







什么是Spark RDD?(RDD的介绍与创建)
一、RDD介绍
RDD: 弹性分布式数据集(Resilient Distributed Datasets)
核心概念:Spark的核心数据抽象。
通过对RDD的理解和使用,可以在分布式计算环境中高效地处理和计算大规模数据
1、特点
- 分布式数据集:RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上。RDD并不存储真正的数据,只是对数据和操作的描述。
- 弹性:默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘。
- 容错性:根据数据血统,可以自动从节点失败中恢复分区。
2、RDD的存储和指向
- 存储在 (HIVE)HDFS、Cassandra、HBase等
- 缓存(内存、内存+磁盘、仅磁盘等)
- 或在故障或缓存收回时重新计算其他RDD分区中的数据
3、RDD与DAG
-
DAG(有向无环图):反映了RDD之间的依赖关系。
-
Stage:RDD和DAG是Spark提供的核心抽象,RDD的操作会生成DAG,DAG会进一步被划分为多个Stage,每个Stage包含多个Task。
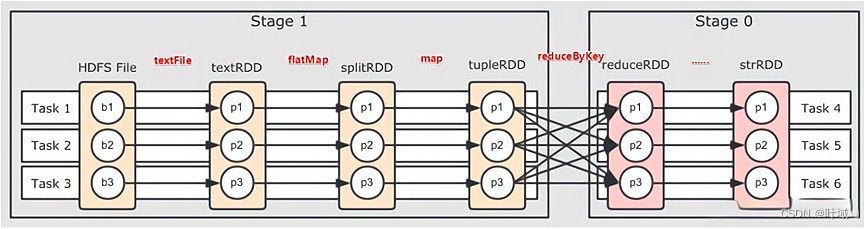
4、RDD的特性
- 分区(Partition):每个任务处理一个分区。
- 计算函数(compute):每个分区上都有compute函数,计算该分区中的数据。
- 依赖关系:RDD之间有一系列的依赖。
- 分区器(Partitioner)
- 决定数据(key-value)分配至哪个分区。
- 常见的分区器有Hash Partition和Range Partition。
- 优先位置列表:将计算任务分派到其所在处理数据块的存储位置。
5、RDD分区
- 分区(Partition):是RDD被拆分并发送到节点的不同块之一。
- 分区越多,并行性越强:我们拥有的分区越多,得到的并行性就越强。
- 每个分区都是被分发到不同Worker Node的候选者。
- 每个分区对应一个Task。
6、RDD操作类型
- Transformation(转换操作)
- Lazy操作:不会立即执行,只是记录操作,当触发Action时才会真正执行。
- 例如:map、filter、flatMap等。
- Actions(动作操作)
- Non-lazy操作:立即执行,会触发所有相关Transformation的计算。
- 例如:count、collect、saveAsTextFile等。
二、RDD创建
1、引入必要的 Spark 库
这里用的是scala语言的maven项目
<!-- 导入 spark-core jar 包 -->
<dependency>
<groupId>org.apache.spark 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8339
8339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









