







Flink学习
官网: https://flink.apache.org/
1. Flink简介
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
1.2 为什么选择Flink
流数据 源源不断的数据
目标: 低延迟 高吞吐 准确性 容错性
1.3 Flink特点
事件驱动
有界流 使用DataSet
无界流 使用 DataStreamAPI
分层API
支持事件时间和处理时间
精确一次的状态一致性保证
低延迟 每秒百万个事件 毫秒级延迟
高可用
与众多常用存储系统的链接
1.4 Flink VS Spark Streaming
流处理 vs 微批处理
- 数据模型
- 运行时架构
2.Flink 部署
2.1 Standalone单机
可以使用webui界面部署
也可以使用shell命令
#启动命令
/bin/start-cluster.sh
#停止
/bin/stop-cluster.sh
#提交任务
/bin/flink run -c [指定启动类] -p [并行度] [要提交的jar包地址] [指定jvm参数]
#查看当前所有作业
/bin/flink list
#取消作业
/bin/flink cancel [jobId]
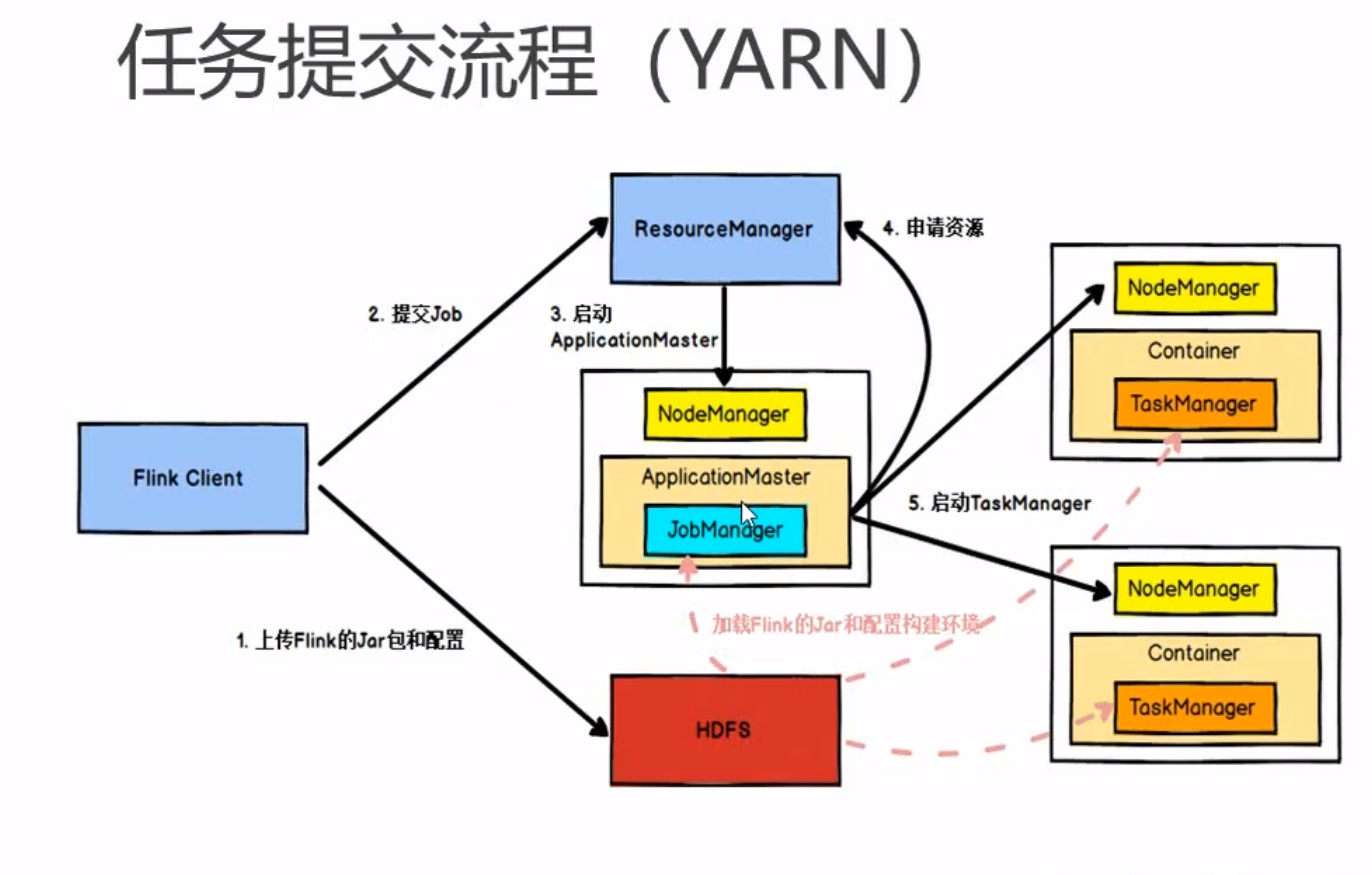
2.2. Yarn
需要hadoop集群
没有安装条件 略
2.3 k8s
略
3. Flink 运行架构
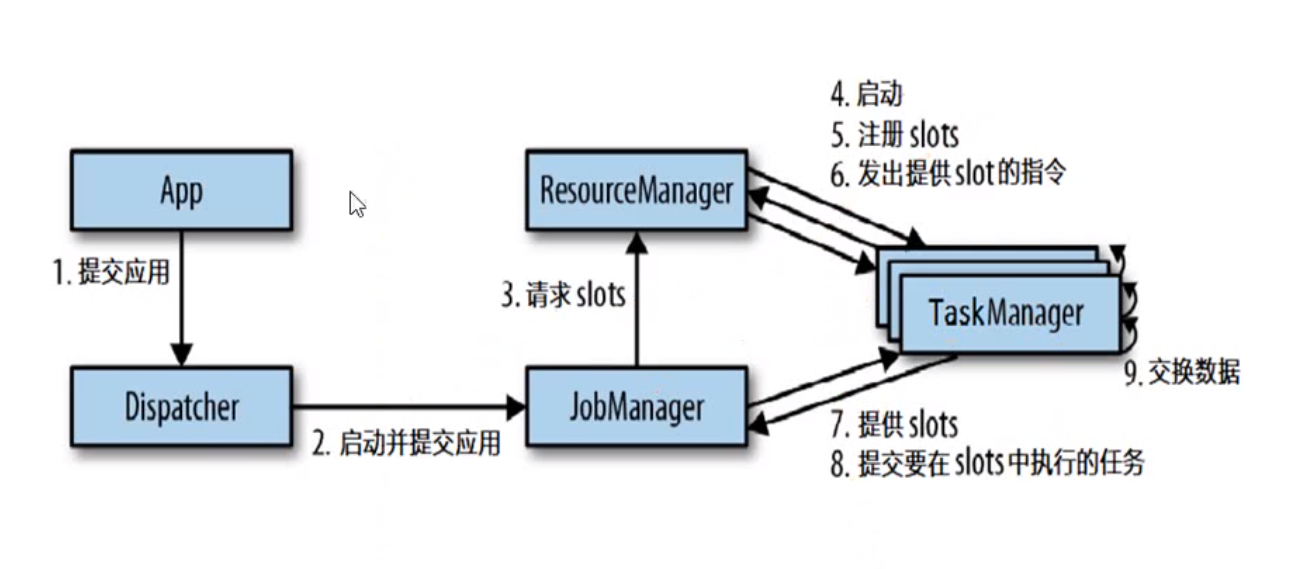
3.1 运行时组件
3.1.1 作业管理器JobManager

3.1.2 任务管理器TaskManager

3.1.3 资源管理器ResourceManager

3.1.4 分发器Dispatcher

3.2 任务提交流程
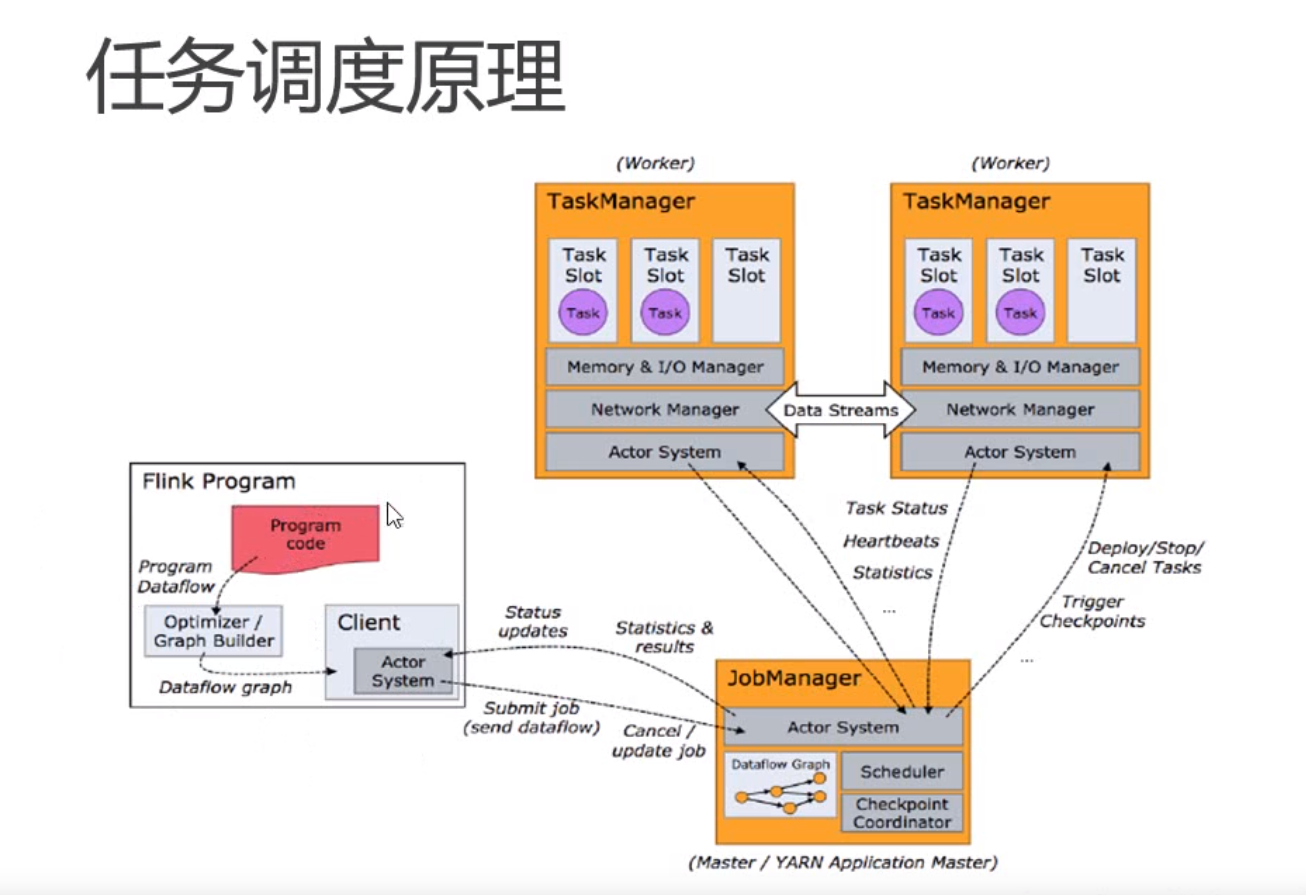
3.3. 任务调度原理
3.4 Slot
并行度: 一个特定算子的子任务的个数称为其并行度
一般情况下,一个stream的并行度,可以认为就是其所有算子中最大的并行度
Slots 是指Flink计算中执行一个线程所需要资源(CPU,内存)的最小单元
所以Slot的数量一般设置为TaskManager(JVM)的核心数
Slot 有分组的概念
如果是不同的组,必须使用不同的Slot
3.5 程序与数据流DataFlow
Flinke程序分为三大块: Source transform sink
数据传输的形式:
- One-to-one 必须是同共享组,并行度也相同的情况下才会One-to-one
- Redistributing 重新分区操作, 当并行度不一样时会进行重新分区轮询操作
4. 流处理API
流处理过程
Environment => source => transform => sink
4.1 Environment
执行环境
//流处理执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 批处理执行环境
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//创建本地执行环境
ExecutionEnvironment.createLocalEnvironment([并行度]);
//创建远程执行环境
ExecutionEnvironment.createRemoteEnvironment(host,port,jar包地址 );
4.2 Source
Flink可以从不同数据源读取数据
4.2.1 从集合和元素中读取数据
API executionEnvironment.fromCollection(list);
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度1
executionEnvironment.setParallelism(1);
// 创造集合数据
List<SensorReading> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
list.add(new SensorReading("Sensor" + i, LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli(), ThreadLocalRandom.current().nextDouble(35, 40)));
}
// 从集合中收集数据
DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.fromCollection(list);
// 打印集合数据
sensorReadingDataStreamSource.print("sensor");
// 从元素中收集数据
DataStreamSource<Integer> integerDataStreamSource = executionEnvironment.fromElements(1, 2, 3, 4, 56, 7);
// 打印从元素中收集到数据
integerDataStreamSource.print("element");
// 执行Flink程序
executionEnvironment.execute();
}
4.2.2 从文件中读取数据
API executionEnvironment.readTextFile(inputPath);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
String inputPath = "E:\\张尧\\idea项目\\FlinkTutorial\\src\\main\\resources\\word.txt";
DataStreamSource<String> dataStreamSource = executionEnvironment.readTextFile(inputPath);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = dataStreamSource.flatMap(new WorkCount.MyFlagMapFunction()).keyBy(0).sum(1);
sum.print();
executionEnvironment.execute();
}
4.2.3 从Kafka中读取数据
4.2.3.1 kafka配置
下载kafka 1.0.0版本以上
需要配置kafka的监听地址(本机除外)

修改config/server.properties
advertised.listeners=PLAINTEXT://192.168.164.205:9092
#启动kafka bin目录下
#启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
#启动kafka
./kafka-server-start.sh config/server.properties
package com.zy.flink.source;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
/**
* @author: zhangyao
* @create:2020-12-21 10:04
* @Description: 测试kafka数据源
**/
public class KafkaSourceTest {
public static void main(String[] args) throws Exception {
// 创建kafka连接配置信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.164.205:9092");
// properties.setProperty("group.id", "")
// 创建流处理执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
// 从kafka从获取数据
DataStreamSource<String> dataStreamSource = executionEnvironment.addSource(new FlinkKafkaConsumer<String>("sourcetest",
new SimpleStringSchema(), properties));
dataStreamSource.print();
executionEnvironment.execute();
}
}
4.2.4 自定义数据源
package com.zy.Flink.source;
import com.sun.org.apache.xpath.internal.operations.Bool;
import com.zy.Flink.entity.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.HashMap;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;
/**
* @author: zhangyao
* @create:2020-12-19 17:21
* @Description: 自定义数据源测试
**/
public class UDFSourceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.addSource(new MySensorSource());
sensorReadingDataStreamSource.print();
executionEnvironment.execute();
}
public static class MySensorSource implements SourceFunction<SensorReading>{
//定义属性控制数据的生成
private Boolean running = true;
@Override
public void run(SourceContext<SensorReading> sourceContext) throws Exception {
//定义传感器集合
HashMap<String, Double> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.put("sensor"+i, 60 + ThreadLocalRandom.current().nextGaussian() * 20);
}
while (running){
for (String s : map.keySet()) {
sourceContext.collect(new SensorReading(s, LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli(),map.get(s)+ThreadLocalRandom.current().nextGaussian()));
}
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
}
4.3 Transform
转换算子
4.3.1 基本转换算子
map flatMap filter 这三个是基本转换算子
package com.zy.Flink.transform;
import com.zy.Flink.entity.SensorReading;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ThreadLocalRandom;
/**
* @author: zhangyao
* @create:2020-12-19 17:55
* @Description:
**/
public class TransormTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
// 创造集合数据
List<SensorReading> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
list.add(new SensorReading("Sensor" + i, LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli(), ThreadLocalRandom.current().nextDouble(35, 40)));
}
// 使用集合收集数据
DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.fromCollection(list);
// map转换 返回sensorReading的sensorId
SingleOutputStreamOperator<Object> map = sensorReadingDataStreamSource.map(new MapFunction<SensorReading, Object>() {
@Override
public Object map(SensorReading sensorReading) throws Exception {
return sensorReading.getId();
}
});
// flatMap转换 将各个属性拆分输出
SingleOutputStreamOperator<Object> flatMap = sensorReadingDataStreamSource.flatMap(new FlatMapFunction<SensorReading, Object>() {
@Override
public void flatMap(SensorReading sensorReading, Collector<Object> collector) throws Exception {
String[] split = sensorReading.toString().split(", ");
for (String s : split) {
collector.collect(s);
}
}
});
// filter 过滤转换
SingleOutputStreamOperator<SensorReading> filter = sensorReadingDataStreamSource.filter(new FilterFunction<SensorReading>() {
@Override
public boolean filter(SensorReading sensorReading) throws Exception {
return sensorReading.getId().equals("Sensor2");
}
});
// 输出map转换后的数据
map.print("map");
// 输出flatmao转换后的数据
flatMap.print("flatMap");
// 输出filter转换后的数据
filter.print("filter");
executionEnvironment.execute();
}
}
4.3.2 聚合算子
keyBy 滚动聚合算子(Rolling Aggregation min() max() sum() minBy() maxBy()) Reduce是聚合类的算子
package com.zy.Flink.transform;
import com.zy.Flink.TestUtil;
import com.zy.Flink.entity.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author: zhangyao
* @create:2020-12-20 09:27
* @Description: 滚动聚合算子转换
**/
public class TransormTest3 {
public static void main(String[] args) throws Exception {
// 创建流执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
executionEnvironment.setParallelism(1);
// 从集合收集数据
DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.fromCollection(TestUtil.createTestCollection());
// 根据id keyBy 取最大温度
SingleOutputStreamOperator<SensorReading> max = sensorReadingDataStreamSource.keyBy("id").maxBy("tmpperature");
// 输出
max.print();
// 执行
executionEnvironment.execute();
}
}
聚合算子 min() 与 minBy() 的区别: min 只有聚合的字段是最小的,其他字段还是第一次收集 到的数据
minBy()是最小的聚合字段对应的数据
4.3.3 Reduce
package com.zy.Flink.transform;
import com.zy.Flink.TestUtil;
import com.zy.Flink.entity.SensorReading;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author: zhangyao
* @create:2020-12-20 11:37
* @Description: reduce操作
**/
public class TransormTest4_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.fromCollection(TestUtil.createTestCollection());
KeyedStream<SensorReading, Object> keyedStream = sensorReadingDataStreamSource.keyBy(new KeySelector<SensorReading, Object>() {
@Override
public Object getKey(SensorReading value) throws Exception {
return value.getId();
}
});
SingleOutputStreamOperator<SensorReading> reduce = keyedStream.reduce((value1, value2) -> {
return new SensorReading(value1.getId(), System.currentTimeMillis(), Math.max(value1.getTmpperature(), value2.getTmpperature()));
});
reduce.print();
executionEnvironment.execute();
}
}
4.3.4 多流转换
split(1.12移除)
connect map 只能合并两条流
union 合并多条流
4.3.5 数据类型
Flink支持的数据类型
- 支持Java和scale的所有基本数据类型(包括包装类)
- Java 和 Scale 元组
- Scale样例类 ?
- Java 简单对象 (空参构造)
- Java 集合 枚举
4.3.6 UDF 函数
- 函数类
- 匿名函数
- 富函数
4.3.7 数据重分区
4.3.7.1 shuffle
打乱分区顺序,重新分区
4.3.7.2 keyby
根据hash计算出分区,相同的key一定在同一分区(同一分区的key不一定相同)
4.3.7.3 global
当前的所有流发送到下一分区(同一个分区)
package com.zy.flink.transform;
import com.zy.flink.entity.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author: zhangyao
* @create:2020-12-21 09:11
* @Description: 分区操作
**/
public class TransfromTest6_partition {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 要测试充分区操作,就不能设置并行度为1
executionEnvironment.setParallelism(4);
// 读取文件数据
SingleOutputStreamOperator<SensorReading> dataStreamSource = executionEnvironment.readTextFile("E" +
":\\张尧\\idea项目\\tl\\Flink_learn\\learn_feature\\src\\main\\resources" +
"\\sensorReading.txt").map(line -> {
String[] split = line.split(",");
return new SensorReading(split[0],new Long(split[1]),new Double(split[2]));
});
//输出源流
dataStreamSource.print("input");
// shuffle
dataStreamSource.shuffle().print("shuffle");
// keyBy
dataStreamSource.keyBy("id").print("keyBy");
// global
dataStreamSource.global().print("global");
// 执行作业
executionEnvironment.execute();
}
}
4.4 Sink
4.4.1 写入kafka
package com.zy.flink.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import java.util.Properties;
/**
* @author: zhangyao
* @create:2020-12-21 10:30
* @Description: 从kafka中读取数据,写入到kafka
**/
public class KafkaSink {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
// 从kafka获取消息
// 创建kafka配置信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.164.205:9092");
// 消费消息
DataStreamSource<String> sourcetest =
executionEnvironment.addSource(new FlinkKafkaConsumer<String>("sourcetest",
new SimpleStringSchema(), properties));
// 写入kafka
DataStreamSink sinktest = sourcetest.addSink(new FlinkKafkaProducer("192.168.164.205:9092", "sinktest", new SimpleStringSchema()));
// 执行作业
executionEnvironment.execute();
}
}
需要依赖kafka connector连接器
<!-- kafka依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${flinks-clients.suffix.version}</artifactId>
</dependency>
4.4.2 写入redis
<flinks-clients.suffix.version>2.11</flinks-clients.suffix.version>
<flinks-redis.version>1.0</flinks-redis.version>
<!-- flink写入redis依赖-->
<!-- https://mvnrepository.com/artifact/org.apache.bahir/flink-connector-redis -->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_${flinks-clients.suffix.version}</artifactId>
<version>${flinks-redis.version}</version>
</dependency>
package com.zy.flink.sink;
import com.zy.flink.TestUtil;
import com.zy.flink.entity.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisConfigBase;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
/**
* @author: zhangyao
* @create:2020-12-21 10:54
* @Description: 从文件中读取到数据输出到redis
**/
public class RedisSinkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.fromCollection(TestUtil.createTestCollection());
// 创建jedis配置环境
FlinkJedisPoolConfig flinkJedisPoolConfig =
new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build();
DataStreamSink test = sensorReadingDataStreamSource.addSink(new RedisSink(flinkJedisPoolConfig,
new RedisMapper<SensorReading>() {
// 创建执行方法的描述
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "test");
}
@Override
public String getKeyFromData(SensorReading sensorReading) {
return sensorReading.getId();
}
@Override
public String getValueFromData(SensorReading sensorReading) {
return sensorReading.getTmpperature().toString();
}
}));
executionEnvironment.execute();
}
}
4.4.3 写入es
4.4.4 写入jdbc
就是写入数据库
5. window
5.1 window 概念
窗口
窗口就是无界流切割为有限流的一种方式
5.2 window 类型
- 时间窗口
- 滚动时间窗口 Tumbling Windows
- 时间对齐,窗口长度固定,一个数据只属于一个窗口
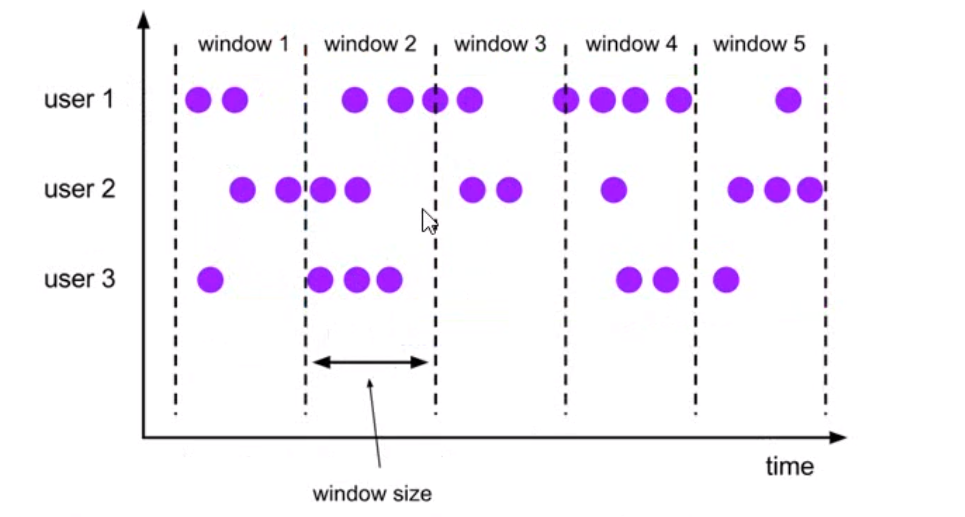
- 滑动时间窗口
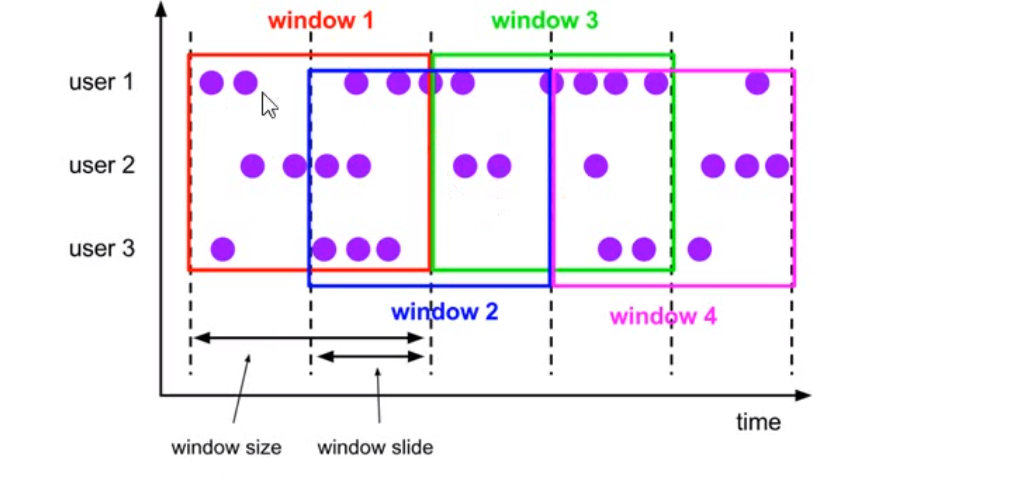
- 滑动窗口有步长,一个数据可以存在多个窗口
- 会话窗口
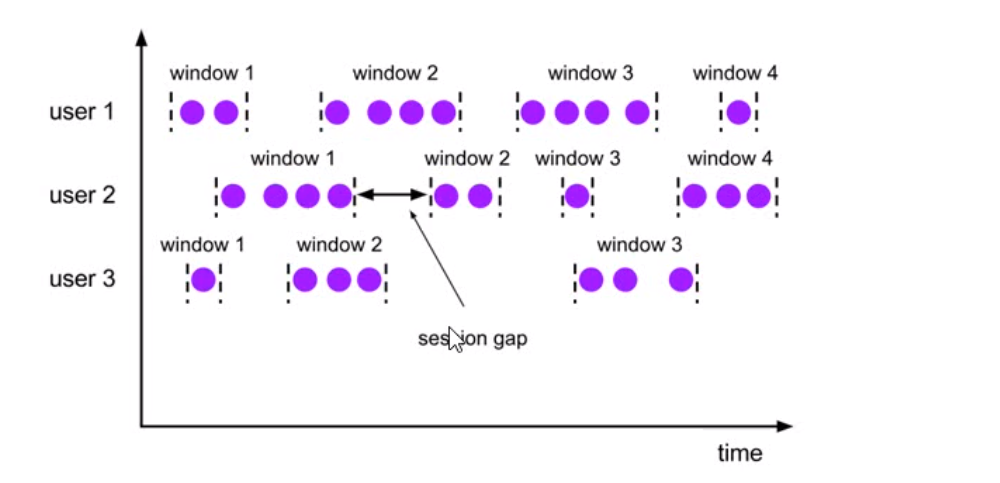
- 时间无对齐
- 滚动时间窗口 Tumbling Windows
- 计数窗口
- 滚动计数窗口
- 滑动计数窗口
5.3. window API
5.3.1 窗口分配器
window()
timeWindow()
countWindow()
都是开窗操作
5.3.2 window Function
当开窗之后,需要使用window Function进行聚合操作
- 增量聚合函数 bucket中只存储一个sum的结果,每来一条数据就计算一次
- ReduceFunction
- AggregateFunction
- …
- 全窗口函数 收集所有的数据放入bucket 最终计算
- ProcessWindowFunction
- WindowFunction
- …
package com.zy.flink.window;
import com.zy.flink.entity.SensorReading;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* @author: zhangyao
* @create:2020-12-21 14:38
* @Description: 时间窗口 滚动
**/
public class WindowApiTest1_TimeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// DataStreamSource<SensorReading> sensorReadingDataStreamSource = executionEnvironment.fromCollection(TestUtil.createTestCollection());
SingleOutputStreamOperator<SensorReading> dataStreamSource = executionEnvironment.socketTextStream(
"192.168.164.205", 8888).map(line -> {
String[] splits = line.split(",");
return new SensorReading(splits[0], new Long(splits[1]), new Double(splits[2]));
});
SingleOutputStreamOperator<Integer> resultStream = dataStreamSource.keyBy("id")
.timeWindow(Time.seconds(10))
.aggregate(new AggregateFunction<SensorReading, Integer, Integer>() {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(SensorReading s, Integer integer) {
return integer + 1;
}
@Override
public Integer getResult(Integer integer) {
return integer;
}
@Override
public Integer merge(Integer integer, Integer acc1) {
return integer + acc1;
}
});
resultStream.print();
executionEnvironment.execute();
}
}
5.3.3 可选API
- trigger 触发器
- 定义window的关闭时间,什么时候触发计算输出结果
- evictor 移除器
- 定义移除某些数据的逻辑
- allowLateness
- 允许迟到数据
- sideOutputLateDate
- 将迟到数据放入侧输出流
- getSideOutput
- 获取测输出流
6. 时间
6.1 时间语义
分为三个时间
- event Time 事件本身的时间,业务数据产生自身的时间
- Ingestion Time 数据进入Flink的时间
- Process Time flink操作算子进行计算的计算时间
6.2 EventTime
设置eventTime
executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
6.3 水位线 watemark
水位线用来处理乱序数据的延迟到达,当数据由于网络或分布式导致到达时间不是顺序时,要使用水位线平衡延迟



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











