




 本文详细介绍了InnoDB存储引擎中数据页的结构,包括页的概述、数据页的16KB存储布局、记录头信息和记录间的链接方式。重点讲解了如何管理用户记录和索引页的关系,以及虚拟记录Infimum和Supremum的作用。适合深入理解InnoDB索引机制。
本文详细介绍了InnoDB存储引擎中数据页的结构,包括页的概述、数据页的16KB存储布局、记录头信息和记录间的链接方式。重点讲解了如何管理用户记录和索引页的关系,以及虚拟记录Infimum和Supremum的作用。适合深入理解InnoDB索引机制。
InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构。而学习页结构,是为了更好的学习索引。
一、页的简介
页是 InnoDB 管理存储空间的基本单位,一个页的大小一般是 16kb。
为了达成不同的目的,作者设计了多种类型的页,比如:
- 存放表空间头部信息的页
- 存放 change buffer 信息的页
- 存放 inode 信息的页
- 存放 undo 日志信息的页
- ... ...
然而我们最关心的,还是那些存放进表中那些数据记录是在哪种页上,官方称这种存放记录的页为索引(INDEX)页,但是为了便于理解,本篇暂把它称为数据页。
二、数据页的结构
这数据页也有 16kb 的存储空间,可以大致划分为 7 个部分。
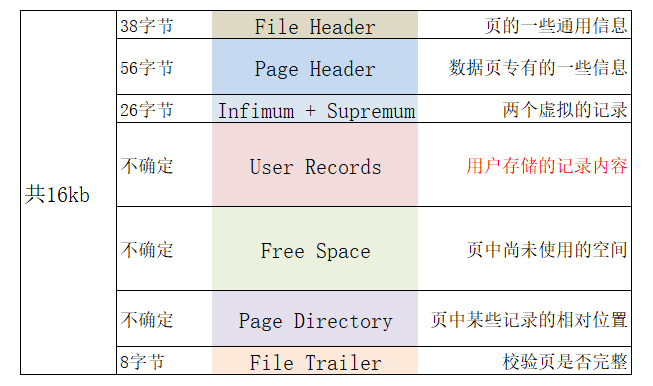
从结构图中可以看到,有些部分的占用字节数是确定的,有的是不确定的。我们最关心的用户存储的记录,在 User Records部分。
不过,在一开始生成页的时候,并没有 User Records 部分。当有新的记录插入时,就会从 Free Space部分申请一个记录大小的空间,然后划分到 User Records 部分,直到 Free Space 全部被 User Records 替代,表示这个页已经用完。如果还有新的记录插入,需要申请新的页。
我觉得这里可以把这个数据页当作是书本的页,书页上的内容通常是一行行的呈现,当整个页都用完了,就得翻到下一页(新页)去继续写了。
三、记录在页中的存储结构
那么,User Records 部分里的这些记录,是如何管理的呢?
先来建一张表:
CREATE TABLE pingguo_demo(
c1 INT,
c2 INT,
c3 VARCHAR(10000),
PRIMARY KEY (c1)
) CHARSET = ASCII ROW_FORMAT = COMPACT;这里的指定使用行格式为 COMPACT(引擎中还存在其他的行格式),暂且知道 COMPACT 即可。
当我们在数据库的插入了一条记录后,其实背后的行格式是这样的:

注意这里橙色标识的记录头信息,它又包含了很多重要信息:

- 预留位1:占用 1 比特,没有使用。
- 预留位2:占用 1 比特,没有使用。
- deleted_flag:占用 1 比特,标记该记录是否被删除。
- min_rec_flag:占用 1 比特,在 B+ 树(后面索引会讲到)中每层非 叶子节点中的最小的目录项,都会添加此标记。
- n_owned:一个页面中的记录被分为若干个组,每个组里有一个记录是“大哥”,其他记录都是“小弟”。而这位“大哥”记录的 n_owned 就是所在组的所有记录条数,而小弟们的 n_owned 都是 0
- heap_no:占用 13 比特,表示当前记录在页面堆中的相对位置。
- record_type:占用 3 比特,表示当前记录的类型,0是普通记录,1是 B+树非叶节点的目录项记录,2是 Infimum 记录,3是 Suprememum 记录。
- next_record:占用 16 比特,表示下一条记录的相对位置。
四、记录头信息
现在,向上面新建的表中插入 4 条记录:
INSERT INTO pingguo_demo VALUES
(1, 100, 'aaaa'),
(2, 200, 'bbbb'),
(3, 300, 'cccc'),
(4, 400, 'dddd');那么,对应这4条记录的行格式应该为: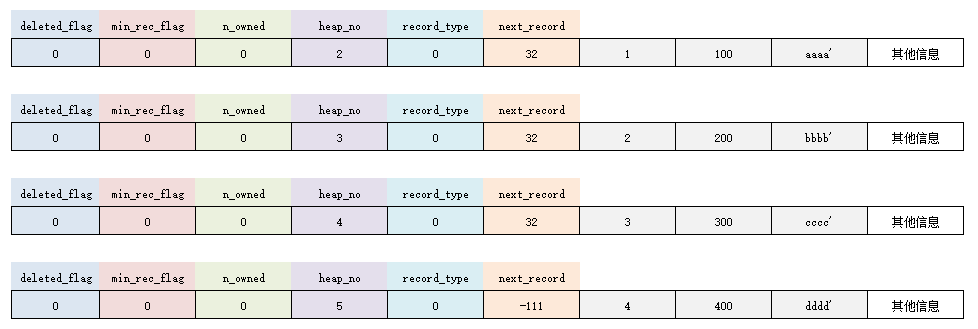
注意,这里为了便于记忆,作了简化。另外,记录中的信息实际是二进制位数据,这里为了理解写的是十进制。而且,各条记录在 User Records 中存储是没有空隙的,这里抽象表示。
1. deleted_flag
这个属性用来标记当前记录是否被删除,1 表示被删除,0 表示没有被删除。
嗯?我表里删除了数据居然还在页里。
是的,你以为被删除了,其实还在磁盘上。为什么呢?
因为如果在磁盘上移除这些记录,还要再重新排列其他记录,会带来性能消耗,所以只打了一个删除的标记。
然后,所有的删除的记录会组成一个垃圾链表。而记录在这个链表中所占用的空间称为可重用空间,当后面有新记录插入到表中,它们就可能覆盖掉这些空间。
2. min_rec_flag
在 B+ 树中每层非叶子节点中的最小的目录项,都会添加此标记。这里说的目录项,要后续讲解。
这里4条记录的 min_rec_flag 都是 0,表示都不是 B+ 树非叶子节点中的最小的目录项记录。
3. n_owned
要下一章讲解。
4. heap_no
表示当前记录在页面堆中的相对位置。
上面的4条记录是抽象的描述,实际上这些记录都是一条一条紧密无缝排列在一起的,这就是堆(heap)。
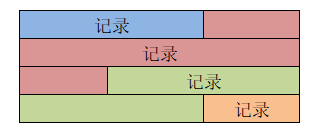
为了方便管理,把一条记录在堆中的相对位置称为 heap_no。
- 在页面前面的记录 heap_no 相对较小
- 在页面后面的记录 heap_no 相对较大
- 每申请一条记录的存储空间时,该记录比物理位置在它之前的那条记录的 heap_no 值大 1
上述 4 条记录的 heap_no 分别为 2、3、4、5,嗯?怎么没有 0 和 1?
虚拟记录-Infimum 和 Supremum
这个在本文第二部分有提到过。其实这2条记录是页里自动添加的:
- Infimum:代表页面中的最小记录
- Supremum:代表页面中的最大记录
作者规定,无论向页中插入了多少条记录,任何用户记录都比 Infimum 记录大,都比 Supremum 记录小。
这 2 条虚拟记录的结构也很简单。

所以,对于上面插入的 4 条用户记录,还应该加上这2个默认记录,而且位置最靠前。
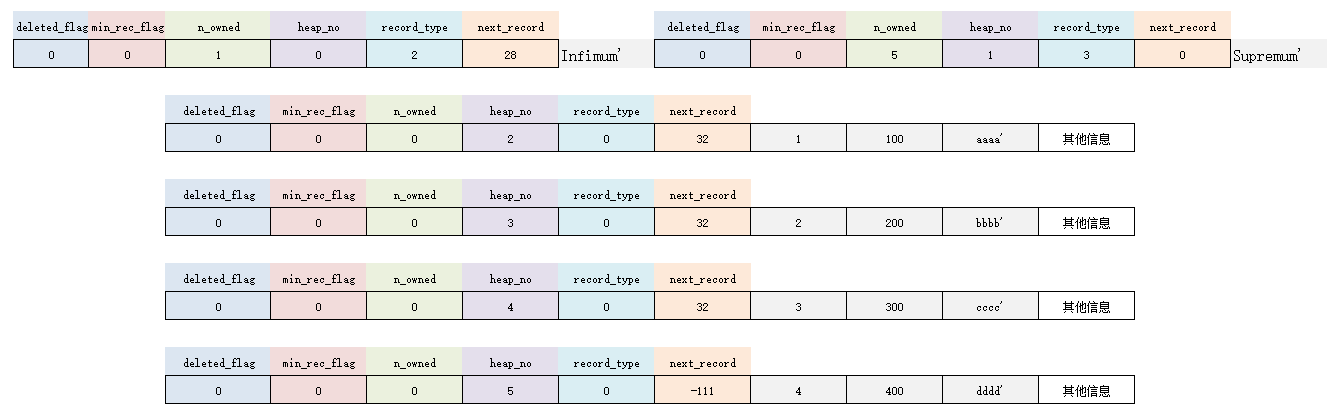
另外,还需要注意,当堆中记录的 heap_no 值分配后,就不会发生改动。即使删除了堆中的某条记录,这条被删记录的 heap_no 值也仍然不变。
5. record_type
这个属性表示当前记录的类型,共 4 种:
- 0:表示普通记录
- 1:表示 B+ 树非叶节点的目录项记录
- 2:表示 Infimum 记录
- 3:表示 Supremum 记录
6. next_record
这个属性很重要,表示从当前记录的真实数据到下一条记录的真实数据之间的距离。
- 属性值为正数:说明当前记录的下一条记录在当前记录的后面。
- 属性值为负数:说明当前记录的下一条记录在当前记录的前面。
比如,第 1 条记录的 next_record 值为 32,那么从此记录的真实数据地址向后找 32 字节就是下一条记录的真实数据。再比如,当值为 -111,那么就代表从此记录向前找 111 字节。
很熟悉?没错,就是链表。
- 下一条记录,是指按照主键从小到大排列的下一条。
- Infrimum 记录的下一条记录,就是本页中主键值最小的用户记录。
- 本页主键值最大的用户记录的下一条记录,就是 Supremum 记录。
所以,现在再来重新看下记录之间的示意图,可以用单向链表来描述了:
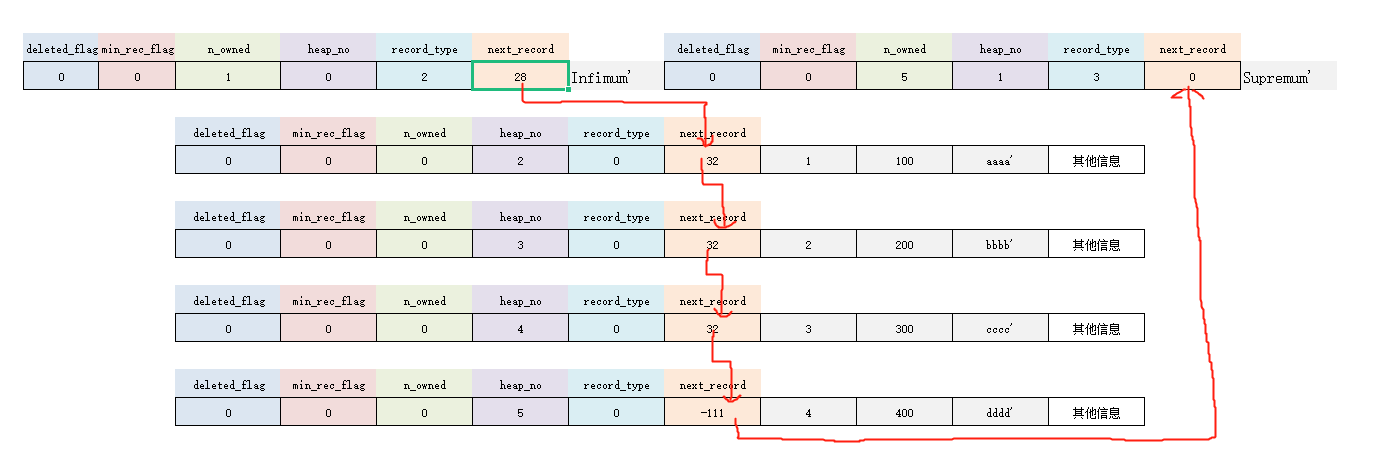
如果这时候,删掉其中的某条记录,改变的是指针。
本文参考书籍: 小孩子4919 《mysql是怎样运行的》

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









