




1.分区表的介绍
在Hive中处理数据时,当处理的一张表的数据量过大的时候,每次查询都是遍历整张表,显然对于计算机来说,是负担比较重的。所以我们可不可以针对数据进行分类,查询时只遍历该分类中的数据,这样就能有效的解决问题。所以就会Hive在表的架构下,就会有分区的这个概念,就是为了满足此需求。
分区表的一个分区对应hdfs上的一个目录。
分区表包括静态分区表和动态分区表,根据分区会不会自动创建来区分。
多级分区表,即创建的时候指定 PARTITIONED BY (event_month string,loc string),根据顺序,级联创建 event_month=XXX/loc=XXX目录,其他和一级的分区表是一样的。
2.静态分区表
-
创建一张分区表:
hive (default)> create table order_partition( > oder_no string, > oder_time string > )partitioned by (event_month string) > row format delimited fields terminated by '\t'; //创建一张静态分区表OK
Time taken: 0.142 seconds
hive (default)> load data local inpath ‘/home/hadoop/data/order_created.txt’ overwrite into table order_partition partition (event_month=‘2019-07’); //向分区表中导入本地数据
Loading data to table default.order_partition partition (event_month=2019-07)
Partition default.order_partition{event_month=2019-07} stats: [numFiles=1, numRows=0, totalSize=213, rawDataSize=0]
OK
Time taken: 0.652 seconds
hive (default)>
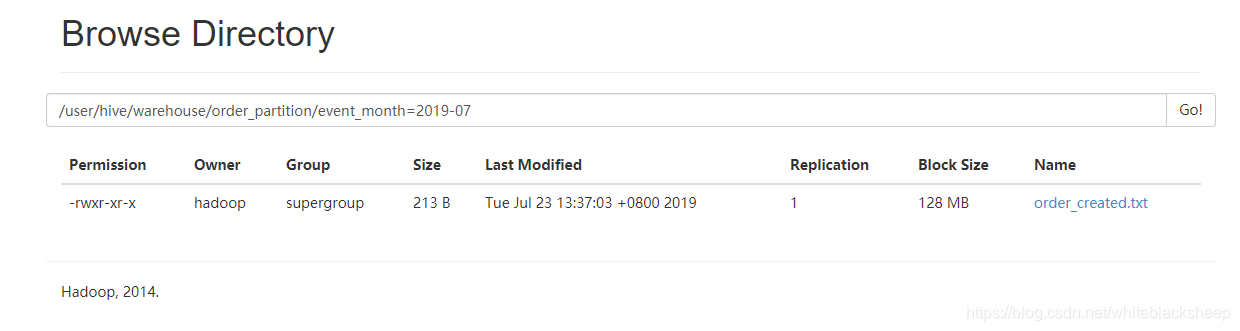
如图下图:我们此时可以看到在order_partition/目录下建了一个event_month=2019-07目录,导入数据后,可以看到目录文件夹下有一个order_created.txt文件。
注意:之前在练习的时候,导入数数据一直报下面的错误:
hive (default)>
> load data local inpath '/home/hadoop/data/order_created.txt' overwrite into table order_partition partition (event_month='2019-07');
Loading data to table default.order_partition partition (event_month=2019-07)
Failed with exception MetaException(message:For direct MetaStore DB connections, we don't support retries at the client level.)
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
最后发现是因为mysql驱动包的版本兼容问题,导致存放元数据的mysql的默认库始终没有partitions这张表,因为我之前用的mysql-connector-java-8.0.16.jar版本太高,把他换成5版本的,然后在重新执行hive命令就能够在mysql默认库中找到partitions这张表,然后再导入数据就成功了。
查看创建表时在hdfs上创建的目录:
[hadoop@hadoop001 ~]$ hadoop fs -ls /user/hive/warehouse/order_partition/
19/07/23 14:27:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-07-23 13:37 /user/hive/warehouse/order_partition/event_month=2019-07
-
通过文本形式给2019-08分区上传本地数据信息
1.先在hdfs上给2019-08分区创建一个目录[hadoop@hadoop001 ~]$ hadoop fs -mkdir -p /user/hive/warehouse/order_partition/event_month=2019-08 19/07/23 14:30:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@hadoop001 ~]$ hadoop fs -ls /user/hive/warehouse/order_partition/ 19/07/23 14:30:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items drwxr-xr-x - hadoop supergroup 0 2019-07-23 13:37 /user/hive/warehouse/order_partition/event_month=2019-07 drwxr-xr-x - hadoop supergroup 0 2019-07-23 14:30 /user/hive/warehouse/order_partition/event_month=2019-08 [hadoop@hadoop001 ~]$
2.把数据放到该分区目录下面
[hadoop@hadoop001 ~]$ hadoop fs -put /home/h 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









