






概念:
该方法网上很多很简洁但是很难懂的公式,本文章将会由简单例子入手,一步步去理解那些公式,但是不做代码实现,毕竟只要搞懂了这个算法的思想,代码的实现其实千变万化,甚至用CV库的话根本不用写代码。
为啥出现这个二值化算法,OTSU的致命缺陷在哪里?
在大津算法OTSU中,由于采取的都是全局均值求出最佳全局阈值,但是在图片光照不均匀的场景,很容易把稍微模糊的边缘目标图像当作背景,为了避免这种场景,我们就可以考虑更为细腻的局部自适应阈值,它是根据图像不同区域亮度,不断计算更新局部阈值,同时不断“刷新”局部图像,直到把整张目标图像都“刷”一遍,所以对于图像不同区域,自适应不同的阈值,因此称为局部自适应阈值法。
如下图所示:

中间我用白线区分的部分,假设全局阈值法做二值化,光亮部分较多的话,整体灰度值亮度偏高,导致右上角阴暗处文字被填充为黑色,只保留了左下角的部分文字,这显然是人工智障,那我们人又是如何知道暗的部分也需要识别的呢?又该怎么教会机器呢?
案例:
仔细想,其实我们是能适应从很亮到很暗的书页字体颜色的一个变化,所以能准确抓住哪部分该识别,哪部分不用识别,假如我们让机器也有这个能力,那它也会慢慢学到“暗”的地方的文字也要识别
再细想一下,二值化的最重要一点,就是阈值,那么我们有什么办法,让阈值不是一个全局的固定的值,而是根据图像各个部位不同,稍微做一些调整呢?
移动平均法,这个初中还是高中学的公式就派上用场了,首先我们把图像切分成N个小部分:
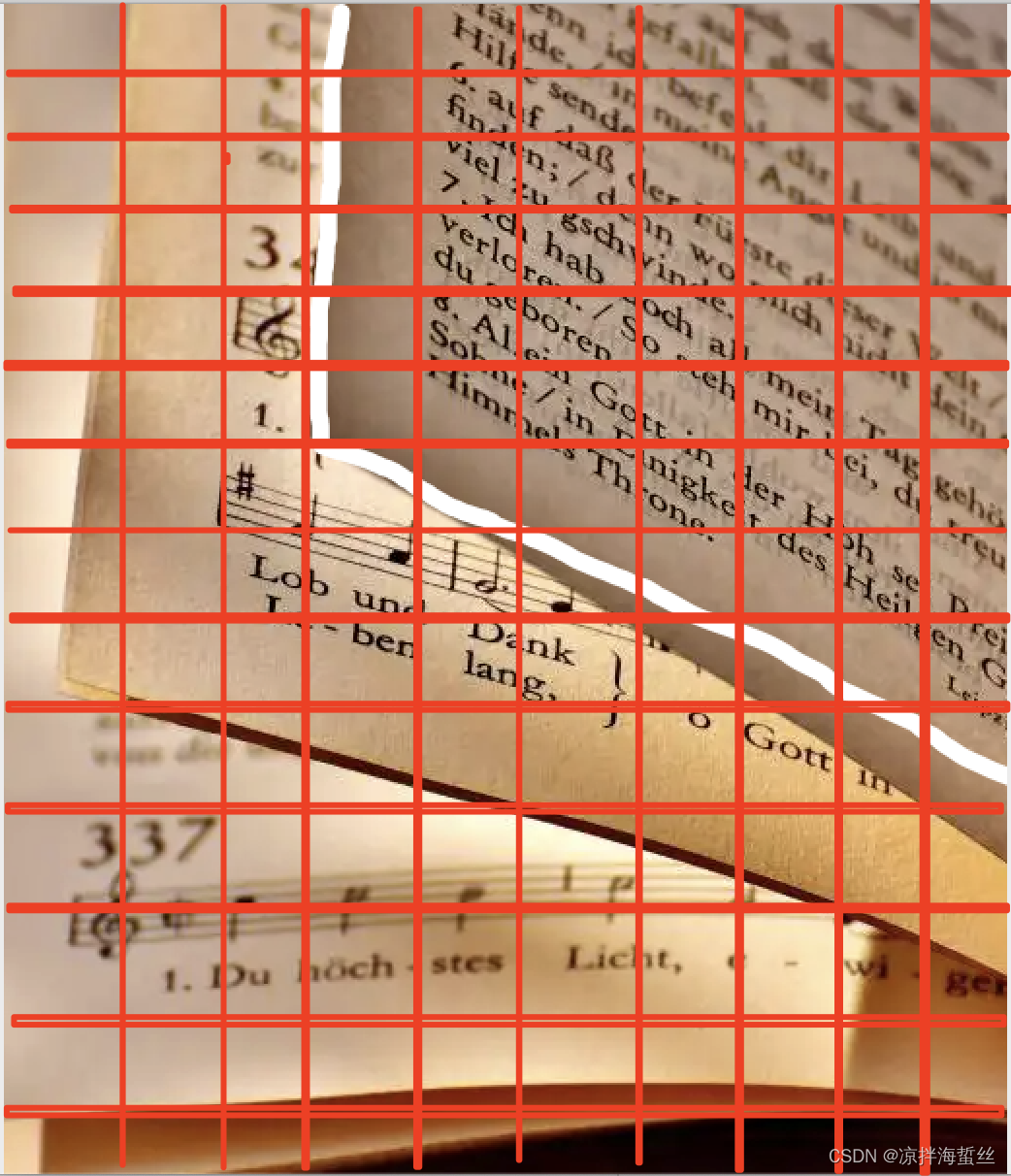
基于初次切分的每个小格,再做一次简单分割,得到下图左上角所示:

这样我们假设可以获得左上角的四个区域,每个区域内的M个像素点的平均灰度值为u1,u2,u3,u4, 那么这四个区域围起来代表的红色区域内的平均灰度值就是 (大写)U1 = (u1+u2+u3+u4) / 4 ,得到一个小格的比较准确的平均灰度值阈值,按照这个方法我们再往后推几个格子
⚠️注意,很多网上例子是说用像素点,但是实际项目中,一张图像可能就百M上G,几G甚至更多,用像素点效率很低,所以这里举例子采用细分区域的平均值,其实核心思想一样,
这里例子用的22网格,现实也可以根据实际情况选择55,66,99……

这个时候,按照移动平均法的公式不断更新一个全局的浮动阈值:UT
UT = (U1+U2+U3+U4+U5) / 5
这个阈值就能很好“识别”阴暗处的文字,为什么呢?因为U1,U2,U3的平均阈值亮度很高,但是“刷”过U4区域的时候,已经“被平均”了,也就是区分的阈值亮度被“拉低”了,这样在U5甚至接下来的U6,U7区域,它也能很快的“适应”光线的变化,准确“读”出二值化识别的目标文字
疑问:万一U4这个过渡区域无法瞬间拉低阈值,怎么办?
好办
方法一:把图像再分割细一点,让刷过去的速度更慢,让阈值有充分的过渡区域可以降低

方法二:把前一个区域的阈值进行百分比取值,也就是只取上一次的百分之几黑度,相当于“我会借鉴/参考前任的经验但是我有我区域的特殊情况,我不会100%按照别人的阈值经验来搞”,这个百分比取值可以通过多次尝试来找到分割效果最好的那一个
例如:
设i区域内的像素点灰度值为[p1,p2,p3…pi],区域的平均阈值为:Ui
t 为pi区域之前的s个像素点的灰度平均阈值的百分比
那么当前区域我的阈值就设为:
Ui+ = Ui / ( 100 - t /100)
有了上面的基础,我们怎么用这一个不断变化的阈值去二值化我们的目标图像呢?
网上有很多例子都是黑底/深色底,白图/浅色图;这里案例用的是白底黑字,目标图像是黑字,那么做二值化时候判断:
设i区域内的像素点灰度值为[p1,p2,p3…pi],区域的平均阈值为:Ui,t 为pi区域之前的s个像素点的灰度平均阈值的百分比
Ui+ = Ui / ( 100 - t /100)
px < Ui+ ?
阈值/100会得到一个更小的灰度值分割值,这个100是可以调整的,不一定写死,如果该像素点比更小的分割都小,也就是还要接近黑,那么直接输出黑
是的话,输出0 (代表黑)
不是的话,输出255(代表白)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









