




目录
一、概述
只涉及伙伴系统初始化,分配,释放,暂不涉及页面回收。
二、内存组织
NUMA结构中每个node对应有一块物理内存,使用pglist_data描述,每块物理内存中因为不同的功能划分为不同的部分,如ISA只能访问低16M地址,对应DMA区域;而有些设备DMA范围是4G,于是也有DMA32;而对于32位CPU来说,大内存情况下内核线性映射范围不够用,因此又有HIGHMEM的区域;在上一篇中内核线性映射的部分称为NORMAL。 因此我们知道,node根据不同的用途可以分成不同的类型,Linux内核使用zone来描述这些类型。对于内存管理来说,每个zone还是太大,因此在zone内又使用物理page来进一步描述:内核使用buddy allocator管理每个zone中的物理page,buddy allocation使用MAX_ORDER个freelist,这样有助于可以解决内部碎片。另一方面,为了解决外部碎片问题,每个freelist又划分为多种迁移类型。
2.1 数据抽象
[include/linux/mmzone.h]
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
unsigned long node_start_pfn;
unsigned long node_present_pages;
unsigned long node_spanned_pages;
int node_id;
unsigned long totalreserve_pages;
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
struct lruvec lruvec;
unsigned int inactive_ratio;
unsigned long flags;
ZONE_PADDING(_pad2_)
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;- node_zones node对应的zone
- node_zonelists
- nr_zone node管理zone的数量
- node_start_pfn node起始页帧
- node_present_pages node中所有的page数量
- node_spanned_pages node中所有的page数量,包括hole
struct zone {
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
long lowmem_reserve[MAX_NR_ZONES];
int node;
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
int initialized;
ZONE_PADDING(_pad1_)
struct free_area free_area[MAX_ORDER];
unsigned long flags;
spinlock_t lock;
ZONE_PADDING(_pad2_)
unsigned long percpu_drift_mark;
bool contiguous;
ZONE_PADDING(_pad3_)
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
- watermark 页换出时使用的水印
- lowmem_reserve 为每个zone指定了一定数量的页,用于无论如何也不能失败的内存分配
- pageset
- zone_start_pfn zone起始页帧
- managed_pages zone中受buddy allocator管理的page的数量,present_pages - reserved_pages
- spanned_pages zone中所有的page数量,包括hole,zone_end_pfn - zone_start_pfn
- present_pages zone中所有的page数量,spanned_pages - absent_pages(pages in holes)
- free_area 空闲列表
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};- zoneref 是分配内存时选择zone的顺序,两个维度:node, zone_type
2.2 伙伴系统的建立
2.2.1 node和zone的数据结构初始化
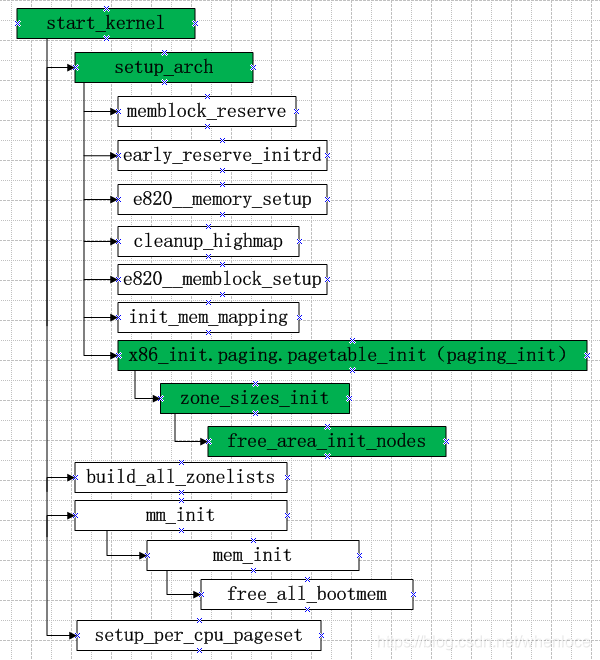
上面绿色部分的流程初始化pglist_data和zone:
[arch/x86/mm/init.c]
void __init zone_sizes_init(void)
{
unsigned long max_zone_pfns[MAX_NR_ZONES];
memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
#ifdef CONFIG_ZONE_DMA
max_zone_pfns[ZONE_DMA] = min(MAX_DMA_PFN, max_low_pfn);
#endif
#ifdef CONFIG_ZONE_DMA32
max_zone_pfns[ZONE_DMA32] = min(MAX_DMA32_PFN, max_low_pfn);
#endif
max_zone_pfns[ZONE_NORMAL] = max_low_pfn;
#ifdef CONFIG_HIGHMEM
max_zone_pfns[ZONE_HIGHMEM] = max_pfn;
#endif
free_area_init_nodes(max_zone_pfns);
}- 在x86_64下zone一般会划分为3个zone(DMA, DMA32, NORMAL), 对于上述max_low_pfn, max_pfn的值,这部分在setup_arch中进行的设置
max_pfn = e820__end_of_ram_pfn();
if (max_pfn > (1UL<<(32 - PAGE_SHIFT)))
max_low_pfn = e820__end_of_low_ram_pfn();
else
max_low_pfn = max_pfn;跟踪代码发现,这两个值在启动过程中有打印:
dmesg | grep last_pfn
[ 0.000000] e820: last_pfn = 0x240000 max_arch_pfn = 0x400000000
[ 0.000000] e820: last_pfn = 0xc0000 max_arch_pfn = 0x400000000
所以此时max_pfn=0x240000, max_low_pfn=0xc0000,参照上篇文章知道:
[ 0.000000] e820: BIOS-provided physical RAM map:
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009ebff] usable
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x00000000bfecffff] usable
[ 0.000000] BIOS-e820: [mem 0x00000000bff00000-0x00000000bfffffff] usable //max_low_pfn
[ 0.000000] BIOS-e820: [mem 0x0000000100000000-0x000000023fffffff] usable //max_pfn
考虑到在进行线性映射的时候(init_map_mapping)
#ifdef CONFIG_X86_64
if (max_pfn > max_low_pfn) {
/* can we preseve max_low_pfn ?*/
max_low_pfn = max_pfn;
}所以最终max_pfn=0x240000, max_low_pfn=0x240000
/* 16MB ISA DMA zone */
#define MAX_DMA_PFN ((16UL * 1024 * 1024) >> PAGE_SHIFT)
/* 4GB broken PCI/AGP hardware bus master zone */
#define MAX_DMA32_PFN ((4UL * 1024 * 1024 * 1024) >> PAGE_SHIFT)- max_zone_pfns[ZONE_DMA] = min(MAX_DMA_PFN, max_low_pfn) = 0x1000
- max_zone_pfns[ZONE_DMA32] = min(MAX_DMA32_PFN, max_low_pfn) = 0x100000
- max_zone_pfns[ZONE_NORMAL] = max_low_pfn = 0x240000
继续向下分析free_area_init_nodes
[mm/page_alloc.c]
void __init free_area_init_nodes(unsigned long *max_zone_pfn)
{
unsigned long start_pfn, end_pfn;
int i, nid;
/* Record where the zone boundaries are */
memset(arch_zone_lowest_possible_pfn, 0,
sizeof(arch_zone_lowest_possible_pfn));
memset(arch_zone_highest_possible_pfn, 0,
sizeof(arch_zone_highest_possible_pfn));
start_pfn = find_min_pfn_with_active_regions();
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
end_pfn = max(max_zone_pfn[i], start_pfn);
arch_zone_lowest_possible_pfn[i] = start_pfn;
arch_zone_highest_possible_pfn[i] = end_pfn;
start_pfn = end_pfn;
}
memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn));
find_zone_movable_pfns_for_nodes();
}- 参数max_zone_pfn 指定了每个zone_type的最大pfn
- 将每个zone_type的 start_pfn和end_pfn存储到arch_zone_lowest_possible_pfn / arch_zone_highest_possible_pfn中
接着打印各zone相关的信息:
/* Print out the zone ranges */
pr_info("Zone ranges:\n");
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
pr_info(" %-8s ", zone_names[i]);
if (arch_zone_lowest_possible_pfn[i] ==
arch_zone_highest_possible_pfn[i])
pr_cont("empty\n");
else
pr_cont("[mem %#018Lx-%#018Lx]\n",
(u64)arch_zone_lowest_possible_pfn[i]
<< PAGE_SHIFT,
((u64)arch_zone_highest_possible_pfn[i]
<< PAGE_SHIFT) - 1);
}
/* Print out the PFNs ZONE_MOVABLE begins at in each node */
pr_info("Movable zone start for each node\n");
for (i = 0; i < MAX_NUMNODES; i++) {
if (zone_movable_pfn[i])
pr_info(" Node %d: %#018Lx\n", i,
(u64)zone_movable_pfn[i] << PAGE_SHIFT);
}
/* Print out the early node map */
pr_info("Early memory node ranges\n");
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, &nid)
pr_info(" node %3d: [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
((u64)end_pfn << PAGE_SHIFT) - 1);这样我们得到了各个zone的pfn的范围,node ranges是真正物理内存:
[ 0.000000] Zone ranges:
[ 0.000000] DMA [mem 0x00001000-0x00ffffff] arch_zone_lowest_possible_pfn/arch_zone_highest_possible_pfn
[ 0.000000] DMA32 [mem 0x01000000-0xffffffff]
[ 0.000000] Normal [mem 0x100000000-0x23fffffff]
[ 0.000000] Movable zone start for each node
[ 0.000000] Early memory node ranges
[ 0.000000] node 0: [mem 0x00001000-0x0009dfff] ram memory
[ 0.000000] node 0: [mem 0x00100000-0xbfecffff]
[ 0.000000] node 0: [mem 0xbff00000-0xbfffffff]
[ 0.000000] node 0: [mem 0x100000000-0x23fffffff]接下来执行核心函数:
[mm/page_alloc.c]
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
pgdat->per_cpu_nodestats = NULL;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
#else
start_pfn = node_start_pfn;
#endif
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
alloc_node_mem_map(pgdat);
reset_deferred_meminit(pgdat);
free_area_init_core(pgdat);
}- 初始化pg_data_t相关的数据,输出memblock的memory 起始和结束,和前面看到的一致的。
[ 0.000000] Initmem setup node 0 [mem 0x00001000-0x23fffffff]- calculate_node_totalpages确定zone/node的spanned_pages和present_pages
[mm/page_alloc.c]
static void __meminit calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zones_size,
unsigned long *zholes_size)
{
unsigned long realtotalpages = 0, totalpages = 0;
enum zone_type i;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
unsigned long zone_start_pfn, zone_end_pfn;
unsigned long size, real_size;
size = zone_spanned_pages_in_node(pgdat->node_id, i,
node_start_pfn,
node_end_pfn,
&zone_start_pfn,
&zone_end_pfn,
zones_size);
real_size = size - zone_absent_pages_in_node(pgdat->node_id, i,
node_start_pfn, node_end_pfn,
zholes_size);
if (size)
zone->zone_start_pfn = zone_start_pfn;
else
zone->zone_start_pfn = 0;
zone->spanned_pages = size;
zone->present_pages = real_size;
totalpages += size;
realtotalpages += real_size;
}
pgdat->node_spanned_pages = totalpages;
pgdat->node_present_pages = realtotalpages;
printk(KERN_DEBUG "On node %d totalpages: %lu\n", pgdat->node_id,
realtotalpages);
}
zone_spanned_pages_in_node,计算spanned pages,即不包含hole:
arch_zone_highest_possible_pfn[zone_type] - arch_zone_lowest_possible_pfn[zone_type]
zone_absent_pages_in_node
这里确定了(zone->spanned_pages, zone->present_pages, pgdat->node_spanned_pages, pgdat->node_present_pages )
On node 0 totalpages: 2097005 //和system ram memory数量一致[mm/page_alloc.c]
static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
realsize = freesize = zone->present_pages;
memmap_pages = calc_memmap_size(size, realsize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
zone->node = nid;
zone->name = zone_names[j];
zone->zone_pgdat = pgdat;
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
init_currently_empty_zone(zone, zone_start_pfn, size);
memmap_init(size, nid, j, zone_start_pfn);
}
}
- calc_memmap_size计算zone内 page占用页面的大小(PAGE_ALIGN(pages * sizeof(struct page)) >> PAGE_SHIFT)
- freesize -= memmap_pages; freesize除去这部分管理page的内存大小
- freesize -= dma_reserve; 预留处dma 保存的内存
- zone->managed_pages = is_highmem_idx(j) ? realsize : freesize; 设定buddy allocator能够管理的page的大小
static __meminit void zone_pcp_init(struct zone *zone)
{
zone->pageset = &boot_pageset;
if (populated_zone(zone))
printk(KERN_DEBUG " %s zone: %lu pages, LIFO batch:%u\n",
zone->name, zone->present_pages,
zone_batchsize(zone));
}present page要除去memmap和reserved内存,剩下的才是buddy alloctor需要管理的,可以参照下面的输出信息:
On node 0 totalpages: 2097005
[ 0.000000] DMA zone: 64 pages used for memmap
[ 0.000000] DMA zone: 21 pages reserved
[ 0.000000] DMA zone: 3997 pages, LIFO batch:0 //zone->present_pages
[ 0.000000] DMA32 zone: 12224 pages used for memmap
[ 0.000000] DMA32 zone: 782288 pages, LIFO batch:31
[ 0.000000] Normal zone: 20480 pages used for memmap
[ 0.000000] Normal zone: 1310720 pages, LIFO batch:31
pgdat->node_present_pages = 3997 + 782288 + 1310720 = 2097005
zone->managed_pages:
DMA: 3997 - 21 - 64 = 3912; DMA32: 782288 - 12224 = 770064; Normal: 262144 - 4096 = 258048
- set_pageblock_order pageblock用于管理migratetype的各种page,在内存足够的情况下,pageblock按照bit进行管理,即pageblock *migratetype
- setup_usemap, 在zone->pageblock_flags将上述pageblock的管理结构进行分配
- init_currently_empty_zone 初始化freelist等
- memmap_init_zone 将migratetype都设置为MIGRATE_MOVABLE,这样在分配时其他类型可以通过steal方式分配大块内存,避免内部碎片
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context,
struct vmem_altmap *altmap)
{
if (!(pfn & (pageblock_nr_pages - 1))) {
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
cond_resched();
}
}2.2.2 zoneref初始化
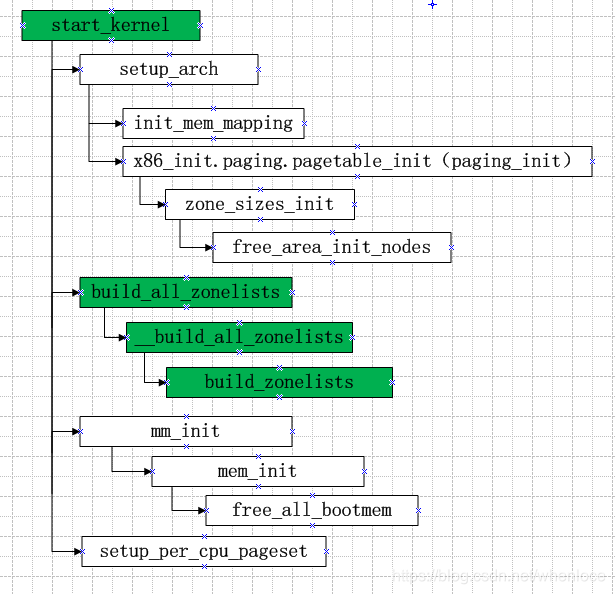
[mm/page_alloc.c]
static void build_zonelists(pg_data_t *pgdat)
{
int i, node, load;
nodemask_t used_mask;
int local_node, prev_node;
struct zonelist *zonelist;
unsigned int order = current_zonelist_order;
for (i = 0; i < MAX_ZONELISTS; i++) {
zonelist = pgdat->node_zonelists + i;
zonelist->_zonerefs[0].zone = NULL;
zonelist->_zonerefs[0].zone_idx = 0;
}
local_node = pgdat->node_id;
load = nr_online_nodes;
prev_node = local_node;
nodes_clear(used_mask);
memset(node_order, 0, sizeof(node_order));
i = 0;
while ((node = find_next_best_node(local_node, &used_mask)) >= 0) {
if (node_distance(local_node, node) !=
node_distance(local_node, prev_node))
node_load[node] = load;
prev_node = node;
load--;
if (order == ZONELIST_ORDER_NODE)
build_zonelists_in_node_order(pgdat, node);
else
node_order[i++] = node; /* remember order */
}
if (order == ZONELIST_ORDER_ZONE) {
build_zonelists_in_zone_order(pgdat, i);
}
build_thisnode_zonelists(pgdat);
}- build_zonelists的作用是用来设置分配内存的fallback方式(即按照node_id,zone_type组合选择对应的zone),这在内核中使用zoneref来记录。
#define MAX_ZONES_PER_ZONELIST (MAX_NUMNODES * MAX_NR_ZONES)
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};目前内核提供了三种组合方式选择:
#define ZONELIST_ORDER_DEFAULT 0 0 = automatic detection of better ordering.
#define ZONELIST_ORDER_NODE 1 1 = order by ([node] distance, -zonetype)
#define ZONELIST_ORDER_ZONE 2 2 = order by (-zonetype, [node] distance)我们分析1,即按node顺序选择,每次循环选择一个最优的node (find_next_best_node),调用build_zonelists_in_node_order
static int build_zonelists_node(pg_data_t *pgdat, struct zonelist *zonelist,
int nr_zones)
{
struct zone *zone;
enum zone_type zone_type = MAX_NR_ZONES;
do {
zone_type--;
zone = pgdat->node_zones + zone_type;
if (managed_zone(zone)) {
zoneref_set_zone(zone,
&zonelist->_zonerefs[nr_zones++]);
check_highest_zone(zone_type);
}
} while (zone_type);
return nr_zones;
}
static void build_zonelists_in_node_order(pg_data_t *pgdat, int node)
{
int j;
struct zonelist *zonelist;
zonelist = &pgdat->node_zonelists[ZONELIST_FALLBACK];
for (j = 0; zonelist->_zonerefs[j].zone != NULL; j++)
;
j = build_zonelists_node(NODE_DATA(node), zonelist, j);
zonelist->_zonerefs[j].zone = NULL;
zonelist->_zonerefs[j].zone_idx = 0;
}- build_zonelists_in_node_order每次就是按照node填充j个 zonerefs,j即是zone中zone_type的数量,需要注意的是,zonerefs->zone=NULL表示zonerefs的终结
- build_zonelists_node填充node对应的zone个zonerefs,这里需要注意的是zone_type是按照从大到小的顺序填充的,这意味着,如果用户指定HIGH_MEM,如果分配失败会向下尝试,如NORMAL, DMA.
一个zonerefs可能向下面这样:

2.2.3 伙伴系统建立
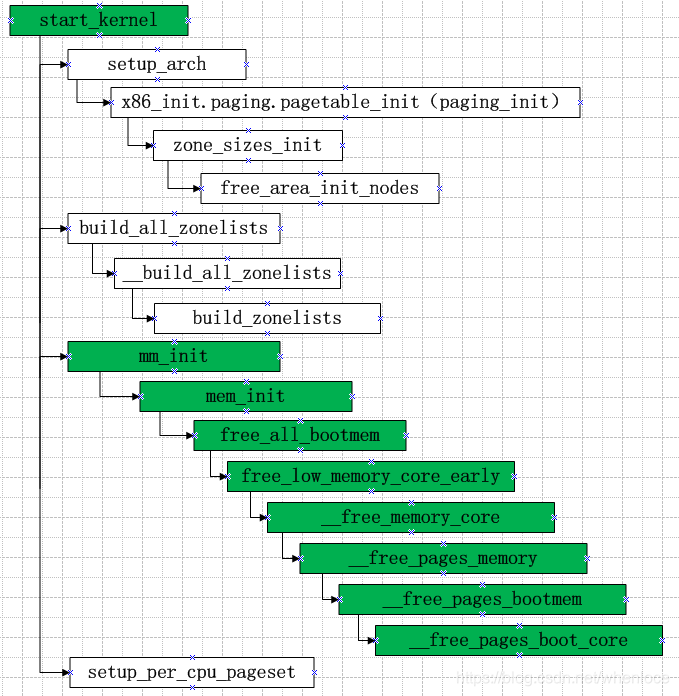
[init/main.c]
/* Set up kernel memory allocators */
static void __init mm_init(void)
{
page_cgroup_init_flatmem();
mem_init();
kmem_cache_init();
percpu_init_late();
pgtable_cache_init();
vmalloc_init();
}[mm/nobootmem.c]
unsigned long __init free_all_bootmem(void)
{
unsigned long pages;
reset_all_zones_managed_pages();
pages = free_low_memory_core_early();
totalram_pages += pages;
return pages;
}- reset_all_zones_managed_pages 将zone->managed_pages清空了,在向伙伴系统释放时进行累加,所以前面的赋值是无用的:(
- 这里注意totalram_pages, 这就是cat /proc/meminfo时显示的总的内存,当然这里是第一次累加,还有其他的地方。
TIPS: totalram_pages的计算:
- free_all_bootmem
- __memblock_free_late
- free_bootmem_late
- adjust_managed_page_count
其中前三个调用实现相同,我的机器上只有free_all_bootmem调用了
adjust_managed_page_count 释放主要有两个途径
- init_cma_reserved_pageblock
- free_reserved_area / free_reserved_page
总的来说,totalram_pages就是ram中需要纳入伙伴系统管理的那部分内存。
[mm/nobootmem.c]
static unsigned long __init free_low_memory_core_early(void)
{
unsigned long count = 0;
phys_addr_t start, end;
u64 i;
memblock_clear_hotplug(0, -1);
for_each_reserved_mem_region(i, &start, &end)
reserve_bootmem_region(start, end);
for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end,
NULL)
count += __free_memory_core(start, end);
return count;
}for_each_free_mem_range的作用是:
Walks over free (memory && !reserved) areas of memblock,即遍历可用内存中没有被reserved的那部分
void __meminit reserve_bootmem_region(phys_addr_t start, phys_addr_t end)
{
unsigned long start_pfn = PFN_DOWN(start);
unsigned long end_pfn = PFN_UP(end); //将包含start, end的页面全部计算进来
for (; start_pfn < end_pfn; start_pfn++) {
if (pfn_valid(start_pfn)) {
struct page *page = pfn_to_page(start_pfn);
init_reserved_page(start_pfn);
/* Avoid false-positive PageTail() */
INIT_LIST_HEAD(&page->lru);
SetPageReserved(page); //注意这句
}
}
}每次遍历,首先对memblock reserved的页面进行初始化init_reserved_page,然后设置页面为reserved的(SetPageReserved),这样的页面不允许回收!
接下来是可用的ram
[mm/nobootmem.c]
static unsigned long __init __free_memory_core(phys_addr_t start,
phys_addr_t end)
{
//和处理reserved内存对应,这里取最少的页面,避免和reserved冲突
unsigned long start_pfn = PFN_UP(start);
unsigned long end_pfn = min_t(unsigned long, PFN_DOWN(end), max_low_pfn);
if (start_pfn > end_pfn)
return 0;
__free_pages_memory(start_pfn, end_pfn);
return end_pfn - start_pfn;
}[mm/nobootmem.c]
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{
int order;
while (start < end) {
order = min(MAX_ORDER - 1UL, __ffs(start));
while (start + (1UL << order) > end)
order--;
__free_pages_bootmem(pfn_to_page(start), start, order);
start += (1UL << order);
}
}order = min(MAX_ORDER - 1UL, __ffs(start)); 确定每次释放的order从小到大,由于每次ffs取右侧数第一个“1”,这也意味着释放的order的增加
while (start + (1UL << order) > end)
order--;
这个条件限制释放的右边界,避免超出范围
[mm/page_alloc.c]
static void __init __free_pages_boot_core(struct page *page, unsigned int order)
{
unsigned int nr_pages = 1 << order;
struct page *p = page;
unsigned int loop;
prefetchw(p);
for (loop = 0; loop < (nr_pages - 1); loop++, p++) {
prefetchw(p + 1);
__ClearPageReserved(p);
set_page_count(p, 0);
}
__ClearPageReserved(p);
set_page_count(p, 0);
page_zone(page)->managed_pages += nr_pages;
set_page_refcounted(page);
__free_pages(page, order);
}- 将每个page的reserved标志清除__ClearPageReserved
- page_zone(page)->managed_pages += nr_pages; 增加zone管理页面的数目
- 最终调用__free_pages将page释放给buddy allocator进行管理。
最后,打印机器的内存信息:
void __init mem_init_print_info(const char *str)
{
unsigned long physpages, codesize, datasize, rosize, bss_size;
unsigned long init_code_size, init_data_size;
physpages = get_num_physpages();
codesize = _etext - _stext;
datasize = _edata - _sdata;
rosize = __end_rodata - __start_rodata;
bss_size = __bss_stop - __bss_start;
init_data_size = __init_end - __init_begin;
init_code_size = _einittext - _sinittext;
...
printk("Memory: %luK/%luK available "
"(%luK kernel code, %luK rwdata, %luK rodata, "
"%luK init, %luK bss, %luK reserved"
"%s%s)\n",
nr_free_pages() << (PAGE_SHIFT-10), physpages << (PAGE_SHIFT-10),
codesize >> 10, datasize >> 10, rosize >> 10,
(init_data_size + init_code_size) >> 10, bss_size >> 10,
(physpages - totalram_pages) << (PAGE_SHIFT-10),
str ? ", " : "", str ? str : "");
}
Memory: 4940384k/9437184k available (6884k kernel code, 1049164k absent,
450780k reserved, 4539k data, 1768k init)
calhost a]# dmesg | grep Freeing
[ 0.006194] Freeing SMP alternatives: 24k freed
[ 18.209711] Freeing initrd memory: 55044k freed
[ 18.796446] Freeing unused kernel memory: 1768k freed
2.3 伙伴系统API
伙伴系统使用order概念描述页的数量单位,在Linux中有MAX_ORDER个order。满足特定关系的同阶的page block称为buddy,这个关系是:
- 两个page block物理地址连续
2.3.1 分配
struct page * alloc_pages(gfp_t gfp_mask, unsigned int order);
上面说过内存的层级是node->zone->page, alloc_pages通过指定gfp_mask,由GFP_ZONE_TABLE确定首先在哪个zone进行分配。如果首选内存节点和区域不能满足要求,需要从其他区域分配,这种情况需要满足以下条件【1】:
- 可以从另一个节点相同的区域借用
- 高区域类型可以从低区域类型借用,而低区域类型不能从高区域类型借用
从上面的描述可以看到,从其他内存区域借用内存需要考虑两个维度:内存节点优先还是区域优先,这在Linux中是可选的。实现的结构是上面说过的zoneref
alloc_pages->__alloc_pages_nodemask
struct page * __alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
gfp_mask &= gfp_allowed_mask;
alloc_mask = gfp_mask;
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))
return NULL;
finalise_ac(gfp_mask, order, &ac);
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
alloc_mask = current_gfp_context(gfp_mask);
ac.spread_dirty_pages = false;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
return page;
}- prepare_alloc_pages确定分配内存的标记,主要是:
ac->high_zoneidx = gfp_zone(gfp_mask);
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
ac->migratetype = gfpflags_to_migratetype(gfp_mask);- zone_type,确定从哪个zone分配
- zonelist
- migratetype
- finalise_ac 确定zoneref
static __always_inline struct zoneref *next_zones_zonelist(struct zoneref *z,
enum zone_type highest_zoneidx,
nodemask_t *nodes)
{
if (likely(!nodes && zonelist_zone_idx(z) <= highest_zoneidx))
return z;
return __next_zones_zonelist(z, highest_zoneidx, nodes);
}
static inline struct zoneref *first_zones_zonelist(struct zonelist *zonelist,
enum zone_type highest_zoneidx,
nodemask_t *nodes)
{
return next_zones_zonelist(zonelist->_zonerefs,
highest_zoneidx, nodes);
}
static inline void finalise_ac(gfp_t gfp_mask,
unsigned int order, struct alloc_context *ac)
{
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}可以看到最后的next_zones_zonelist就是在单node时,按照zone_type的降序依次进行尝试,而__next_zones_zonelist对应于numa
接下来,进行第一次get_page_from_freelist分配,先只考虑正常分配流程:
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
try_this_zone:
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
prep_new_page(page, order, gfp_mask, alloc_flags);
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
}
}
return NULL;
}- for_next_zone_zonelist_nodemask 按照zone_type遍历zone
- rmqueue用于从指定zone分配page
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
if (likely(order == 0)) {
page = rmqueue_pcplist(preferred_zone, zone, order,
gfp_flags, migratetype);
goto out;
}
spin_lock_irqsave(&zone->lock, flags);
do {
page = NULL;
if (!page)
page = __rmqueue(zone, order, migratetype);
} while (page && check_new_pages(page, order));
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);
zone_statistics(preferred_zone, zone);
local_irq_restore(flags);
}- 分成两种情况:单个page,多个page
先来看多个page的分配情况:
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype)
{
struct page *page;
retry:
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page)) {
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);
if (!page && __rmqueue_fallback(zone, order, migratetype))
goto retry;
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
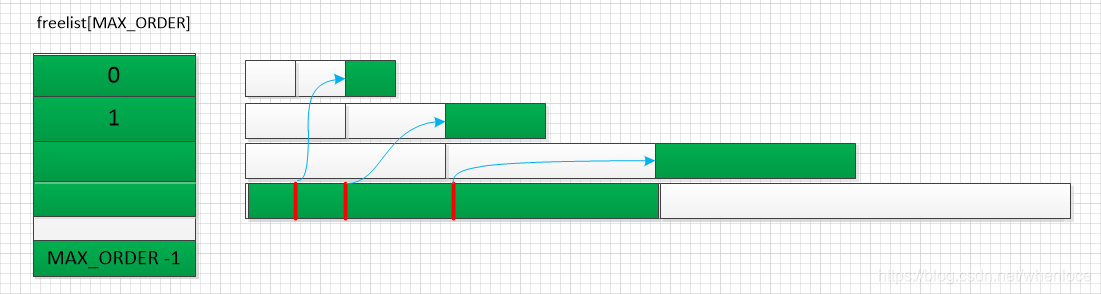
}从前面我们知道zone中内存分配时基于freelist和migratetype的,上面的函数时伙伴系统分配的核心代码,代码很好理解,就是按照order遍历migratetype对应的freelist,当找到适合的order的freelist,就将page从对应的freelist移除,由于找到的order可能比请求的order要大,所以要通过expand函数,将page不断切分,直到每个order的配置都挂到对应的freelist中去
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}下面的图展示了一个expand过程:
若__rmqueue_smallest失败,__rmqueue_fallback会尝试其他migratetype的freelist
static __always_inline bool __rmqueue_fallback(struct zone *zone, int order, int start_migratetype)
{
struct free_area *area;
int current_order;
struct page *page;
int fallback_mt;
bool can_steal;
for (current_order = MAX_ORDER - 1; current_order >= order;
--current_order) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt == -1)
continue;
if (!can_steal && start_migratetype == MIGRATE_MOVABLE
&& current_order > order)
goto find_smallest;
goto do_steal;
}
return false;
find_smallest:
for (current_order = order; current_order < MAX_ORDER;
current_order++) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt != -1)
break;
}
do_steal:
page = list_first_entry(&area->free_list[fallback_mt],
struct page, lru);
steal_suitable_fallback(zone, page, start_migratetype, can_steal);
return true;
}首先要确定是否可以从其他的migratetype中steal内存,首先看一下fallback的顺序:
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};和前面不同的是,从migratetype的高order开始向下查找,这样可以避免小的内存碎片
2.3.2 释放页
- void free_pages(unsigned long addr, unsigned int order)
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_unref_page(page);
else
__free_pages_ok(page, order);
}
}__free_pages_ok->free_one_page->__free_one_page
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long combined_pfn;
unsigned long uninitialized_var(buddy_pfn);
struct page *buddy;
unsigned int max_order;
max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);
continue_merging:
while (order < max_order - 1) {
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn))
goto done_merging;
if (!page_is_buddy(page, buddy, order))
goto done_merging;
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
if (max_order < MAX_ORDER) {
max_order++;
goto continue_merging;
}
done_merging:
set_page_order(page, order);
if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)) {
struct page *higher_page, *higher_buddy;
combined_pfn = buddy_pfn & pfn;
higher_page = page + (combined_pfn - pfn);
buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);
higher_buddy = higher_page + (buddy_pfn - combined_pfn);
if (pfn_valid_within(buddy_pfn) &&
page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
}
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}continue_merging,和分配相反,释放时如果检测到buddy page可以合并一直向上合并
static inline unsigned long
__find_buddy_pfn(unsigned long page_pfn, unsigned int order)
{
return page_pfn ^ (1 << order);
}注意检测buddy page的技巧,一个page的buddy pfn有两种情况,即在order下,pfnA的buddy pfnB是 pfnA + (1 << order)或pfnA - (1 << order),这样就可以通过检测 1 << order 的bit是否存在来计算buddy pfn,可以使用^
三、参考
【1】Linux内核深度解析
【2】深入Linux内核架构

















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









