




 本文详细介绍了Hadoop分布式文件系统(HDFS)的读写操作流程,包括客户端如何与NameNode交互获取数据块信息,以及数据块的读取、验证、写入和文件完成过程。
本文详细介绍了Hadoop分布式文件系统(HDFS)的读写操作流程,包括客户端如何与NameNode交互获取数据块信息,以及数据块的读取、验证、写入和文件完成过程。
本文简介:HDFS读写数据流程
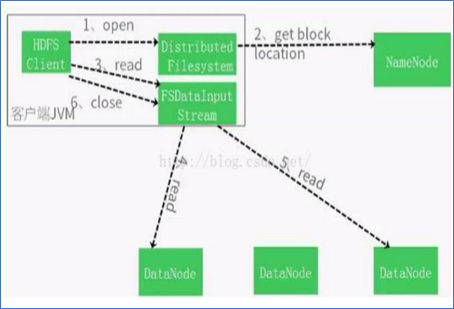
HDFS读数据流程
- HDFS客户端创建DistributedFileSystem对象,执行open()方法请求打开一个文件。
- DistributedFileSystem对象向名称节点请求得到文件开始位置的数据块(DataBlock)的位置信息,NameNode返回信息并按存储数据块的DataNode离client远近进行排序。
- DistributedFileSystem对象利用DFSInputSystem创建FSDataInputStream对象,客户端通过FSDataInputStream对象请求读取read()数据,找出首个文件数据块所在的DataNode节点并读取数据块。
- 首个数据块读取完成后,DFSInputStream关闭与该DataNode的连接,并重复调用read()函数,接着读取下一个数据块,直至全部文件块读完为止。
- 每读取完一个文件块都要进行Checksum验证,一旦从DataNode上读取数据出现了错误,客户端首先告知NameNode,并查找该数据块在集群数据节点上的其它位置信息以继续读取。
- 当前数据块被正确读取完毕后,关闭当前的DataNode节点链接并寻找下一个待读取的DataNode节点。如果文件读取还没有完成,DFSInputStream会继续从Namenode上读取下一批文件块的位置信息继续读取数据。
- 客户端将所需要的文件读取完毕后,将调用FSDataInputStream的close()方法关闭所有的数据流读取。
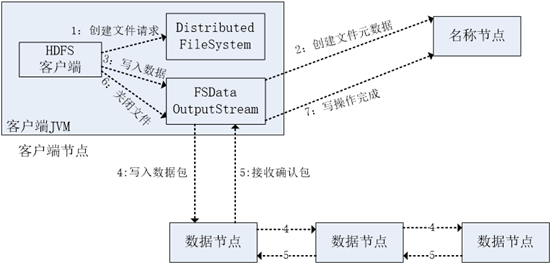
HDFS写数据流程
- 客户端通过调用DistributedFileSystem类中的create()方法创建文件请求,调用create()方法将创建一个文件输出流对象(FSDataOutputStream)。
- FSDataOutputStream对象向远程的名称节点(NameNode)发出RPC调用请求,NameNode节点检查该待写入文件是否存在及客户端的写入权限,检查通过之后,在NameNode上创建一个写入文件的元数据。
- 客户端通过调用FSDataOutputStream对象的write()方法请求写数据,所要写入的数据先载入到缓冲区中,然后切分成大小相等的数据块(DataBlock)。
- 每个数据块按照NameNode上的节点分配传输数据块到对应的数据节点(DataNode)上。
- 数据节点依次反向返回确认信息给第一个数据节点,并将所有的确认信息返回。client收到应答后,将删除队列中的ACK Packet,写入到下一数据节点中。
- 文件写入完成后,客户端将调用close()方法关闭FSDataOutputStream。
- 最后,客户端调用complete()方法通知NameNode文件写入成功。


















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









