




 为提升消息收发性能,Netty对ByteBuf采用池化技术,减少gc次数。本文介绍了Netty内存池的数据结构,如PoolArena、PoolChunk、PoolSubpage等,还阐述了内存分配策略,包括tiny、small、normal、huge内存的分配情况,最后提及可通过jemalloc和源码调试深入学习。
为提升消息收发性能,Netty对ByteBuf采用池化技术,减少gc次数。本文介绍了Netty内存池的数据结构,如PoolArena、PoolChunk、PoolSubpage等,还阐述了内存分配策略,包括tiny、small、normal、huge内存的分配情况,最后提及可通过jemalloc和源码调试深入学习。
为了提升消息接收和发送性能,Netty针对ByteBuf的申请和释放采用了池化技术,通过PooledByteBufAllocator 可以创建基于内存池分配的ByteBuf对象,这样就避免了每次消息读写都申请和释放ByteBuf,这样很大程度减少了gc的次数,对性能提升是非常可观的,下面就具体介绍下Netty内存池的分配原理以及内存管理的数据结构。
Netty的内存池整体上参照jemalloc实现,首先先介绍下Netty内存池的数据结构:
- PoolArena:代表内存中一大块连续的区域,PoolArena由PoolChunkList组成的双向链表组成,每个PoolChunkList由多个PoolChunk组成,每个PoolChunk由PoolSubpage数组组成,Netty为了提升性能,内存池中包含一组PoolArena。
- PoolChunk:用来组织和管理和组织多个PoolSubpage的内存分配和释放,默认16M.
- PoolSubpage:对于小于一个Page的内存,Netty在Page中完成分配,每个page会被切分成大小相等的多个存储块,存储快的大小由第一次申请内存块大小决定.。假如一个Page 是8字节,如果第一次申请块的大小是4字节,那么这个Page就包括两个存储块;如果第一次申请的块大小是8个字节,那么这个Page就被分成一个存储块。一个Page只能用于分配与第一次申请时大小相同的内存。
内存池的内存分配从PoolArena开始,一个PoolArena包含多个PoolChunkList,PoolChunk具体负责内存的分配和回收。每一个PoolChunk包含多个Page(PoolSubpage),每个Page由大小相等块组成,每个Page块大小由第一次从Page申请的内存大小决定,某个Page中的块大小是相等的。PoolChunk默认为16MB,包含2048个Page,每个Page8kB。
//pageSize默认值为8192 maxOrder默认值为11
chunkSize = validateAndCalculateChunkSize(pageSize, maxOrder);
//chunkSize =16777216B=16384KB=16MB
private static int validateAndCalculateChunkSize(int pageSize, int maxOrder) {
if (maxOrder > 14) {
throw new IllegalArgumentException("maxOrder: " + maxOrder + " (expected: 0-14)");
}
// Ensure the resulting chunkSize does not overflow.
int chunkSize = pageSize;
for (int i = maxOrder; i > 0; i --) {
if (chunkSize > MAX_CHUNK_SIZE / 2) {
throw new IllegalArgumentException(String.format(
"pageSize (%d) << maxOrder (%d) must not exceed %d", pageSize, maxOrder, MAX_CHUNK_SIZE));
}
chunkSize <<= 1;
}
return chunkSize;
}内存分配策略:通过PooledByteBufAllocator申请内存时首先从PoolThreadLocalCache中获取与线程绑定的缓存池PoolThreadCache,如果不存在线程私有缓存池,则轮询分配一个Arena数组中PoolArena,创建一个新的PoolThreadLocalCache作为缓存池使用,如下代码:
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}PoolArena在进行内存分配时对预分配的内存容量做判断,分为如下几种场景:
- 需要分配的内存小与PageSize时,分配tiny(小于512B)或者small(大于等于512B小于8KB)内存。
- 需要分配的内存介于PageSize和ChunkSize之间时,则分配normal(大于等于8KB小于等于16MB)内存。
- 需要分配的内存大于Chunk时,则分配huge(大于16MB)内存(非池化内存)
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
}
incTinySmallAllocation(tiny);
return;
}
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}在PoolArena中创建PoolChunk后,调用PoolChunk的allocate()方法进行真正的内存分配:PoolChunk通过二叉树记录每个PoolSubpage的分配情况,实现代码如下:
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
return allocateRun(normCapacity);
} else {
return allocateSubpage(normCapacity);
}
}
/**
* Create/ initialize a new PoolSubpage of normCapacity
* Any PoolSubpage created/ initialized here is added to subpage pool in the PoolArena that owns this PoolChunk
*
* @param normCapacity normalized capacity
* @return index in memoryMap
*/
private long allocateSubpage(int normCapacity) {
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
synchronized (head) {
int d = maxOrder; // 子页面只能从页面分配,即叶子
int id = allocateNode(d);
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
return subpage.allocate();
}
}具体的PoolChunk结构如下图所示
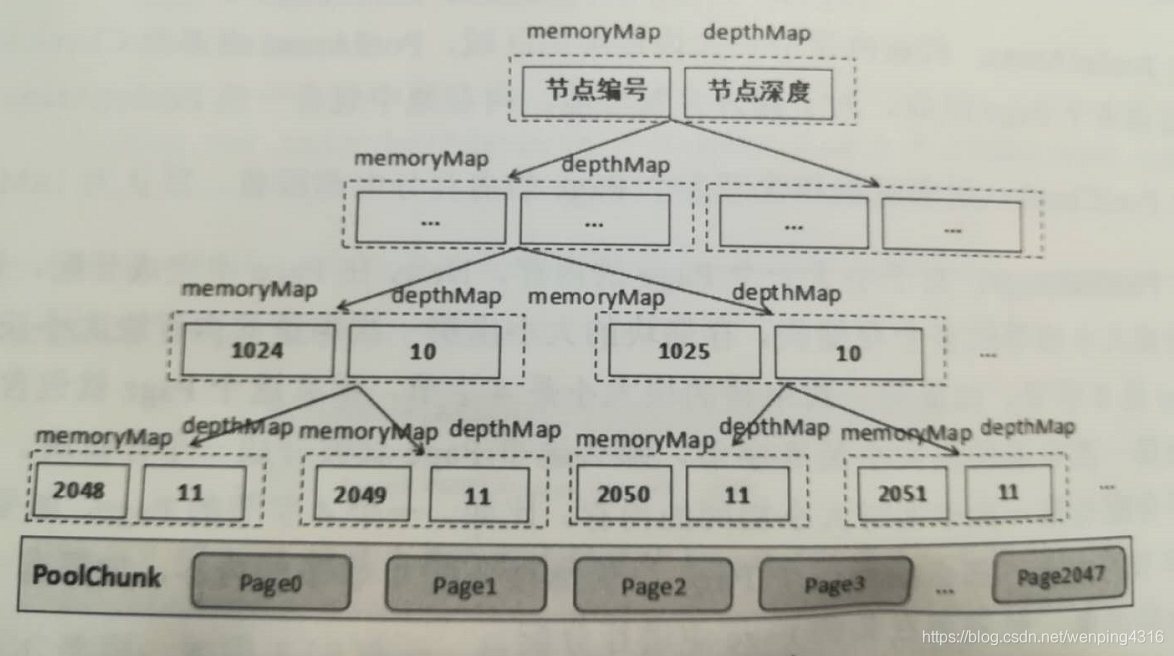
PoolChunk用memoryMap和depthMap来表示二叉树,其实memoryMap存放的是PoolSubpage的分配信息,depthMap存放的是二叉树的深度。depthMap初始化之后就不再变化,而memoryMap则随着PoolSubpage的分配而改变。初始化时,memoryMap和depthMap的取值相同。节点的分配情况有如下三种可能。
- memoryMap[id] = depthMap[id]:表示当前节点可分配内存。
- memoryMap[id] > depthMap[id]:表示当前节点已经被分配,无法分配满足该深度的内存,但是可以分配更小一些的内存
- memoryMap[id] = 最大深度(默认11)+1:表示当前节点下所有的子节点都已经分配完,没有可用内存。
Netty内存池的实现细节还是非常复杂的,限于篇幅只总结了Netty内存池实现的重点,如果还想深入去了解的话,可以通过jemalloc原理学习+Netty源码调试的方式,更深入地学习和掌握Netty内存池。

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









