







 本文详细介绍了如何使用Spark-submit提交一个Word Count(WC)任务,包括准备输入文件、编写统计代码,以及深入解析Spark-submit的执行过程,涉及SparkConf、SparkEnv、DAGScheduler、TaskScheduler和UI等关键步骤。
本文详细介绍了如何使用Spark-submit提交一个Word Count(WC)任务,包括准备输入文件、编写统计代码,以及深入解析Spark-submit的执行过程,涉及SparkConf、SparkEnv、DAGScheduler、TaskScheduler和UI等关键步骤。
一:准备工作:
1.1 准备一个被统计文件:
[root@hadoop001 ~]# hadoop fs -ls /logs/input
Found 1 items
-rw-r–r-- 3 root supergroup 97 2019-03-14 22:48 /logs/input/text.txt
[root@hadoop001 ~]# hadoop fs -cat /logs/input/text.txt
hell0 world
word excel
spark sparkcore
soark sparksql
hello how
are you
spark scala
scala goog
1.2 WC统计代码:
package com.weizonggui.core03
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.fs.{FileSystem, Path}
object SparkContextApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
val sc = new SparkContext(conf)
val configuration=new Configuration()
val uri = new URI("hdfs://hadoop002:8020")
val fileSystem = FileSystem.get(uri,configuration,"hadoop")
if(fileSystem.exists(new Path(args(1)))){
fileSystem.delete(new Path(args(1)),true)
}
val wc =sc.textFile(args(0))
.flatMap(_.split("\t"))
.map((_,1))
.reduceByKey(_+_)
.saveAsTextFile(args(1))
sc.stop()
}
}
二:对代码进行打包上传并提交执行:
$SPARK_HOME/bin/spark2-submit
–master local[2]
–class com.weizonggui.core03.SparkContextApp
–name WCApp
/home/hadoop/G5-Spark-1.0.jar
hdfs://hadoop002:8020/logs/input/text.txt hdfs://hadoop002:8020/logs/output
三:Spark-submit执行解析:
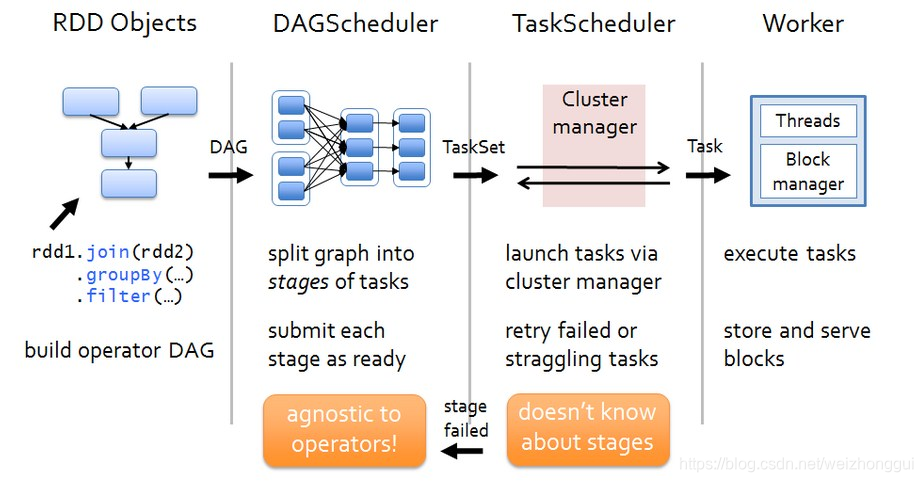
1)SparkConf
2)创建SparkEnv
3) DAGScheduler 切分stage 并且提交stage
4) TaskScheduler task提交运行 <== SchedulerBackend
5) UI


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









