




从零开始学爬虫--Python[日更] # whisky和你一起实战学爬虫
Welcome! - -[whisky带你学IT]- -公众号
出入T圈小菜鸡,因工作需要开始接触爬虫,维护项目,接下来的几天里我们一起从零升级,闯关打败爬虫,谨以此帖,记录经验。

1. 爬虫入门:
1.1 爬虫的分类: 累积式爬虫 聚焦爬虫(针对特定网站) 深网爬虫
1.2 爬虫的流程:
1.向url 发送请求,获取响应
2.对响应进行提取
3.提取url,继续发送请求获取响应
4.提取数据,保存
1.3 http和https
- 在发送请求,获取响应的过程中 就是发送http或https的请求,获取http或https的响应
- http :80 端口 https:443 端口
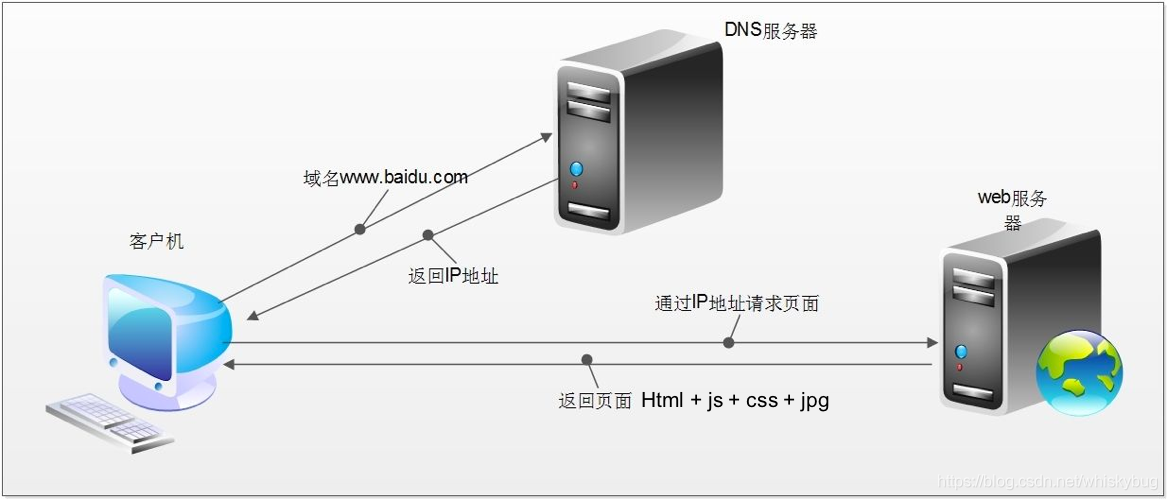
1.3.1 http 请求过程
-
浏览器输入 url 发送请求,获取响应
-
返回响应体中,带有css,js,图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序发送其他请求,获取相应的响应。
-
浏览器每获取一个响应并在浏览器中展示,直到获取全部响应,并在展示的结果中添加内容或修改————这个过程叫做浏览器的渲染
-
爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等)浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样,所以在爬虫中,需要以url地址对应的响应为准来进行数据的提取
-
http 请求的形式
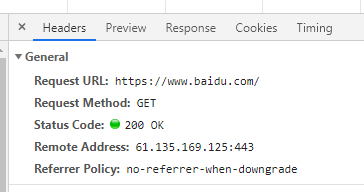
-
Host (主机和端口号)
Connection (链接类型)
Upgrade-Insecure-Requests (升级为HTTPS请求)
User-Agent (浏览器名称)
Accept (传输文件类型)
Referer (页面跳转处)
Accept-Encoding(文件编解码格式)
Cookie (Cookie)
x-requested-with :XMLHttpRequest (表示该请求是Ajax异步请求) -
http 重要的响应头
-1. set-cookie(对方服务器设置cookie到用户浏览器的缓存)
-2. last-modified(对方静态页面最后更新时间) -
响应状态码
常见的状态码:200:成功
302:临时转移至新的url
307:临时转移至新的url
404:找不到该页面
500:服务器内部错误
503:服务不可用
所有的状态码都不可信,一切以是否获取到数据为准
1.4 字符串
- UTF-8是Unicode的实现方式之一
- py3 中的字符串:str bytes
str 使用encode方法转化为 bytes
s = 'abc'
print(type(s))
#str编码变为bytes类型
b = s.encode
print(type(b))
bytes 通过decode转化为 str
b = b'abc'
print(type(b))
#bytes类型解码成为str类型
s = b.decode()
print(type(s))

2.2 请求的发送方法
2.2.1 request模块
-requests 模块底层实现就是urllib
作用: 发送网络请求,返回响应数据
中文文档 : http://docs.python-requests.org/zh_CN/latest/index.html
- requests 基础get操作:
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
- response的常用属性:
response.text 响应体 str类型
respones.content 响应体 bytes类型
response.status_code 响应状态码
response.request.headers 响应对应的请求头
response.headers 响应头
response.request.cookies 响应对应请求的cookie
response.cookies 响应的cookie(经过了set-cookie动作) - response.text
类型:str
解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding=”gbk”
- response.content
类型:bytes
解码类型: 没有指定
如何修改编码方式:response.content.deocde(“utf8”)
2.1.1 requests 两种发送参数的请求
- 方式一:利用params参数发送带参数的请求
- 方式二:直接发送带参数的url的请求
2.2.2 requests发送post 请求
response = requests.post("http://www.baidu.com/",data = data,headers=headers)
TODO
- 花了¥130 大洋报了期货从业考试,在不学习,打水漂了。倒计时18days。发挥大中国从小培养的应试教育功底。开搂!
2 使用代理
2.1 为什么要使用代理
让服务器以为不是同一个客户端在请求
防止我们的真实地址被泄露,防止被追究
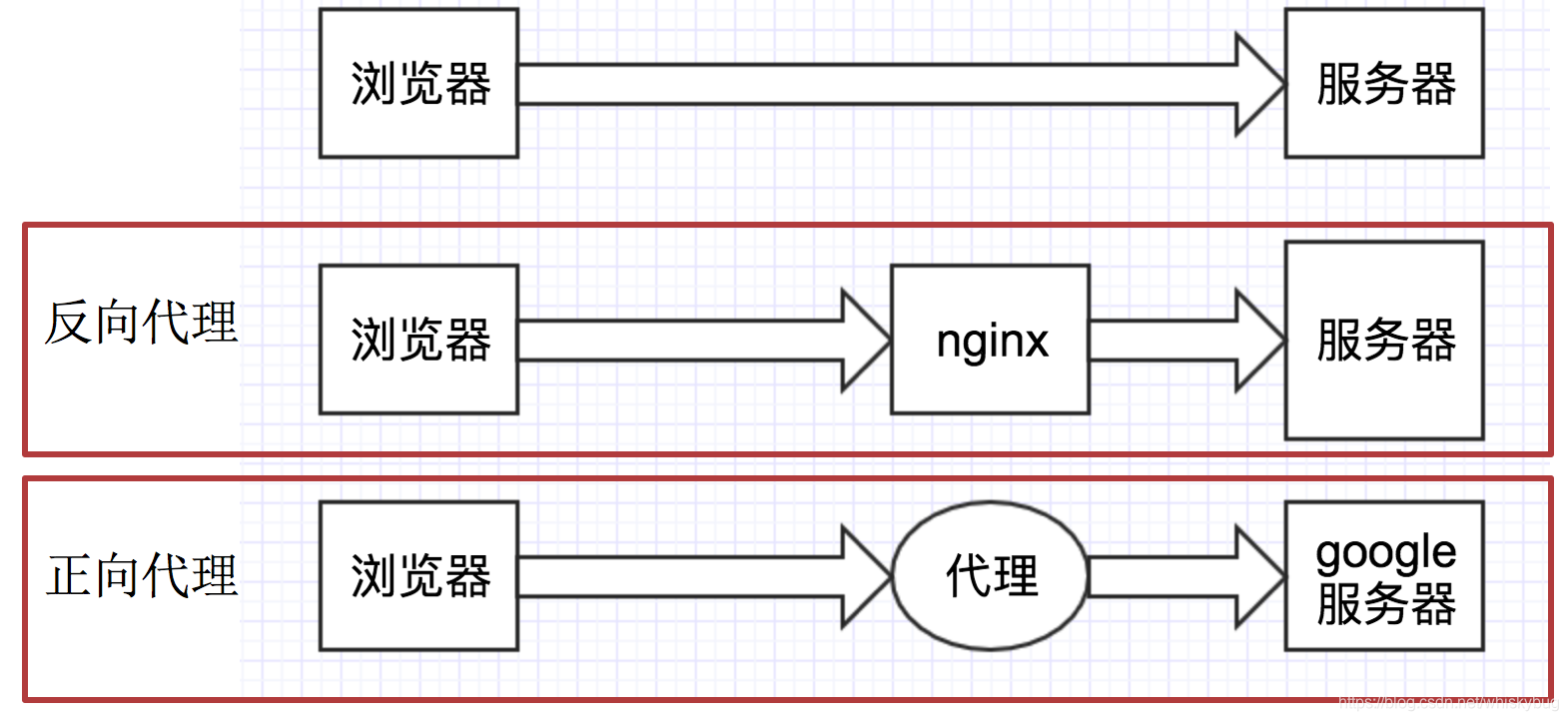
正向代理:对于浏览器知道服务器的真实地址,例如VPN
反向代理:浏览器不知道服务器的真实地址,例如nginx
- 2.4 代理的使用
用法:
requests.get("http://www.baidu.com", proxies = proxies)
#proxies的形式:字典
#例如:
proxies = {
"http": "http://12.34.56.79:9527",
"https": "https://12.34.56.79:9527",
}
-
2.5 代理IP的分类
根据代理ip的匿名程度,代理IP可以分为下面四类:透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。
匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
在使用的使用,毫无疑问使用高匿代理效果最好
从请求使用的协议可以分为:
http代理
https代理
socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择 -
2.6 代理IP使用的注意点
-----反反爬使用代理ip是非常必要的一种反反爬的方式
但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:
一段时间内,检测IP访问的频率,访问太多频繁会屏蔽
检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽
服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
-----代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
2.2.3 requess模块处理cookie相关的请求
- requests处理cookie的三种方法
1.cookie字符串放在headers中
2.把cookie字典反传给请求方法的cookies参数接收
3.使用requests提供的session模块 - cookie 添加在headers中
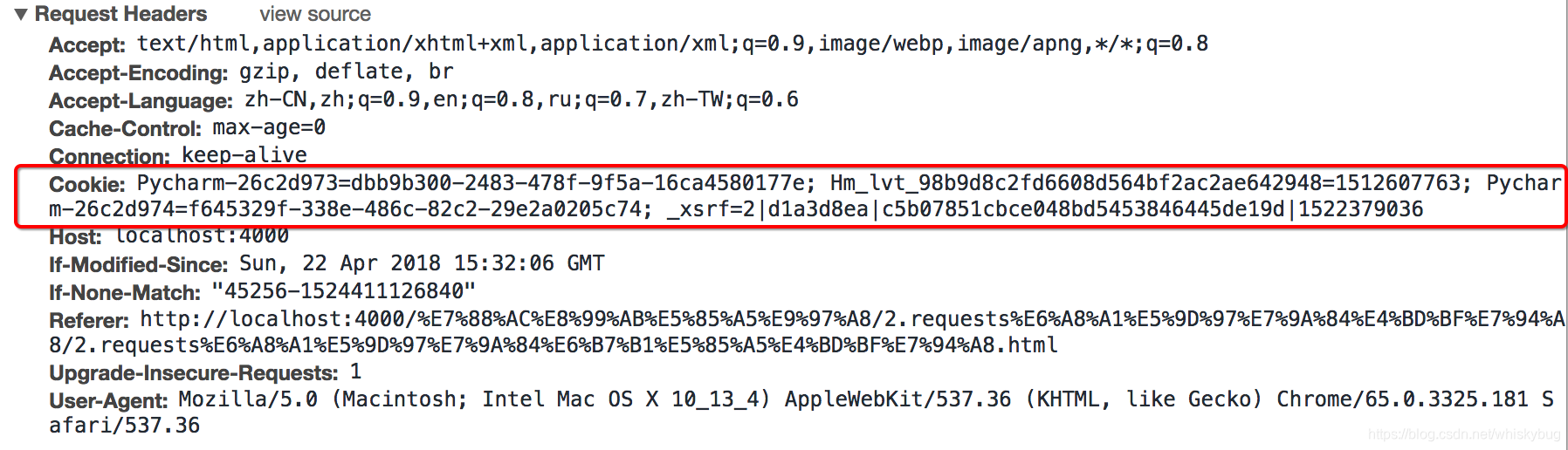
- requests处理cookie的三种方法
headers中的cookie:
使用分号(;)隔开
分号两边的类似a=b形式的表示一条cookie
a=b中,a表示键(name),b表示值(value)
在headers中仅仅使用了cookie的name和value

由于headers中对cookie仅仅使用它的name和value,所以在代码中我们仅仅需要cookie的name和value即可
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"}
requests.get(url,headers=headers)
注意:通过一个程序专门来获取cookie供其他程序使用
//cookies的形式:字典
cookies = {"cookie的name":"cookie的value"}
//使用方法:
requests.get(url,headers=headers,cookies=cookie_dict}

















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









