






项目一:爬取金山词霸翻译功能
1.找到网址:http://www.iciba.com/fy
2.推荐爬虫学习者使用谷歌浏览器,打开谷歌浏览器,进入开发者模式(右键,检查)
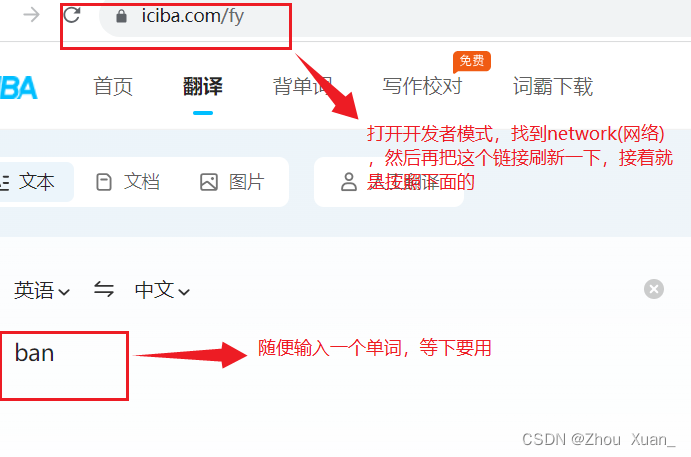
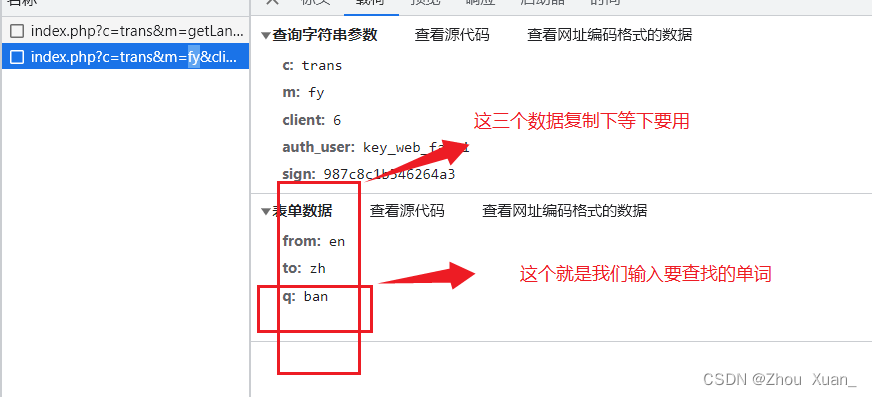
接下来,进入完整代码:
import requests
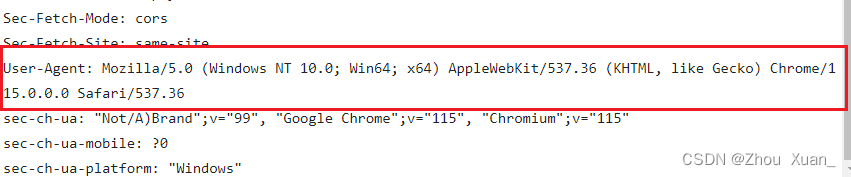
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_web_fanyi&sign=987c8c1b546264a3'
data = {
'from': 'en',
'to': 'zh',
'q': 'ban'
}
response = requests.post(url, headers=headers, data=data)
# res = json.loads(response.content.decode('utf-8'))
# print(res)
print(response.json()['content']['out'])对于本代码的一些关键:
1.为啥不直接使用input()替代ban,这样就可以得到任意一个翻译,而不是特定的了?
这个在链接中,使用了特定的参数验证,也就是sign = 后面的值,这个值一般是通过算法得到唯一的值,用于身份验证,通常他们也就是对应着一个唯一的值,所以
2.在此,还有另外一种方法,就是我#后的语句,这个需要导入json库进行使用
3.最后输入,我加了content和out,这个要根据实际情况来确定,具体如何使用方法如下:
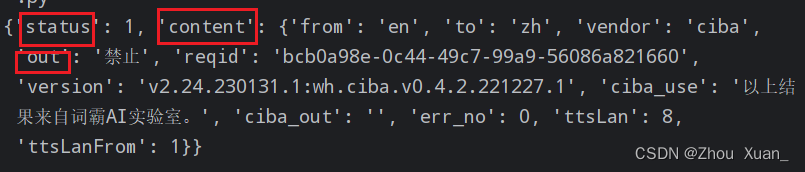
首先,这是个元组,根据需求(我们只选择翻译),我们选择content的内容,在content中选择输出翻译的out。接下来,我们进行还是进行一个翻译的,大家观察下不同之处,也便于大家更好的理解。
项目二:爬取百度翻译功能
1.老规矩都是换汤不换药,得到url和headers
2.我们可以在data中更改原有数据,现在更改成input('单词'),为啥在这里可以用了呢,往上翻,金山词霸在链接中植入了特定的参数验证,关于在深入一点,我们暂且就不探讨了
3.还有后面,我们先直接print(response,json()),查看一下

跟上面比较,你发现了不同之处了吗?上面content后面直接是一个元组,而我们现在的data后面先是一个列表,在嵌入一个元组,如果我们依旧是用上面的方法,那么肯定出现报错(可以自己尝试一下),此时,我们就要用到列表的知识了,我们先通过创建‘ fanyi ’将 li_fanyi 的元组提取出来
fanyi = li_fanyi[0]
# 我们知道下标为0的就是列表中的第一项,这样我们把列表中的第一项提取出来
然后再使用元组提取的方法,直接fanyi['v'] 就可以了
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/115.0.0.0 Safari/537.36'
}
data = {
'kw': input('单词')
}
response = requests.post(url, headers=headers, data=data)
li_fanyi = response.json()['data']
fanyi = li_fanyi[0]
print(fanyi['v'])


















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











