



 Lucene是一个全文搜索框架,用于构建自定义的搜索引擎。它提供了倒排索引功能,支持文档域加权和特定项搜索。性能表现良好,如在250万记录测试中,平均处理时间为300ms。LZ4压缩算法被应用于索引,提高效率。工作流程包括源字符串的分词、处理、存储和检索。Lucene适用于新闻资料库、数据库搜索等场景。
Lucene是一个全文搜索框架,用于构建自定义的搜索引擎。它提供了倒排索引功能,支持文档域加权和特定项搜索。性能表现良好,如在250万记录测试中,平均处理时间为300ms。LZ4压缩算法被应用于索引,提高效率。工作流程包括源字符串的分词、处理、存储和检索。Lucene适用于新闻资料库、数据库搜索等场景。
lucene
1.什么是lucene它能干什么?
Lucene是一个全文搜索框架,而不是应用产品。因此它并不像http://www.baidu.com/ 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
要回答这个问题,先要了解lucene的本质。实际上lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键词出现在哪里。知道了这个本质,你就可以发挥想象做任何符合这个条件的事情了。你可以把站内新闻都索引了,做个资料库;你可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;你也可以写个自己的搜索引擎……
lucene的性能怎么样
下面给出一些测试数据,如果你觉得可以接受,那么可以选择。
测试一:250万记录,300M左右文本,生成索引380M左右,800线程下平均处理时间300ms。
测试二:37000记录,索引数据库中的两个varchar字段,索引文件2.6M,800线程下平均处理时间1.5ms。
lucene倒排索引 :
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排文件(倒排索引),索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文档或者文档集合的一种最常用的索引机制。
搜索引擎的关键步骤就是建立倒排索引,倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
lucene压缩算法:
LZ4算法又称为Realtime Compression Algorithm,在操作系统(linux/freeBSD)、文件系统(OpenZFS)、大数据(Hadoop)、搜索引擎(Lucene/solr)、数据库(Hbase)……都可以看到它的身影,可以说是一个非常通用的算法。LZ4最突出的地方在于它的压缩/解压速度。
lucene的工作方式
lucene提供的服务实际包含两部分:一入一出。所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源
写入流程
源字符串首先经过analyzer处理,包括:分词,分成一个个单词;去除stopword(可选)。 将源中需要的信息加入Document的各个Field中,并把需要索引的Field索引起来,把需要存储的Field存储起来。 将索引写入存储器,存储器可以是内存或磁盘。
读出流程
用户提供搜索关键词,经过analyzer处理。 对处理后的关键词搜索索引找出对应的Document。 用户根据需要从找到的Document中提取需要的Field。
document
用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。用户进行搜索,也是以Document列表的形式返回。
field
一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过Field在Document中存储的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要
lucene的pop依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.javaxl</groupId>
<artifactId>javaxl_lunece_freemarker</artifactId>
<packaging>war</packaging>
<version>0.0.1-SNAPSHOT</version>
<name>javaxl_lunece_freemarker Maven Webapp</name>
<url>http://maven.apache.org</url>
<properties>
<httpclient.version>4.5.2</httpclient.version>
<jsoup.version>1.10.1</jsoup.version>
<!-- <lucene.version>7.1.0</lucene.version> -->
<lucene.version>5.3.1</lucene.version>
<ehcache.version>2.10.3</ehcache.version>
<junit.version>4.12</junit.version>
<log4j.version>1.2.16</log4j.version>
<mysql.version>5.1.44</mysql.version>
<fastjson.version>1.2.47</fastjson.version>
<struts2.version>2.5.16</struts2.version>
<servlet.version>4.0.1</servlet.version>
<jstl.version>1.2</jstl.version>
<standard.version>1.1.2</standard.version>
<tomcat-jsp-api.version>8.0.47</tomcat-jsp-api.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<!-- jdbc驱动包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- 添加Httpclient支持 -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>${httpclient.version}</version>
</dependency>
<!-- 添加jsoup支持 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>${jsoup.version}</version>
</dependency>
<!-- 添加日志支持 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<!-- 添加ehcache支持 -->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>${ehcache.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.apache.struts</groupId>
<artifactId>struts2-core</artifactId>
<version>${struts2.version}</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>${servlet.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version> </dependency> -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- 5.3、jstl、standard -->
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
<version>${jstl.version}</version>
</dependency>
<dependency>
<groupId>taglibs</groupId>
<artifactId>standard</artifactId>
<version>${standard.version}</version>
</dependency>
<!-- 5.4、tomcat-jsp-api -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jsp-api</artifactId>
<version>${tomcat-jsp-api.version}</version>
</dependency>
</dependencies>
<build>
<finalName>javaxl_lunece_freemarker</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
实际代码
后台代码
BlogAciton.java
package com.javaxl.lucene;
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
/**
* 配合Demo1.java进行lucene的helloword实现
* @author Administrator
*
*/
public class IndexCreate {
private IndexWriter indexWriter;
/**
* 1、构造方法 实例化IndexWriter
* @param indexDir
* @throws Exception
*/
public IndexCreate(String indexDir) throws Exception{
// 获取索引文件的存放地址对象
FSDirectory dir = FSDirectory.open(Paths.get(indexDir));
// 标准分词器(针对英文)
Analyzer analyzer = new StandardAnalyzer();
// 索引输出流配置对象
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
indexWriter = new IndexWriter(dir, conf);
}
/**
* 2、关闭索引输出流
* @throws Exception
*/
public void closeIndexWriter() throws Exception{
indexWriter.close();
}
/**
* 3、索引指定路径下的所有文件
* @param dataDir
* @return
* @throws Exception
*/
public int index(String dataDir) throws Exception{
File[] files = new File(dataDir).listFiles();
for (File file : files) {
indexFile(file);
}
return indexWriter.numDocs();
}
/**
* 4、索引指定的文件
* @param file
* @throws Exception
*/
private void indexFile(File file) throws Exception{
System.out.println("被索引文件的全路径:"+file.getCanonicalPath());
Document doc = getDocument(file);
indexWriter.addDocument(doc);
}
/**
* 5、获取文档(索引文件中包含的重要信息,key-value的形式)
* @param file
* @return
* @throws Exception
*/
private Document getDocument(File file) throws Exception{
Document doc = new Document();
doc.add(new TextField("contents", new FileReader(file)));
// Field.Store.YES是否存储到硬盘
doc.add(new TextField("fullPath", file.getCanonicalPath(),Field.Store.YES));
doc.add(new TextField("fileName", file.getName(),Field.Store.YES));
return doc;
}
}
BlogDao.java
package com.javaxl.lucene;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
/**
* 配合Demo2.java进行lucene的helloword实现
* @author Administrator
*
*/
public class IndexUse {
/**
* 通过关键字在索引目录中查询
* @param indexDir 索引文件所在目录
* @param q 关键字
*/
public static void search(String indexDir, String q) throws Exception{
FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));
// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的
IndexReader indexReader = DirectoryReader.open(indexDirectory);
// 获取索引搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
Analyzer analyzer = new StandardAnalyzer();
QueryParser queryParser = new QueryParser("contents", analyzer);
// 获取符合关键字的查询对象
Query query = queryParser.parse(q);
long start=System.currentTimeMillis();
// 获取关键字出现的前十次
TopDocs topDocs = indexSearcher.search(query , 10);
long end=System.currentTimeMillis();
System.out.println("匹配 "+q+" ,总共花费"+(end-start)+"毫秒"+"查询到"+topDocs.totalHits+"个记录");
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
int docID = scoreDoc.doc;
// 索引搜索对象通过文档下标获取文档
Document doc = indexSearcher.doc(docID);
System.out.println("通过索引文件:"+doc.get("fullPath")+"拿数据");
}
indexReader.close();
}
}
LuceneUilts
package com.javaxl.blog.util;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.highlight.Formatter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryTermScorer;
import org.apache.lucene.search.highlight.Scorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
/**
* lucene工具类
* @author Administrator
*
*/
public class LuceneUtil {
/**
* 获取索引文件存放的文件夹对象
*
* @param path
* @return
*/
public static Directory getDirectory(String path) {
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(path));
} catch (IOException e) {
e.printStackTrace();
}
return directory;
}
/**
* 索引文件存放在内存
*
* @return
*/
public static Directory getRAMDirectory() {
Directory directory = new RAMDirectory();
return directory;
}
/**
* 文件夹读取对象
*
* @param directory
* @return
*/
public static DirectoryReader getDirectoryReader(Directory directory) {
DirectoryReader reader = null;
try {
reader = DirectoryReader.open(directory);
} catch (IOException e) {
e.printStackTrace();
}
return reader;
}
/**
* 文件索引对象
*
* @param reader
* @return
*/
public static IndexSearcher getIndexSearcher(DirectoryReader reader) {
IndexSearcher indexSearcher = new IndexSearcher(reader);
return indexSearcher;
}
/**
* 写入索引对象
*
* @param directory
* @param analyzer
* @return
*/
public static IndexWriter getIndexWriter(Directory directory, Analyzer analyzer)
{
IndexWriter iwriter = null;
try {
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
// Sort sort=new Sort(new SortField("content", Type.STRING));
// config.setIndexSort(sort);//排序
config.setCommitOnClose(true);
// 自动提交
// config.setMergeScheduler(new ConcurrentMergeScheduler());
// config.setIndexDeletionPolicy(new
// SnapshotDeletionPolicy(NoDeletionPolicy.INSTANCE));
iwriter = new IndexWriter(directory, config);
} catch (IOException e) {
e.printStackTrace();
}
return iwriter;
}
/**
* 关闭索引文件生成对象以及文件夹对象
*
* @param indexWriter
* @param directory
*/
public static void close(IndexWriter indexWriter, Directory directory) {
if (indexWriter != null) {
try {
indexWriter.close();
} catch (IOException e) {
indexWriter = null;
}
}
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
directory = null;
}
}
}
/**
* 关闭索引文件读取对象以及文件夹对象
*
* @param reader
* @param directory
*/
public static void close(DirectoryReader reader, Directory directory) {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
reader = null;
}
}
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
directory = null;
}
}
}
/**
* 高亮标签
*
* @param query
* @param fieldName
* @return
*/
public static Highlighter getHighlighter(Query query, String fieldName)
{
Formatter formatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");
Scorer fragmentScorer = new QueryTermScorer(query, fieldName);
Highlighter highlighter = new Highlighter(formatter, fragmentScorer);
highlighter.setTextFragmenter(new SimpleFragmenter(200));
return highlighter;
}
}
创建 数据库 索引
IndexStarter
package com.javaxl.blog.web;
import java.io.IOException;
import java.nio.file.Paths;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import com.javaxl.blog.dao.BlogDao;
import com.javaxl.blog.util.PropertiesUtil;
/**
* 构建lucene索引
* @author Administrator
* 1。构建索引 IndexWriter
* 2、读取索引文件,获取命中片段
* 3、使得命中片段高亮显示
*
*/
public class IndexStarter {
private static BlogDao blogDao = new BlogDao();
public static void main(String[] args) {
IndexWriterConfig conf = new IndexWriterConfig(new SmartChineseAnalyzer());
Directory d;
IndexWriter indexWriter = null;
try {
d = FSDirectory.open(Paths.get(PropertiesUtil.getValue("indexPath")));
indexWriter = new IndexWriter(d , conf );
// 为数据库中的所有数据构建索引
List<Map<String, Object>> list = blogDao.list(null, null);
for (Map<String, Object> map : list) {
Document doc = new Document();
doc.add(new StringField("id", (String) map.get("id"), Field.Store.YES));
// TextField用于对一句话分词处理 java培训机构
doc.add(new TextField("title", (String) map.get("title"), Field.Store.YES));
doc.add(new StringField("url", (String) map.get("url"), Field.Store.YES));
indexWriter.addDocument(doc);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
try {
if(indexWriter!= null) {
indexWriter.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
接下来就修改数据库的密码 数据库名就好
前台代码
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
</head>
<body>
<form action="${pageContext.request.contextPath}/sy/blog_list.action"
method="post">
博客标题:<input type="text" name="title"> <input type="submit"
value="确定">
</form>
<button id="add">添加</button>
<button id="refresh">刷新全局索引</button>
<table border="1" width="100%">
<tr>
<td>编号</td>
<td>名称</td>
<td>价格</td>
<td>操作</td>
</tr>
<c:forEach items="${blogList }" var="blog">
<tr>
<td>${blog.id }</td>
<td>${blog.title }</td>
<td><a href="${blog.url }">${blog.title }</a></td>
<td>
<a href="">修改</a>
<a href="">删除</a>
</td>
</tr>
</c:forEach>
</table>
</body>
</html>
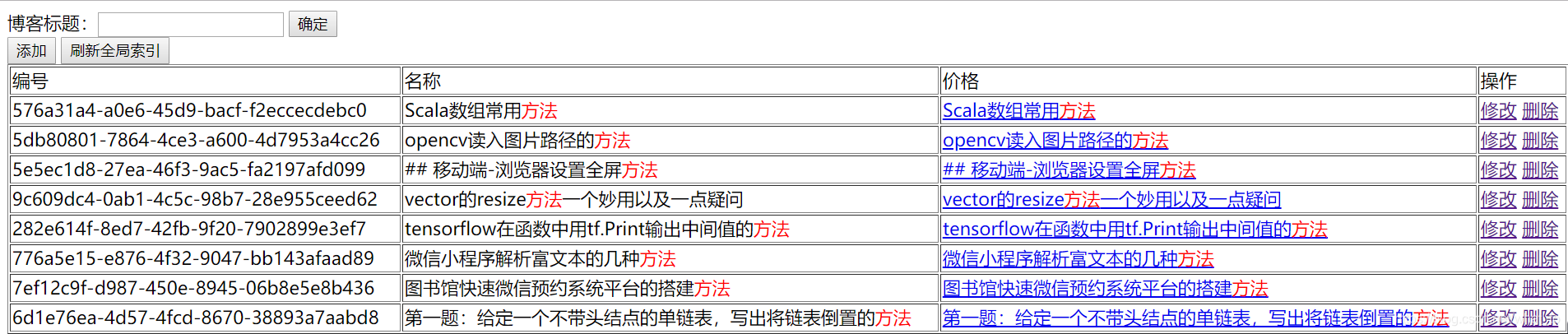
对索引的增删改
Demo3
package com.cpc.lucene;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
/**
* 构建索引
* 对索引的增删改
* @author Administrator
*
*/
public class Demo3 {
private String ids[]={"1","2","3"};
private String citys[]={"qingdao","nanjing","shanghai"};
private String descs[]={
"Qingdao is a beautiful city.",
"Nanjing is a city of culture.",
"Shanghai is a bustling city."
};
private FSDirectory dir;
/**
* 每次都生成索引文件
* @throws Exception
*/
@Before
public void setUp() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\temp\\demo2\\indexDir"));
IndexWriter indexWriter = getIndexWriter();
for (int i = 0; i < ids.length; i++) {
Document doc = new Document();
doc.add(new StringField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city", citys[i], Field.Store.YES));
doc.add(new TextField("desc", descs[i], Field.Store.NO));
indexWriter.addDocument(doc);
}
indexWriter.close();
}
/**
* 获取索引输出流
* @return
* @throws Exception
*/
private IndexWriter getIndexWriter() throws Exception{
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
return new IndexWriter(dir, conf );
}
/**
* 测试写了几个索引文件
* @throws Exception
*/
@Test
public void getWriteDocNum() throws Exception {
IndexWriter indexWriter = getIndexWriter();
System.out.println("索引目录下生成"+indexWriter.numDocs()+"个索引文件");
}
/**
* 打上标记,该索引实际并未删除
* @throws Exception
*/
@Test
public void deleteDocBeforeMerge() throws Exception {
IndexWriter indexWriter = getIndexWriter();
System.out.println("最大文档数:"+indexWriter.maxDoc());
indexWriter.deleteDocuments(new Term("id", "1"));
indexWriter.commit();
System.out.println("最大文档数:"+indexWriter.maxDoc());
System.out.println("实际文档数:"+indexWriter.numDocs());
indexWriter.close();
}
/**
* 对应索引文件已经删除,但是该版本的分词会保留
* @throws Exception
*/
@Test
public void deleteDocAfterMerge() throws Exception {
// https://blog.youkuaiyun.com/asdfsadfasdfsa/article/details/78820030
// org.apache.lucene.store.LockObtainFailedException: Lock held by this virtual machine:indexWriter是单例的、线程安全的,不允许打开多个。
IndexWriter indexWriter = getIndexWriter();
System.out.println("最大文档数:"+indexWriter.maxDoc());
indexWriter.deleteDocuments(new Term("id", "1"));
indexWriter.forceMergeDeletes(); //强制删除
indexWriter.commit();
System.out.println("最大文档数:"+indexWriter.maxDoc());
System.out.println("实际文档数:"+indexWriter.numDocs());
indexWriter.close();
}
/**
* 测试更新索引
* @throws Exception
*/
@Test
public void testUpdate()throws Exception{
IndexWriter writer=getIndexWriter();
Document doc=new Document();
doc.add(new StringField("id", "1", Field.Store.YES));
doc.add(new StringField("city","qingdao",Field.Store.YES));
doc.add(new TextField("desc", "dsss is a city.", Field.Store.NO));
writer.updateDocument(new Term("id","1"), doc);
writer.close();
}
}

文档域加权
package com.cpc.lucene;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
/**
* 文档域加权
* @author Administrator
*
*/
public class Demo4 {
private String ids[]={"1","2","3","4"};
private String authors[]={"Jack","Marry","John","Json"};
private String positions[]={"accounting","technician","salesperson","boss"};
private String titles[]={"Java is a good language.","Java is a cross platform language","Java powerful","You should learn java"};
private String contents[]={
"If possible, use the same JRE major version at both index and search time.",
"When upgrading to a different JRE major version, consider re-indexing. ",
"Different JRE major versions may implement different versions of Unicode,",
"For example: with Java 1.4, `LetterTokenizer` will split around the character U+02C6,"
};
private Directory dir;//索引文件目录
@Before
public void setUp()throws Exception {
dir = FSDirectory.open(Paths.get("D:\\temp\\demo3\\indexDir"));
IndexWriter writer = getIndexWriter();
for (int i = 0; i < authors.length; i++) {
Document doc = new Document();
doc.add(new StringField("id", ids[i], Field.Store.YES));
doc.add(new StringField("author", authors[i], Field.Store.YES));
doc.add(new StringField("position", positions[i], Field.Store.YES));
TextField textField = new TextField("title", titles[i], Field.Store.YES);
// Json投钱做广告,把排名刷到第一了
if("boss".equals(positions[i])) {
textField.setBoost(2f);//设置权重,默认为1
}
doc.add(textField);
// TextField会分词,StringField不会分词
doc.add(new TextField("content", contents[i], Field.Store.NO));
writer.addDocument(doc);
}
writer.close();
}
private IndexWriter getIndexWriter() throws Exception{
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
return new IndexWriter(dir, conf);
}
@Test
public void index() throws Exception{
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
String fieldName = "title";
String keyWord = "java";
Term t = new Term(fieldName, keyWord);
Query query = new TermQuery(t);
TopDocs hits = searcher.search(query, 10);
System.out.println("关键字:‘"+keyWord+"’命中了"+hits.totalHits+"次");
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println(doc.get("author"));
}
}
}
文本加域前后

特定项搜索
package com.cpc.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
/**
* 特定项搜索
* 查询表达式(queryParser)
* @author Administrator
*
*/
public class Demo5 {
@Before
public void setUp() {
// 索引文件将要存放的位置
String indexDir = "D:\\temp\\demo4";
// 数据源地址
String dataDir = "D:\\temp\\demo4\\data";
IndexCreate ic = null;
try {
ic = new IndexCreate(indexDir);
long start = System.currentTimeMillis();
int num = ic.index(dataDir);
long end = System.currentTimeMillis();
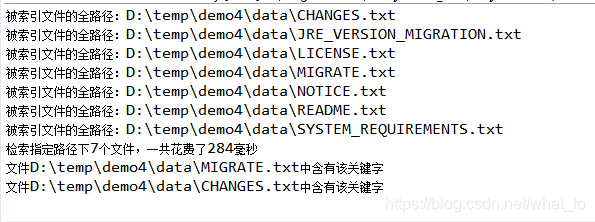
System.out.println("检索指定路径下" + num + "个文件,一共花费了" + (end - start) + "毫秒");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
ic.closeIndexWriter();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 特定项搜索
*/
@Test
public void testTermQuery() {
String indexDir = "D:\\temp\\demo4";
String fld = "contents";
String text = "indexformattoooldexception";
// 特定项片段名和关键字
Term t = new Term(fld , text);
TermQuery tq = new TermQuery(t );
try {
FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));
// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的
IndexReader indexReader = DirectoryReader.open(indexDirectory);
// 获取索引搜索对象
IndexSearcher is = new IndexSearcher(indexReader);
TopDocs hits = is.search(tq, 100);
// System.out.println(hits.totalHits);
for(ScoreDoc scoreDoc: hits.scoreDocs) {
Document doc = is.doc(scoreDoc.doc);
System.out.println("文件"+doc.get("fullPath")+"中含有该关键字");
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testQueryParser() {
String indexDir = "D:\\temp\\demo4";
// 获取查询解析器(通过哪种分词器去解析哪种片段)
QueryParser queryParser = new QueryParser("contents", new StandardAnalyzer());
try {
FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));
// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的
IndexReader indexReader = DirectoryReader.open(indexDirectory);
// 获取索引搜索对象
IndexSearcher is = new IndexSearcher(indexReader);
// 由解析器去解析对应的关键字
TopDocs hits = is.search(queryParser.parse("indexformattoooldexception") , 100);
for(ScoreDoc scoreDoc: hits.scoreDocs) {
Document doc = is.doc(scoreDoc.doc);
System.out.println("文件"+doc.get("fullPath")+"中含有该关键字");
}
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

















 7615
7615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









