







文章目录
一、什么是索引?
MySQL的索引是一种数据结构,它可以帮助数据库高效地查询、更新数据表中的数据。索引通过一定的规则排列数据表中的记录,使得对表的查询可以通过对索引的搜索来加快速度。
使用索引的目的就是为了提高查询速度
二、索引的存储
B+树
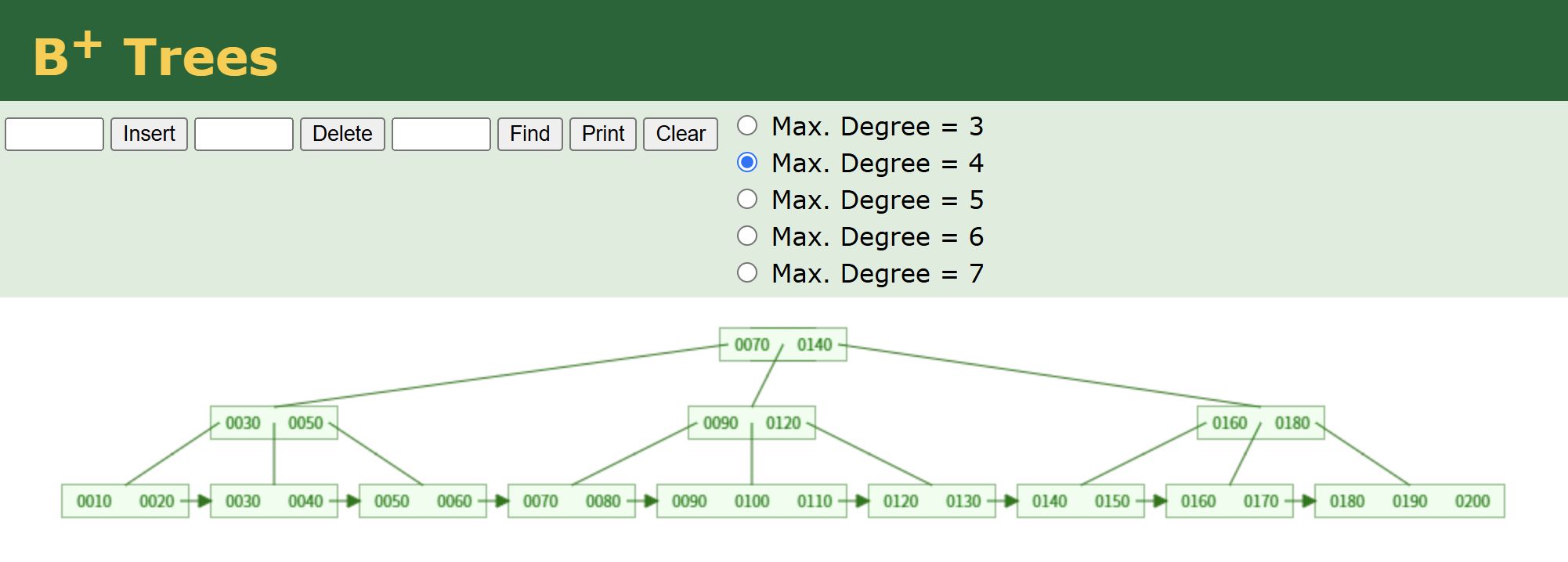
B+树的优点
- B+ 树的所有叶子节点通过指针相连,形成一个有序链表。当需要进行范围查询时,只需从起始节点开始,沿着链表顺序访问即可,无需多次进行随机磁盘 I/O,大大提高了范围查询的效率。
- 插入和删除操作的时间复杂度也保持在 O (log n),保证了在数据动态变化时,数据库的性能不会受到太大影响。
- 与B树的区别在于B+ 树的叶子节点通过指针相连,更适合进行范围查询。
三、索引的分类
补充:
创建索引后都会生成一棵索引树,索引树也是会占用磁盘空间的,同时树越多对增删改查的影响越大,因此要慎重考虑是否需要索引
3.1 主键索引
当在一个表上定义一个主键 PRIMARY KEY 时,InnoDB使用它作为聚集索引。
聚集索引和主键索引为同义词
3.2 普通索引
最基本的索引,没有唯一性的限制
可以包含一列或者多列,为多列创建组合索引称为复合索引或者组全索引
**创建的目的:**是为了提高效率,一般会为查询频繁的列创建索引——列的值重复度不高
3.3 唯一索引
当一个表定义一个唯一UNIQUE时,自动创建唯一索引。
与普通索引类似,但唯一索引不允许有重复值
3.4 全文索引
基于文本列(CHAR、VARCHAR或TEXT列)上创建,以加快对这些列中包含的数据查询和DML操作
全文索引主要用于加快数据的查询操作,尤其是针对文本数据的模糊查询,而不是加快 DML 操作。实际上,全文索引可能会在一定程度上降低 DML 操作的性能。因为在执行 INSERT、UPDATE 或 DELETE 操作时,数据库不仅要更新表中的数据,还需要更新与之关联的全文索引,这会增加额外的开销。不过,全文索引在查询时带来的性能提升通常能弥补 DML 操作的性能损失,特别是在处理大量文本数据的查询场景中。
3.5 聚集索引
如果没有为表定义 PRIMARY KEY, InnoDB使用第一个UNIQUE 和 NOT NULL 的列作为聚集索引。
聚集索引的特性:
聚集索引决定了表中数据在磁盘上的物理存储顺序。一个表只能有一个聚集索引,因为数据在磁盘上只能有一种物理存储顺序。聚集索引的键值可以用来快速定位和访问数据行,通过索引项可以直接找到对应的数据页。
唯一索引和聚集索引的关系:
唯一索引:UNIQUE 约束创建的唯一索引确保索引列中的值是唯一的,即表中不会存在两个记录在该索引列上具有相同的值。它主要用于保证数据的完整性和唯一性,同时也可以提高查询性能。
聚集索引:如前面所述,它决定数据的物理存储顺序。当没有显式定义 PRIMARY KEY 时,InnoDB 会选择第一个满足 UNIQUE 和 NOT NULL 条件的列作为聚集索引。此时,这个唯一索引同时也充当了聚集索引的角色。
不会冲突的原因:
唯一性保证:唯一索引本身就要求索引列的值是唯一的,这与聚集索引要求键值唯一的特性相契合。由于唯一索引确保了列中值的唯一性,所以在将其作为聚集索引时,不会出现键值重复的冲突问题。
非空约束:NOT NULL 约束确保该列不会包含 NULL 值。而聚集索引的键值不能为 NULL,因为 NULL 值无法有效地进行排序和定位。所以,满足 UNIQUE 和 NOT NULL 条件的列天然适合作为聚集索引。
特殊情况说明:
如果表中存在多个 UNIQUE 和 NOT NULL 的列,InnoDB 只会选择第一个定义的这样的列作为聚集索引,其他的唯一索引则作为普通的非聚集唯一索引存在。这些非聚集唯一索引仍然可以保证对应列值的唯一性,但不会影响数据的物理存储顺序。
3.6 非聚集索引
聚集索引以外的索引称为非聚集索引或二级索引
二级索引中的每条记录都包含该行的主键列,以及二级索引指定的列。
InnoDB使用这个主键值来搜索聚集索引中的行,这个过程称为回表查询
回表查询
非聚集索引查询过程:
- 通过索引查到叶子节点中的索引记录
- 通过索引记录中的主键值,去主键索引树中找到相应完整的记录 ——回表查询
产生原因
- 索引的存储结构:在关系型数据库中,通常存在主键索引(聚集索引)和非主键索引(辅助索引)。主键索引的叶子节点存储了整行数据,而非主键索引的叶子节点只存储了索引列的值和对应的主键值。
- 查询需求:当查询语句中需要的数据列不在非主键索引中时,数据库就需要先通过非主键索引定位到主键值,再根据主键值到主键索引中查找完整的数据行,从而产生回表查询。
3.7 索引覆盖
当⼀个select语句使用了普通索引且查询列表中的列刚好是创建普通索引时的所有或部分列,这时就可以直接返回数据,而不用回表查询,这样的现象称为索引覆盖。
上面我们介绍了回表查询的原因:是因为普通索引中的叶子节点存储的内容不全,所以要通过主键索引查询对应的所有内容,而索引覆盖则是,我普通索引中存储的信息覆盖了我所要查的内容,那就不需要问主键了
四、使用索引
4.1 主键索引
# 方式一,创建表时创建主键
create table t_test_pk1 (
id bigint primary key auto_increment,
name varchar(20)
);
# 方式二,创建表时单独指定主键列
create table t_test_pk2 (
id bigint auto_increment,
name varchar(20),
primary key (id)
);
# 方式三,修改表中的列为主键索引
create table t_test_pk3 (
id bigint,
name varchar(20)
);
alter table t_test_pk3 add primary key (id) ;
alter table t_test_pk3 modify id bigint auto_increment;
# ALTER TABLE:这是一个用于修改已有表结构的 SQL 关键字。借助它,能够对表进行多种操作,像添加列、删除列、修改列的数据类型等。
# MODIFY:此关键字用于修改表中现有列的定义,能够改变列的数据类型、约束条件等。
4.2 唯一索引
# 方式一,创建表时创建唯一键
create table t_test_uk1 (
id bigint primary key auto_increment,
# name为唯一键
name varchar(20) unique
);
# 方式二,创建表时单独指定唯一列
create table t_test_uk2 (
id bigint primary key auto_increment,
name varchar(20),
unique (name)
);
# 方式三,修改表中的列为唯一索引
create table t_test_uk3 (
id bigint primary key auto_increment,
name varchar(20),
);
alter table t_test_uk3 add unique (name);
4.3 普通索引
# 方式一,创建表时指定索引列
create table t_test_index1 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10),
index(sno)
);
# 方式二,修改列表中的列为普通索引
create table t_test_index2 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10)
);
alter t_test_index2 add index (sno);
# 方式三,单独创建索引并指定索引名
create table t_test_index3 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10)
);
create index index_name on t_test_index3 (sno);
4.4 复合索引
创建语法与创建普通索引相同,只不过指定多个列,列与列之间用逗号隔开
# 方式一,创建表时指定索引列
create table t_test_index4 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10),
class_id bigint,
index(sno,class_id)
);
# 方式二,修改列表中的列为普通索引
create table t_test_index5 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10),
class_id bigint
);
alter t_test_index5 add index (sno,class_id);
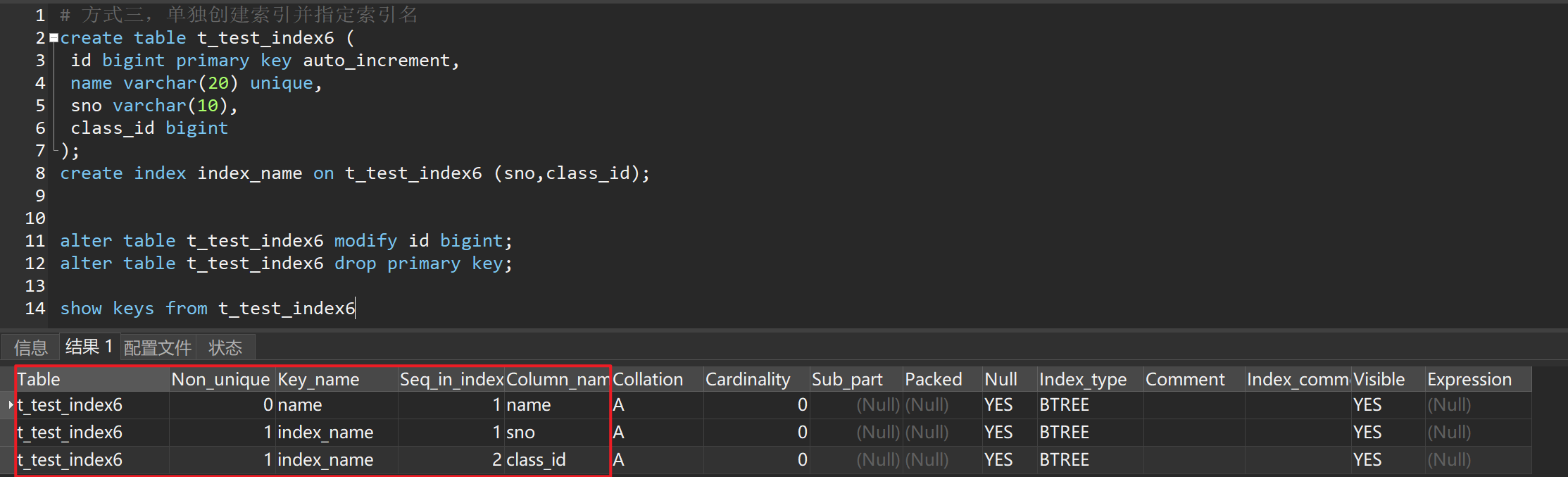
# 方式三,单独创建索引并指定索引名
create table t_test_index6 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10),
class_id bigint
);
create index index_name on t_test_index6 (sno,class_id);
五、查看索引
# 下面两个方法作用是一样的
show keys from table_name;
show index from table_name;
# 或者通过查看表的基本结构信息,来查看索引
desc table_name;
六、删除索引
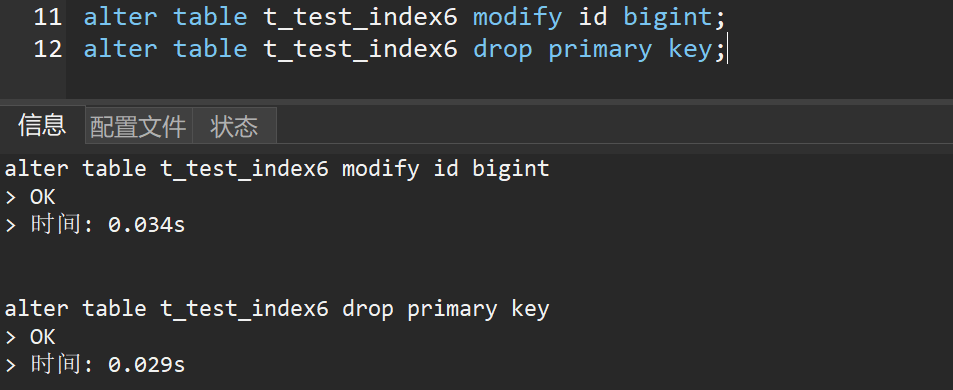
6.1 删除主键
alter table t_test_index6 drop primary key;

自增列错误,应先删除自增属性
alter table t_test_index6 modify id bigint;
alter table t_test_index6 drop primary key;
查看索引
6.2 删除其他索引
alter table 表名 drop index 索引名;

注意:
除了因为主键在一张表里只能有一个,而其他键都可以有很多,所以必须使用索引名。

总结
本篇文章主要介绍了有关关系型数据库MySQL中的索引相关内容,如果有什么不对的地方,希望可以在评论区指正,谢谢大家。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









