




 文章介绍了机器学习中的基本概念,包括错误率、精度、过拟合和欠拟合等评估模型性能的指标。同时,详细阐述了假设、假设空间和版本空间的概念,以及训练集、验证集和测试集的作用。讨论了过拟合的问题,指出其难以避免并强调了模型泛化能力的重要性。
文章介绍了机器学习中的基本概念,包括错误率、精度、过拟合和欠拟合等评估模型性能的指标。同时,详细阐述了假设、假设空间和版本空间的概念,以及训练集、验证集和测试集的作用。讨论了过拟合的问题,指出其难以避免并强调了模型泛化能力的重要性。
前言:整理西瓜书第一、二章中的基本概念
待办:第二章评估方法、性能度量及后续内容未整理
下图梳理机器学习中部分概念
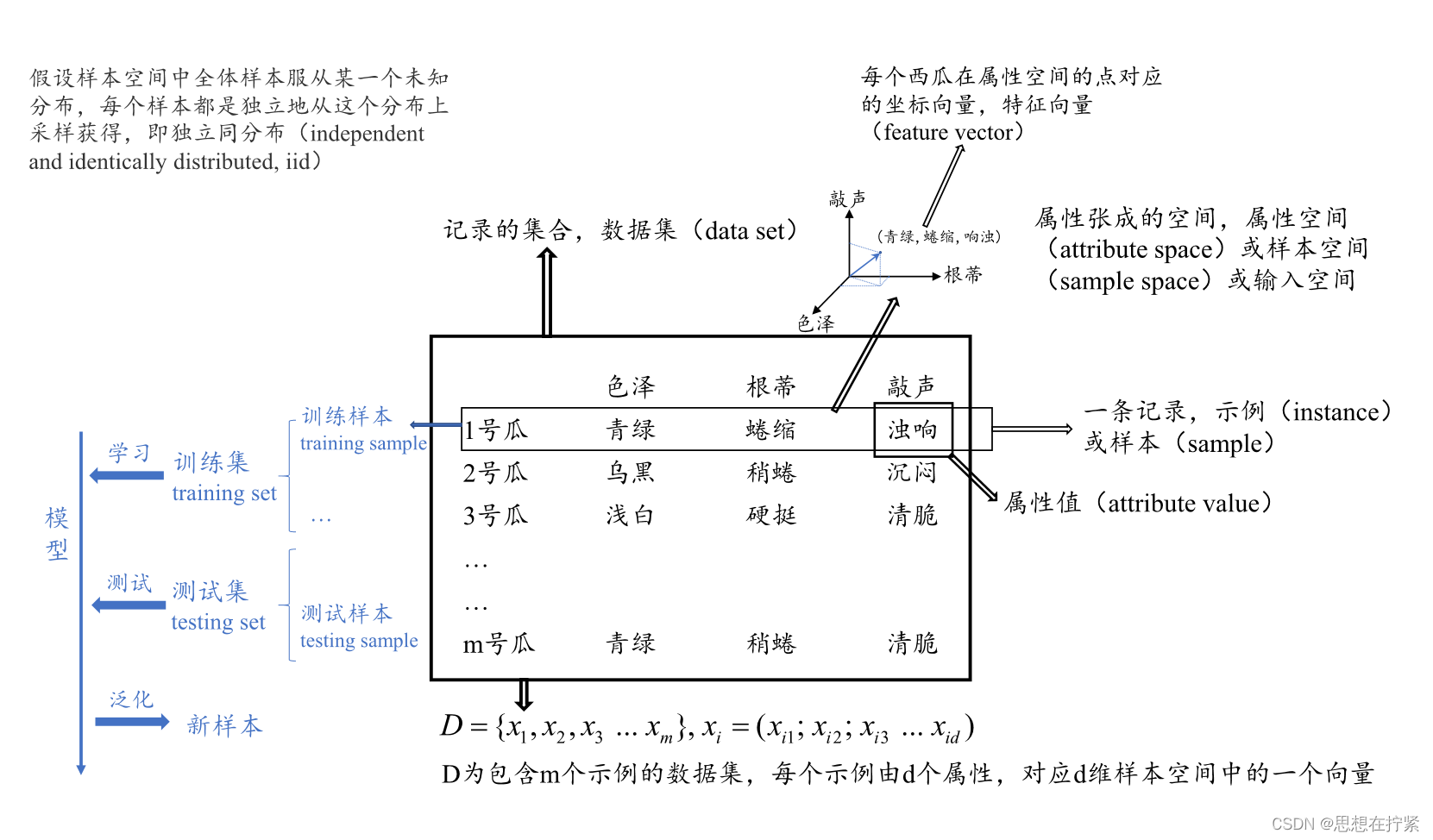
模型评估与选择相关知识点:
错误率(error rate, E):如果在m个样本中有a个样本分类错误,则错误率E=a/m
精度(accuracy)=1-E=1-a/m
误差(error):学习器的实际预测输出与样本的真实输出之间的差异。误差在不同数据集上含义不同,在训练集上的误差称为训练误差(training error)或经验误差(empirical error),在测试集上的误差称为测试误差(testing error),在新样本上的误差称为泛化误差(generalization error)。
过拟合(overfitting):学习能力过强,将训练样本中不太一般的特征学到。难以避免,只能缓解。
欠拟合(underfitting):学习能力低下。在决策树学习中拓展分支、在神经网络学习中增加训练轮数以克服。
学习问题
1、概念理解–假设、假设空间和版本空间
西瓜书P4-P6
假设(hypothesis):学得的模型对应假设空间中的一个假设。换句话说,一个假设就是一种映射方法,它把具有某些特定属性值的西瓜映射为好瓜,其余西瓜映射为坏瓜。1
假设空间(hypothesis space):所有不重复假设组成的空间。
版本空间(version space):一个与训练集一致的所有假设构成的集合,也就是假设空间中的一个最大子集,该子集内的每一个元素都不与训练集相冲突,因此版本空间也是唯一的。1另外值得注意的是,训练集的不同会导致版本空间的不同。
2、已知训练数据集求解版本空间2
- 列出所有可能的假设,即假设空间
- 不断删除与正例(已知训练数据集中的好瓜)不一致的假设,和与反例一致的假设
- 得到与训练集一致的假设,即版本空间
3、为什么要考虑归纳偏好?
版本空间内每一个假设都可以判断训练数据集中的每个瓜是好是坏,若用不同的假设判断同一条记录可能会得出不一样的结果,这便引出讨论归纳偏好的必要性。
4、训练集、验证集、测试集有何区别?
训练数据一般划分为训练集(training set)和验证集(validation set),训练集是用来训练模型或确定模型参数的,验证集是用来做模型选择,即做模型的最终优化及确定。
测试集(testing set):测试已训练好的模型在实际使用中的泛化能力。
在实际应用中,一般只将数据集分成训练集和测试集,并不涉及验证集。
未解决问题:为什么过拟合无法避免?P23
参考文章:

















 8682
8682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









