




 本文介绍了如何使用Python爬虫从两个天气网站抓取2023年西安的气温数据,并将数据整理为CSV文件,随后通过Pandas和Pyecharts进行数据清洗和可视化,生成了气温变化的折线图。
本文介绍了如何使用Python爬虫从两个天气网站抓取2023年西安的气温数据,并将数据整理为CSV文件,随后通过Pandas和Pyecharts进行数据清洗和可视化,生成了气温变化的折线图。
Python爬虫——2023年西安全年气温数据并进行可视化处理
一、网站选择
我们要找到西安历史气温数据,可以去一些天气网站上查找,但不一定每一个天气网站都会留有各城市的历史天气数据,因此我在这里给大家推荐两个网站方便大家进行历史气温的获取:
1.天气网
这个网站点进去后可以根据城市的首字母进行城市的选择,选择后就可以查找想要年份月份的气温数据(目前最早到2011年)
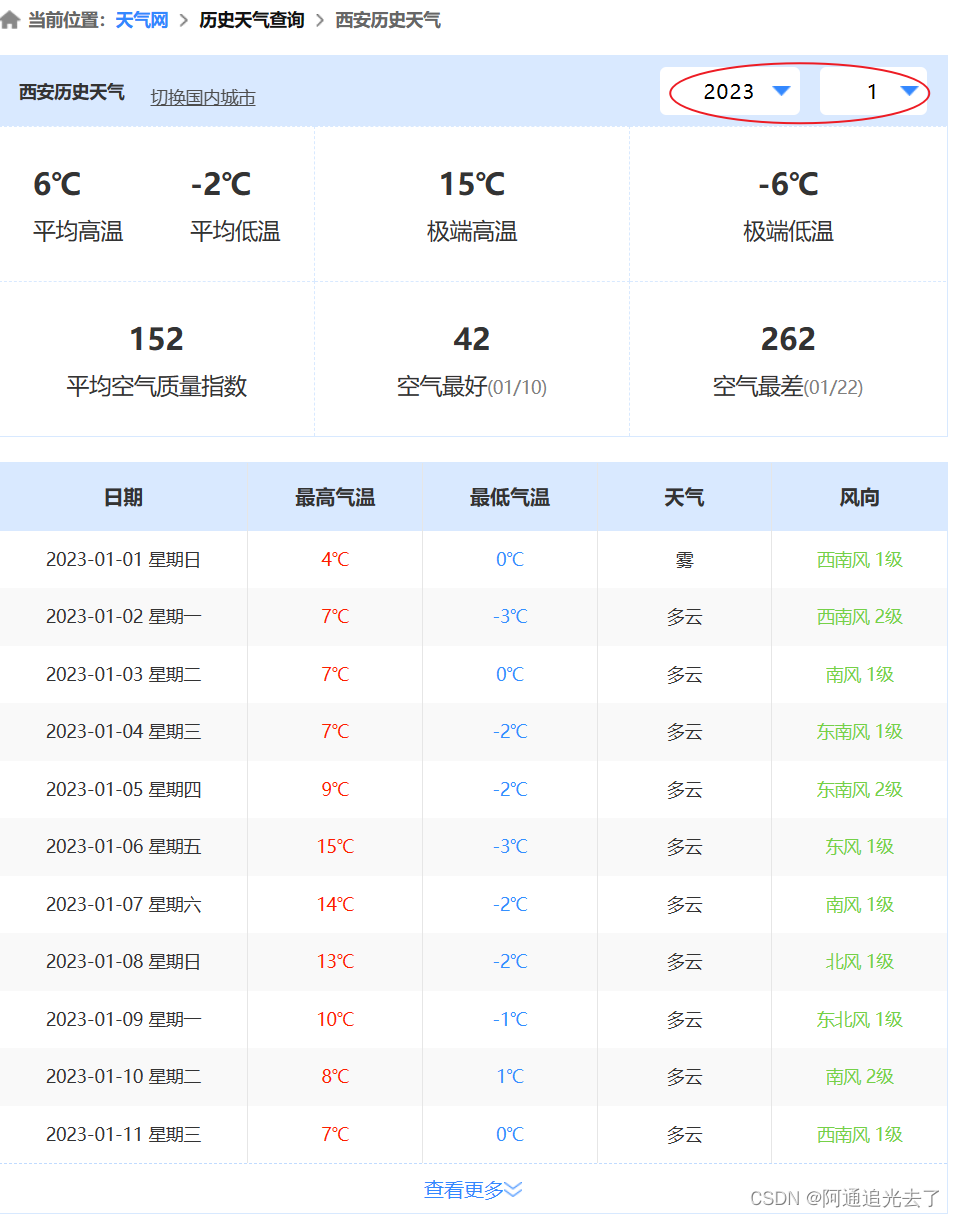
下来以2023年西安气温作为示例:
在首字母为x中找到西安

在下图选择对应的时间即可
2.2345天气王
进入网站后点击最上面的导航->历史天气
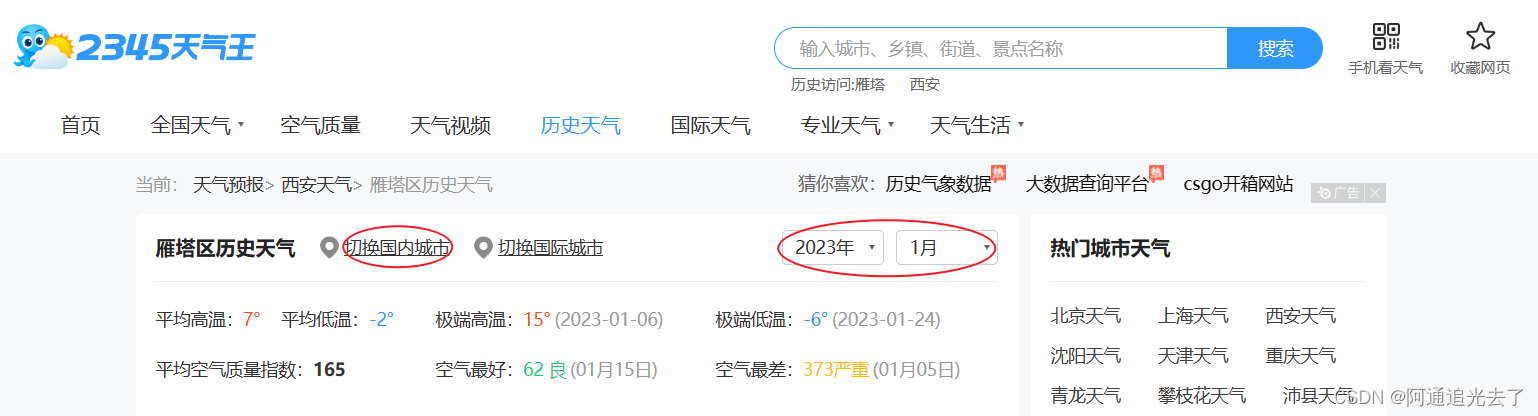
进入后可以切换城市与具体时间
二、爬虫代码编写
代码编写对第一个网站的2023年西安气温进行数据爬取
1.库函数的选择
我们使用的是Python语言进行数据的爬虫,首先确定代码编写当中所需要用到的库:
import requests # 模拟浏览器进行网络请求
from lxml import etree # 进行数据预处理
import csv # 写入csv文件
——request库是爬虫所需要的最基本的进行网络请求的库
——etree是使用xpath解析所需要用到的对数据进行预处理的库
——csv是用来将获取到的数据进行存储的库
2.获取天气数据
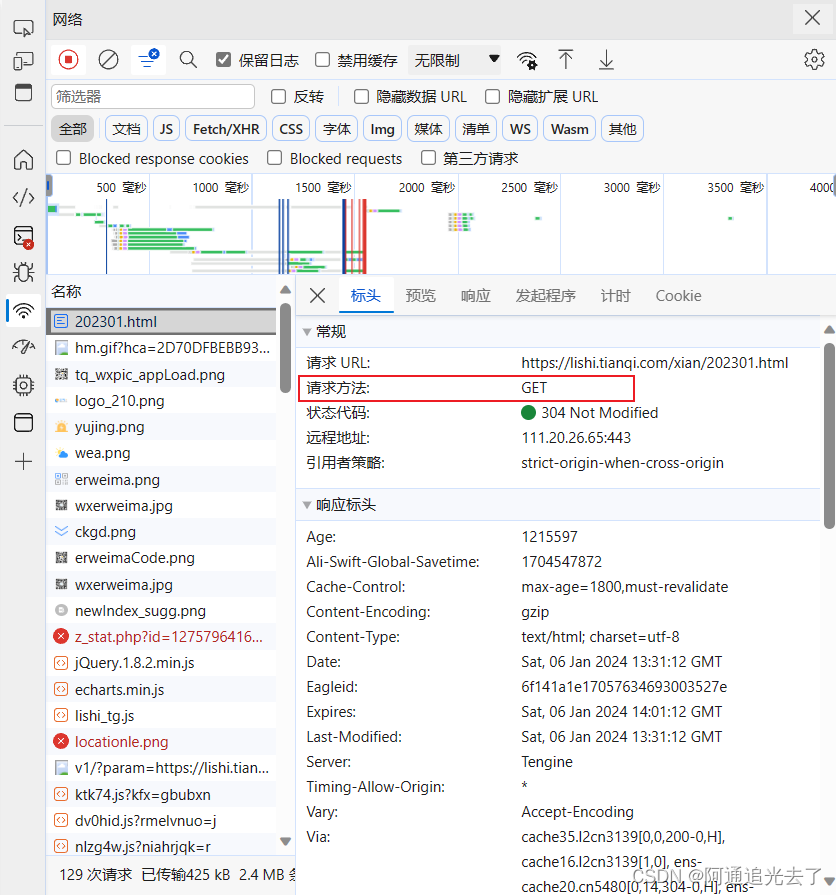
首先定义一个获取天气数据的函数grtWeather,参数为url,接下来新建一个列表weather_info,这个列表用于存放一个月的天气数据。接下来设置请求头:(一般情况下会因为浏览器版本不同导致请求头不同,请勿直接复制粘贴!!!)
空白处鼠标右键选择检查/F12–>找到network(网络)–>找到202301.html点击–>找到标头最下面的User-Agent复制作为请求头即可
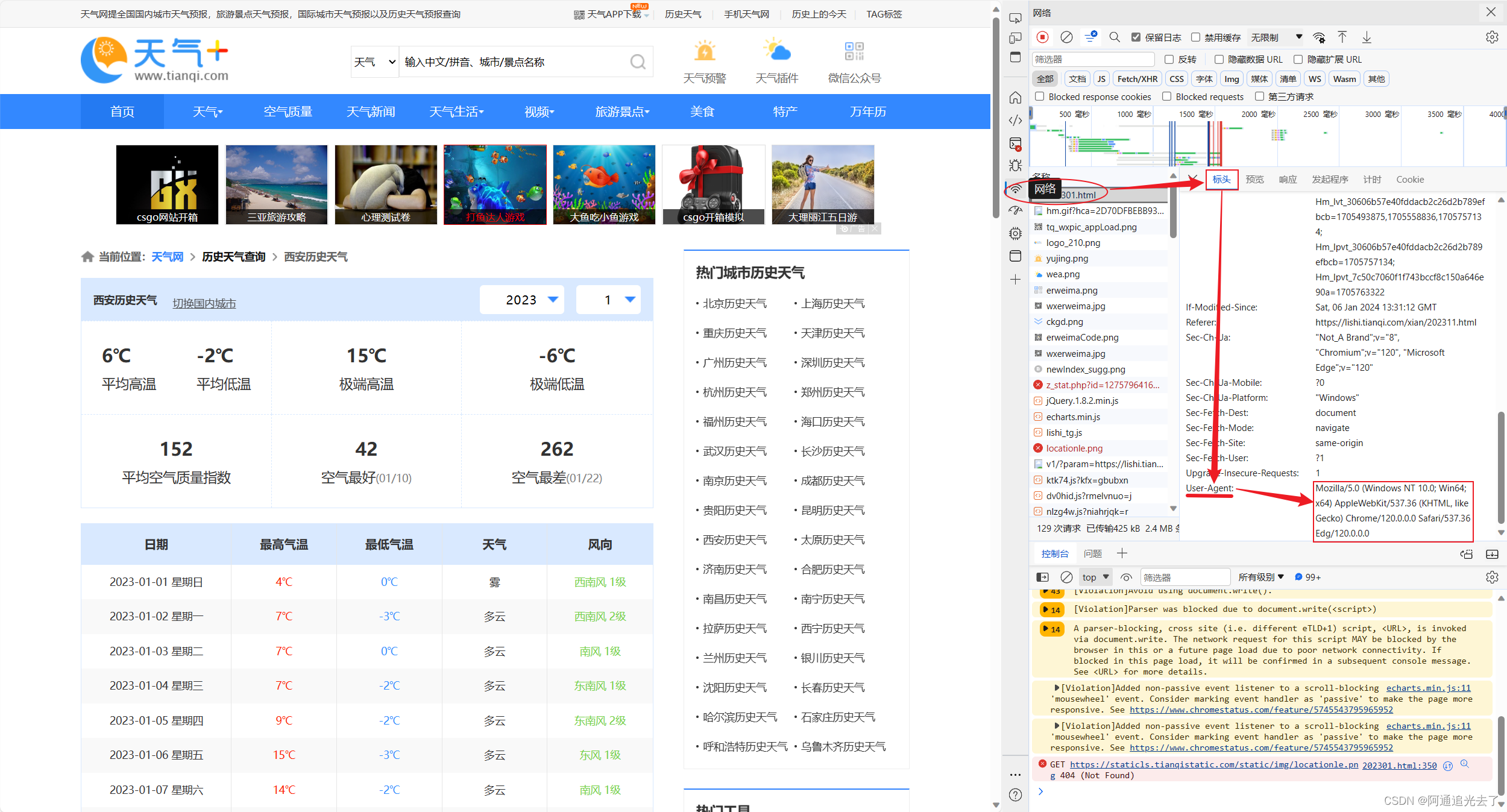
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
接下来接收响应数据,通过request的get方法进行接收,参数一般为url与headers(分清楚是get还是post方法)
接下来通过etree将网络上的页面源码数据加载到resp_html中,参数为resp.text,其中text返回字符串形式的响应数据。
# 请求 接收到了响应数据
resp = requests.get(url, headers=headers)
# 数据预处理
resp_html = etree.HTML(resp.text)
使用resp_html.xpath将对应地址的数据返回,其中xpath地址可以这样进行编写:
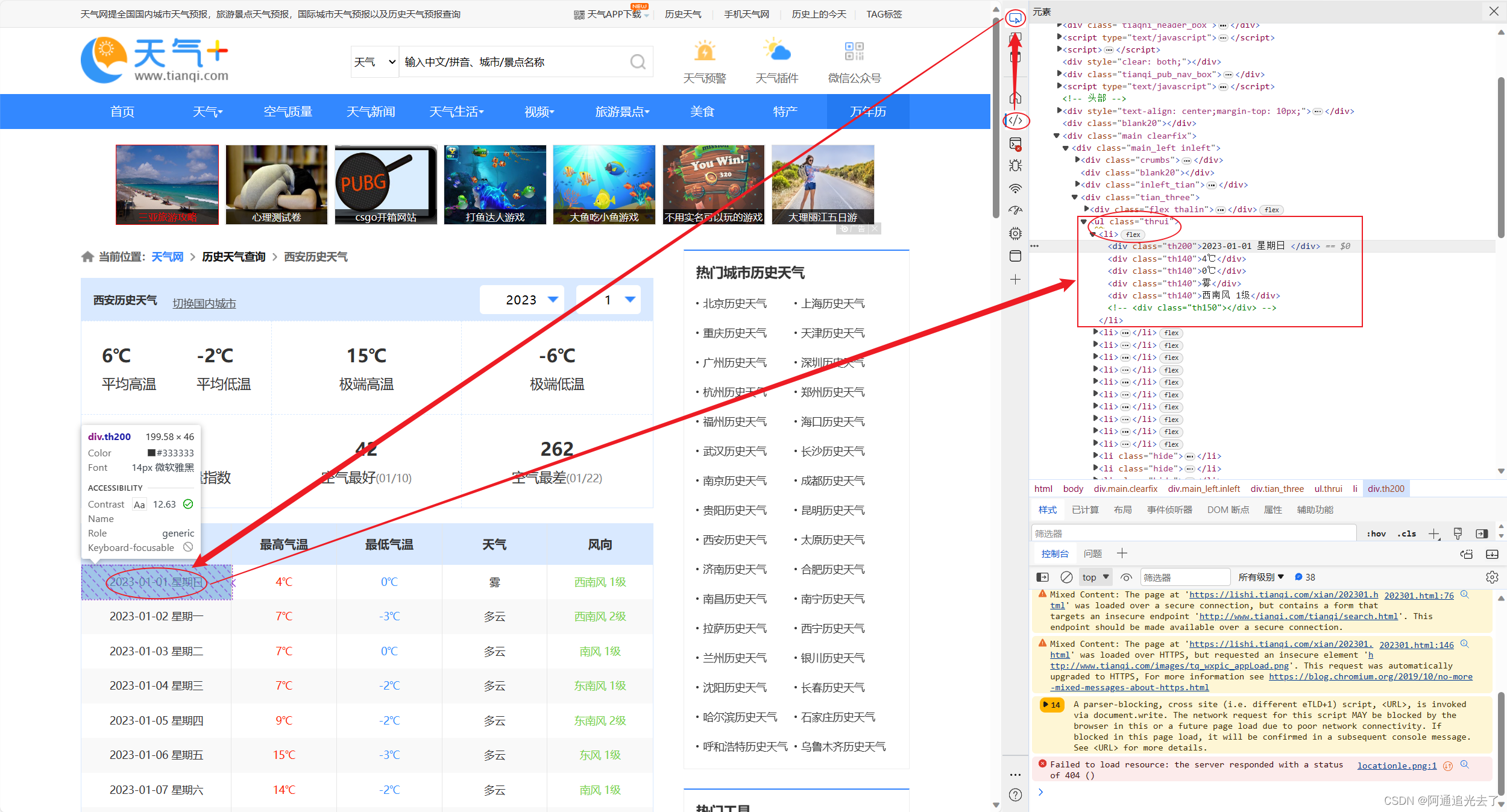
1.在控制台找到element(元素)后点击最上方的鼠标按钮
2.在左侧页面找到自己想要查找的元素,如图所示
3.点击后右侧的元素就会自动跳转到你所点击的元素位置上,就可以查看具体的元素位置了
例:本图日期的位置为:ul class = 'thrui’标签下的li标签中
//:表示的是多个层级,可以表示从任意位置开始定位(‘/html//title’)(‘//title’)
属性定位://div[@class=“song”]
因此此处的xpath位置为:
# xpath提取所有数据
resp_list = resp_html.xpath("//ul[@class='thrui']/li")
我们可以看到在ul下的每一个li标签当中都有着日期、最高温、最低温、天气、风向五个元素,想要将它们存储起来就需要使用一个字典进行存储,并且需要使用一个循环对每一个li标签进行遍历以获得每一天的数据(一个li标签对应一个月的一天)。首先定义一个day_weather_info字典,再分别对日期,最高温,最低温,天气(将自己需要的数据进行处理即可)进行数据的存储:
对于日期而言,我们需要对其具体的xpath路径进行解析,可以看到日期是在li标签下的第一个div下,因此获取div[1]下的文本即可,其中的split是对获取的日期前后的空白进行抹除以确保格式统一,接下来的剩余元素按照统一方式处理即可。
最后将每天的天气数据追加到列表中并返回它即可。
/text():获取的是标签中直系的文本内容
//text():获取的是标签中非直系的文本内容(所有的文本内容)
# for循环迭代遍历
for li in resp_list:
day_weather_info = {
}
# 日期
day_weather_info['date_time'] = li.xpath("./div[1]/text()")[0].split(' ')[0]
# 最高气温 (包含摄氏度符号)
high = li.xpath("./div[2]/text()")[0]
day_weather_info['high'] = high
# 最低气温
low = li.xpath("./div[3]/text()")[0]
day_weather_info['low'] = low
# 天气
day_weather_info['weather'] = li.xpath("./div[4]/text()")[0]
weather_info.append(day_weather_info)
return weather_info
完整的函数体
def getWeather(url):
weather_info = [] # 新建一个列表,将爬取的每月数据放进去
# 请求头信息:浏览器版本型号,接收数据的编码格式
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
# 请求 接收到了响应数据
resp = requests.get(url, headers=headers)
# 数据预处理
resp_html = etree.HTML(resp.text)
# xpath提取所有数据
resp_list = resp_h 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









