!
外键(Foreign Key)
外键是数据表中的一个或多个字段创建而来的, 但是它的值是引用了另一个表的主键或唯一键
对于外键的创建,我们是用的FOREIGN KEY
应用场景
举个栗子
我们来创建一个客户表和订单表 并且把它们关联起来!
/*客户信息*/
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY IDENTITY,
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
Email NVARCHAR(100) UNIQUE NOT NULL,
PhoneNumber NVARCHAR(20),
Address NVARCHAR(255),
City NVARCHAR(50),
State NVARCHAR(50),
PostalCode NVARCHAR(20),
Country NVARCHAR(50)
);
/*插入一些数据*/
INSERT INTO Customers (FirstName,LastName,Email,PhoneNumber,Address,City,State,PostalCode,Country)VALUES
('张三', '小三', 'zhangsan@qq.com', '123-456-7890', '无声区街道', '重庆市', 'YES', '62701', '中国');
INSERT INTO Customers (FirstName,LastName,Email,PhoneNumber,Address,City,State,PostalCode,Country)VALUES
('李四', '小李', 'lisi@qq.com', '777-1011-7890', '黄角哑街道', '北京市', 'YES', '98657', '中国');
INSERT INTO Customers (FirstName,LastName,Email,PhoneNumber,Address,City,State,PostalCode,Country)VALUES
('王五', '小五', 'wangwu@qq.com', '888-456-666', '东城区街道', '北京市', 'YES', '33658', '中国');
INSERT INTO Customers (FirstName,LastName,Email,PhoneNumber,Address,City,State,PostalCode,Country)VALUES
('张军', '小军', 'zhangjun@qq.com', '555-456-7766', '青杨区街道', '成都市', 'YES', '88709', '中国');
INSERT INTO Customers (FirstName,LastName,Email,PhoneNumber,Address,City,State,PostalCode,Country)VALUES
('赵云', '云云', 'zhaoyun@qq.com', '000-111-564', '青杨区街道', '成都市', 'YES', '88709', '中国');
/*创建订单表*/
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATETIME,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
这样我们就把它们彼此关联起来了, 然后你也可以插入一些测试数据 尝试一下!
如图
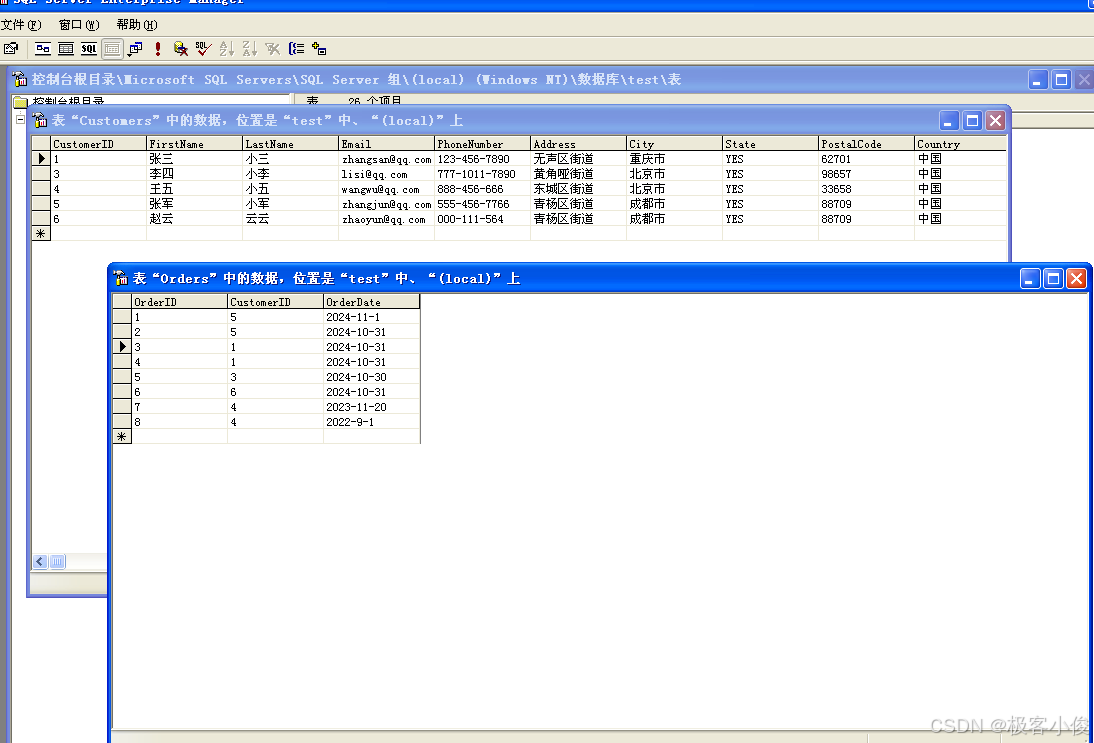
那么如果说我们在订单表中插入一个客户ID为2的数据,看看会怎么样?
如图
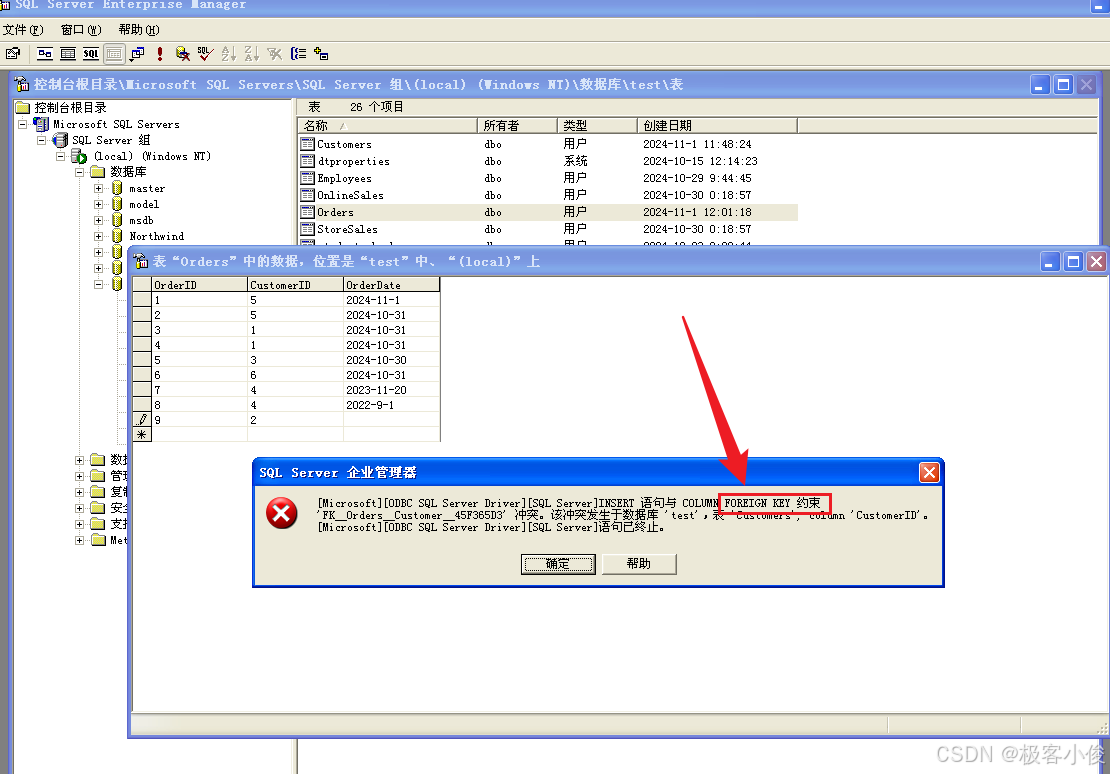
那么这就是外键和主键让数据保持了一致性的优势,之前我也已经说过了这里就不赘述了!
在上面的案例中 订单表(Orders)和客户表(Customers)之间,可以通过CustomerID外键来建立关联。
这样当我们查询一个订单的时候,就可以轻松的找到与该订单相关的客户信息!
这里我们简单演示一下
如下
select * from Orders;
我们这样查会查询到很多订单,里面有客户的ID
如图
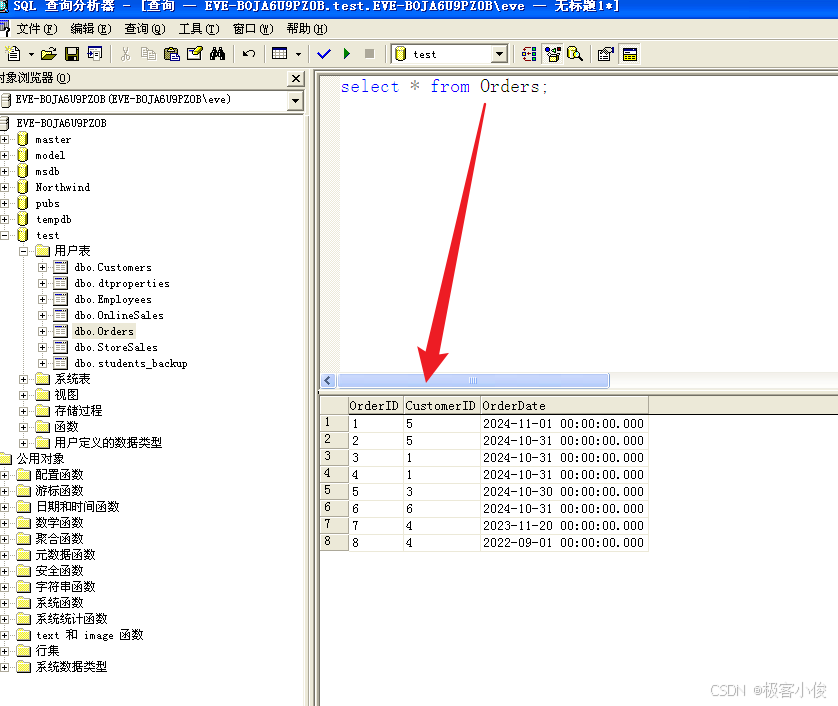
但是现在我们希望还能看到 对应客户的信息!
如下
SELECT * FROM Customers INNER JOIN Orders ON Orders.CustomerID = Customers.CustomerID
关于内连接查询我们稍后再说!
如图
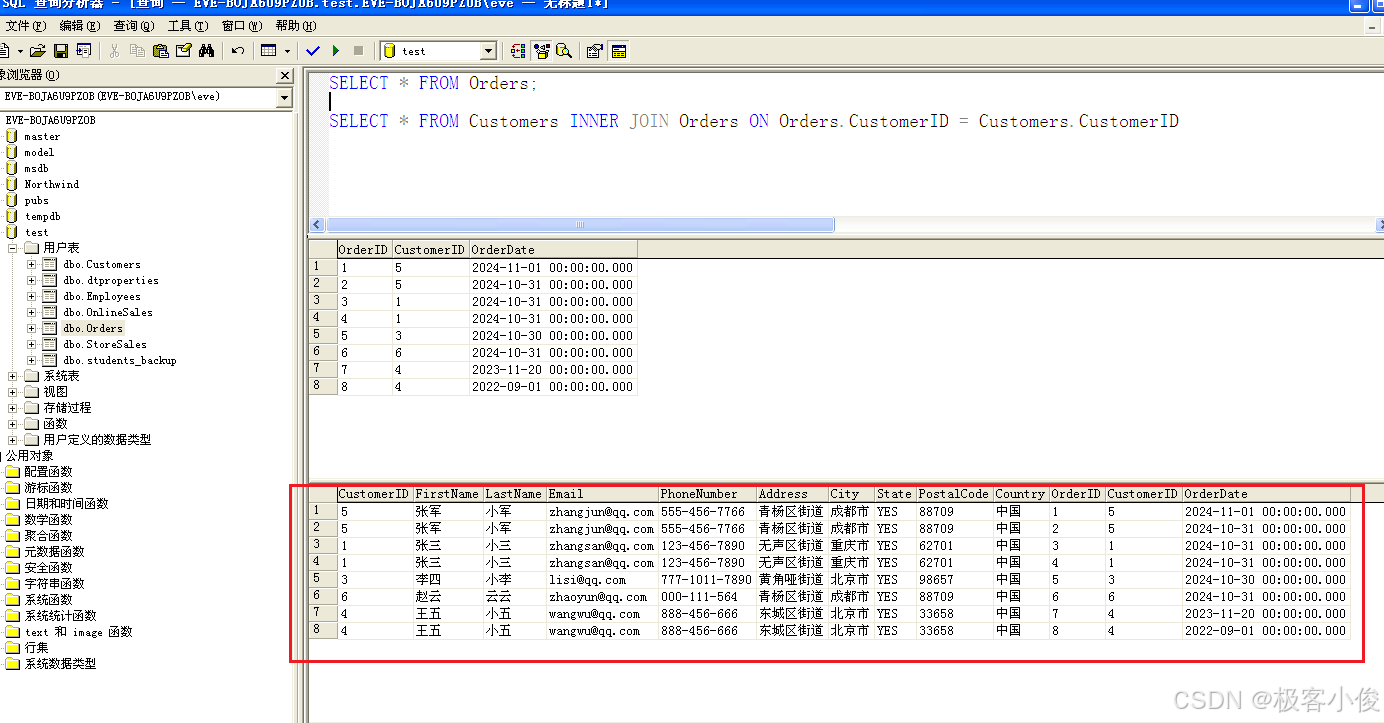
那么得到这样一个结果集之后,我们就可以继续做更多的处理了呀,比如统计、分组、计算等等操作都可以了!
级联删除
同样地,当我们删除一个客户时, 可以确保与该客户相关的所有订单都被相应地处理
例如:我们可以设置级联删除!
这里简单演示一下:
因为我们已经创建了订单表了,只能通过Alter语句来修改
如下
ALTER TABLE Orders ADD CONSTRAINT FK_Customer_Order FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) ON DELETE CASCADE;
那么此时此刻,我们已经在外键约束中设置了级联删除(ON DELETE CASCADE)
当主表(Customers)中的某条记录被删除时,从表(Orders)中与该记录相关联的所有记录也会被自动删除。
你还不信?我们来手动删除试试看~~
如图
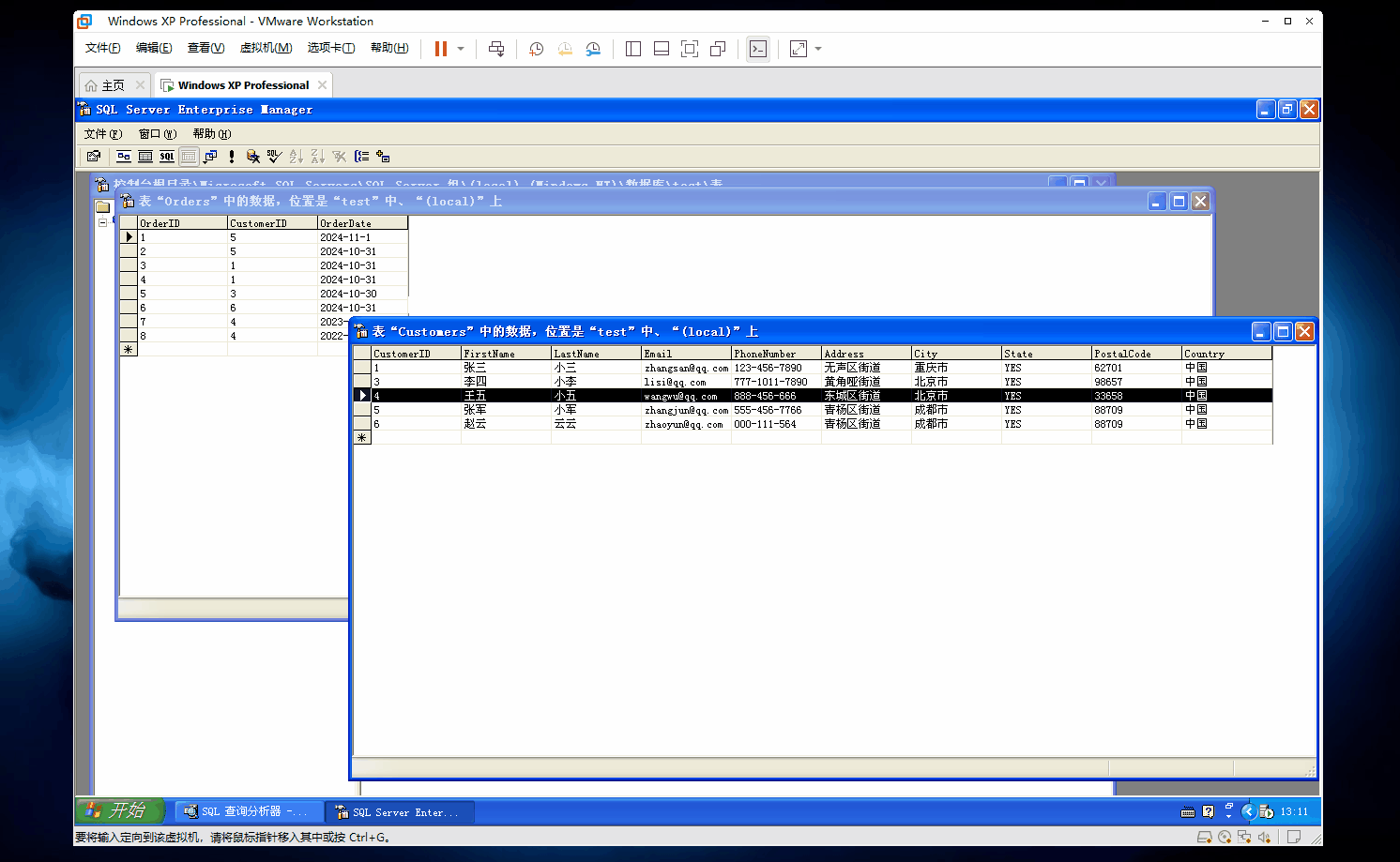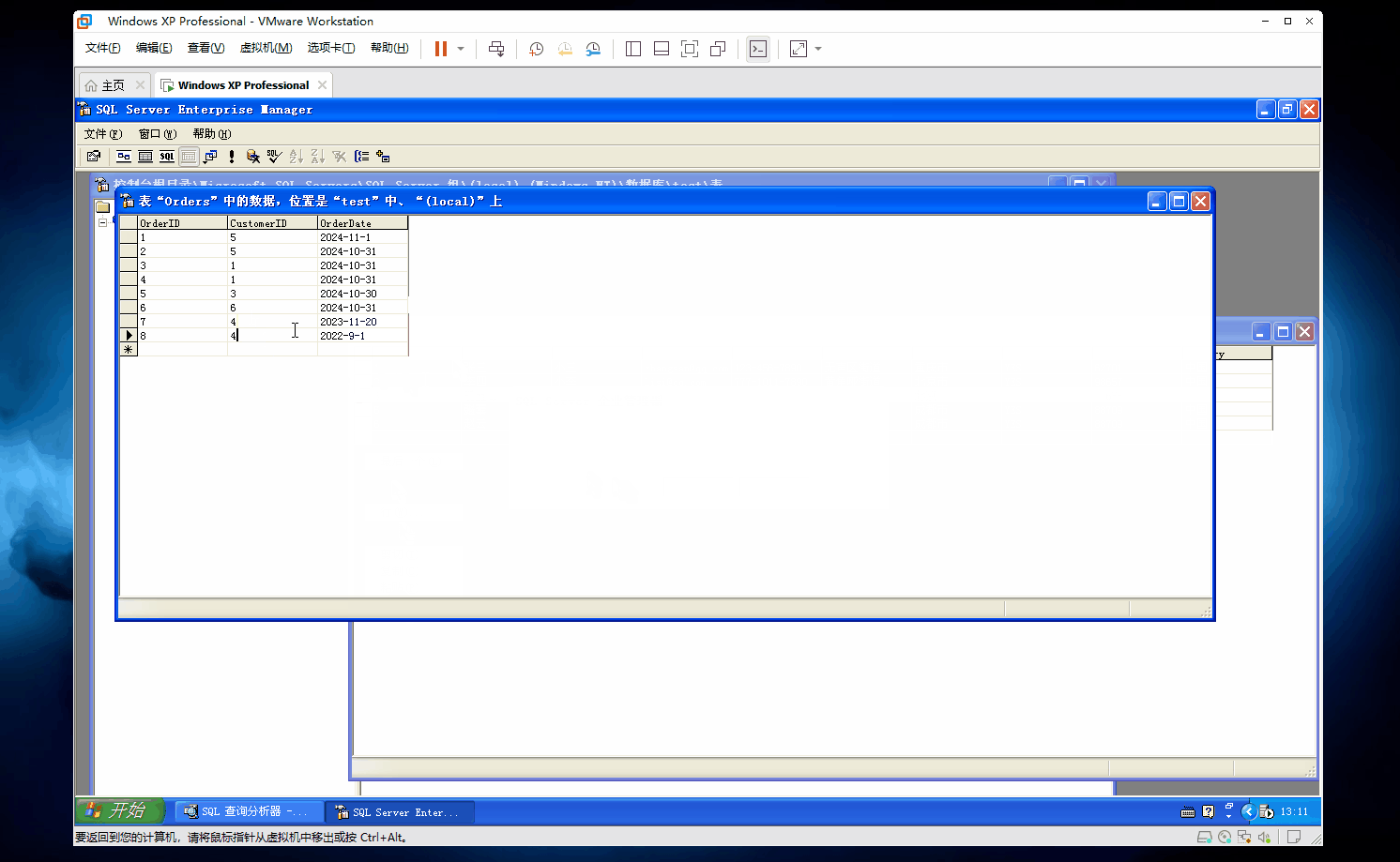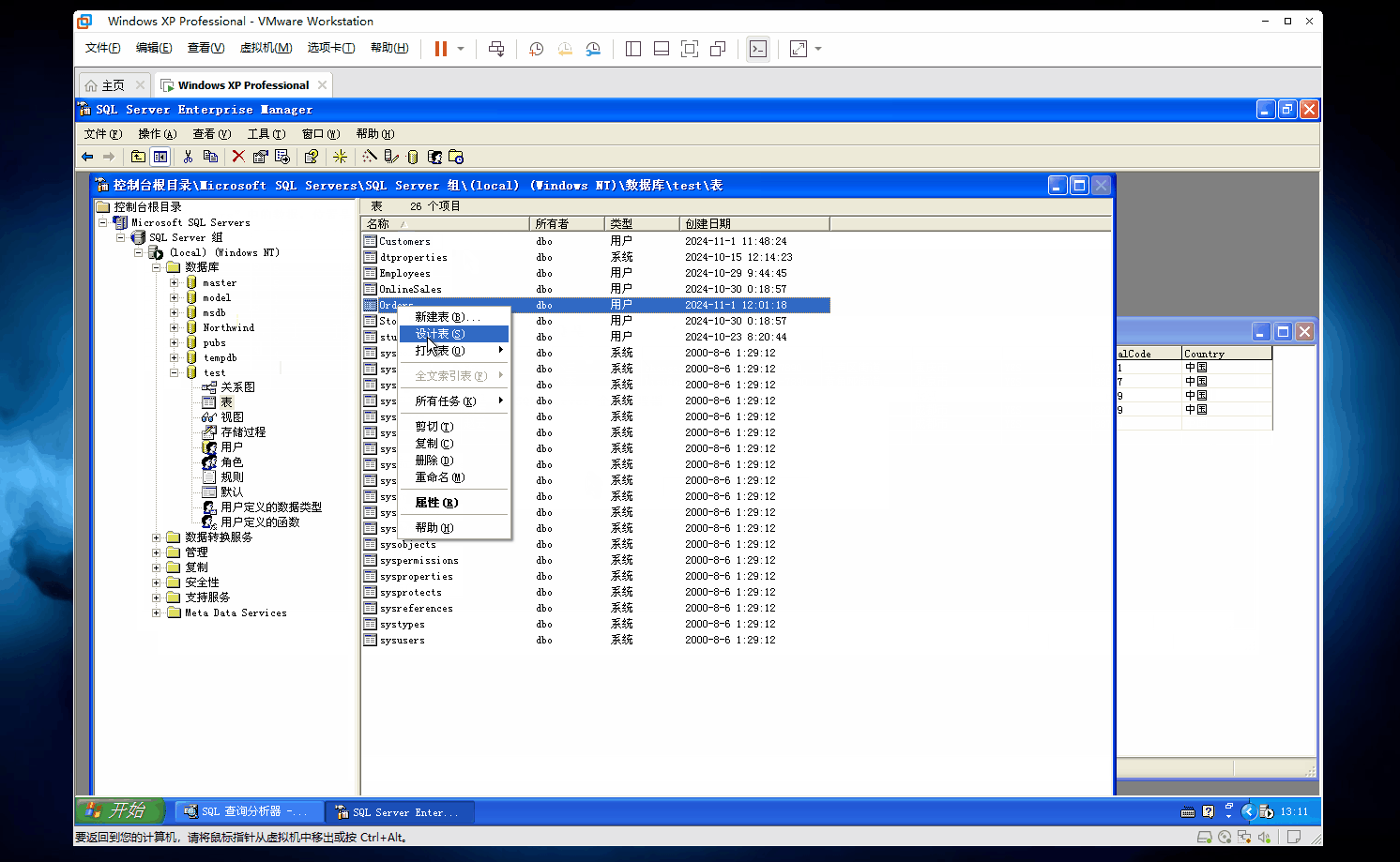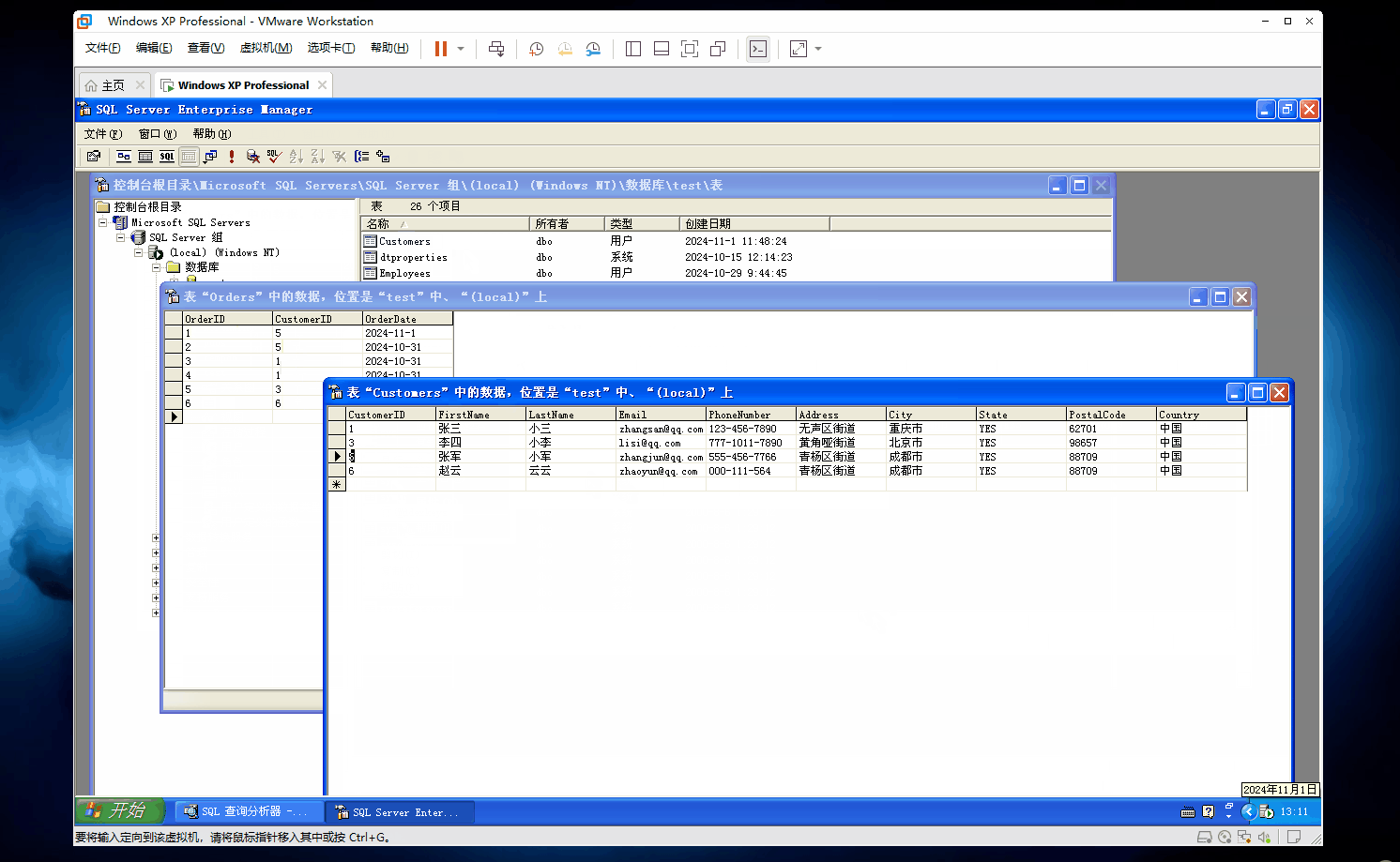
你们看,当我们把客户ID为4的记录删除了,那么订单表中和客户ID为4的订单记录也会被全部删除!
如果你还不明白如何设置级联删除 也没关系,后面我们会单独出一期~ 这里先理解一下大致的概念即可!
多表关系
多表关系其实不是一尘不变的,反而在我们实际开发中,这是非常灵活多变的,并且表和表之间的关系也会根据实际的业务逻辑需求,随时随地的进行改变…这也是我们学习关系型数据库的一大难点!
在数据库设计中,一对一、一对多、多对多是关系在数据库设计中的核心概念,理解这些关系千万不要去要死记硬背,而是需要通过灵活应用实际场景来帮助记忆和理解!
那接下来,我们就来讨论一下多表查询中,这三种关系吧~~
一对一关系
概念定义
一对一关系指的是一个表中的一条记录可以与另一个表中的一条记录相关联,且这种关联是唯一的!
举个栗子
比如我们可以将常用于将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率。
例如: 用户表包含用户名、年龄等基本信息, 和用户详情表包含用户家庭住址、电话号码等详细信息!
一个用户信息只对应一个用户详情,反之一个用户详情信息也只能去对应一个用户,这就是典型的一对一关系
所以类似于这种用户与用户详情的关系,通常也多用于单表拆分,也就是将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率。
从表的设计结构上是通过在任意一方加入外键来关联另一方的主键,并且设置外键为唯一(UNIQUE)的来实现!
应用场景
比如说我们正在设计一个用于存储员信息和敏感财务信息的系统, 但是出于安全考虑,我们希望将员工的敏感财务信息如银行账户信息与他们的个人信息分开存储, 那么这个时候,我们可以考虑使用一对一关系来连接这两个表!
具体SQL如下
-- 创建Employees 员工表
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY IDENTITY,
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
Email NVARCHAR(100) NOT NULL UNIQUE,
-- 其他非敏感个人信息字段
);
-- 创建EmployeeFinancials 员工财务状况表
CREATE TABLE EmployeeFinancials (
EmployeeID INT PRIMARY KEY,
BankAccountNumber NVARCHAR(20) NOT NULL,
BankRoutingNumber NVARCHAR(10) NOT NULL,
-- 其他敏感财务信息字段
FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID) ON DELETE CASCADE
);
在上面的案例中,EmployeeID 字段是两个表之间的关联字段,也是 EmployeeFinancials 表的主键
所以我平常叫大家 命名的时候一定要注意,方便我们开发和识别, 不然很容易混淆,搞不清楚哪个是哪个!
同时,EmployeeFinancials 表中的 EmployeeID 字段也是一个外键,它引用了 Employees 表中的 EmployeeID 字段,并且设置了 ON DELETE CASCADE(级联删除) 选项,意味着如果我们在 Employees 员工表中删除一条记录,那么与之关联的 EmployeeFinancials 员工财务表中的记录也会被自动删除 !
我们也可以先插入一些数据进去测试一下看看!
如下
-- 插入员工信息
INSERT INTO Employees (FirstName, LastName, Email) VALUES ('John', 'Doe', 'john.doe@qq.com');
INSERT INTO Employees (FirstName, LastName, Email) VALUES ('Jane', 'Smith', 'jane.smith@qq.com');
INSERT INTO Employees (FirstName, LastName, Email) VALUES ('张三', '小张', 'zhangsan@qq.com');
-- 插入与这些员工关联的财务信息
INSERT INTO EmployeeFinancials (EmployeeID, BankAccountNumber, BankRoutingNumber) VALUES (1, '12345678901234567890', '123456789');
INSERT INTO EmployeeFinancials (EmployeeID, BankAccountNumber, BankRoutingNumber) VALUES (2, '98765432109876543210', '987654321');
INSERT INTO EmployeeFinancials (EmployeeID, BankAccountNumber, BankRoutingNumber) VALUES (3, '10065432109878888889', '866987748');
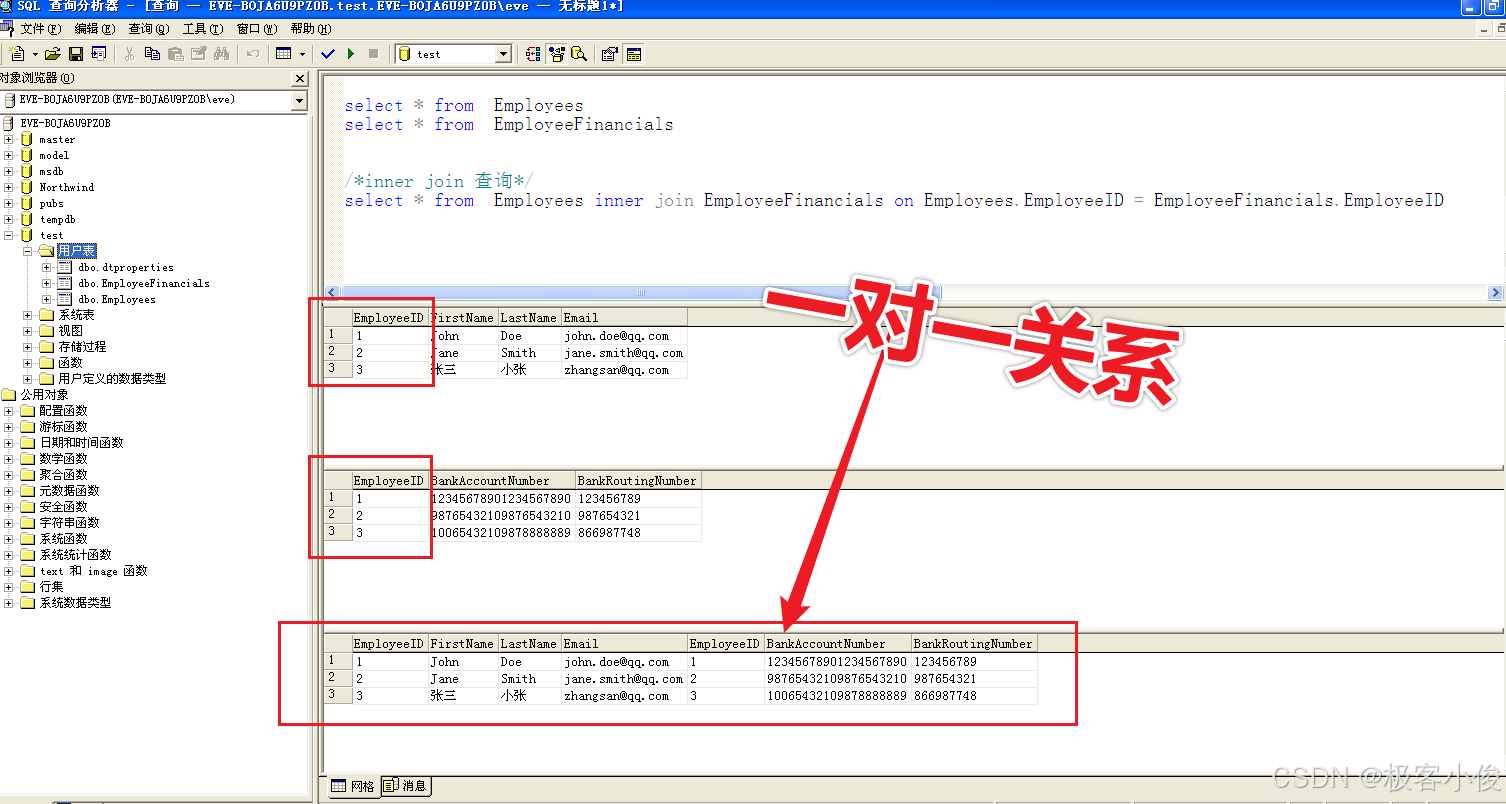
我们来简单查询一下
如下
select * from Employees
select * from EmployeeFinancials
/*inner join 查询*/
select * from Employees inner join EmployeeFinancials on Employees.EmployeeID = EmployeeFinancials.EmployeeID
如图
我们来执行删除一个员工信息看看, 看看员工财务表中会有会有效果!
如下
/*删除某个员工*/
delete from Employees where EmployeeID = 3;
如图
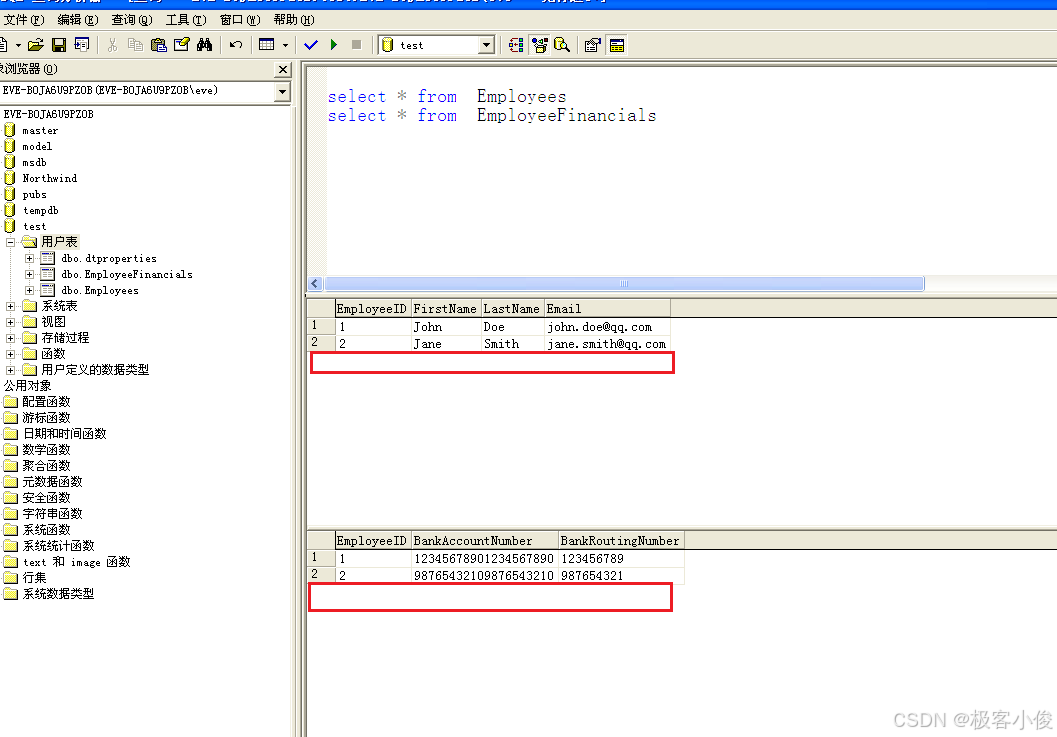
那么张三这个员工的记录删除了,自然在员工财务中张三的财务信息也被自动删除了!
这里我们在操作数据表的时候,就完美诠释了什么叫保证数据一致性和完整性 明白了吧!
类似于这种关系的我们还可以举例,比如学生表和学生信息详情表
学生表
| ID | 姓名 | 年龄 | 性别 |
|---|---|---|---|
| 1 | 张三 | 20 | 男 |
| 2 | 张丽 | 22 | 女 |
| 3 | 小王 | 18 | 男 |
学生信息详情表
| ID | 学号 | 所属专业 |
|---|---|---|
| 1 | 001A02 | 体育 |
| 2 | 002B08 | 英语 |
| 3 | 001A12 | 体育 |
你也可以根据需求在详情表中增加字段…具体都是看需求来决定的!
针对这种一对一关系情况,从表的结构可以分析出,不需要创建额外的键,只需要让他们的主键一一对应,就可以让它们建立关系, 大家可以自己试试实现一下,上面的表关系!
一对多(多对一) 关系
定义:
一对多关系指的是一个表中的一条记录可以与另一个表中的多条记录相关联, 也就是说描述了一个实体可以关联多个其他实体的场景!
这样来产生一对多关系 ,那么反过来也是一样, 一个表中的多条记录对应另一个表中的一条记录,也就是多对一 注意这是单向的!
实现方式
我们可以在多的一方建立外键,指向一的一方的主键 这样来建立一对多的关系表结构
应用场景
一对多的应用场景,那就要比一对一关系要多得多了,也是我们开发中最常见的逻辑关系
例如 部门与员工、公司与员工、分类与产品等等…范围可以说是相当广泛!
就好比说一个部门可以有多个员工,但一个员工只能属于一个部门 对吧!
所以我们在设计数据库表和业务逻辑的时候,要善于观察生活中,现实中哪些事物是属于一对多的关系,那么你就可以把它们设计成一对多的数据表,进行管理和查询!
我们这里还是用订单与客户的关系来举个例子吧!
在这个订单与客户场景中,我们可以分析一下:
一个客户可以下多个订单,但每个订单只能属于一个客户, 每个客户都有一个唯一的客户ID,而每个订单都有一个唯一的订单号ID,并且每个订单都会记录它所关联的客户ID是不是这样? 这就是典型的一对多(多对一)的关系!
那么我们把这个关系梳理之后,就可以来建立数据表了,很多人关系都没有梳理清楚,就马上开始写代码,这个习惯我个人觉得是非常不好的,也很不利于后期的维护和开发!
现在我们创建两个表Customers(客户表)和 Orders(订单表)
具体SQL如下
-- 创建客户表
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY IDENTITY, --客户ID
CustomerName NVARCHAR(100) NOT NULL, --客户名
ContactName NVARCHAR(100), --联系人姓名
Country NVARCHAR(50) --国家
);
-- 创建订单表
CREATE TABLE Orders (
OrderID INT PRIMARY KEY, --订单ID
OrderDate DATETIME NOT NULL, --下单日期
ShippedDate DATETIME, --发货日期
Status NVARCHAR(20), --订单状态
CustomerID INT, --所属客户ID
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) --关联关系
);
注意:我并没有为Orders表的CustomerID字段设置ON DELETE CASCADE(级联删除)
因为在实际开发中,是否要进行级联删除订单取决于具体的业务需求。
有时候,即使客户被删除,我们也可能希望保留他们的订单记录以供备案和历史分析
当然你也可以可以在FOREIGN KEY约束中添加ON DELETE CASCADE,这个随便你~~🎃🎃🎃
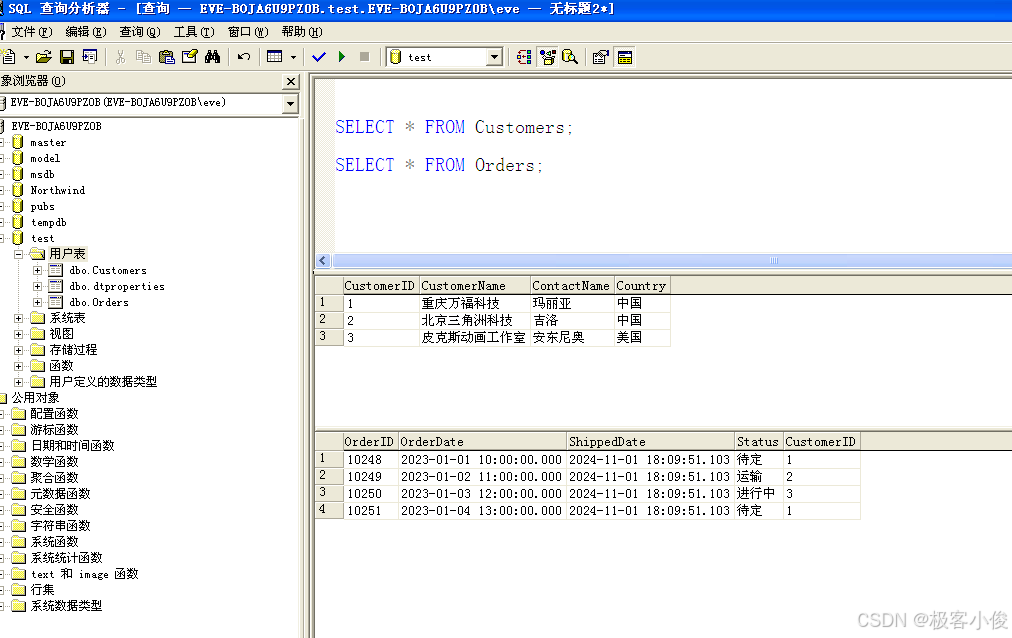
然后我们插入一些数据作为测试
如下
-- 插入客户数据
INSERT INTO Customers (CustomerName, ContactName, Country) VALUES ('重庆万福科技', '玛丽亚', '中国');
INSERT INTO Customers (CustomerName, ContactName, Country) VALUES ('北京三角洲科技', '吉洛', '中国');
INSERT INTO Customers (CustomerName, ContactName, Country) VALUES ('皮克斯动画工作室', '安东尼奥', '美国');
-- 插入订单数据
INSERT INTO Orders (OrderID, OrderDate, ShippedDate, Status, CustomerID) VALUES (10248, '2023-01-01 10:00:00', GETDATE(), '待定', 1);
INSERT INTO Orders (OrderID, OrderDate, ShippedDate, Status, CustomerID) VALUES (10249, '2023-01-02 11:00:00', GETDATE(), '运输', 2);
INSERT INTO Orders (OrderID, OrderDate, ShippedDate, Status, CustomerID) VALUES (10250, '2023-01-03 12:00:00', GETDATE(), '进行中', 3);
INSERT INTO Orders (OrderID, OrderDate, ShippedDate, Status, CustomerID) VALUES (10251, '2023-01-04 13:00:00', GETDATE(), '待定', 1);
如图
我们也可以使用inner join查询一下
SELECT * FROM Customers as c inner join Orders as o on c.CustomerID = o.CustomerID;
如图
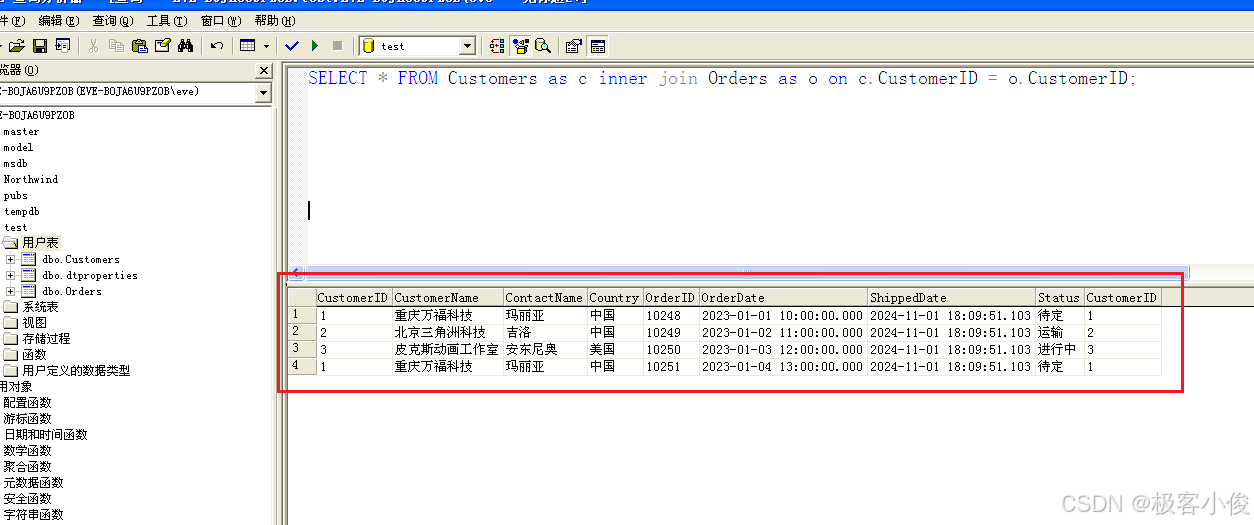
我们从查询的结果上其实可以看到,玛利亚这个客户有两个订单,以及订单的状态等信息!
以上就是一对多关系的实际应用场景之一 !
最经典的还要属于学生和学校的关系,也是一对多
如下
学生表
| ID | 学生姓名 | 年龄 | 性别 |
|---|---|---|---|
| 1 | 张三 | 20 | 男 |
| 2 | 张丽 | 22 | 女 |
| 3 | 小王 | 18 | 男 |
| 4 | 陈涛 | 23 | 男 |
| 5 | 杨博 | 30 | 男 |
学校表
| ID | 学校名 | 所在城市 |
|---|---|---|
| 1 | 清华 | 北京 |
| 2 | 复旦 | 浙江 |
| 3 | 重大 | 重庆 |
| 4 | 上海交大 | 上海 |
这种一对多的关系我们该如何起来?
根据外键应该建立在多的一方, 所以我们这个一对多关系应该建立在学生表中
| ID | 姓名 | 年龄 | 性别 | sid |
|---|---|---|---|---|
| 1 | 张三 | 20 | 男 | 3 |
| 2 | 张丽 | 22 | 女 | 1 |
| 3 | 小王 | 18 | 男 | 3 |
| 4 | 陈涛 | 23 | 男 | 2 |
| 5 | 杨博 | 30 | 男 | 4 |
有兴趣的朋友可以去把SQL实现出来,我们一起讨论!
所以 一对多关系非常常见,并且可以根据业务需求进行各种扩展和修改 非常灵活!
多对多 关系
定义
多对多关系指的是一个表中的一条记录可以与另一个表中的多条记录相关联
注意这种关系是一种双向的,而非单向!
举个栗子
常见的应用场景包括学生与课程、作者与书籍、演员与电影等等, 这些都需要你平常在生活中善于观察得来!
例如: 一个学生可以选择多门课程,而一门课程也可以由多个学生选择 对吧!
学生与课程的这种关系,你想一下, 是不是一个学生可以选多个课程,那么同时一个课程也可以被多个学生进行选择呢? 那么这种就是一种典型的多对多关系!
实现方式
多对多的关系通常我们是要通过第三张中间表来实现, 建立的第三张中间表平常我们也称为关联表或交叉表
这个中间表中至少包含两个外键,分别关联两方主键这样来关联!
应用场景
这里我们还是以学生与课程来举例!
在这个场景中,我们刚刚说过了一个学生可以选多门课程,同时一门课程也可以被多个学生选择 !
我们先把具体的数据表创建出来!
那么现在这个表应该如何建立呢? 其实也很简单!
需求分析
根据我们的分析, 首先应该把学生表和课程表这两个实体创建出来:
学生表中,每个学生都有一个唯一的学号,
课程表中, 每门课程都有一个唯一的课程号。
最后为了表示学生和课程之间的多对多关系,就需要一个额外的第三张表来存储这种关联关系的外键,这这个表也就是关联表或交叉引用表!
具体SQL如下
-- 创建学生表
CREATE TABLE Students (
StudentID INT PRIMARY KEY, --学生ID
StudentName NVARCHAR(100) NOT NULL --学生姓名
);
-- 创建课程表
CREATE TABLE Courses (
CourseID INT PRIMARY KEY, --课程ID
CourseName NVARCHAR(100) NOT NULL --课程名称
);
-- 创建学生和课程的关联表
CREATE TABLE S_C (
StudentID INT, --学生ID
CourseID INT, --课程ID
PRIMARY KEY (StudentID, CourseID), --联合主键
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
在企业管理器中去执行一下
如图
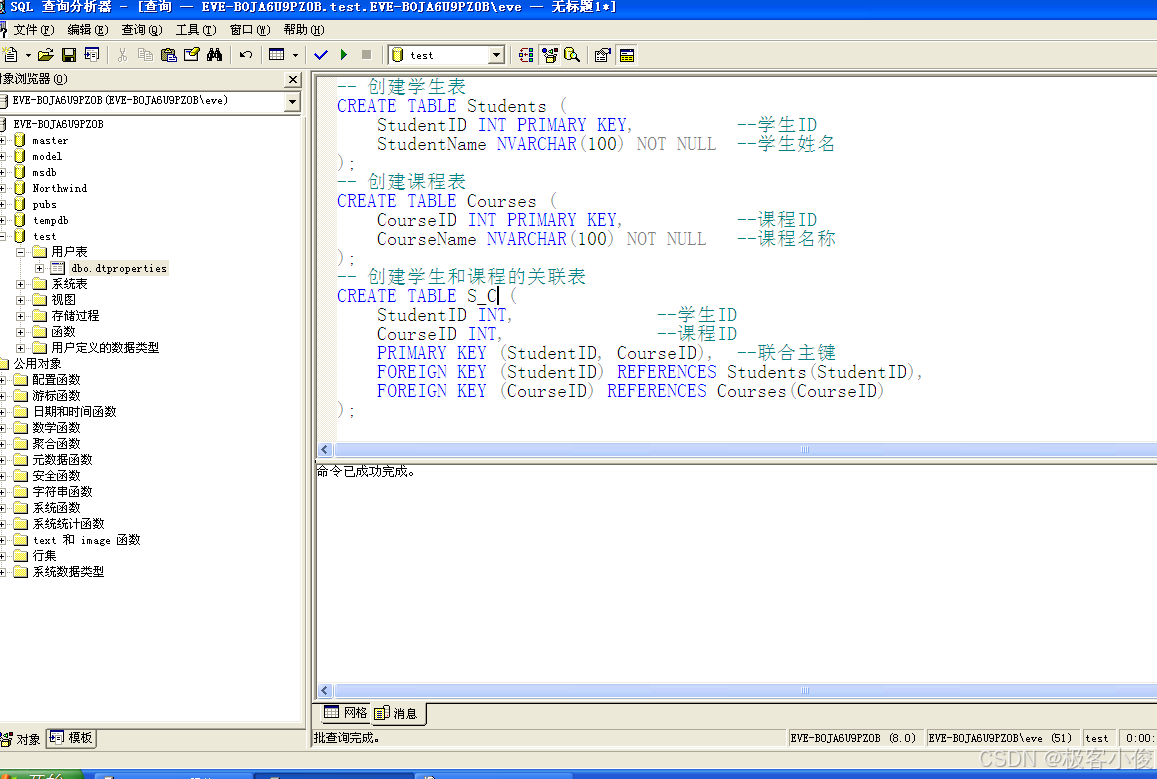
这里我们要注意一些创建表的问题:
联合主键
我们在创建S_C关联表中使用了联合主键
如下
PRIMARY KEY (StudentID, CourseID), --联合主键
为什么要这样设置呢?
首先是为了保证数据的唯一性约束, 你可以试想一下, 我们要确保了每个学生只能选修每门课程一次 ,你总不可能让某个学生选择某个课程多次吧,这样就会产生数据重复和冗余也就是说,我们要保证在S_C表中,不会出现重复的StudentID, CourseID键值对 ,不希望有重复的数据来表示同一个学生和同一门课程之间的关联, 那么这个时候联合主键就很重要了!
其次是为了数据完整性,这个我们前面也说过的,
这里的联合主键还帮助维护数据完整性, 你想一下, 由于StudentID和CourseID都是外键,它们分别引用了Students表和Courses表的主键, 对吧, 这意味着在S_C表中插入的StudentID和CourseID值必须在Students表和Courses表中存在, 为了防止了无效或孤立的关联被插入到数据库中, 所以这里我们要使用联合主键, 同时主键索引也有提高查询效率的作用!
总体来说创建这种联合主键就是为了保持数据的唯一性!
清楚之后,我们就来插入一些测试数据吧~
-- 插入学生数据
INSERT INTO Students (StudentID, StudentName) VALUES (1, '张三');
INSERT INTO Students (StudentID, StudentName) VALUES (2, '李四');
INSERT INTO Students (StudentID, StudentName) VALUES (3, '王五');
-- 插入课程数据
INSERT INTO Courses (CourseID, CourseName) VALUES (101, '数学');
INSERT INTO Courses (CourseID, CourseName) VALUES (102, '物理');
INSERT INTO Courses (CourseID, CourseName) VALUES (103, '化学');
-- 插入学生课程关联数据
INSERT INTO S_C (StudentID, CourseID) VALUES (1, 101);
INSERT INTO S_C (StudentID, CourseID) VALUES (1, 102);
INSERT INTO S_C (StudentID, CourseID) VALUES (2, 101);
INSERT INTO S_C (StudentID, CourseID) VALUES (2, 103);
INSERT INTO S_C (StudentID, CourseID) VALUES (3, 102);
INSERT INTO S_C (StudentID, CourseID) VALUES (3, 103);
如图
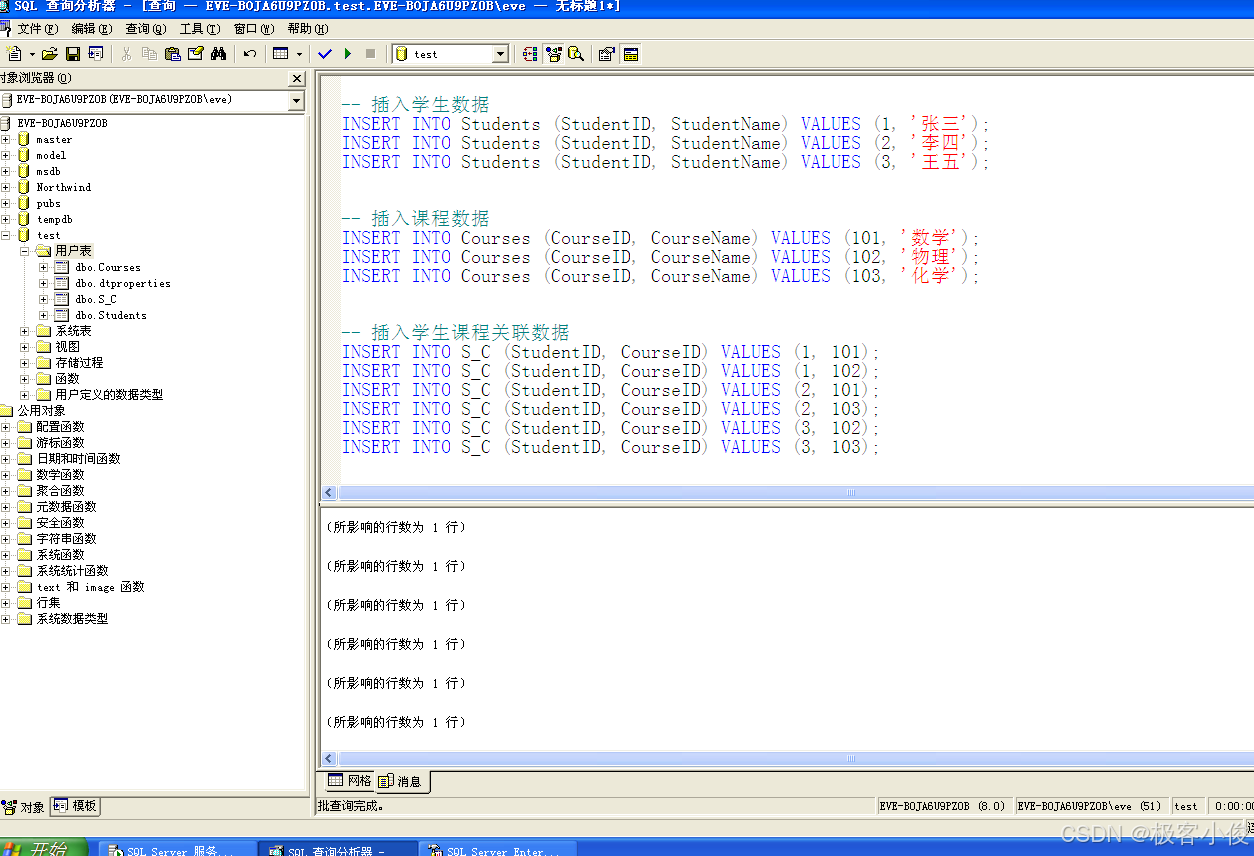
我们查询一下这几张表:
如图
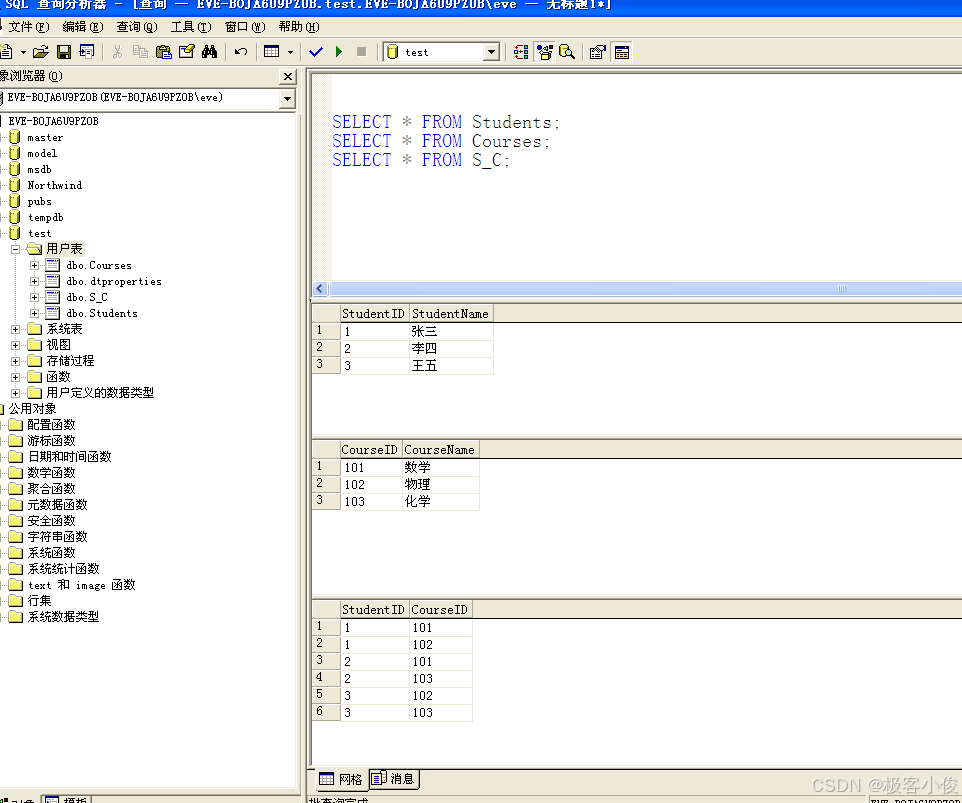
我们重点注意第三张表, 这就是多表查询的时候的重点!
这里我们简单的使用inner join来查询一下
这里我们查询一下: 每一门课都有哪些学生来学过!
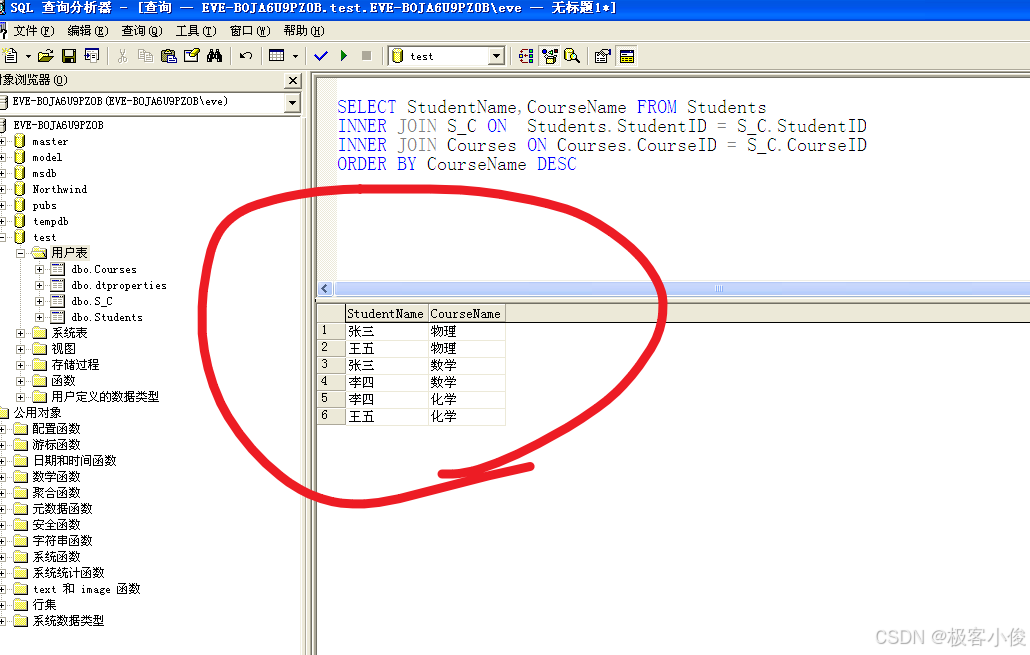
SELECT StudentName,CourseName FROM Students
INNER JOIN S_C ON Students.StudentID = S_C.StudentID
INNER JOIN Courses ON Courses.CourseID = S_C.CourseID
ORDER BY CourseName DESC
结果如图
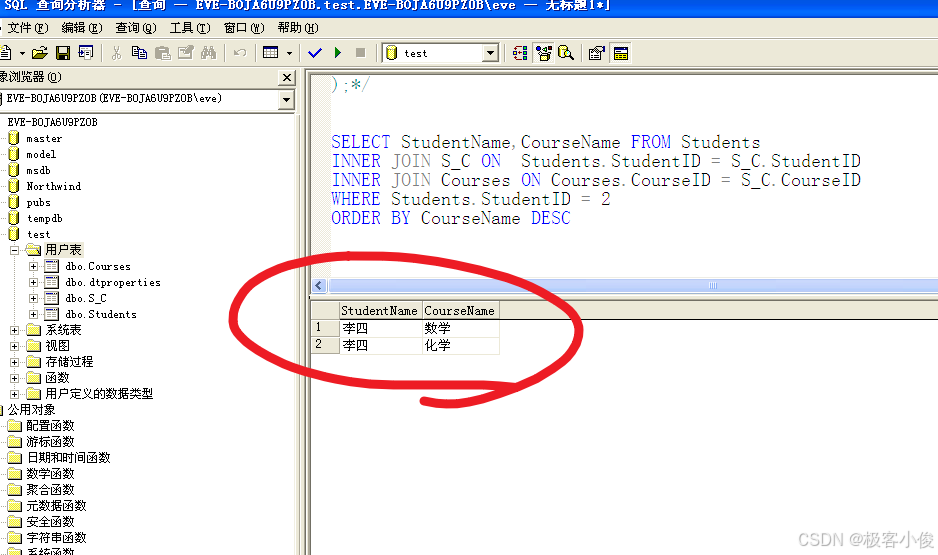
比如现在我们要查询李四选修了哪些课程!~ 其实我们只需要加一个where条件就可以啦
如下
SELECT StudentName,CourseName FROM Students
INNER JOIN S_C ON Students.StudentID = S_C.StudentID
INNER JOIN Courses ON Courses.CourseID = S_C.CourseID
WHERE Students.StudentID = 2
ORDER BY CourseName DESC
结果
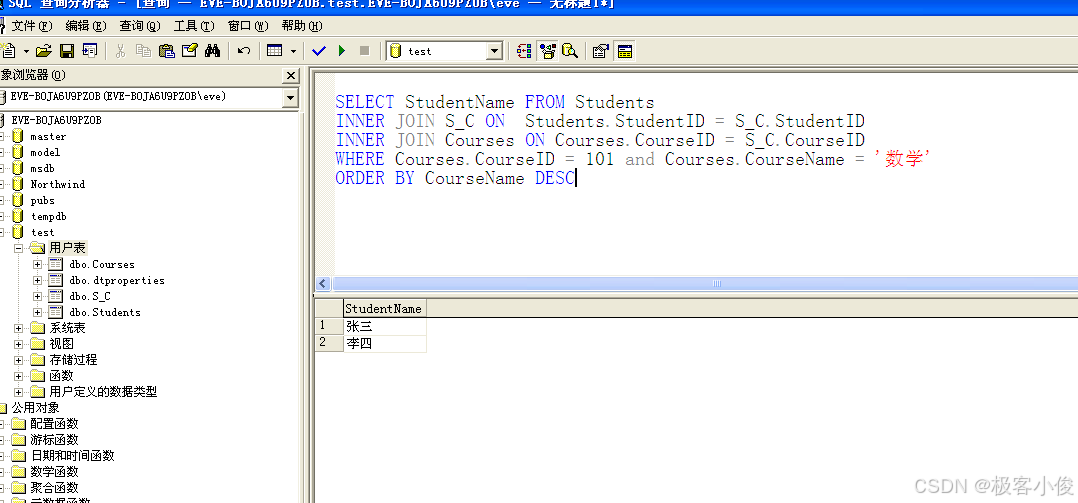
同时我们反过来也可以查询选修了数学的所有学生有哪些
SELECT StudentName FROM Students
INNER JOIN S_C ON Students.StudentID = S_C.StudentID
INNER JOIN Courses ON Courses.CourseID = S_C.CourseID
WHERE Courses.CourseID = 101 and Courses.CourseName = '数学'
ORDER BY CourseName DESC
如图
看是不是很简单呢!
关于inner join和多表查询我会在后面讲解!!
最后
总的来说数据库设计中的表与表之间关系千万不要去死记硬背,要灵活应用,
如果要彻底理解一对一、一对多、多对多的关系,也不是一两天的事情,需要你在很多不同的项目中进行实战和积累,慢慢才能完全掌握表的关系, 通过实际开发项目的应用场景,才可以更加深刻地理解这些关系,并能够在数据库设计中灵活运用。
绝对不应仅仅依靠这一点死记硬背,那你就学不到数据库的精髓了! 嘿嘿!!
以上这些关系在数据库设计中至关重要,它们决定了表结构的设计、数据的完整性和查询的效率,并且在一定程度上也影响你的后端代码逻辑开发!
所以在实际应用中,一定要先把需求梳理清楚,要根据业务情况和数据关系来合理的设计表!
那么今天就分享到这里啦,真心希望能帮助到大家,hohohoho 下期继续分享~~~~~~~~~~~~~~~~~~…级联删除


"👍点赞" "✍️评论" "收藏❤️"欢迎一起交流学习❤️❤️💛💛💚💚
好玩 好用 好看的干货教程可以点击下方关注❤️微信公众号❤️
说不定有意料之外的收获哦..🤗嘿嘿嘿、嘻嘻嘻🤗!
🌽🍓🍎🍍🍉🍇




















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









