






mian
# -*- coding: utf-8 -*-
import scrapy
from qingchun_p.items import QingchunPItem
from urllib.parse import urljoin
from copy import deepcopy
class QcSpider(scrapy.Spider):
name = 'qc'
allowed_domains = ['www.vdfly.com']
start_urls = ['http://www.vdfly.com/star/bg/']
def parse(self, response):
ul_list = response.xpath("//div[@class='newsList']/ul/li")
for lione in ul_list:
item = QingchunPItem()
item["url"] = lione.xpath("./a/@href").extract_first()
yield scrapy.Request(url=item["url"], callback=self.detial_parse, meta={"item": item})
next_url = response.xpath("//ul[@class='fl w_500']/a[last()]/@href").extract_first()
next_url = urljoin(response.url, next_url)
yield scrapy.Request(url=next_url, callback=self.parse, )
def detial_parse(self, response):
item = response.meta["item"]
item["title"] = response.xpath("//div[@class='left fl']/h1/text()").extract_first()
item["time"] = response.xpath("//div[@class='info']/span/text()").extract_first()
item["source"] = response.xpath("//div[@class='info']/span/a/text()").extract()
item["detial"] = response.xpath("//div[@class='content']/p/text()").extract()
detial_next_url = response.xpath("//div[@class='page']/a[@class='a1'][last()]/@href").extract_first()
if detial_next_url is not None: #详情页有下一页链接
yield scrapy.Request(url=detial_next_url, callback=self.detial_parse_next, meta={"item2": item})
# item["detial"] = self.detial_parse_next(response)
else:
yield item #详情页没有下一页的在此处yield ,有的就在下面函数yield,分开了
def detial_parse_next(self, response): #处理详情页,详情页需要翻页,需要翻页的item在此处理
item = response.meta["item2"]
detial_next = response.xpath("//div[@class='content']/p/text()").extract()
item["detial"] = item["detial"] + detial_next #详情页内容拼接到一起
detial_next_url_twoend = response.xpath("//div[@class='page']/a[@class='a1'][last()]/@href").extract_first()
if response.url != detial_next_url_twoend:
yield scrapy.Request(url=detial_next_url_twoend, callback=self.detial_parse_next, meta={'item2': item})
# return item["detial"]
item_list = [] #每次都会产生一个item,放数组里,取最后一个,完事!
item_list.append(item)
item = item_list[-1]
else:
yield item
pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
import re
class QingchunPPipeline(object):
def __init__(self):
client = pymongo.MongoClient(host="127.0.0.1", port=27017)
self.db = client.qingchun.qc
def process_item(self, item, spider):
item["detial"] = "\n".join(item["detial"])
item["detial"] = item["detial"].replace("\u3000", "").replace("\r\n", "").replace("\xa0", "").replace("\n", "")
self.db.insert(item)
items
import scrapy
class QingchunPItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
_id = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
detial = scrapy.Field()
source = scrapy.Field()
url = scrapy.Field()
detial_next_url = scrapy.Field()
# detial_next = scrapy.Field()
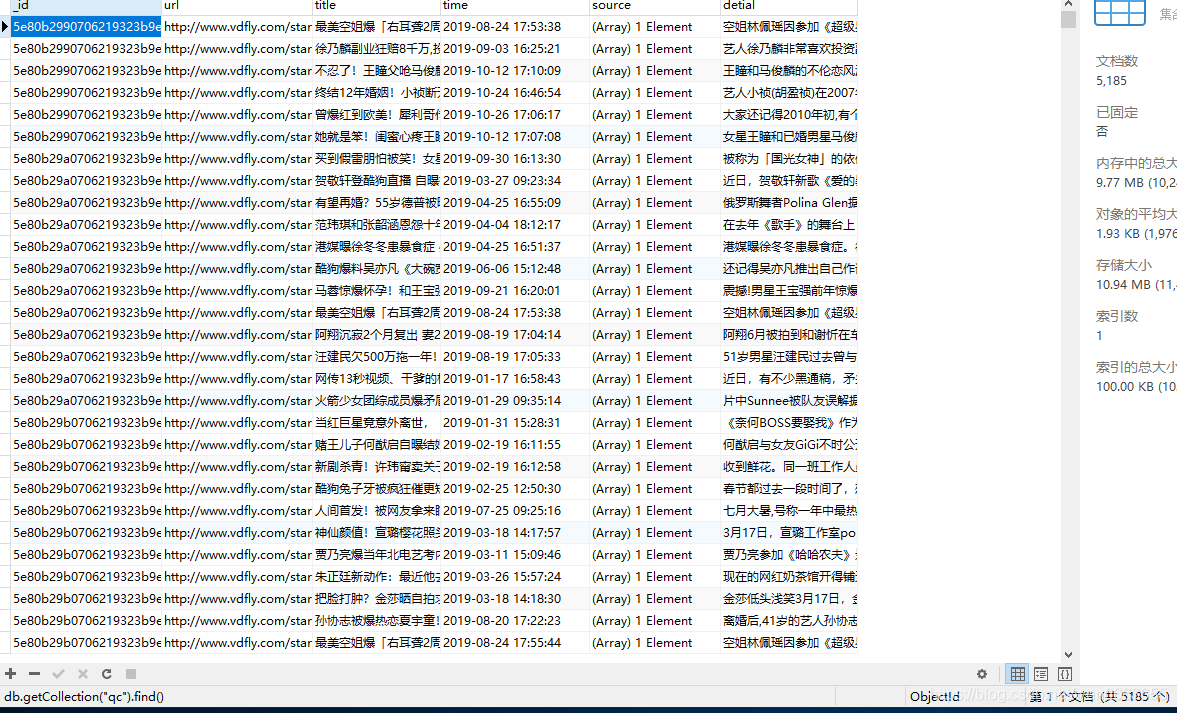
爬取成功:

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









