






前言
前几天看到一个文章,感触很深
字节跳动面试官:请你实现一个大文件上传和断点续传
作者从0实现了大文件的切片上传,断点续传,秒传,暂停等功能,深入浅出的把这个面试题进行了全面的剖析
彩虹屁不多吹,我决定蹭蹭热点,录录视频,把作者完整写代码的过程加进去,并且接着这篇文章写,所以请看完上面的文章后再食用,我做了一些扩展如下
- 计算hash耗时的问题,不仅可以通过web-workder,还可以参考React的FFiber架构,通过requestIdleCallback来利用浏览器的空闲时间计算,也不会卡死主线程
- 文件hash的计算,是为了判断文件是否存在,进而实现秒传的功能,所以我们可以参考布隆过滤器的理念, 牺牲一点点的识别率来换取时间,比如我们可以抽样算hash
- 文中通过web-workder让hash计算不卡顿主线程,但是大文件由于切片过多,过多的HTTP链接过去,也会把浏览器打挂 (我试了4个G的,直接卡死了), 我们可以通过控制异步请求的并发数来解决,我记得这也是头条的一个面试题
- 每个切片的上传进度不需要用表格来显示,我们换成方块进度条更直观一些(如图)
- 并发上传中,报错如何重试,比如每个切片我们允许重试两次,三次再终止
- 由于文件大小不一,我们每个切片的大小设置成固定的也有点略显笨拙,我们可以参考TCP协议的慢启动策略, 设置一个初始大小,根据上传任务完成的时候,来动态调整下一个切片的大小, 确保文件切片的大小和当前网速匹配
- 小的体验优化,比如上传的时候
- 文件碎片清理

已经存在的秒传的切片就是绿的,正在上传的是蓝色的,并发量是4,废话不多说,我们一起代码开花
时间切片计算文件hash
其实就是time-slice概念,React中Fiber架构的核心理念,利用浏览器的空闲时间,计算大的diff过程,中途又任何的高优先级任务,比如动画和输入,都会中断diff任务, 虽然整个计算量没有减小,但是大大提高了用户的交互体验
这可能是最通俗的 React Fiber(时间分片) 打开方式
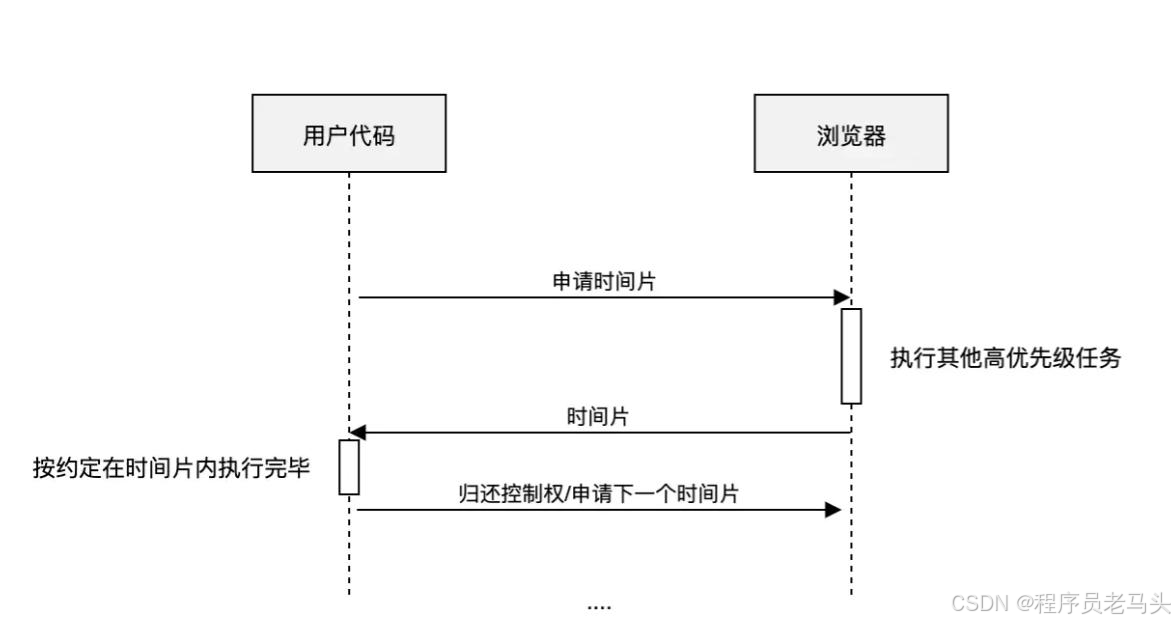
requestIdleCallback
window.requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作 requestIdelCallback执行的方法,会传递一个deadline参数,能够知道当前帧的剩余时间,用法如下
requestIdelCallback(myNonEssentialWork);
function myNonEssentialWork (deadline) {
// deadline.timeRemaining()可以获取到当前帧剩余时间
// 当前帧还有时间 并且任务队列不为空
while (deadline.timeRemaining() > 0 && tasks.length > 0) {
doWorkIfNeeded();
}
if (tasks.length > 0){
requestIdleCallback(myNonEssentialWork);
}
}
deadline的结构如下
interface Dealine {
didTimeout: boolean // 表示任务执行是否超过约定时间
timeRemaining(): DOMHighResTimeStamp // 任务可供执行的剩余时间
}

该图中的两个帧,在每一帧内部,TASK和redering只花费了一部分时间,并没有占据整个帧,那么这个时候,如图中idle period的部分就是空闲时间,而每一帧中的空闲时间,根据该帧中处理事情的多少,复杂度等,消耗不等,所以空闲时间也不等。
而对于每一个deadline.timeRemaining()的返回值,就是如图中,Idle Callback到所在帧结尾的时间(ms级)
时间切片计算
我们接着之前文章的代码,改造一下calculateHash
async calculateHashIdle(chunks) {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
// 根据文件内容追加计算
const appendToSpark = async file => {
return new Promise(resolve => {
const reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = e => {
spark.append(e.target.result);
resolve();
};
});
};
const workLoop = async deadline => {
// 有任务,并且当前帧还没结束
while (count < chunks.length && deadline.timeRemaining() > 1) {
await appendToSpark(chunks[count].file);
count++;
// 没有了 计算完毕
if (count < chunks.length) {
// 计算中
this.hashProgress = Number(
((100 * count) / chunks.length).toFixed(2)
);
// console.log(this.hashProgress)
} else {
// 计算完毕
this.hashProgress = 100;
resolve(spark.end());
}
}
window.requestIdleCallback(workLoop);
};
window.requestIdleCallback(workLoop);
});
},
计算过程中,页面放个输入框,输入无压力,时间切片的威力
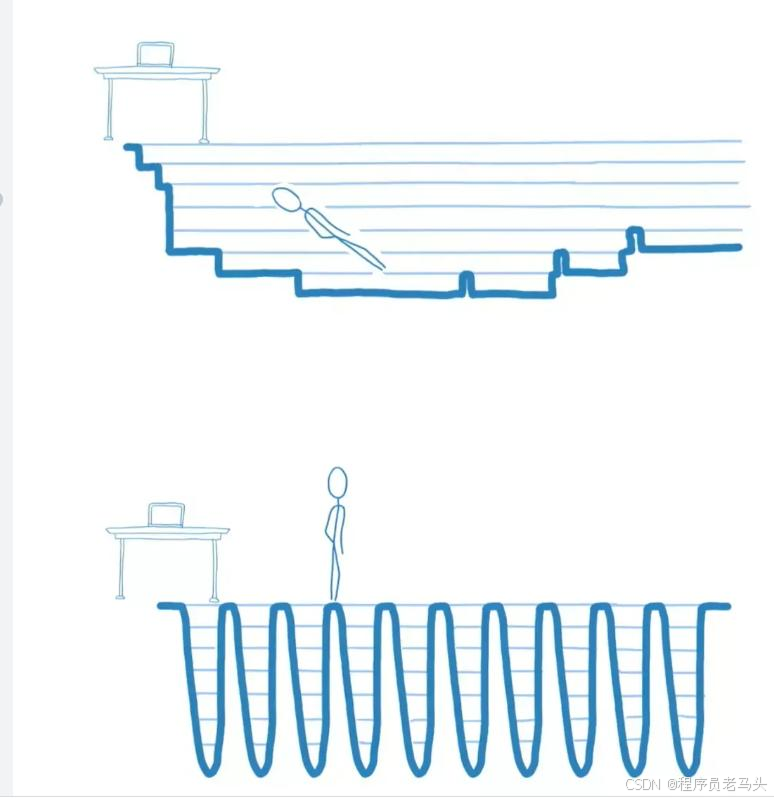
上图是React15和Fiber架构的对比,可以看出下图任务量没变,但是变得零散了,不混卡顿主线程
抽样hash
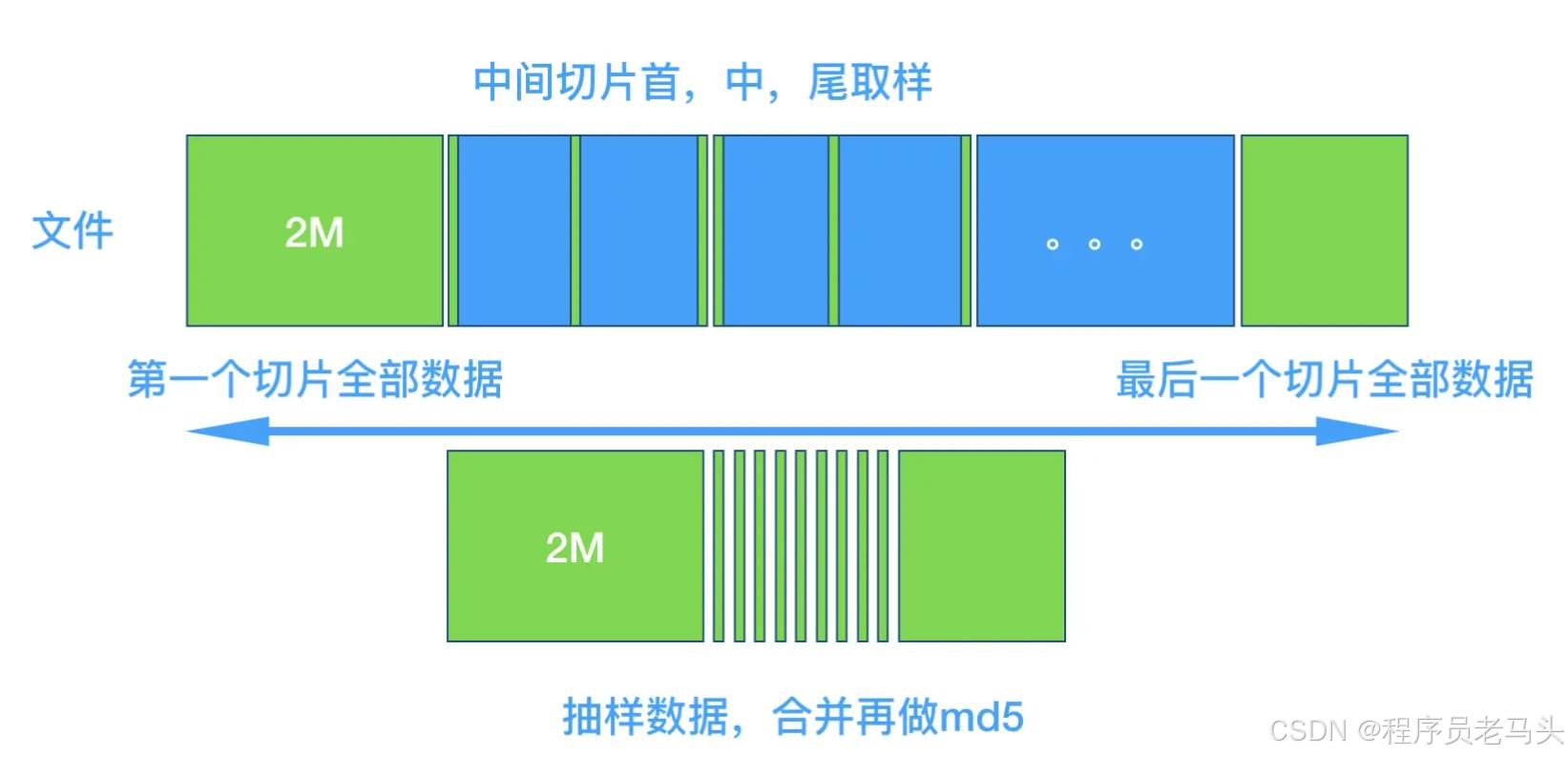
计算文件md5值的作用,无非就是为了判定文件是否存在,我们可以考虑设计一个抽样的hash,牺牲一些命中率的同时,提升效率,设计思路如下
- 文件切成2M的切片
- 第一个和最后一个切片全部内容,其他切片的取 首中尾三个地方各2个字节
- 合并后的内容,计算md5,称之为影分身Hash
- 这个hash的结果,就是文件存在,有小概率误判,但是如果不存在,是100%准的的 ,和布隆过滤器的思路有些相似, 可以考虑两个hash配合使用
- 我在自己电脑上试了下1.5G的文件,全量大概要20秒,抽样大概1秒还是很不错的, 可以先用来判断文件是不是不存在
- 我真是个小机灵
抽样md5: 1028.006103515625ms
全量md5: 21745.13916015625ms
async calculateHashSample() {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReader();
const file = this.container.file;
// 文件大小
const size = this.container.file.size;
let offset = 2 * 1024 * 1024;
let chunks = [file.slice(0, offset)];
// 前面100K
let cur = offset;
while (cur < size) {
// 最后一块全部加进来
if (cur + offset >= size) {
chunks.push(file.slice(cur, cur + offset));
} else {
// 中间的 前中后去两个字节
const mid = cur + offset / 2;
const end = cur + offset;
chunks.push(file.slice(cur, cur + 2));
chunks.push(file.slice(mid, mid + 2));
chunks.push(file.slice(end - 2, end));
}
// 前取两个字节
cur += offset;
}
// 拼接
reader.readAsArrayBuffer(new Blob(chunks));
reader.onload = e => {
spark.append(e.target.result);
resolve(spark.end());
};
});
}
网络请求并发控制
大文件hash计算后,一次发几百个http请求,计算哈希没卡,结果TCP建立的过程就把浏览器弄死了,而且我记得本身异步请求并发数的控制,本身就是头条的一个面试题

思路其实也不难,就是我们把异步请求放在一个队列里,比如并发数是3,就先同时发起3个请求,然后有请求结束了,再发起下一个请求即可, 思路清楚,代码也就呼之欲出了
我们通过并发数max来管理并发数,发起一个请求max--,结束一个请求max++即可
+async sendRequest(forms, max=4) {
+ return new Promise(resolve => {
+ const len = forms.length;
+ let idx = 0;
+ let counter = 0;
+ const start = async ()=> {
+ // 有请求,有通道
+ while (idx < len && max > 0) {
+ max--; // 占用通道
+ console.log(idx, "start");
+ const form = forms[idx].form;
+ const index = forms[idx].index;
+ idx++
+ request({
+ url: '/upload',
+ data: form,
+ onProgress: this.createProgresshandler(this.chunks[index]),
+ requestList: this.requestList
+ }).then(() => {
+ max++; // 释放通道
+ counter++;
+ if (counter === len) {
+ resolve();
+ } else {
+ start();
+ }
+ });
+ }
+ }
+ start();
+ });
+}
async uploadChunks(uploadedList = []) {
// 这里一起上传,碰见大文件就是灾难
// 没被hash计算打到,被一次性的tcp链接把浏览器稿挂了
// 异步并发控制策略,我记得这个也是头条一个面试题
// 比如并发量控制成4
const list = this.chunks
.filter(chunk => uploadedList.indexOf(chunk.hash) == -1)
.map(({ chunk, hash, index }, i) => {
const form = new FormData();
form.append("chunk", chunk);
form.append("hash", hash);
form.append("filename", this.container.file.name);
form.append("fileHash", this.container.hash);
return { form, index };
})
- .map(({ form, index }) =>
- request({
- url: "/upload",
- data: form,
- onProgress: this.createProgresshandler(this.chunks[index]),
- requestList: this.requestList
- })
- );
- // 直接全量并发
- await Promise.all(list);
// 控制并发
+ const ret = await this.sendRequest(list,4)
if (uploadedList.length + list.length === this.chunks.length) {
// 上传和已经存在之和 等于全部的再合并
await this.mergeRequest();
}
},
话说字节跳动另外一个面试题我也做出来的,不知道能不能通过他们的一面
慢启动策略实现
TCP拥塞控制的问题 其实就是根据当前网络情况,动态调整切片的大小
- chunk中带上size值,不过进度条数量不确定了,修改createFileChunk, 请求加上时间统计)
- 比如我们理想是30秒传递一个
- 初始大小定为1M,如果上传花了10秒,那下一个区块大小变成3M
- 如果上传花了60秒,那下一个区块大小变成500KB 以此类推
- 并发+慢启动的逻辑有些复杂,我自己还没绕明白,囧所以先一次只传一个切片,来演示这个逻辑,新建一个handleUpload1函数
async handleUpload1(){
// @todo数据缩放的比率 可以更平缓
// @todo 并发+慢启动
// 慢启动上传逻辑
const file = this.container.file
if (!file) return;
this.status = Status.uploading;
const fileSize = file.size
let offset = 1024*1024
let cur = 0
let count =0
this.container.hash = await this.calculateHashSample();
while(cur<fileSize){
// 切割offfset大小
const chunk = file.slice(cur, cur+offset)
cur+=offset
const chunkName = this.container.hash + "-" + count;
const form = new FormData();
form.append("chunk", chunk);
form.append("hash", chunkName);
form.append("filename", file.name);
form.append("fileHash", this.container.hash);
form.append("size", chunk.size);
let start = new Date().getTime()
await request({ url: '/upload',data: form })
const now = new Date().getTime()
const time = ((now -start)/1000).toFixed(4)
let rate = time/30
// 速率有最大2和最小0.5
if(rate<0.5) rate=0.5
if(rate>2) rate=2
// 新的切片大小等比变化
console.log(`切片${count}大小是${this.format(offset)},耗时${time}秒,是30秒的${rate}倍,修正大小为${this.format(offset/rate)}`)
// 动态调整offset
offset = parseInt(offset/rate)
// if(time)
count++
}
}
调整下slow 3G网速 看下效果
切片0大小是1024.00KB,耗时13.2770秒,是30秒的0.5倍,修正大小为2.00MB
切片1大小是2.00MB,耗时25.4130秒,是30秒的0.8471倍,修正大小为2.36MB
切片2大小是2.36MB,耗时14.1260秒,是30秒的0.5倍,修正大小为4.72MB
搞定
并发重试+报错
- 请求出错.catch 把任务重新放在队列中
- 出错后progress设置为-1 进度条显示红色
- 数组存储每个文件hash请求的重试次数,做累加 比如[1,0,2],就是第0个文件切片报错1次,第2个报错2次
- 超过3的直接reject
首先后端模拟报错
if(Math.random()<0.5){
// 概率报错
console.log('概率报错了')
res.statusCode=500
res.end()
return
}
async sendRequest(urls, max=4) {
- return new Promise(resolve => {
+ return new Promise((resolve,reject) => {
const len = urls.length;
let idx = 0;
let counter = 0;
+ const retryArr = []
const start = async ()=> {
// 有请求,有通道
- while (idx < len && max > 0) {
+ while (counter < len && max > 0) {
max--; // 占用通道
console.log(idx, "start");
- const form = urls[idx].form;
- const index = urls[idx].index;
- idx++
+ // 任务不能仅仅累加获取,而是要根据状态
+ // wait和error的可以发出请求 方便重试
+ const i = urls.findIndex(v=>v.status==Status.wait || v.status==Status.error )// 等待或者error
+ urls[i].status = Status.uploading
+ const form = urls[i].form;
+ const index = urls[i].index;
+ if(typeof retryArr[index]=='number'){
+ console.log(index,'开始重试')
+ }
request({
url: '/upload',
data: form,
onProgress: this.createProgresshandler(this.chunks[index]),
requestList: this.requestList
}).then(() => {
+ urls[i].status = Status.done
max++; // 释放通道
counter++;
+ urls[counter].done=true
if (counter === len) {
resolve();
} else {
start();
}
- });
+ }).catch(()=>{
+ urls[i].status = Status.error
+ if(typeof retryArr[index]!=='number'){
+ retryArr[index] = 0
+ }
+ // 次数累加
+ retryArr[index]++
+ // 一个请求报错3次的
+ if(retryArr[index]>=2){
+ return reject()
+ }
+ console.log(index, retryArr[index],'次报错')
+ // 3次报错以内的 重启
+ this.chunks[index].progress = -1 // 报错的进度条
+ max++; // 释放当前占用的通道,但是counter不累加
+
+ start()
+ })
}
}
start();
}
如图所示,报错后会区块变红,但是会重试
文件碎片清理
如果很多人传了一半就离开了,这些切片存在就没意义了,可以考虑定期清理,当然 ,我们可以使用node-schedule来管理定时任务 比如我们每天扫一次target,如果文件的修改时间是一个月以前了,就直接删除把
// 为了方便测试,我改成每5秒扫一次, 过期1钟的删除做演示
const fse = require('fs-extra')
const path = require('path')
const schedule = require('node-schedule')
// 空目录删除
function remove(file,stats){
const now = new Date().getTime()
const offset = now - stats.ctimeMs
if(offset>1000*60){
// 大于60秒的碎片
console.log(file,'过期了,浪费空间的玩意,删除')
fse.unlinkSync(file)
}
}
async function scan(dir,callback){
const files = fse.readdirSync(dir)
files.forEach(filename=>{
const fileDir = path.resolve(dir,filename)
const stats = fse.statSync(fileDir)
if(stats.isDirectory()){
return scan(fileDir,remove)
}
if(callback){
callback(fileDir,stats)
}
})
}
// * * * * * *
// ┬ ┬ ┬ ┬ ┬ ┬
// │ │ │ │ │ │
// │ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
// │ │ │ │ └───── month (1 - 12)
// │ │ │ └────────── day of month (1 - 31)
// │ │ └─────────────── hour (0 - 23)
// │ └──────────────────── minute (0 - 59)
// └───────────────────────── second (0 - 59, OPTIONAL)
let start = function(UPLOAD_DIR){
// 每5秒
schedule.scheduleJob("*/5 * * * * *",function(){
console.log('开始扫描')
scan(UPLOAD_DIR)
})
}
exports.start = start
开始扫描
/upload/target/625c.../625c...-0 过期了,删除
/upload/target/625c.../625c...-1 过期了,删除
/upload/target/625c.../625c...-10 过期了,删除
/upload/target/625c.../625c...-11 过期了,删除
/upload/target/625c.../625c...-12 过期了,删除
后续扩展和思考
留几个思考题,下次写文章再实现 方便继续蹭热度
- requestIdleCallback兼容性,如何自己实现一个react也是自己写的调度逻辑,以后有机会写个文章介绍React自己实现的requestIdleCallback
- 并发+慢启动配合
- 抽样hash+全量哈希+时间切片配合
- 大文件切片下载一样的切片逻辑,通过axios.head请求获取content-Length使用http的Range这个header就可以切片下载了,其他逻辑和上传差不多
- 小的体验优化比如离开页面的提醒 等等小tips
- 慢启动的变化应该更平滑,比如使用三角函数,把变化率平滑的限制在0.5~1.5之间
- websocket推送进度
思考和总结
- 任何看似简单的需求,量级提升后,都变得很复杂,人生也是这样
- 文件上传简单,大文件就复杂,单机简单,分布式难
- 就连一个简单的leftPad函数(左边补齐字符),考虑到性能,二分法性能都秒杀数组join ,引起大讨论论left-pad函数的实现任何一个知识点 都值得深挖
- 产品经理下次再说啥需求简单,就kan他
- 我准备结合上一篇,录一个大文件上传的手摸手剖析视频 敬请期待
代码
https://github.com/shengxinjing/upload
# 1、什么是秒传
通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了.
# 2、本文实现的秒传核心逻辑
a、利用redis的set方法存放文件上传状态,其中key为文件上传的md5,value为是否上传完成的标志位,
b、当标志位true为上传已经完成,此时如果有相同文件上传,则进入秒传逻辑。如果标志位为false,则说明还没上传完成,此时需要在调用set的方法,保存块号文件记录的路径,其中key为上传文件md5加一个固定前缀,value为块号文件记录路径
# 分片上传
# 1、什么是分片上传
分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。
# 2、分片上传的场景
1.大文件上传
2.网络环境环境不好,存在需要重传风险的场景
# 断点续传
# 1、什么是断点续传
断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。本文的断点续传主要是针对断点上传场景。
# 2、应用场景
断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。
# 3、实现断点续传的核心逻辑
在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。
为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。
# 4、实现流程步骤
a、方案一,常规步骤
- 将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
- 初始化一个分片上传任务,返回本次分片上传唯一标识;
- 按照一定的策略(串行或并行)发送各个分片数据块;
- 发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。
b、方案二、本文实现的步骤
- 前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小
- 服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)
- 服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。
# 5、分片上传/断点上传代码实现
a、前端采用百度提供的webuploader的插件,进行分片。因本文主要介绍服务端代码实现,webuploader如何进行分片,具体实现可以查看如下链接:
http://fex.baidu.com/webuploader/getting-started.htmlopen in new window
b、后端用两种方式实现文件写入,一种是用RandomAccessFile,如果对RandomAccessFile不熟悉的朋友,可以查看如下链接:
https://blog.youkuaiyun.com/dimudan2015/article/details/81910690open in new window
另一种是使用MappedByteBuffer,对MappedByteBuffer不熟悉的朋友,可以查看如下链接进行了解:
https://www.jianshu.com/p/f90866dcbffcopen in new window
# 后端进行写入操作的核心代码
# 1、RandomAccessFile实现方式
@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS)
@Slf4j
public class RandomAccessUploadStrategy extends SliceUploadTemplate {
@Autowired
private FilePathUtil filePathUtil;
@Value("${upload.chunkSize}")
private long defaultChunkSize;
@Override
public boolean upload(FileUploadRequestDTO param) {
RandomAccessFile accessTmpFile = null;
try {
String uploadDirPath = filePathUtil.getPath(param);
File tmpFile = super.createTmpFile(param);
accessTmpFile = new RandomAccessFile(tmpFile, "rw");
//这个必须与前端设定的值一致
long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024
: param.getChunkSize();
long offset = chunkSize * param.getChunk();
//定位到该分片的偏移量
accessTmpFile.seek(offset);
//写入该分片数据
accessTmpFile.write(param.getFile().getBytes());
boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath);
return isOk;
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.close(accessTmpFile);
}
return false;
}
}
# 2、MappedByteBuffer实现方式
@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER)
@Slf4j
public class MappedByteBufferUploadStrategy extends SliceUploadTemplate {
@Autowired
private FilePathUtil filePathUtil;
@Value("${upload.chunkSize}")
private long defaultChunkSize;
@Override
public boolean upload(FileUploadRequestDTO param) {
RandomAccessFile tempRaf = null;
FileChannel fileChannel = null;
MappedByteBuffer mappedByteBuffer = null;
try {
String uploadDirPath = filePathUtil.getPath(param);
File tmpFile = super.createTmpFile(param);
tempRaf = new RandomAccessFile(tmpFile, "rw");
fileChannel = tempRaf.getChannel();
long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024
: param.getChunkSize();
//写入该分片数据
long offset = chunkSize * param.getChunk();
byte[] fileData = param.getFile().getBytes();
mappedByteBuffer = fileChannel
.map(FileChannel.MapMode.READ_WRITE, offset, fileData.length);
mappedByteBuffer.put(fileData);
boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath);
return isOk;
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.freedMappedByteBuffer(mappedByteBuffer);
FileUtil.close(fileChannel);
FileUtil.close(tempRaf);
}
return false;
}
}
# 3、文件操作核心模板类代码
@Slf4j
public abstract class SliceUploadTemplate implements SliceUploadStrategy {
public abstract boolean upload(FileUploadRequestDTO param);
protected File createTmpFile(FileUploadRequestDTO param) {
FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class);
param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath()));
String fileName = param.getFile().getOriginalFilename();
String uploadDirPath = filePathUtil.getPath(param);
String tempFileName = fileName + "_tmp";
File tmpDir = new File(uploadDirPath);
File tmpFile = new File(uploadDirPath, tempFileName);
if (!tmpDir.exists()) {
tmpDir.mkdirs();
}
return tmpFile;
}
@Override
public FileUploadDTO sliceUpload(FileUploadRequestDTO param) {
boolean isOk = this.upload(param);
if (isOk) {
File tmpFile = this.createTmpFile(param);
FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile);
return fileUploadDTO;
}
String md5 = FileMD5Util.getFileMD5(param.getFile());
Map<Integer, String> map = new HashMap<>();
map.put(param.getChunk(), md5);
return FileUploadDTO.builder().chunkMd5Info(map).build();
}
/**
* 检查并修改文件上传进度
*/
public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) {
String fileName = param.getFile().getOriginalFilename();
File confFile = new File(uploadDirPath, fileName + ".conf");
byte isComplete = 0;
RandomAccessFile accessConfFile = null;
try {
accessConfFile = new RandomAccessFile(confFile, "rw");
//把该分段标记为 true 表示完成
System.out.println("set part " + param.getChunk() + " complete");
//创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127
accessConfFile.setLength(param.getChunks());
accessConfFile.seek(param.getChunk());
accessConfFile.write(Byte.MAX_VALUE);
//completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传)
byte[] completeList = FileUtils.readFileToByteArray(confFile);
isComplete = Byte.MAX_VALUE;
for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) {
//与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE
isComplete = (byte) (isComplete & completeList[i]);
System.out.println("check part " + i + " complete?:" + completeList[i]);
}
} catch (IOException e) {
log.error(e.getMessage(), e);
} finally {
FileUtil.close(accessConfFile);
}
boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete);
return isOk;
}
/**
* 把上传进度信息存进redis
*/
private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath,
String fileName, File confFile, byte isComplete) {
RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class);
if (isComplete == Byte.MAX_VALUE) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true");
redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5());
confFile.delete();
return true;
} else {
if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) {
redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false");
redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(),
uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf");
}
return false;
}
}
/**
* 保存文件操作
*/
public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) {
FileUploadDTO fileUploadDTO = null;
try {
fileUploadDTO = renameFile(tmpFile, fileName);
if (fileUploadDTO.isUploadComplete()) {
System.out
.println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName);
//TODO 保存文件信息到数据库
}
} catch (Exception e) {
log.error(e.getMessage(), e);
} finally {
}
return fileUploadDTO;
}
/**
* 文件重命名
*
* @param toBeRenamed 将要修改名字的文件
* @param toFileNewName 新的名字
*/
private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) {
//检查要重命名的文件是否存在,是否是文件
FileUploadDTO fileUploadDTO = new FileUploadDTO();
if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) {
log.info("File does not exist: {}", toBeRenamed.getName());
fileUploadDTO.setUploadComplete(false);
return fileUploadDTO;
}
String ext = FileUtil.getExtension(toFileNewName);
String p = toBeRenamed.getParent();
String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName;
File newFile = new File(filePath);
//修改文件名
boolean uploadFlag = toBeRenamed.renameTo(newFile);
fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp());
fileUploadDTO.setUploadComplete(uploadFlag);
fileUploadDTO.setPath(filePath);
fileUploadDTO.setSize(newFile.length());
fileUploadDTO.setFileExt(ext);
fileUploadDTO.setFileId(toFileNewName);
return fileUploadDTO;
}
}
# 总结
在实现分片上传的过程,需要前端和后端配合,比如前后端的上传块号的文件大小,前后端必须得要一致,否则上传就会有问题。其次文件相关操作正常都是要搭建一个文件服务器的,比如使用fastdfs、hdfs等。
本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的md5值计算,后端写入的速度还是比较快。
如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:
https://help.aliyun.com/product/31815.htmlopen in new window
阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
文末提供一个oss表单上传的链接demo,通过oss表单上传,可以直接从前端把文件上传到oss服务器,把上传的压力都推给oss服务器:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









