







 本文探讨了数据清洗子系统如何通过批过滤器识别数据质量问题,并详细介绍了四种数据质量控制方法:列属性约束、结构约束、数据约束和值约束。此外,还讲解了数据评估的基本规则,包括定义无效值、数字列的范围、字符列长度限制以及表大小等。
本文探讨了数据清洗子系统如何通过批过滤器识别数据质量问题,并详细介绍了四种数据质量控制方法:列属性约束、结构约束、数据约束和值约束。此外,还讲解了数据评估的基本规则,包括定义无效值、数字列的范围、字符列长度限制以及表大小等。
过滤器及其度量
在数据体系中,总会有一些数据看起来没什么问题,一旦联系了上下文或者和其它数据放在一起就会发现数据存在问题,我们称这样的数据为异常数据。
在监测数据异常时,通常采用一下方式:
数据采样:对有问题的列进行分组,计算该表的行数,可以使用数据评估工具
约束类型:把各种不同类型的数据质量检查分为四大类型
√ 列属性约束:保证由源系统输入的数据包含系统的期望值,列属性约束检查的过滤器包括:检查列的空值、超出期望的最高和最低范围的数值、长度超长和超短的列、包含有效值列表之外的数值、匹配所需的格式或一组格式、在已知的错误值列表中命中数、拼写检查器
√ 结构约束:对列之间的关系进行约束,也检查层次间的父子关系
√ 数据约束:业务规则约束或逻辑检测
√ 值约束:一般采用在表中单独加标记列,标记错误状态或次数
数据质量处理的整个流程如下图:
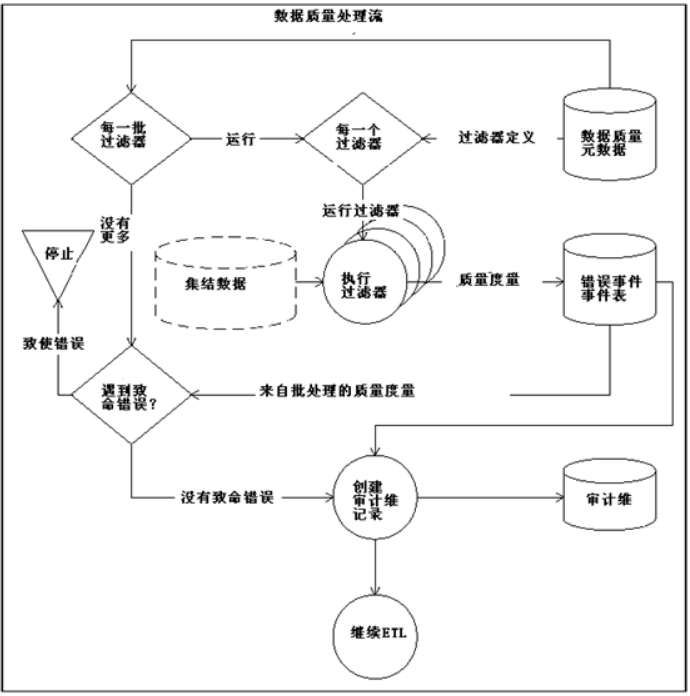
数据清洗子系统的处理流程目标是触发可以并行运行的批过滤器,这些过滤器识别出数据质量问题,并在错误事件事实表中插入记录。数据清洗子系统完成清洗处理并规范化记录后,还需要为审计维给出整个数据质量得分。
书中建议的运行过滤器的方法是建立一个通用的软件模型,可以执行任何过滤器,只需要设置批处理ID和过滤器代理键作为参数即可。数据清洗子系统在记录数据质量错误时应该持续运行,不能跳过记录或者停止ETL系统,因此数据清洗子系统必须提供一些处理意想不到情况的机制。在此,又提到了数据质量、系统可信性的平衡关系。在运行过滤器前,应该要先建立一个全局的数据评估基本规则,其中包括定义无效值、数字列的范围,字符列长度限制以及表大小等属性限制。一个数据评估的检查列表应该包括:
- 为抽取的表提供每天记录数的历史
- 提供每天的关键业务度量的总数
- 确定需要的列
- 确定需要唯一的列集合
- 确定允许(以及不允许)为空的列
- 确定数字字段的可接受数值范围
- 确定字符列的可接受字符长度
- 为所有列定义明确的有效数值集
- 确定列中无效值(不在有效值集合中)出现的频繁程度
规范化报表
数据集成意味着创建规范化的维,以及通过组合来自多个数据源的最有效信息为一个综合的视图来创建的事实实力。按照标准化、匹配和删除重复记录、生存三个构建规范化维和事实的步骤来描述。
规范化维和规范化事实是对于从多个分离的事实表组合数据的最终用户应用来说,我们必须为这些事实表提供统一的界面,这样数据才可以被整合。规范化为对于每一个可以被关联的事实表来说都是相同的。在实际环境中,经常需要规范化的维包括:客户维、产品维、地理维、促销维和日期维等。数据仓库设计团队的主要职责是创建、发布、维护和约束规范化维。大多数规范化维很自然的被定义成原子级别。客户维和产品维使用最小粒度以便与原系统的条目对应。日期维的力度通常为天。
本篇介绍了数据清洗和规范化的四个大主题:目标、技巧、元数据和度量。下一篇将详细介绍提交维表的内容。

















 1697
1697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









