






🚀 个人主页 极客小俊
✍🏻 作者简介:程序猿、设计师、技术分享
🐋 希望大家多多支持, 我们一起学习和进步!
🏅 欢迎评论 ❤️点赞💬评论 📂收藏 📂加关注

ANY和ALL介绍
这两个关键字通常都用于子查询,在你掌握了子查询的基本概念之后,就可以来使用这两个关键字进行查询数据了!
首先,我想告诉大家,这两个关键字其实属于运算符, 它们提供了强大的比较功能,使我们能够执行复杂的条件判断!
所以通常情况下, ANY和ALL这两个运算符必须要结合比较运算符一起使用!
语法规则
where 比较者 比较运算符 any (子查询)
在sql中我们熟悉的比较运算符通常都有>(大于)、>=(大于等于)、<(小于)、<=(小于等于)、=(等于)、<>不等于…这些运算符!
核心思想
ANY和ALL这两个运算符可以让我们将一个值与子查询返回的一组值进行比较, 以此来决定查询的结果,帮助我们更加精确的拉取数据!
ANY运算符
ANY运算符 用于查询某个值是否与子查询返回的任何值匹配!
也就是说当使用ANY关键字,只要子查询中的任何一个值满足比较条件,整个表达式就返回true, 如果没有满足的条件,那直接false,也就是没有结果被查询出来了!
这样说我觉得大家肯定还是一头雾水,这样吧,我们直接看一个案例,你马上就回明白了!
举个栗子
我们首先看一下表结构!
如图
那么现在我们提一个问题需求: 我们现在要查询出哪些分数低于浙江地区任意一个分数人的信息
sql如下
SELECT * FROM Persons WHERE pScore < ANY (SELECT pScore FROM Persons WHERE pAddr = '浙江');
如图
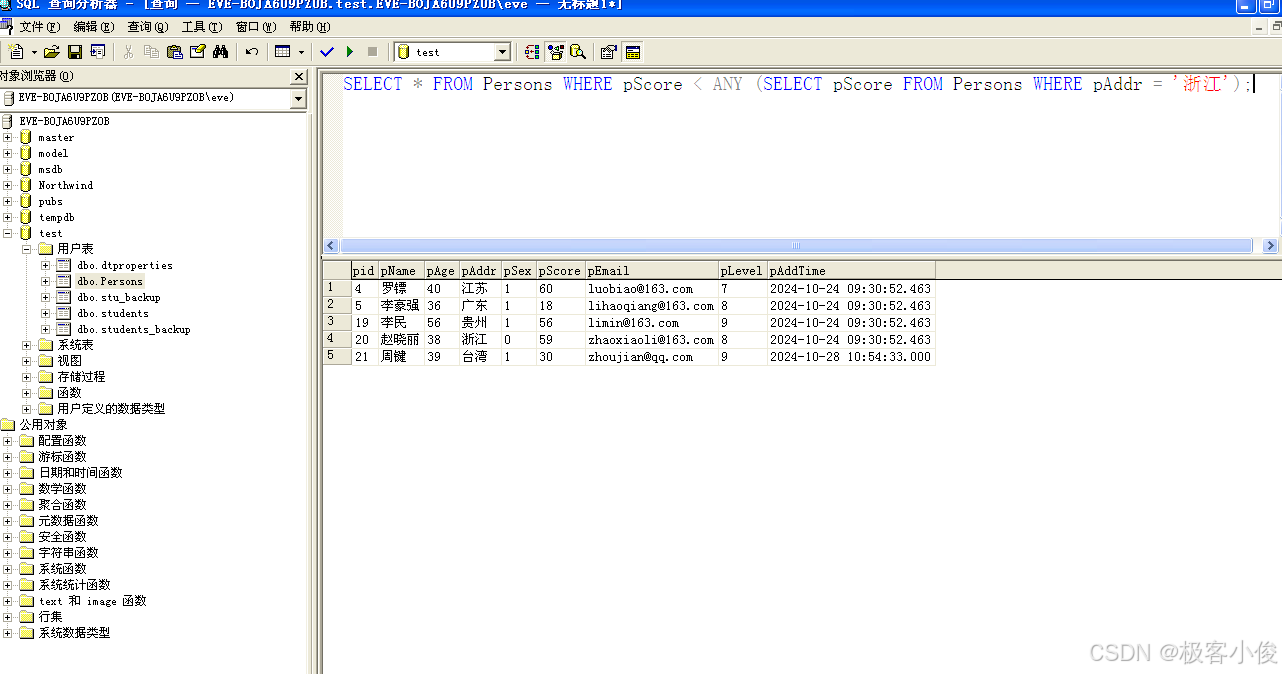
当我们这样看结果可能你还是不懂,让我们来把这个SQL拆分开就能明白了!
我们先把这个子查询单独提取出来!
SELECT pScore FROM Persons WHERE pAddr = '浙江'
如图
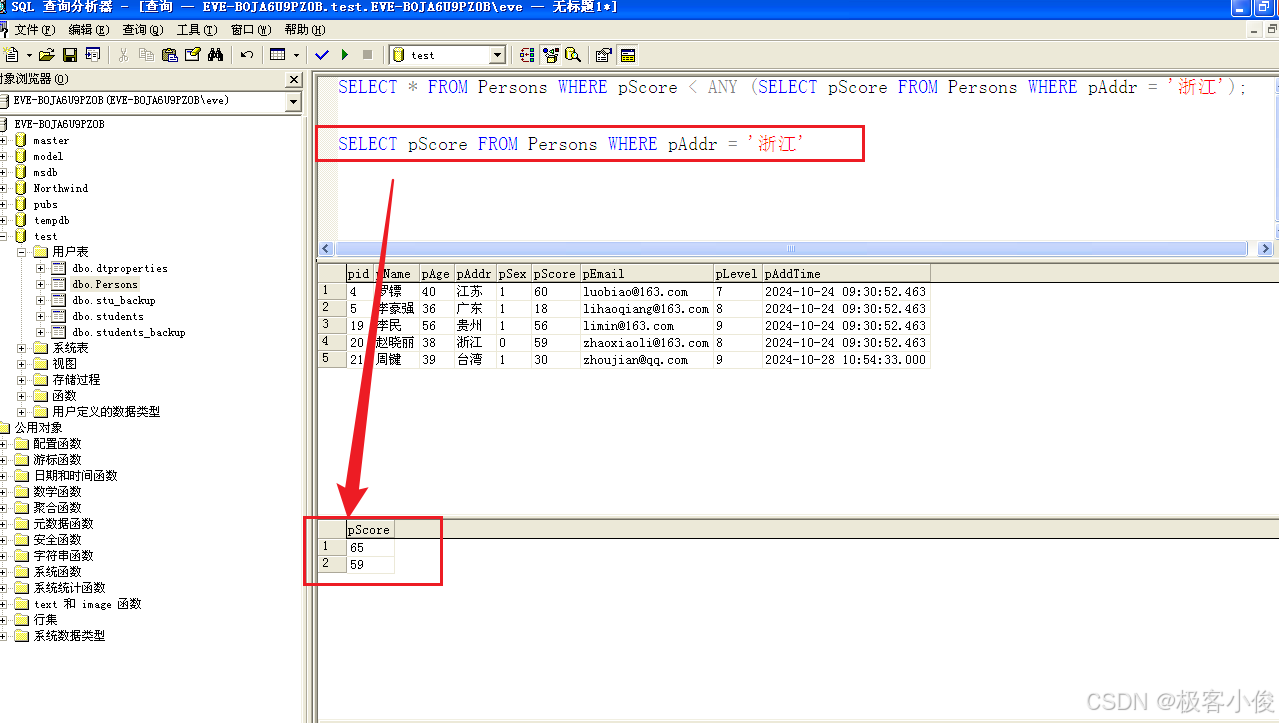
那么这里是不是先把浙江的所有分数都查询出来了呢! 那么好,继续把这个查询封装为子查询,注意它能返回一组值 对吧, 那么让这一组值 去比较,所有人的分数,这里我们比较的条件为小于
所以也就是说所有人的分数如果小于浙江地区其中任意一个人的分数都可以被查询出来!
这里应该是满足了浙江地区里面第一个分数条件65
如果把SQL写直白一点也就是这样
SELECT * FROM Persons WHERE pScore < 65
如图
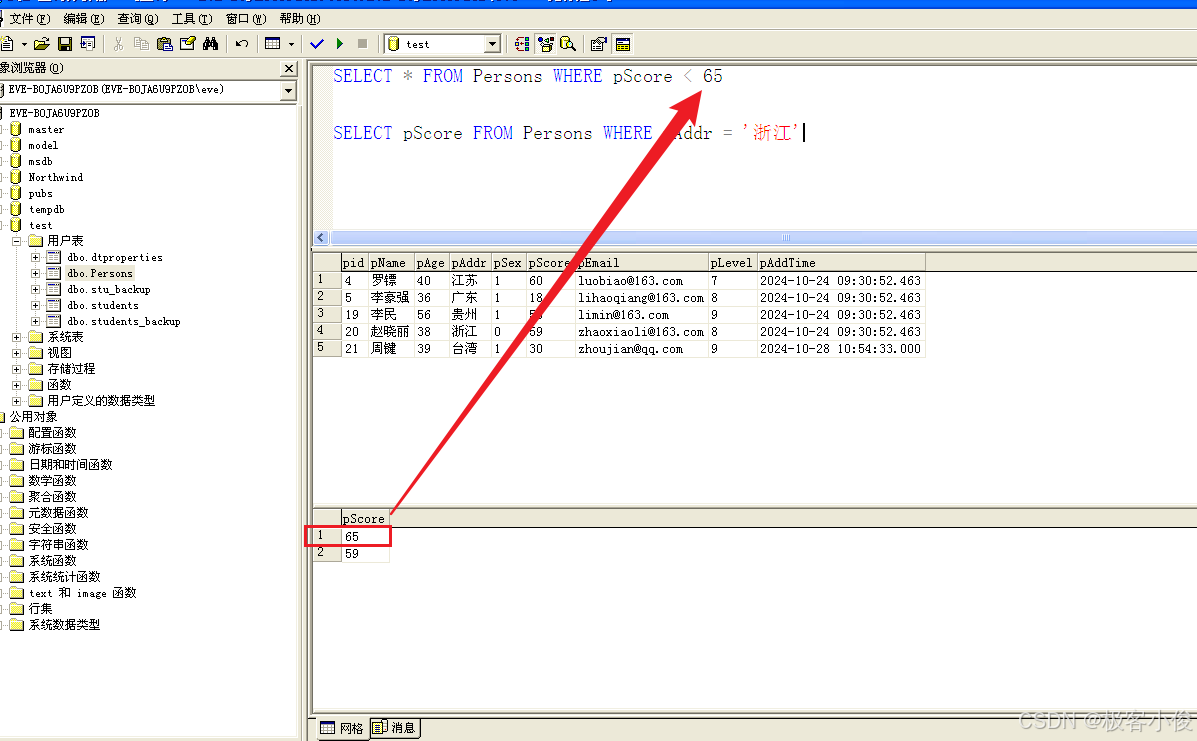
这里很明显65就成为了一个能满足表达式的条件!~
ANY的一个疑问
但是这里又有人问那么 ANY 到底是以什么依据去匹配条件组中的哪一个值呢?是第一个还是最后一个? 还是随机?
其实它并不是基于条件组中的第一个、最后一个或随机一个值来进行匹配的, 相反ANY 会与子查询返回的结果集中的任意一个值进行比较, 那怎么一个任意法呢?
我们具体要看一下当执行一个包含 ANY的查询时执行步骤:
-
执行子查询:首先数据库会执行子查询,并返回一个结果集, 这个结果集包含了与子查询条件相匹配的所有值, 这个没什么问题! -
逐个比较:这里就很关键了,数据库会将主查询中的值与子查询返回的结果集中的每一个值进行逐个比较! -
最后确定结果:也就是说如果主查询中的值与子查询返回的结果集中的至少一个值满足比较条件如 <, >, =, <=, >=, <>),那么则整个ANY 表达式的结果为true!
ANY运算符的核心总结
一句话ANY 运算符只要满足子查询结果集中的任意一个条件,整个 ANY 表达式就为真,就把这些条件成立的数据拉取出来!
那么换句话说,ANY运算符 可以让我们在一组值中找到一个满足条件的值,而不需要所有值都满足!
所以上面的案例中,一组值里面有 65和59 虽然都逐个比较过,但是一上来65基本上都满足相应的条件!~
ALL 运算符
你如果搞懂了ANY就能马上明白,ALL运算符的含义!
ALL关键字它也是用于与比较运算符(如<, >, =, <=, >=, <>)配合使用!
ALL运算符其实就是与一组值进行全局比较, 也就是它会对子查询返回结果集中的值全部比较,并且全部都要满足的情况下,那么表达式才能为true, 如果不满足条件那直接false,也就是没有结果被查询出来了!
ALL运算符核心思想
就是全局比较 用于查询结果集中的所有行,确保比较条件对于结果集中的所有值都成立, 并且ALL运算符通常与子查询一起使用,子查询返回一个结果集,然后主查询中的值与这个结果集中的所有值进行比较,并且都必须成立才行!
举个栗子
还是之前我们说过的,比如查询Persons表中分数高于重庆地区所有人分数的其他人的数据记录!
SQL如下
SELECT * FROM Persons WHERE pScore > ALL (SELECT pScore FROM Persons WHERE pAddr = '重庆');
如图
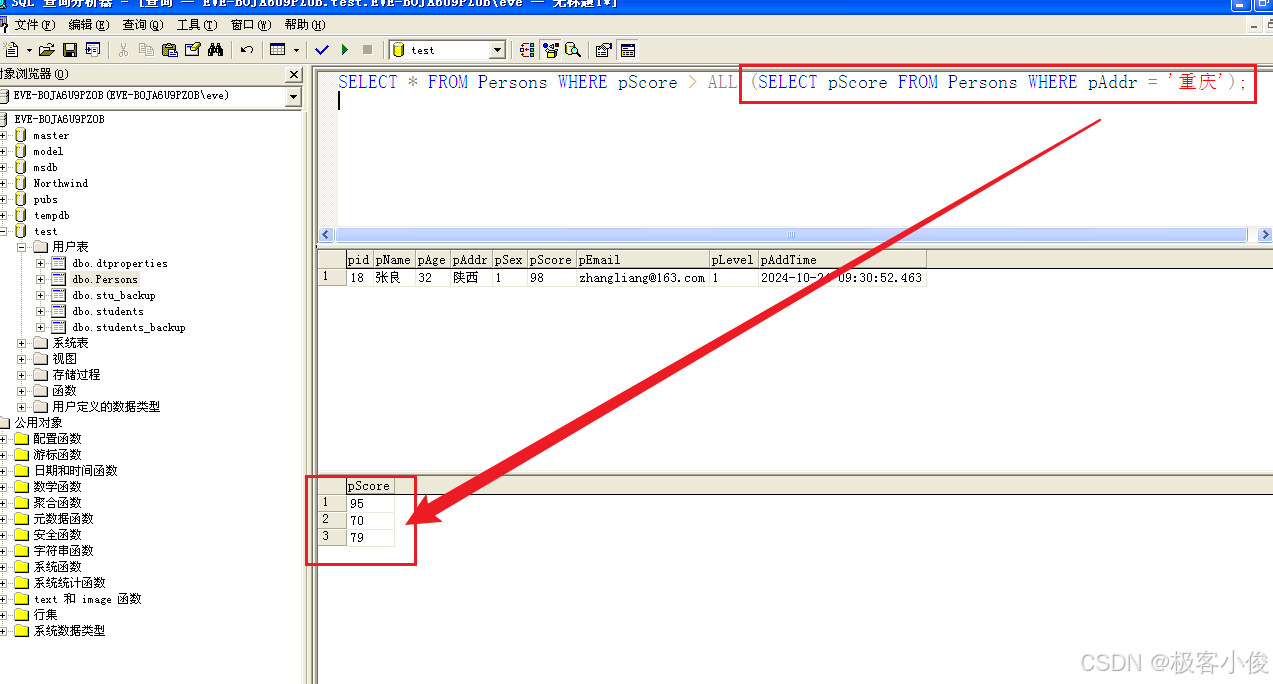
那么其实如果你还不明白,我们就可以把这个SQL拆开来看!
如下
首先子查询中返回了一组值 对吧!
SELECT pScore FROM Persons WHERE pAddr = '重庆'
如图
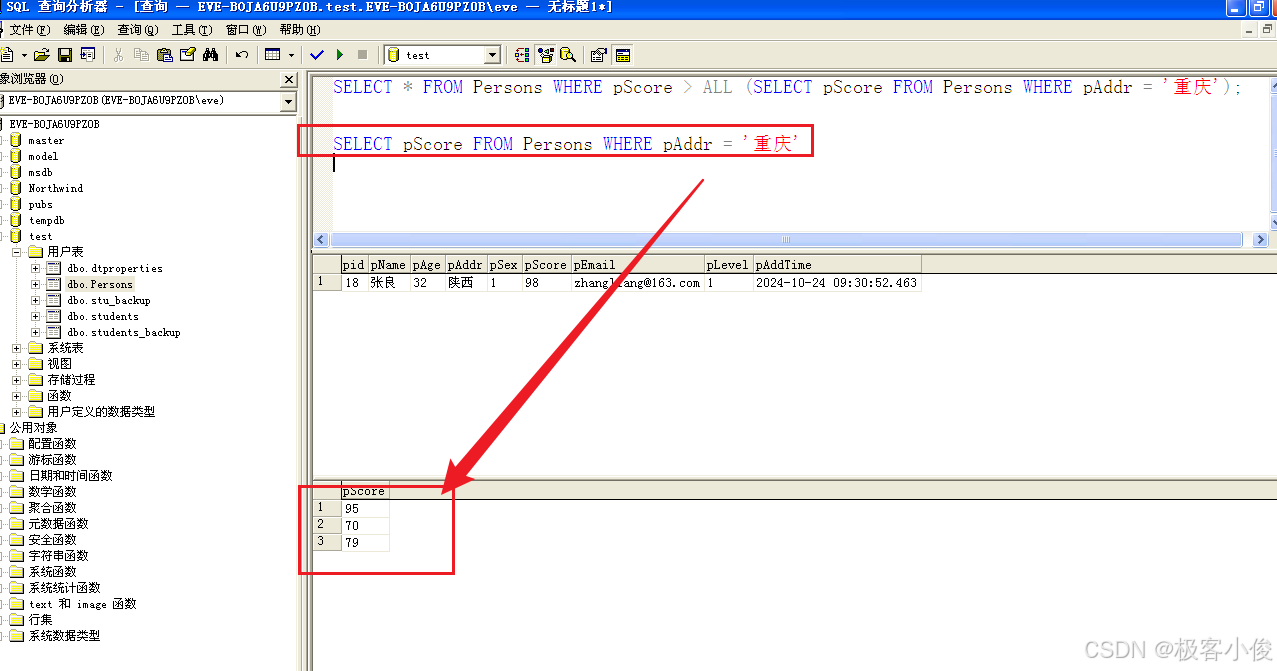
那么这一组值 每一个值 都会去和主查询进行条件比较,并且都要成立!
其实我们可以把SQL修改为如下形式,不使用ALL运算符你就明白了!
如下
SELECT * FROM Persons WHERE pScore > 95 and pScore > 70 and pScore > 79
你可以看看 执行结果 是不是完全一样!
如图

这个查询的逻辑其实也就只有当某个人的分数比重庆地区所有人的分数都高时,这个人的记录才会被选中!
现在明白了ALL关键字的使用方法了吧, 它与ANY关键字的区别在于ALL要求与结果集中的所有值进行比较,而不是任意一个值。这与ANY关键字不同,ANY只要求与结果集中的任意一个值进行比较!
特别注意
出于性能考虑使用ALL运算符进行全局比较时,子查询返回的结果集大小会影响查询性能, 可能会导致较高的CPU和I/O消耗
所以如果子查询返回的结果集很大,那么主查询的性能可能会受到影响, 在可能的情况下,我们应该尽量优化子查询以提高性能!
应用场景
我们利用子查询结合ANY和ALL实现多表查询
例如:
我们现在有这样两个数据表!
如下
Employees 表:
---EmployeeID(员工ID)
---Name(姓名)
---DepartmentID(部门ID)
---Salary(薪水)
Departments 表:
---DepartmentID(部门ID)
---DepartmentName(部门名称)
我们用SQL把这两个表结构实现建立出来!
如下
/*部门表*/
CREATE TABLE Departments(
DepartmentID int PRIMARY KEY IDENTITY, --部门ID
DepartmentName varchar(255) NOT NULL, --部门名
)
/*员工表*/
CREATE TABLE Employees(
EmployeeID int PRIMARY KEY IDENTITY, --员工ID
Name varchar(255) NOT NULL, --员工姓名
DepartmentID TINYINT NOT NULL, --部门ID
Salary int NOT NULL --薪水
)
我们执行一下
如图
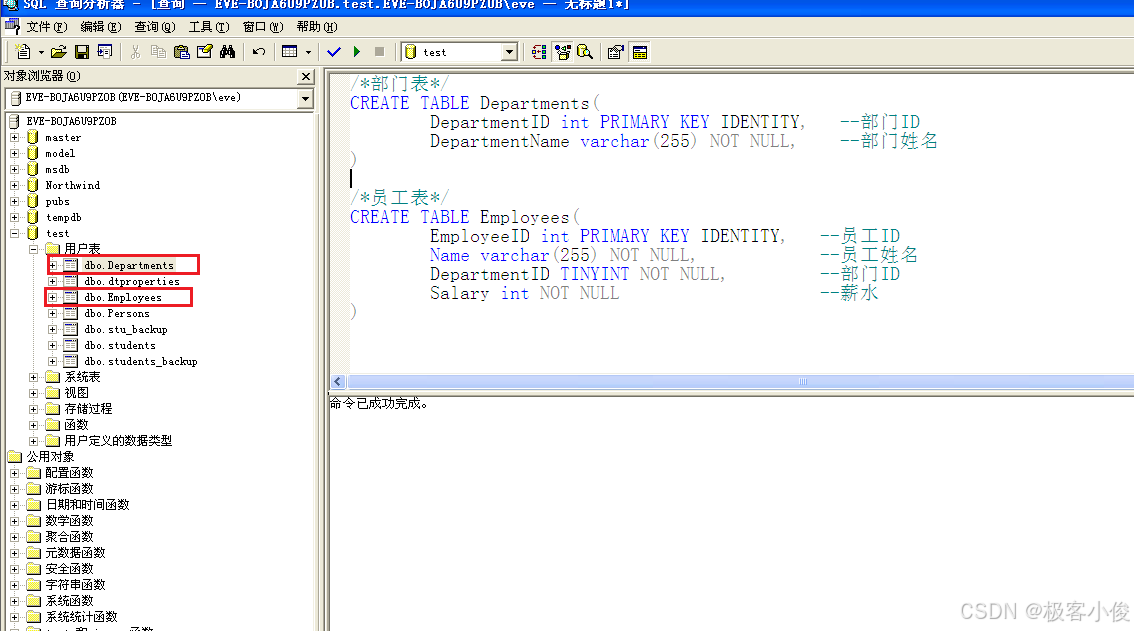
同时,我们在这两个表中加入一些数据!
INSERT INTO Departments(DepartmentName) VALUES('技术部');
INSERT INTO Departments(DepartmentName) VALUES('销售部');
INSERT INTO Departments(DepartmentName) VALUES('市场部');
INSERT INTO Departments(DepartmentName) VALUES('推广部');
INSERT INTO Departments(DepartmentName) VALUES('运营部');
INSERT INTO Employees(Name,DepartmentID,Salary) VALUES('张三',2,3000);
INSERT INTO Employees(Name,DepartmentID,Salary) VALUES('李四',2,2500);
INSERT INTO Employees(Name,DepartmentID,Salary) VALUES('王五',1,5000);
INSERT INTO Employees(Name,DepartmentID,Salary) VALUES('赵云',5,8000);
INSERT INTO Employees(Name,DepartmentID,Salary) VALUES('李逵',4,6800);
INSERT INTO Employees(Name,DepartmentID,Salary) VALUES('张謇',3,4900);
如图

准备好数据之后,我们就可以来查询一下了
如图

比如: 查询出所有薪水高于所以在销售部门工作的员工的薪水的员工
我们其实可以把这个SQL拆分,最后再组合!
如下
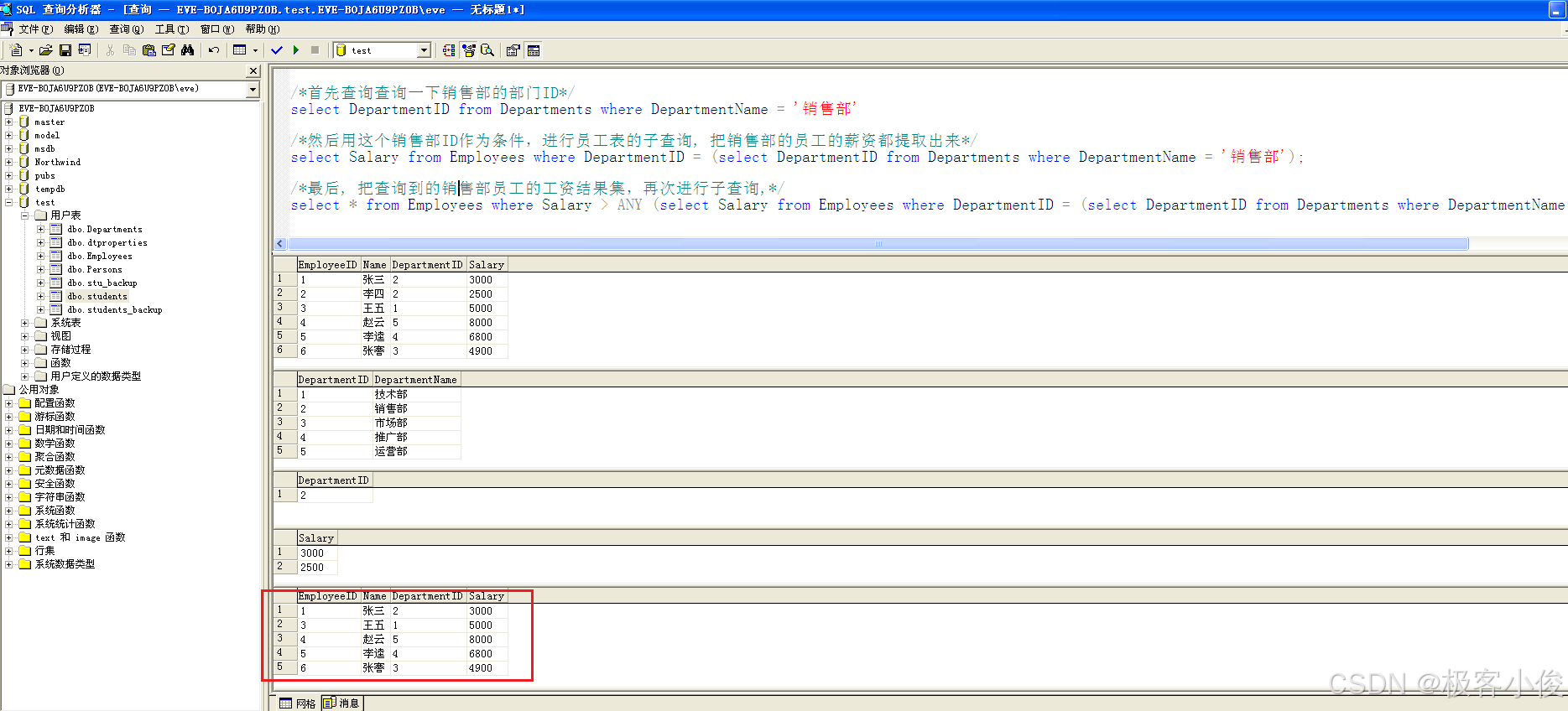
/*首先查询查询一下销售部的部门ID*/
select DepartmentID from Departments where DepartmentName = '销售部'
/*然后用这个销售部ID作为条件,进行员工表的子查询, 把销售部的员工的薪资都提取出来*/
select Salary from Employees where DepartmentID = (select DepartmentID from Departments where DepartmentName = '销售部');
/*最后, 把查询到的销售部员工的工资结果集,再次进行子查询,*/
select * from Employees where Salary > ALL (select Salary from Employees where DepartmentID = (select DepartmentID from Departments where DepartmentName = '销售部'))
如图
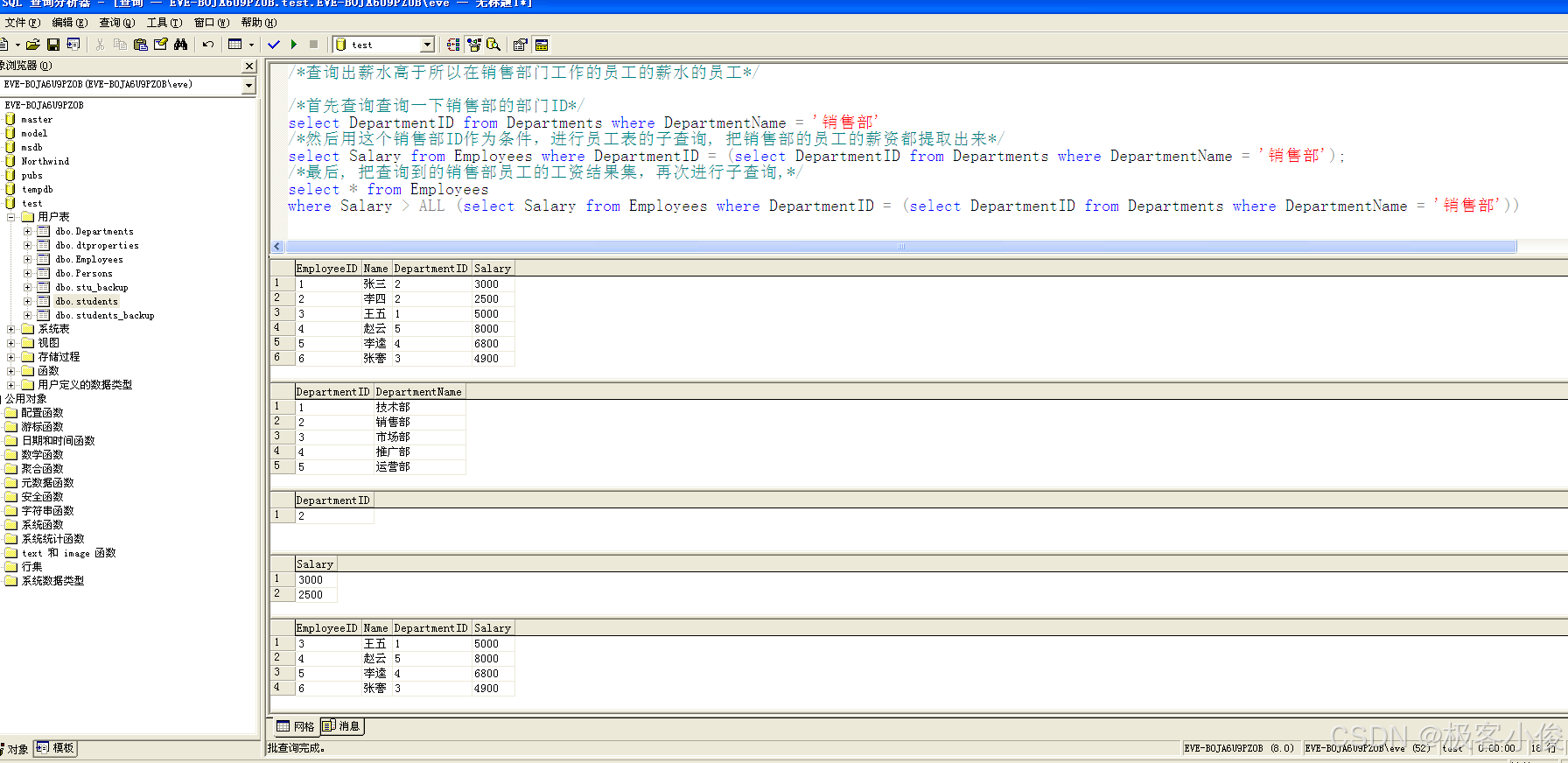
这里我们用到了ALL运算符,比较了子查询结果集中所有的条件!
那么如果我们把ALL修改成了ANY,那么意思就变了
那么我们查询出来的结果将会是找出所有薪水高于任何一个在销售部门工作的员工的薪水的员工
select * from Employees where Salary > ANY (select Salary from Employees where DepartmentID = (select DepartmentID from Departments where DepartmentName = '销售部'))
如图
最后总结
ANY如果一个值与子查询结果集中的任意一个值满足比较条件,则条件为真。
ALL如果一个值与子查询结果集中的所有值都满足比较条件,则条件为真。
这两个关键字在处理涉及子查询的复杂条件时非常有用,可以帮助我们更灵活地查询数据, 在以后我们实际开发项目中也会使用到!
并且这里还要注意一个地方,就是和IN关键字的区别, 虽然ANY和ALL与IN运算符都涉及到与子查询结果的比较,
但它们的用途和逻辑完全不同!
IN用于检查一个值是否存在于子查询结果列表中,而ANY和ALL则分别用于检查是否至少存在一个或所有值满足特定的比较条件, 这里要区别开来!


"👍点赞" "✍️评论" "收藏❤️"欢迎一起交流学习❤️❤️💛💛💚💚
好玩 好用 好看的干货教程可以点击下方关注❤️微信公众号❤️
说不定有意料之外的收获哦..🤗嘿嘿嘿、嘻嘻嘻🤗!
🌽🍓🍎🍍🍉🍇




















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









