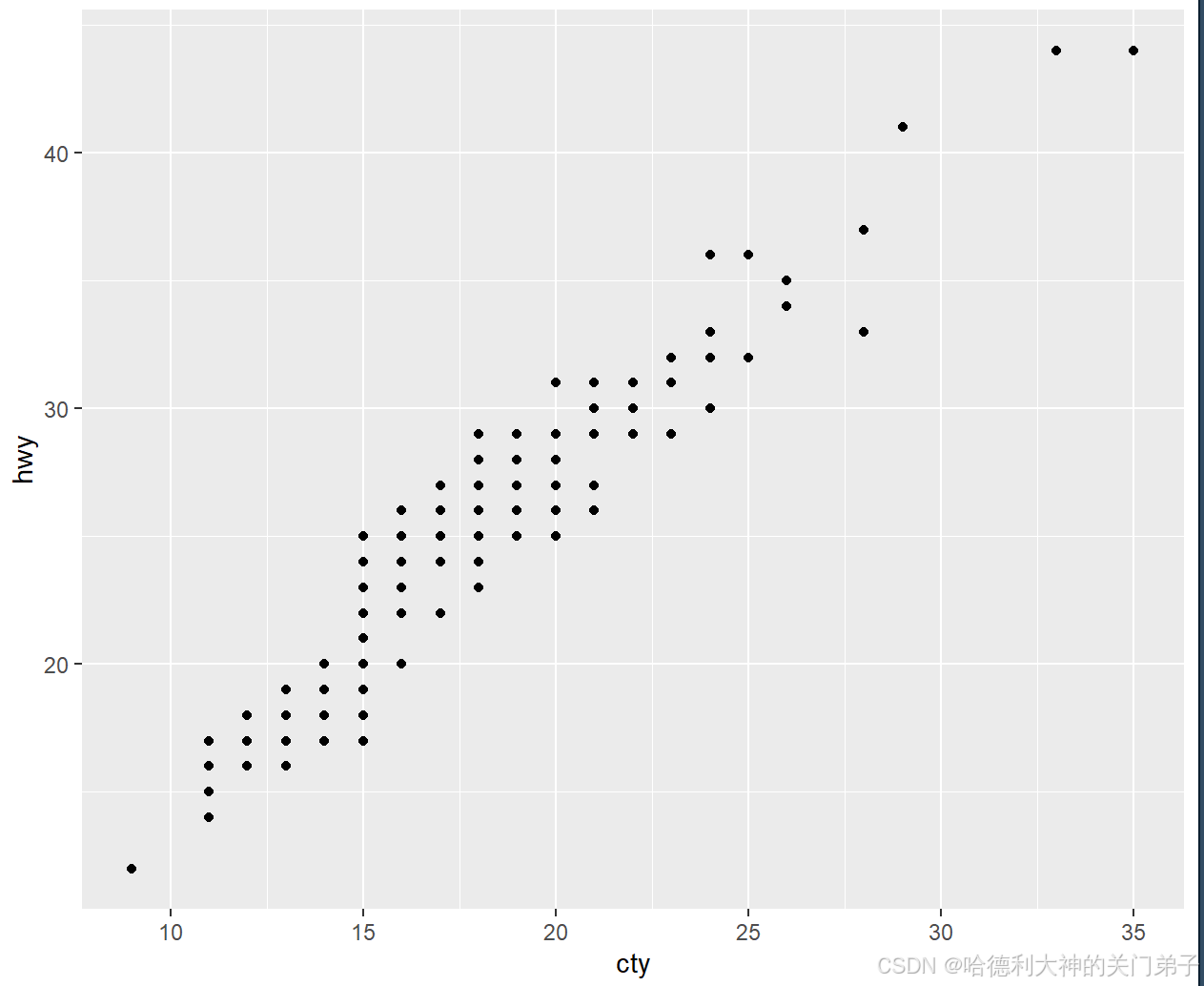
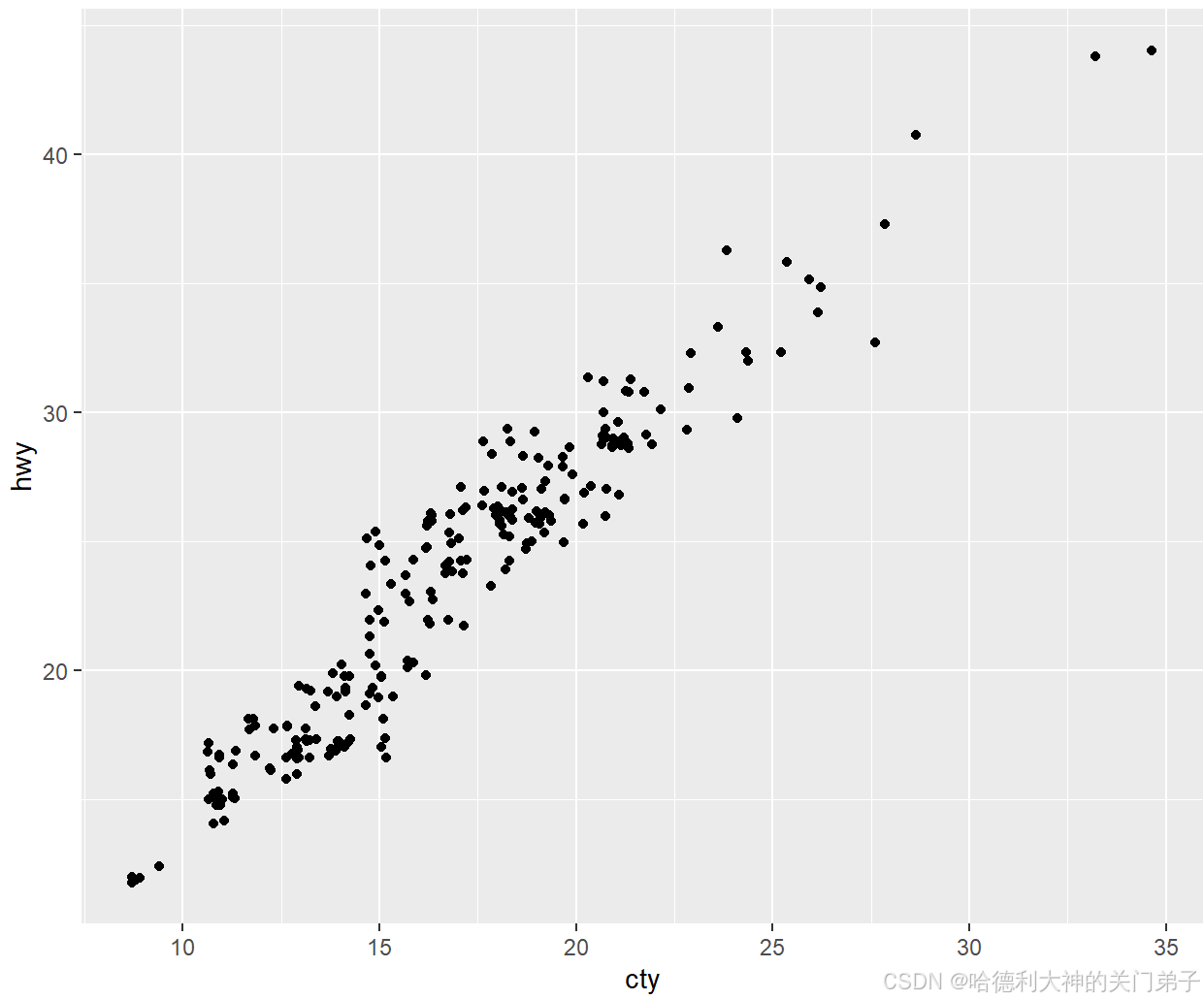
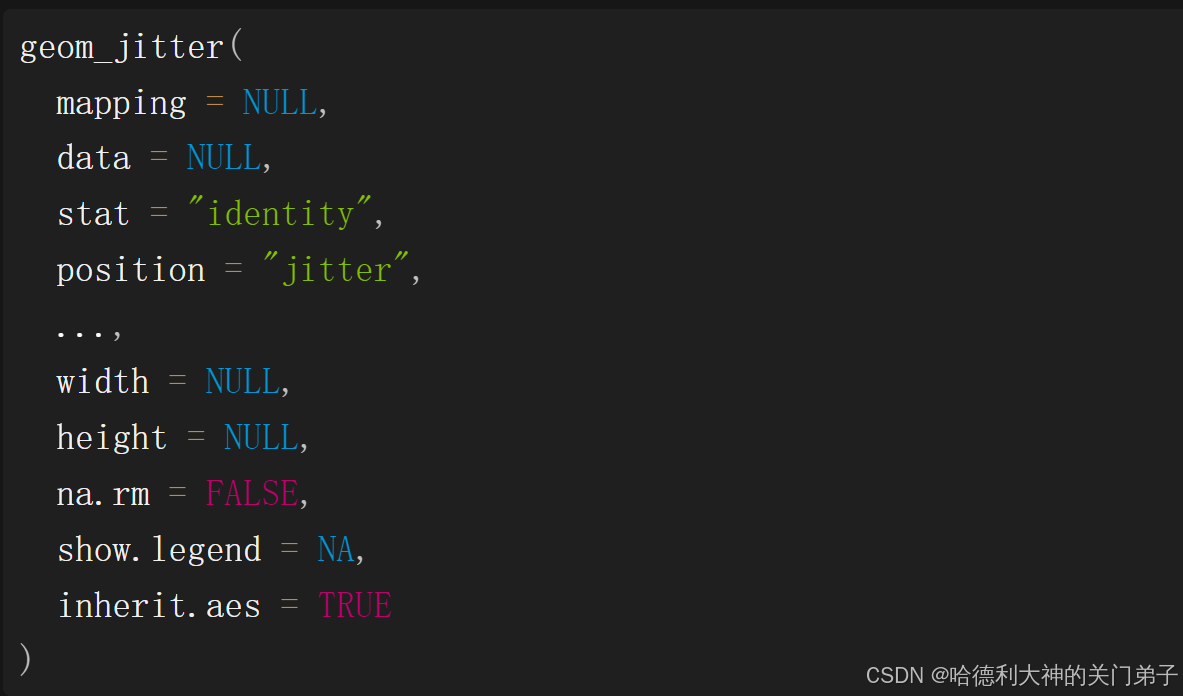
一、以下图形有什么问题?应该如何改善? 该图形的问题在于:同一个位置有多个重叠的点,无法准确观察数据分布特点,应将位置调整方式设为“抖动”,就可以将重叠的点分散开来,因为不可能有两个点会收到同样的随机扰动。 二、geom_jitter()使用哪些参数来控制抖动的程度? 以下参数可控制抖动的程度 三、对比geom_jitter()与geom_count()。 1.geom_jitter()通过随机抖动来区分重叠的点;geom_count()通过点的大小来表示每个位置的点的数目; 2.geom_jitter()适用于连续变量的散点图;geom_coun

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2181
2181





