




urllib是Python内置的HTTP请求库。
请求
urllib.request模块提供了最基本的构造HTTP请求的方法。
-
urlopen()
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
打开一个urlimport urllib.request response = urllib.request.urlopen('http://www.httpbin.org/get') print(response.read().decode('utf-8'))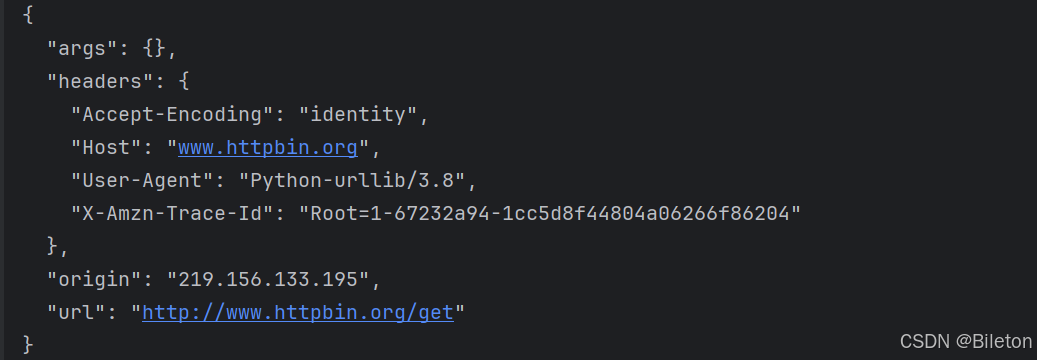
使用type方法输出响应的类型import urllib.request response = urllib.request.urlopen('http://www.httpbin.org/get') print(type(response)) # <class 'http.client.HTTPResponse'>是一个HTTPResponse类型的对象。
-
HTTPResponse对象
HTTPResponse对象有一些方法和属性,如read(),getheaders()等方法,version,status等属性import urllib.request response = urllib.request.urlopen('http://www.httpbin.org/get') print(response.getheaders()) # [('Date', 'Thu, 31 Oct 2024 07:08:57 GMT'), ('Content-Type', 'application/json'), ('Content-Length', '284'), ('Connection', 'close'), ('Server', 'gunicorn/19.9.0'), ('Access-Control-Allow-Origin', '*'), ('Access-Control-Allow-Credentials', 'true')] print(response.version) # 11 print(response.status) # 200 -
data参数
添加该参数,需要将参数转化为字节流编码格式的内容,bytes类型。import urllib.request data = bytes(urllib.parse.urlencode({'name':'Bileton'}),encoding = 'utf-8') response = urllib.request.urlopen('http://www.httpbin.org/post',data) print(response.read().decode('utf-8'))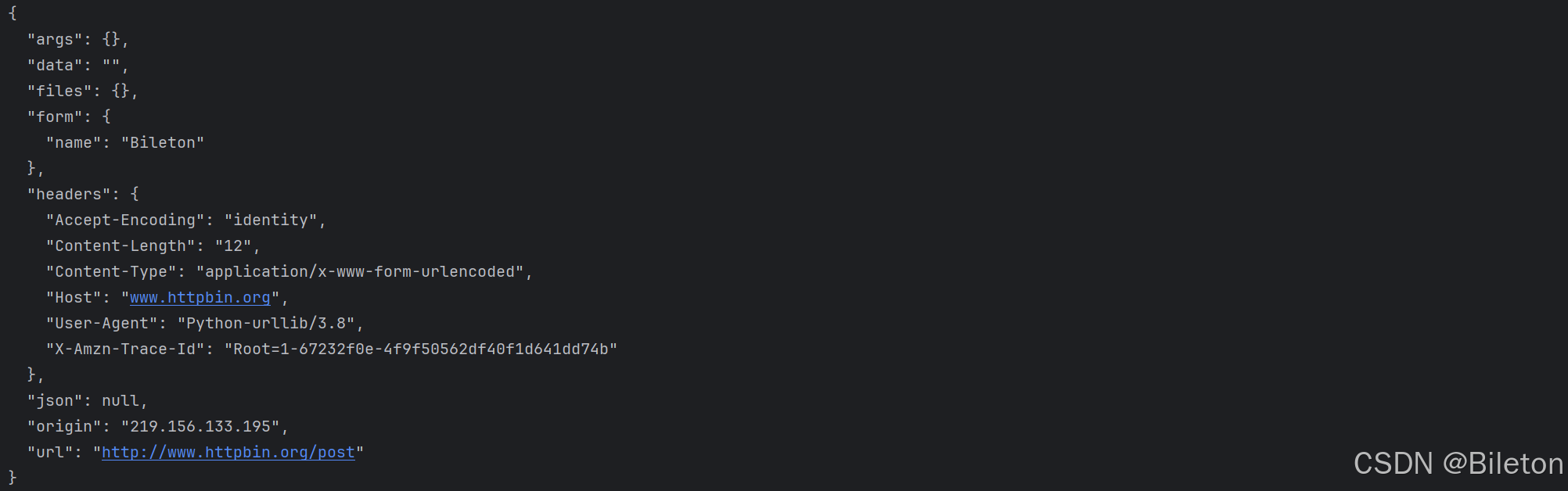
-
timeout参数
设置超时时间import urllib.request response = urllib.request.urlopen('http://www.httpbin.org/get',timeout=1) print(response.read().decode('utf-8')) -
Request
urllib方法可以发起最基本的请求,但它的参数不够完整,Request类可以解决。import urllib.request request = urllib.request.Request("http://www.httpbin.org/get") response = urllib.request.urlopen(request) print(response.read().decode('utf-8'))Request类的构造方法
class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
origin_req_host是请求方的host名称或IP地址
unverifiable表示请求是否是无法验证的,默认取值False。
method是一个字符串,指示请求方法。import urllib.request import urllib.parse url = "http://www.httpbin.org/post" headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)","Host":"www.httpbin.org"} dict = {"name":"Bileton"} data = bytes(urllib.parse.urlencode(dict),encoding = 'utf-8') req = urllib.request.Request(url,data,headers,method="POST") response = urllib.request.urlopen(req) print(response.read().decode('utf-8'))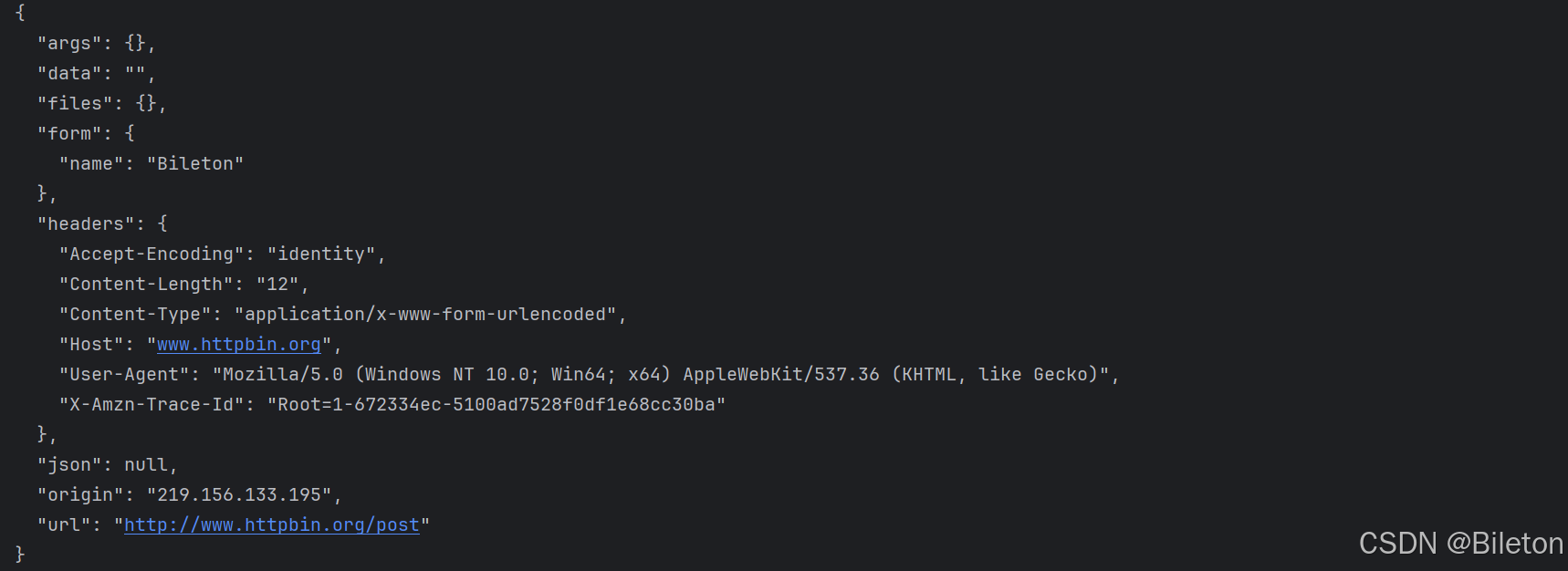
请求类型 Requestimport urllib.request import urllib.parse url = "http://www.httpbin.org/post" headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)","Host":"www.httpbin.org"} dict = {"name":"Bileton"} data = bytes(urllib.parse.urlencode(dict),encoding = 'utf-8') req = urllib.request.Request(url,data,headers,method="POST") print(type(req)) # <class 'urllib.request.Request'> -
Handler
Handler可以理解为各种处理器,有专门处理登录验证的,处理Cookie的,处理代理设置的。BaseHandler类是其他所有Handler类的父类,提供了最基本的方法。 -
OpenerDirector
OpenerDirector可以称之为Opener,之前使用过的urlopen方法就是urllib库提供的Opener。Opener可以实现更高级的功能。Opener类可以提供open方法,利用Handler类来构建Opener类。 -
登录验证
验证的网站:https://ssr3.scrape.center
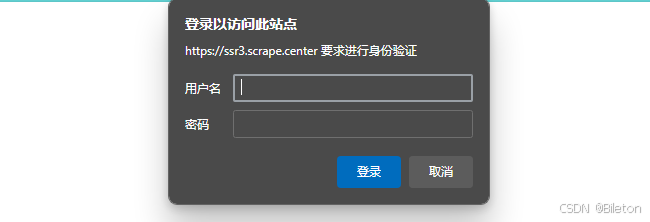
这个网页启用了基本身份认证,英文名称为:HTTP Basic Access Authentication,这是一种登录验证方式,允许网页浏览器或其他客户端程序在请求网站时提供用户名和口令形式的身份凭证。
对于这样的页面,爬虫可以借助HTTPBasicAuthHandler模块完成。from urllib.error import URLError from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener url = "https://ssr3.scrape.center" username = "admin" password = "admin" p = HTTPPasswordMgrWithDefaultRealm() p.add_password(None,url,username,password) auth_handler = HTTPBasicAuthHandler(p) opener = build_opener(auth_handler) try: result = opener.open(url) html = result.read().decode('utf-8') print(html) except URLError as e: print(e.reason)这里是使用
HTTPBasicAuthHandler实例化一个auth_handler对象,参数是HTTPPasswordMgrWithDefaultRealm对象,它利用add_password()方法来添加用户名和密码,构建了一个处理登录验证的Handler类,然后利用build_opener方法构建一个Opener。
处理异常
urllib库中的error模块定义了由request模块产生的异常。
-
URLError
URLError类来自urllib库的error模块,继承自OSError类。from urllib import request, error try: response = request.urlopen("https://cuiqingcai.com/404") except error.URLError as e: print(e.reason)
-
HTTPError
HTTPError是URLError的子类,用来处理HTTP请求错误。
它有三个属性:- code:HTTP状态码
- reason:返回错误原因
- headers:返回请求头
from urllib import request, error try: response = request.urlopen("https://cuiqingcai.com/404") except error.HTTPError as e: print(e.reason,e.code,e.headers,sep="\n") else: # 处理正常的逻辑。 print("Request Seccessfully!")输出为:
Not Found 404 Connection: close Content-Length: 9379 Server: GitHub.com Content-Type: text/html; charset=utf-8 Access-Control-Allow-Origin: * ETag: "64d39a40-24a3" Content-Security-Policy: default-src 'none'; style-src 'unsafe-inline'; img-src data:; connect-src 'self' x-proxy-cache: MISS X-GitHub-Request-Id: 80EE:2B9D99:2D2C57C:2E7A1AF:67273E60 Accept-Ranges: bytes Age: 382 Date: Sun, 03 Nov 2024 09:18:23 GMT Via: 1.1 varnish X-Served-By: cache-lin1730043-LIN X-Cache: HIT X-Cache-Hits: 0 X-Timer: S1730625503.444448,VS0,VE1 Vary: Accept-Encoding X-Fastly-Request-ID: 72b761b1f690ecdb8d0b860da3708e9eb6b4c8a7 -
timeout
from urllib import request, error try: response = request.urlopen("https://cuiqingcai.com/404",timeout=0.01) except error.URLError as e: print(type(e.reason)) if isinstance(e.reason,socket.timeout): print("TIME OUT") else: print("Request Seccessfully!")
解析链接
urllib提供了parse模块,它定义了处理URL的标准接口。
-
urlparse
from urllib.parse import urlparse url = "https://www.baidu.com/index.html;user?id=5#comment" result = urlparse(url) print(type(result)) print(result)
urlparse方法的API用法
urllib.parse.urlparse(urlstring,scheme=' ',allow_fragments=True)- urlstring:待解析的URL。
- scheme:默认的协议,如果待解析的URL没有携带协议信息,就将这个作为默认协议。
- allow_fragment:是否忽略fragment。如果设置为False,那么fragment部分就会被忽略。
-
urlunparse
urlunparse用于构造URL。接受的参数是一个可迭代对象,长度必须是6,否则会报错。from urllib.parse import urlunparse data = ["https","www.baidu.com","index.html","user","a=6","comment"] url = urlunparse(data) print(url)
-
urlsplit
和urlparse方法类似,它不是单独解析params这部分(把它params会合并到path中),返回5个结果。from urllib.parse import urlsplit url = "https://www.baidu.com/index.html;user?id=5#comment" result = urlsplit(url) print(result)
-
urlunsplit
from urllib.parse import urlunsplit data = ["https","www.baidu.com","index.html","id=5","comment"] url = urlunsplit(data) print(url)
-
urljoin
这个方法需要两个参数,第一个参数是基础链接(base_url),新的链接是第二个参数。urljoin方法会分析base_url的scheme、netloc和path这三个内容,并对新链接缺失的部分进行补充,返回结果。

















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









