







 本文详细对比了Java中的Stream流与Hadoop的MapReduce计算框架,指出两者在处理大量数据时的相似之处。Java Stream提供了一种在集合之上更高层次的数据处理方式,允许指定计算任务而不关注实现细节,而MapReduce则通过map和reduce阶段进行分布式计算。文章还深入介绍了Stream的中间操作(如filter、map、reduce)和终结操作(如collect、reduce),以及如何将数据转换成Stream并进行各种操作。此外,讨论了Stream的惰性执行特性以及与Hadoop MapReduce的计算流程的类比。
本文详细对比了Java中的Stream流与Hadoop的MapReduce计算框架,指出两者在处理大量数据时的相似之处。Java Stream提供了一种在集合之上更高层次的数据处理方式,允许指定计算任务而不关注实现细节,而MapReduce则通过map和reduce阶段进行分布式计算。文章还深入介绍了Stream的中间操作(如filter、map、reduce)和终结操作(如collect、reduce),以及如何将数据转换成Stream并进行各种操作。此外,讨论了Stream的惰性执行特性以及与Hadoop MapReduce的计算流程的类比。
Java中的Stream流 与 Hadoop中的MapReduce
Stream,流,个人感觉是Java提供的针对大量数据计算的API。Stream接口中的reduce、Collectors接口中的groupingBy、reducing、maxBy、minBy等其它许多计算方法,从思想上看,和Hadoop的计算引擎MapReduce很相似。
这里插入一下MapReduce中的计算阶段,总的来说是先执行用户自定义的map任务,再执行用户自定义的reduce任务:
- readData:MapReduce框架从用户指定的文件user_input_file中读取要处理的数据
- map(映射):一系列的key/value经过用户自定义的map任务处理,映射成另外的一系列key/value)
- collect(集中,收集):MapReduce框架对map任务处理后的key/value做分区,并写入各个分区各自的的环形缓冲区
- spill(溢出,水满则溢):环形缓冲区的写入量到达一定比例后就写一次磁盘临时文件user_output_file/spillN.out.index,写入前会先做一个局部本地的排序及合并压缩。所谓本地排序,是说只是在本机器上的key/value范围内做排序、合并压缩,而非对所有机器上的数据做分区、和key的排序
- combine(结合、联合、合并):将本地所有map任务产出的临时文件spillx文件合并,确保在本地执行的所有map任务的结果合并成一个本地数据文件(仅在本机器上的合并),这个文件中可能包括不同分区的数据。因此要将分区号和文件的索引关系写到map任务的内存中,以便reduce阶段在shuffle时获取其所需要的分区数据。
- shuffle(改组、洗牌):由于map任务的结果中,同一个分区的数据,分散存储在不同的机器上。而我们的计算却是要对一个分区内的所有数据做一些汇总之类的。因此shuffle阶段的任务是,从不同的机器上获取某分区的数据,下载执行此分区数据计算任务的reduce任务所在的机器上,并对所有此分区所有进行排序、合并,合并成一个文件。结果就是,同一分区的所有数据都在一个文件中,一个文件内的所有数据都是同一分区的。这一阶段称为shuffle,就像整理一副扑克牌一样,按照花色重组。
- reduce(简化;归纳;减少;缩小):将shuffle后的数据,经过用户自定义的reduce任务处理…
Stream-流
流提供了一种在比集合更高的概念级别上指定计算的数据视图。——流提供的是数据视图,这种数据视图可以让我们在在比集合更高的概念级别上指定计算。
我们可以指定要完成什么任务,而不用给出具体实现。例如:假如我们想计算某个属性的平均值,我们可以指定数据源和该属性,但我们不用写代码来对一系列属性的值做加总、再求均值、也不用写Runnable开启多个线程来提高效率,以上这些计算代码都由流库去实现并优化。
也就是说流库让开发者以“做什么而非怎么做”的方式处理集合。比如上例中,做什么:求平均值,怎么做:如何实现求平均值。
java.util.stream-流计算的类图
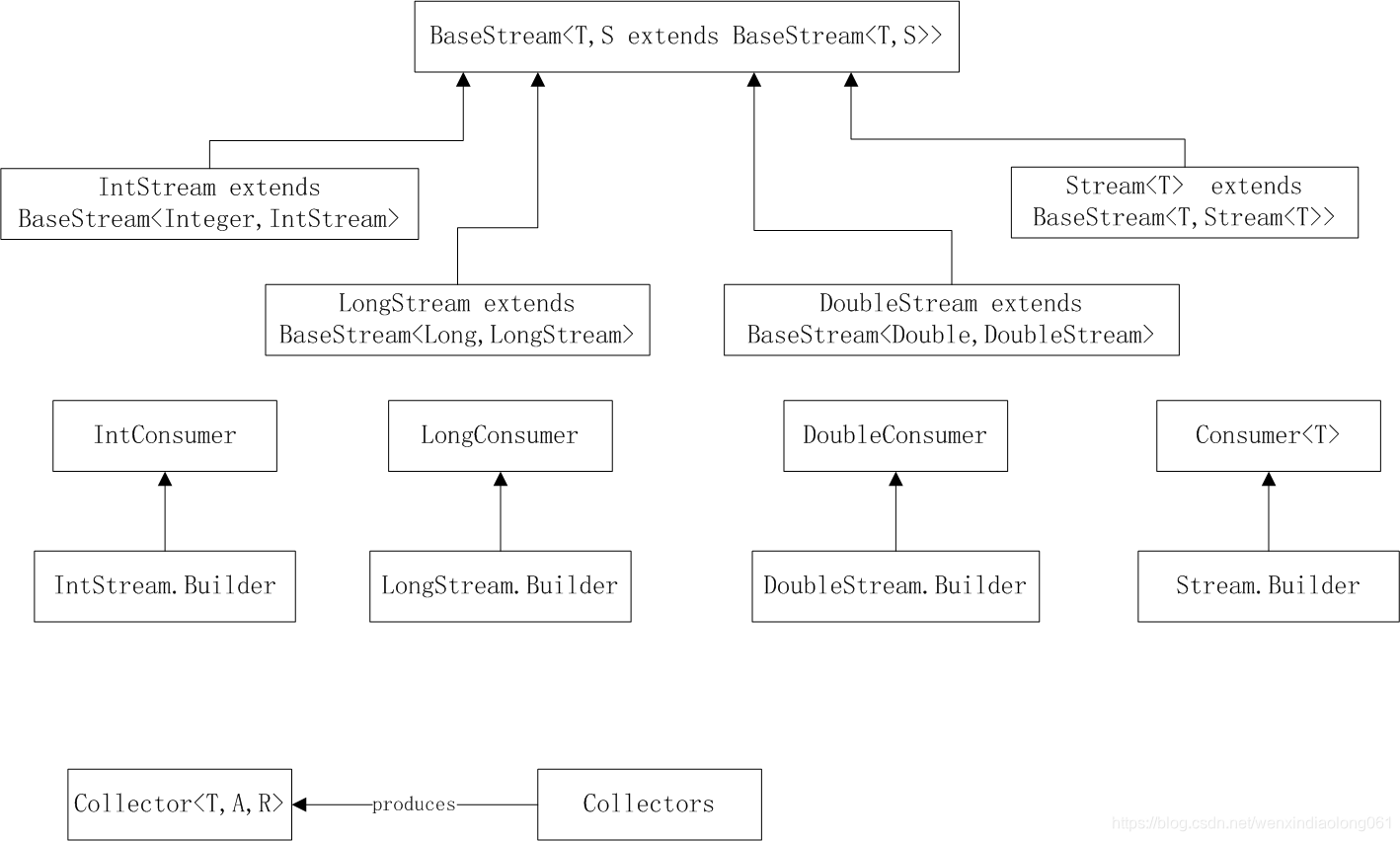
BaseStream<T,S extends BaseStream<T,S>>
| void close() | S parallel() | S sequencial() | S unordered() |
| S onClose(Runnable closeHandler) | boolean isParallel() | Iterator iterator() | Spliterator spliterator() |
IntStream \ LongStream \ DoubleStream
以上三个接口,是为了减少对基本数据类型的封装和拆装而专门定义的。
其常用的不同于泛型接口Stream接口方法有以下几个:
| IntStream range(int from,int to ) | IntStream rangeClosed(int from,int to ) | IntSummaryStatistics summaryStatistics() |
| int sum() | int min() | int max() |
Stream
生成Stream的API
| static Stream<T> of(T … values) | static Stream<T> of(T collection) | static Stream<T> empty() |
| static Stream<T> iterate(T seed,UnaryOperator<T> f) | static Stream<T> generate(Supplier<T> s) |
- empty()方法是生成一个串行化的元素个数为0的Stream,
- iterate(T seed ,UnaryOperator f)是迭代地将函数f作用于seed生成x1,然后将f作用于x1生成x2,然后将f作用于x2生成x3…,例如Stream.iterate(0,x->x+1),会生成[0,1,2,3,4…];一般要与limit(n)合用,否则就会生成无限个元素。
- generate(Supplier s):重复执行函数s,然后取每次执行后的返回值add到Stream中去。一般要与limit(n)合用。示例:
Stream.generate(()->{return new Random().nextInt(10000);});会生成小于10000的随机数;
Stream.generate(Math::random),随机生成一些Double;
Stream.generate(HashMap<String,Integer>::new);可以生成许多HashMap的示例。 - of(T … values),将一个数组对象转换生成一个Stream实例对象。
- of(T collection),将一个Collection实例对象转换成一个Stream对象。
过滤、去重、排序、转换
这些都是对Stream流中的数据的中间操作,数据经过这些操作的处理后,生成一个新的流。
| Stream<T> distinct() | Stream<T> limit(long size) | Stream<T> skip(long n) |
| Stream<T> filter(Predicate<? super T> p) | Stream<T> peek(Consumer<? super T>) | static Stream<T> concat(Stream<T> a,Stream<T> b) |
| Stream<T> sorted() | Stream<T> sorted(Comparator<? super T> c) | |
| <R> Stream<R> map(Function<T,R> mapper) | flatMap() |
- <R> Stream map(Function<T,R> mapper):将函数mapper作用于原stream中的每个元素,用函数的返回值替代原stream中的原值。Stream中的每一个元素,经过函数mapper的映射,都变成了一个新的有可能类型不同的元素。
- Instream mapToInt(…) / LongStream mapToLong(…) / DoubleStream mapToDouble(…) :同上,只不过返回值比较典型
- <R> Stream<R> flatMap(Function<T,? extends Stream<R>> mapper):flat(平的),推平。参数mapper本身的返回值是一个Stream<R>对象,也就是说,对于原来的每一个T类型元素,都会被函数mapper映射成成一个Stream<R>对象,这样就生成了一系列的Stream<R>对象,但是flatMap则会将这些Stream<R>对象全都进行concat(),将所有Stream<R>对象中的所有R类型的对象全都拼接到一个Stream<R>中去。
- Instream flatMapToInt(…) / LongStream flatMapToLong(…) / DoubleStream flatMapToDouble(…) :同上,只不过返回值比较典型
- Stream<T> concat(Stream<T> a,Stream<T> b):将a和b中的元素合在一起组成一个新的Stream<T>
- Stream<T> filter(Predicate<? super T> predicate):根据条件predicate过滤
- Stream<T> limit(long size):只需要前size个
- Stream<T> skip(long n):跳过前n个
- Stream<T> peek(Consumer<? super T> c)
- Stream<T> sorted():将元素排序
- Stream sorted(Comparator<? super T> c):使用给定的比较器,将元素排序
终结操作——收集
将流中的数据,处理、收集、存储到一个容器中去。
经过终结操作后,流中元素被消费掉了,对流中数据的操作的管道链到终点了。
| Object [] toArray() | <A> A[] toArray(IntFunction<A[]> generate) |
| Optional<T> max(Comparator<? super T> c) | Optinal<T> min(Comparator<? super T> c) |
| long count() | boolean noneMatch(Predicate<? super T> p) |
| boolean anyMatch(Predicate<? super T> p) | boolean allMatch(Predicate<? super T> p) |
| Optional<T> findAny() | Optional<T> findFirst() |
| void forEach(Consumer<? super T> c) | void forEachOrdered(Consumer<? super T> c) |
| collect() | reduce() |
Object[] toArray():将流中的元素收集到数组中
A[] toArray(A[]::new):收集到新构建的一个数组(new A[])中
<R,A> R collect(Collector<? super T,A,R> collector):
惰性操作
stream的所有中间操作都是惰性的,直到遇到终结操作,才会执行之前的所有操作。因此,如果进行终结操作之前,对stream的源数据做了增删改,那么都会影响终结操作的结果。
String file = new String(Files.readAllBytes(Paths.get("./out.txt")),"utf-8");
// 小写\p是property的意思,表示Unicode属性,用于Unicode正表达式的前缀。而大写字母P则表示Unicode字符集七个字符属性之一:标点字符(punctuation,逗号,句号等标点)。
// 其它六个属性:L:(letter)字母;M:(mark)标记符号,一般不会单独出现; Z:分隔符,空格、换行等, S:符号,数学符号、货币符号。N:(number)数字,阿拉伯数字,C:其它字符
// 因此,在如下的语句中的正则表达式“\\PL+”中,由于在Java的字符串中字符‘\’本身有特殊含义,必须用“\\”来表示,因此"\\P"就是表示\p,而后跟'L',意思就是Unicode字符集中的字母,再加一个'+',就表示获取一个单词。
String [] words = file.split("\\PL+");
List<String> wordsList= new ArrayList(Arrays.asList(words));
// stream的所有操作都是惰性的,直到遇到终结操作,才会执行之前的所有操作。因此,如果进行终结操作之前,对stream的源数据做了增删改,那么都会影响终结操作的结果。
wordsList.forEach(out::println);
wordsList.add("END1");
wordsList.forEach(out::println);
Stream<String> stream = wordsList.stream();
wordsList.add("END");
stream.forEach(out::println);
数组、集合如何转成Stream流
Collection接口提供的方法
Collection接口提供了以下将一个Collection实例对象转换成一个Stream流对象的方法:
default Stream<E> stream();
default Stream<E> parallelStream();
Collection接口中的stream()方法,可以从Collection实例中获取成一个Stream流实例。因此对于任何Collection的子类,都可以直接调用stream()方法,来获取Stream实例。
HashSet<String> set = new HashSet();
set.add("rrra");
set.add("rrdf");
set.add("rrbe");
set.add("rrjjh");
out.println(set.stream().count());
数组转成Stream流对象
工具类java.util.Arrays中,提供了以下方法,将一个数组对象转换成一个Stream流对象:
static IntStream stream(int [] a);
static IntStream stream(int [] a, int startIdx, int endIdx);
// LongStream \ DoubleStream 同上
static <T> Stream<T> stream(T [] a);
static <T> Stream<T> stream(T [] a, int startIdx, int endIdx);
StreamSupport
底层工具类,提供给底层库开发者使用的。Collection接口的stream()方法就是调用这个工具类,来生成相应的BaseStream流。
StreamSupport类提供了许多工具方法,将Spliterator的实例生成一个BaseStream的实例。
而Iterable接口中的spliterator()方法就是提供一个Spliterator实例。因此,所有Iterable接口的实现类都可以被转换成流,如:Collection接口的所有子类。
Stream接口的 collect方法 与 接口Collector 、工具类 Collectors
java.util.stream.Stream<T,S extends Stream<T,S>>::collect
Stream接口中定义了两个名为collect的重载方法:
R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BinaryOperator<R> combiner)
<A,R> R collect(Collector<? super T, A, R> collector)
collect方法是Stream类提供的的一个终结操作,功能是将流中的数据转换、收集、存储到集合或者其他类型的变量中去。
第一个collect方法中的三个参数,分别有如下功用:
- Supplier supplier,第一个参数是函数式接口Supplier的实例,这个接口的API方法
R get()是返回一个R类的对象实例,也就是生产一个对象。collect方法会利用这个参数生成一个R类的对象实例,这个对象将用于存储流操作的结果集,一般为集合。即这个参数最终用于存储流操作的结果集。例如:ArrayList::new - BiConsumer<R,? super T> accumulator,第二个参数是函数式接口BiConsumer的实例,根据泛型的定义<R, ? super T>,其中R为返回值类型、T为流中元素的类型,可以理解为是对流中的元素做操作后,添加到R中去。例如:
ArrayList::add - BinaryOperator<R> combiner,第三个参数是函数式接口BinaryOperator的实例,这个接口相当于一个二元运算符,其接口方法
R apply(R a, R b)的功能是对两个相同类型的数据进行运算,返回一个想同类型的返回值。根据其泛型的定义<R>\和方法的名字combiner,可以理解为对并发执行的多个结果集进行合并。
举例,以下例子将一个整数列表中的数据,经过过滤后,存储到另一个整数列表中去:
import static java.lang.System.out;
import java.util.function.*;
import java.util.stream.*;
import java.util.*;
import java.nio.file.*;
import java.util.logging.*;
public class Test{
public static void main(String[] args){
Supplier<List<Integer>> supplier = ArrayList<Integer>::new; // 创建ArrayList的实例,用于存储Stream流的结果集
BiConsumer<List<Integer>,Integer> accumulator=(list,i)->{if(i<5) list.add(i);}; // 将Stream流中的元素添加到ArrayList中
BiConsumer<List<Integer>,List<Integer>> combiner = (part1,part2)->{ // 合并并行执行的ArrayList切片,
part1.addAll(part2);
};
Integer [] ints = {1,2,3,4,5,6,7};
List<Integer> sourcelist = new ArrayList<>(Arrays.asList(ints));
List<Integer> result = sourcelist.stream().collect(supplier,accumulator,combiner);
out.println(result); // 输出 [1, 2, 3, 4]
}
}
第二个collect方法,参数Collector其实就是对第一个collect方法中的参数的封装,之所以要专门设计一个类来对参数进行封装,是因为有一些非常常用的成套的collect方法的参数,可以直接提供给开发者用。于是就将每套参数封装成一个Collector的对象,作为参数直接传递给collect方法。
Collector<T,A,R>接口
此接口是专门用于生成Stream类的collect方法的参数的,它有三个类型参数:
- T:要处理的流的元素的类型
- A:中间结果类型
- R:collect方法的最终返回之的类型
| 返回值类型 | API方法名 |
|---|---|
| Supplier<A> | supplier(); |
| BiConsumer<A, T> | accumulator(); |
| BinaryOperator<A> | combiner(); |
| Function<A,R> | finisher(); |
| Set<Characteristics> | characteristics() |
| static <T,A,R> Collector<T,A,R> | of(Supplier<A> s, BiConsumer<A, T> c , BinaryOperator<A> combiner, Function<A,R> finisher, Characteristics… crctrstics)) |
| static <T,R,R> Collector<T,R,R> | of(Supplier<R> s,BiConsumer<R,T> c, BinaryOperator<R> combiner, Characteristics… crctrstics) |
Collector接口:专门用来封装collect方法中用到的转换、存储操作的生成器的。它定义了以下API方法:
- Supplier<R> supplier();supplier方法会返回函数式接口Supplier<R>的一个实例对象,Supplier<R>接口是一个供给接口,其接口方法
R get(),不需要入参(不消费)、返回一个R类型的对象(只生产),功能是供给给调用方一个R类型的实例对象。Stream类的collect方法的第一个参数的类型就是一个Supplier<R>类型的对象supplier,collect方法内会调用supplier的get()方法,就得到一个R类型的实例对象。假如接口Supplier的一个实例为:ArrayList::new,则我们最终就可以获得一个ArrayList实例。collect方法内,使用supplier对象,最终会生成一个用来存储从stream流中收集到的数据的容器。而Collector接口的这个supplier()方法,就是专门为collect方法生成其第一个参数对象的。 - BiConsumer<A,T> accumulator();这个方法会返回函数式接口BiConsumer<A,T>的一个实例,BiConsumer<A,T>接口是一个二元消费接口,接口方法
accept(A a,T t)需要两个入参(只消费)、但无返回值(不生产),而二元则指有两个参数,因此称之为二元消费接口。Stream流的collect方法的第二个参数就是一个BiConsumer<A,T>接口的的实例对象consumer,collect方法内会调用consumer.accept(A a,T t)方法,消费Stream流对象中的元素,一般是执行将流中的元素添加到用于存储结果集的集合中(即collectorsupplier)去,如:List::add。而Collector接口的这个 accumulator()方法,就是用于生成collect方法的第二个参数对象的。 - BinaryOperator<T> combiner();这个方法会返回函数式接口BinaryOperator<T>的一个实例,这个接口顾名思义相当于一个二元(Binary)运算符(Operator),运算符肯定要求参与运算的数据的类型相同,而且肯定有运算结果,并且运算结果的数据类型也与参与运算的数据类型相同。因此collect方法会调用这个接口的实例的apply(T t1, T t2)方法,对流中的元素做两两运算,比如两两比较、最终获得最大值,或者两两相加、最终获得sum值。如:
(left,right)->{ left.addAll(right); return left; } - Function<A,R> finisher();这个方法的返回值是一个函数式接口Function<A,R>的实例,Function顾名思义就是一个典型方法,有入参A、有返回值R。
- Set<Collector.Characteristics> characteristics();这个方法的返回值是枚举类Collector.Characteristics的所有枚举值排列组合中的一个组合。这个枚举类共有三个枚举值:CONCURRENT, IDENTITY_FINISH, UNORDERED,每个枚举值的含义…
- of(…);两个of方法都是工厂方法,直接生成Collector接口的实例。
Collectors
前边提到,有许多常用的成套的collect方法的参数,因而设计了Collector接口来封装,同时JDK也设计了Collectors类来将这些成套的参数直接通过方法调用来提供给开发者。
处理流元素类型为CharSequence(String\Stringbuffer\StringBuilder)的收集器:
| static Collector<CharSequence,?,String> joining() | 针对元素类型为CharSequence的Stream,将所有元素连接成一个字符串,用,分隔 |
| static Collector<CharSequence,?,String> joining(CharSequence delimiter) | 针对元素类型为CharSequence的Stream,将所有元素连接成一个字符串,用给定的参数delimiter分隔 |
| static Collector<CharSequence,?,String> joining(CharSequence delimiter,Charsequence prefix,Charsequence suffix) | 针对元素类型为CharSequence的Stream,对每个元素加上前缀prefix,后缀suffix,然后将所有元素连接成一个字符串,用delimiter分隔 |
| static <T> Collector<T,?,List<T>> toList() | 同上,构造出一个collector,collect方法执行此collector中封装的函数式接口后,能将元素收集到一个Set中并返回 |
| static <T> Collector<T,?,Set<T>> toSet() | 同上,构造出一个collector,collect方法执行collector中封装的函数式接口后,能将元素收集到一个Set中并返回 |
| static <T> Collector<T,?,Set<T>> toCollection(Supplier<R>) | 同上,构造出一个collector,能将元素收集到一个Collection中去,不过需要用户指定一个Collection的实现类的生成器 |
| static <T,K,U> Collector<T,?,Map<K,U>> toMap(Function<? supert T,? extends K> keyMapper,Function<? super T,? extends U> valueMapper,BinaryOperator<U> mergeRepeatKey,Supplier<? extnds Map> mapSupplier) | 同上,构造出一个collector,collect方法执行collector中封装的函数式接口后,能将元素收集到一个Map中并返回。keyMapper是一个函数、作用于流元素、生成Map的key;valueMapper是一个函数、作用于流元素、生成Map的value;mergeRepeatKey是一个二元操作符,处理出现重复key的情况,作用于两个value,生成要保留的value;mapSupplier是一个生成器,生成Map的一个子类的实例,如TreeSet::new |
| static <T> Collector<T,?,List<T>> toList() | 同上,构造出一个collector,collect方法执行此collector中封装的函数式接口后,能将元素收集到一个Set中并返回 |
| static <T> Collector<T,?,Set<T>> toSet() | 同上,构造出一个collector,collect方法执行collector中封装的函数式接口后,能将元素收集到一个Set中并返回 |
| static <T> Collector<T,?,Set<T>> toCollection(Supplier<R>) | 同上,构造出一个collector,能将元素收集到一个Collection中去,不过需要用户指定一个Collection的实现类的生成器 |
| static <T,K,U> Collector<T,?,Map<K,U>> toMap() | 同上,构造出一个collector,collect方法执行collector中封装的函数式接口后,能将元素收集到一个Map中并返回 |
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new,
List::add,
(left, right) -> {
left.addAll(right);
return left;
},
CH_ID);
}

















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









