







 本文探讨了C++中的sizeof操作符,它在编译时确定对象大小,并涉及内存对齐规则。规则一指出类大小为内部最大变量的整数倍,规则二描述了变量在内存中的排列方式。通过示例展示了不同编译器和平台下的sizeof行为差异,强调了理解内存对齐对解决编程问题的重要性。此外,还提到了sizeof在动态内存分配和数组大小获取中的应用。
本文探讨了C++中的sizeof操作符,它在编译时确定对象大小,并涉及内存对齐规则。规则一指出类大小为内部最大变量的整数倍,规则二描述了变量在内存中的排列方式。通过示例展示了不同编译器和平台下的sizeof行为差异,强调了理解内存对齐对解决编程问题的重要性。此外,还提到了sizeof在动态内存分配和数组大小获取中的应用。
上一篇中已经提到了由于cpu的寻址特性,导致只能读取某些地址的数据,因此就有了一个对齐的概念,编译器会为我们的程序中私自添加一些填充数据,使得对象在内存中能够对齐,从而获取更佳的存取速度。
C++中获取一个对象大小的操作符,之所以说是操作符,因为sizeof并不是一个语句,而是一个C++的内置操作符,sizeof的值在编译的时候,就已经定下来了,不需要等到运行时,通过sizeof来学习C++中数据是如何对齐的,对齐的规则又是什么。
规则一
整个类的大小应该为内部最大变量所占字节数的整数倍
class A
{
public:
virtual void f1() {}
int a;
char b;
};
上面sizeof(A)的大小为16,因为虚函数表指针要占一个long类型的大小为8,int占4字节,char占1字节,8+4+1=13,但是需要满足对齐规则一,因此扩充3个字节,总大小为16.
规则二
在基类里面,仅仅内部非静态成员变量和虚函数表指针占用空间,其他的不占空间,每个变量的偏移位置应该为该变量大小的整数倍。
class A
{
public:
char c = 1;
int a = 2;
short b = 3;
void f1() {}
};
1+4+2=7,函数不占空间,根据规则二,偏移量应该为该变量大小的整数倍,所以int a的位置应该是第4位,而不是紧接着char的第1个位置,又因为规则一,需要整个大小对齐,因此总大小:1+3(填充)+4+2+2(填充)=12,其内存分布如下图:
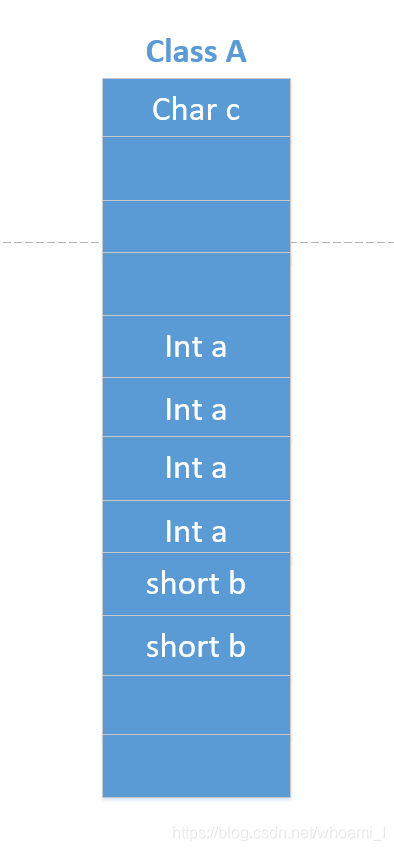
可以使用下面这段程序验证:
A *pa = new A();
cout << (int)*(long *)((char *)pa + 4) << endl; //输出a的值2
cout << (short)*(long *)((char *)pa + 8) << endl; //输出b的值3
其实对齐的规则就是上面两条,如果我们想自己决定对齐规则,可以使用#pragma pack(n)来改变对齐规则,这条语句也有两条对齐规则:
1、对于偏移对齐,若n大于该变量的大小,那么按照类默认对齐方式;否则按照n字节对齐方式放置该变量位置。(最小原则)
2、对于整个变量的大小,若n大于类里面所有的变量大小(也就是大于最大变量大小),那么类大小为默认的;否则为n的倍数。(最小原则)
举个例子:
class A
{
#pragma pack(2)
public:
char c = 1;
int a = 2;
short b = 3;
void f1() {}
};
sizeof大小为8,char占1字节,int大小为4,4大于2,按照最小原理,int的偏移为2的倍数,所以中间填充了一个字节,short偏移为6,符合规则1,这样整个大小为8,符合规则2,不用填充。
下面看一看在继承的时候,sizeof的行为会是如何:
class A
{
public:
char c = 1;
int a = 2;
short b = 3;
};
class B : public A
{
short b;
};
class C : public B
{
public:
short c;
};
上面这段代码在不同的编译器上跑出来的结果还不一样:
Visual studio结果为12、16、20.
Gcc结果为12、16、16
这说明了对齐规则本身是和编译器息息相关的,而且和具体的平台也有关系,因此我们一般不要使用sizeof去做一些什么判断,因为你会发现不同的平台结果不一样,我们只是通过sizeof去讲cpu是有对齐这个概念的,通过这个对齐的规则去了解C++编译器具体对我们的源代码干了什么,class内存布局是怎样的,使得在实际使用的时候如果出现问题,能够多一个思路去想出可能的解决方案。
sizeof一个比较常见的用处就是在C语言中获取一块所需大小的内存空间:
struct A *pa = (struct A*)malloc(sizeof(struct A));
还有就是获取数组的大小:
int c[] = {1,2,5,657,8,7};
int num = sizeof(c)/sizeof(c[0]);
能够获取的根本原因还是c中的数组都是固定大小的,当在堆上分配数组时,sizeof就不管用了。

















 4531
4531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









