







整体介绍:
基于RAG(检索增强生成)技术,可以使用Java开发智能客服机器人。核心思路是首先将问答QA以Word形式导入系统,并通过数据准备流程进行清洗和向量化处理。接着,利用向量化后的数据构建索引,便于快速检索。当用户提出问题时,系统先识别查询意图并改写查询,再从已建立的索引中检索相关信息。最后,根据检索结果生成回答返回给用户。这一过程充分利用了RAG能力,结合大模型如阿里云通义千问,使得Java智能问答客服机器人能够高效、准确地提供服务。此方案不仅提高了客服效率,还增强了用户体验,是现代智能问答客服系统的重要组成部分。
rag介绍:
检索增强生成 (RAG) 是一种结合了检索模型和生成模型的技术,用于提高文本生成的准确性和相关性。通过利用私有知识库的信息来辅助大型语言模型(LLM)生成回复,RAG解决了模型在使用过程中可能出现的幻觉问题,并能够根据企业的自有数据提供更加精准和具体的答案。这种方法确保了生成的内容不仅基于广泛的知识,还融合了特定领域的私有信息,从而增强了回答的相关性和实用性。
RAG的主要流程
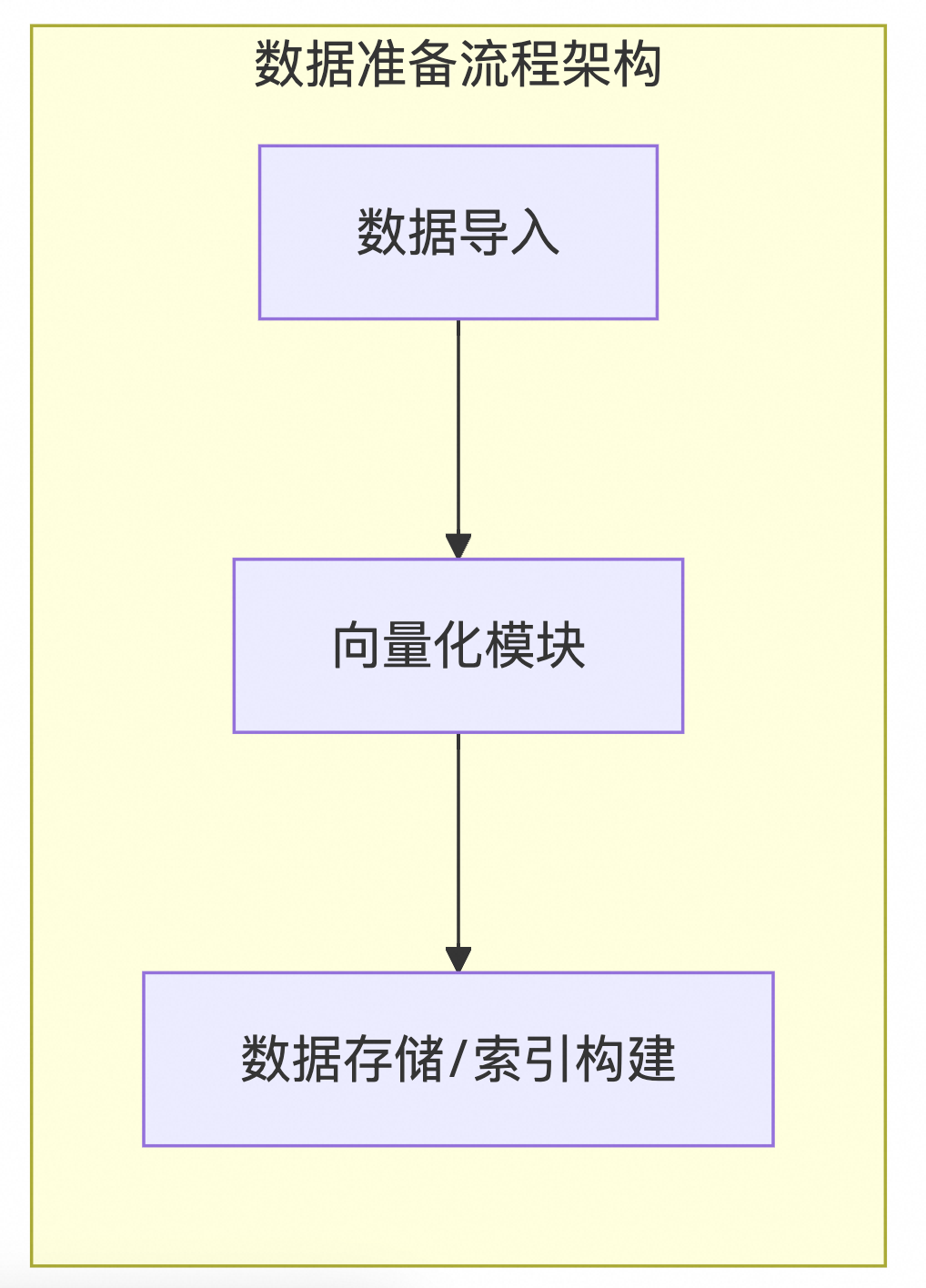
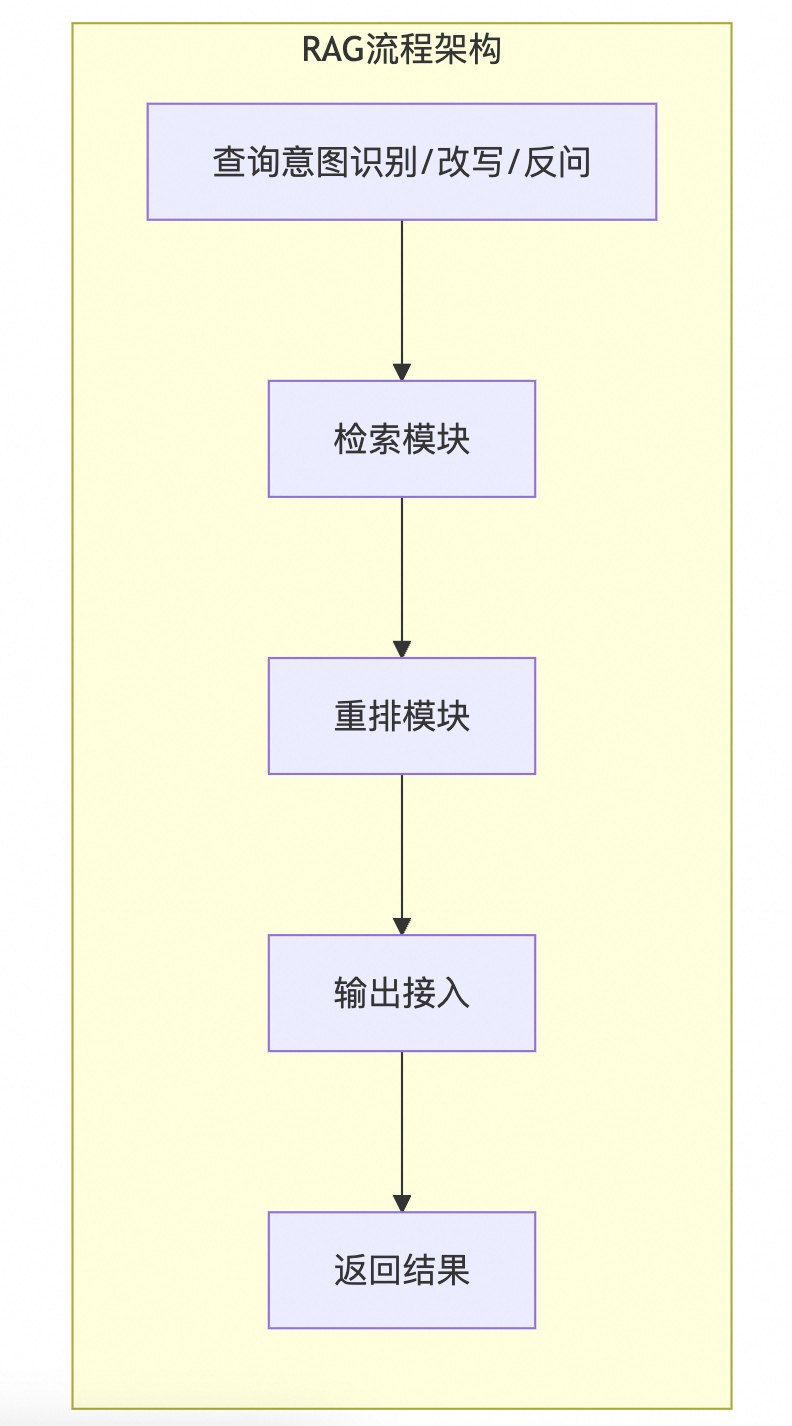
在RAG(Retrieval-Augmented Generation)中,主要流程分为索引构建流程和使用流程两个部分。首先,在索引构建流程里,数据导入模块通过从各种数据源收集原始数据并对其进行预处理,包括数据清洗与转换,以确保数据的质量和一致性;接着,向量化模块利用特征提取技术将处理后的数据转换为向量表示,通常采用预训练的语言模型实现这一过程;最后,数据存储/索引构建模块负责保存这些向量化数据,并为其创建索引结构,便于后续高效检索。对于使用流程而言,查询意图识别/改写/反问模块会分析用户提出的自然语言问题,识别其背后的真实需求,并可能对原问题进行适当的调整来提高匹配度;随后,检索模块基于已有的索引快速定位到与当前查询最相关的文档或信息片段;重排模块则根据相关性等标准对这些初步结果进行排序优化,确保高质量的内容优先展示;输出接入阶段整合了所有经过筛选和排序的信息,生成易于理解的答案或解决方案;最终,返回结果给用户的同时也会收集他们对所提供答案的反馈,用以不断迭代改进系统性能。
通义千问介绍
通义千问是由阿里集团推出的开源大模型服务,它支持全尺寸、多模态的大规模模型。在中文开源模型领域,通义千问表现出色,在国内的思南大模型竞技场排名中名列前茅。
核心能力
通义千问的核心优势包括:
- 能力排名靠前:QWen(通义千问的一个版本)在多个客观评测指标上表现优异,例如MMLU、TheoremQA、GPQA等测试中超越了Llama 3 70B。此外,在国产模型中,通义千问紧随open ai 的gpt、claude和马斯克的grek之后。
- 安全性和合规性:通过API调用时,通义千问提供了安全保护措施,有效防止恶意攻击。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









