







Redis最佳设计
Redis键值设计
key结构
* 格式: [业务名称]:[数据名]:[id] `login:user:10` + 优点: 可读性强 ; 避免key冲突 ; 方便管理 * 长度不超过44字节 键和值都是string类型,底层的编码方式是一样的,底层编码包括int,embstr,raw三种,embstr小于44字节,采用连续内存空间,内存占用小 * 不包含特殊字符BigKey
避免BigKey(Key大小和成员数量判定)推荐值:
- 单个key的value小于10kb
- 对于集合类,元素数量小于1000
危害:
- 网络阻塞
- 数据倾斜
- Redis阻塞
- CPU压力
发现BigKey
- redis-cli --bigkeys但是只能显示每一个的最大值
- scan扫描 利用strlen,hlen,自定义
- 第三方工具
- 网络监控
删除BigKey
- 4.0以后 unlink异步删除
恰当的数据类型
json字符串简单粗暴
数据耦合不够灵活
字段打散
可以访问对象任意字段
占用空间大,没办法统一控制
hash
底层使用ziplist,空间占用小,灵活(entry>1000使用hash表内存占用多,可以对大hash进行拆分)
代码复杂
批处理优化
Pipeline
**单个命令执行流程:(网络运输耗时太多)**一次命令响应时间 = 1次往返的网络传输耗时+1次Redis执行命令耗时
N个命令批量执行(速度快)
一次命令响应时间 = 1次往返的网络传输耗时+N次Redis执行命令耗时
但是一次批处理不能传输太多命令,否则单次命令占用带宽过多,会导致网络阻塞
Pipeline
MSET虽然能批处理但是只能操作少部分数据类型,对复杂数据类型用Pipeline
不能一次携带太多命令
多个命令之间不具备原子性
集群下批处理
集群下处理命令的多个key必须落在同一个插槽,否则就会执行失败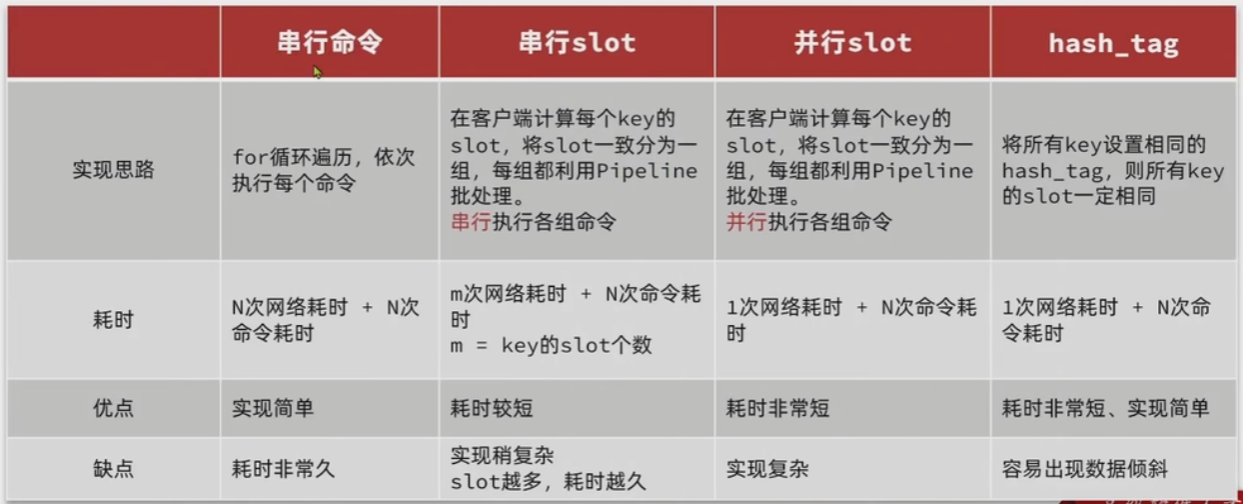
服务端配置
持久化配置
能保证数据安全但是增加开销 * 用来做缓存的Redis实例不要开启持久化功能
* 使用AOF持久化
* 利用脚本定期在slave节点做RDB,实现数据备份
* 合理设置rewrite阈值
* 配置no-appendfsync-on-rewrite=yes禁止在rewrite期间做aof,避免因AOF引起的阻塞(为了性能)
慢查询
在Redis执行时耗时超过某个阈值的命令阈值通过配置:
slowlog-log-slower-than:慢查询阈值默认10000微秒,建议1000
slowlog-max-len:慢查询日志默认128,建议1000
慢查询日志查询
slowlog len:查询慢查询日志长度
showlog get[n]:读取n条
slowlog reset:清空
内存配置
导致Key被频繁删除,响应时间过长
info memory查看Redis内存分配状态
memory xxx
内存缓冲区配置:
复制缓冲区:默认1mb避免频繁全量复制
AOF缓冲区:AOF刷盘之前的缓存区
客户端缓冲区:重点问题,分为输入和输出缓冲区,输入缓冲区最大1G而且不能设置,输出缓冲区可以设置

集群最佳实践
集群完整性:默认配置:一个插槽不可用整个集群都停止服务解决:将cluster-require-full-coverage配置为 false

Redis原理篇
数据结构
动态字符串(Simple Dynamic String)
key,value往往是字符串或者字符串集合,Redis最常用的一种数据结构,虽然Redis是C语言实现的,但是C语言字符串有一定问题(获取字符串长度需要运算,非二进制安全,不可修改),所以Redis构建了一种新的字符串结构,SDSuint:无符号整型
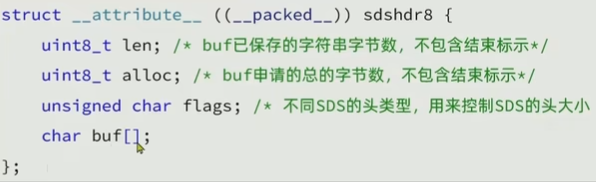

/0是为了和C语言匹配,但是其实是通过看len = 多少来读,有多少读多少
可以动态扩容

+1指的是结束标识,所以alloc值还是是两倍(预分配)
IntSet
**Intset概念,结构**Redis中set集合的实现,基于整数数组实现,具备长度可变,有序的特征
头部固定8个字节

数组从零开始索引是为了性能,黑框里面是寻址公式,如果索引从1开始每次都要-1,性能下降
IntSet升级
当数字超过范围,IntSet自动升级编码方式到合适大小
升级编码后,倒序拷贝到扩容后的位置,将待插入元素放入数组末尾,length属性改变

Dict
Redis是一个键值型数据库,我们可以通过键快速增删改查,映射关系通过Dict实现Dict组成:哈希表(DictHashTable),哈希节点(DictEntry),字典(Dict)

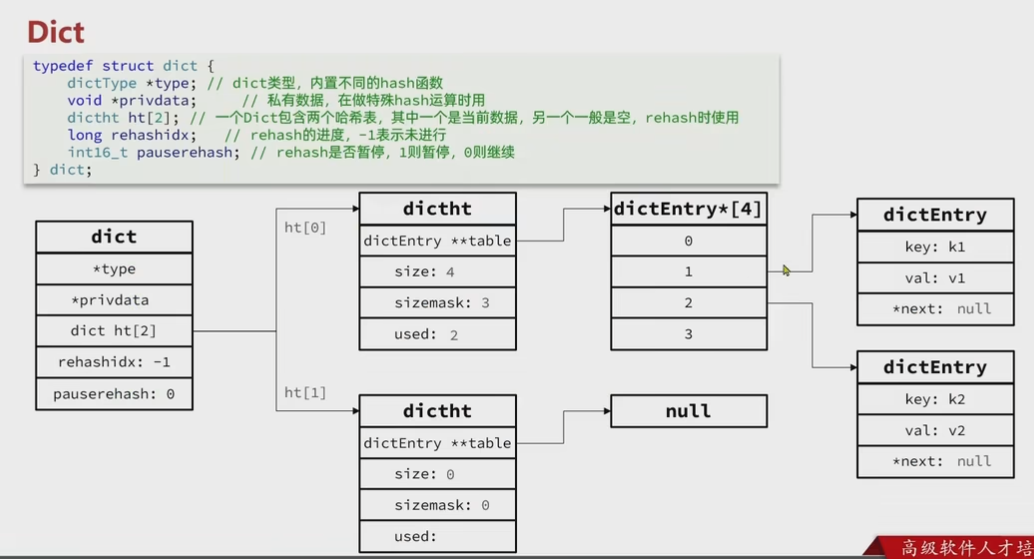
Dict的HashTable就是数组结合单向列表的实现,元素多时,必然导致哈希冲突增多,链表过长,查询效率大大降低
触发哈希表扩容的两种情况

LoadFactor<0.1收缩

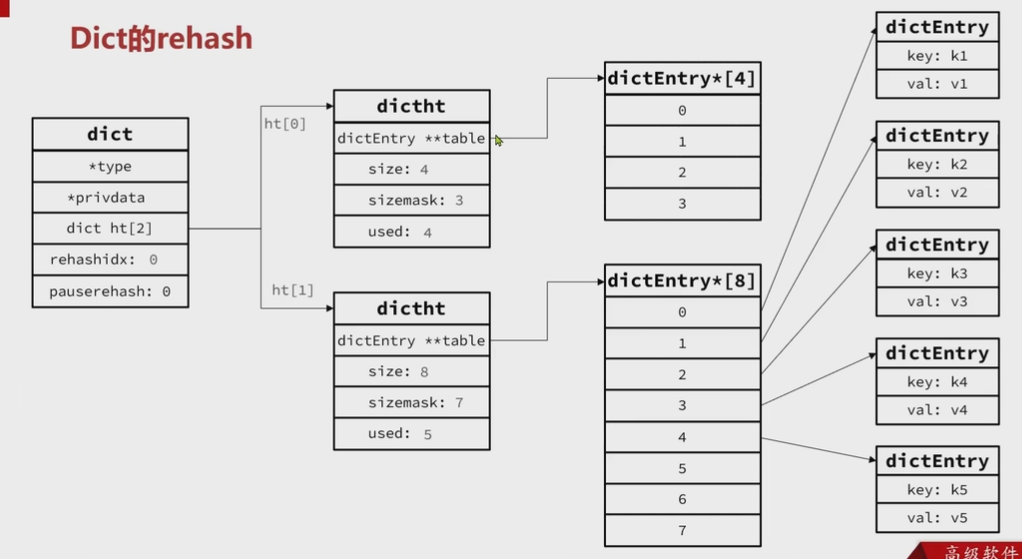 -》
-》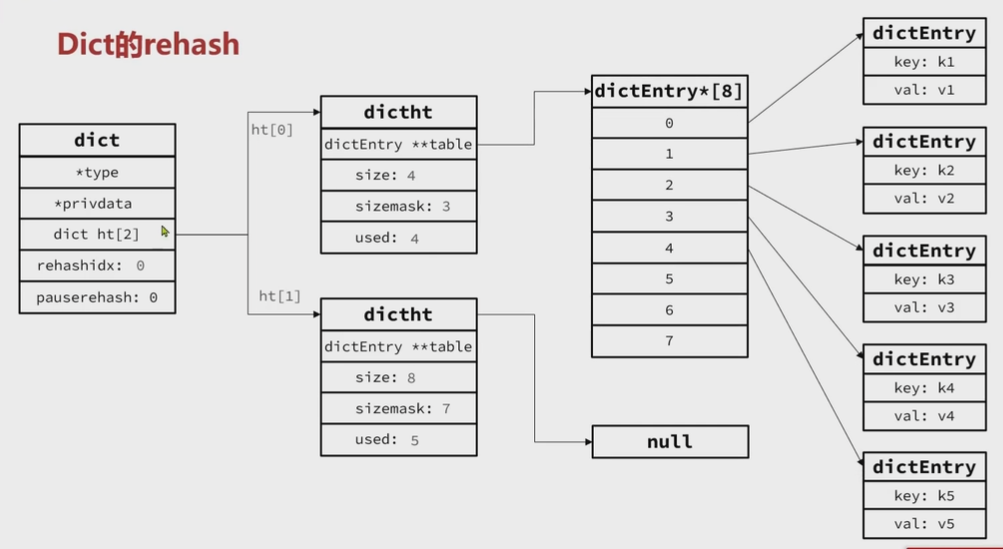
渐进式Rehash

ZipList
可以看做特殊的双端列表,不是列表但是可以进行双端列表的操作,连续的内存空间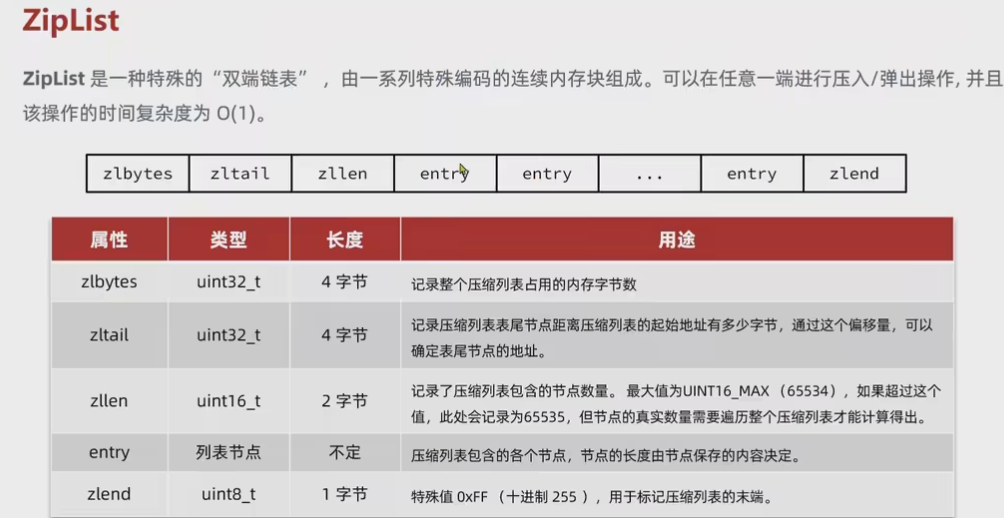

连续内存更新,连续多次空间扩展操作:连锁更新。新增删除可能导致
QuickList
ZIplist没办法解决大量数据, 虽然节约内存但是必须连续内存,如果内存占用多,申请内存效率低 ->限制长度和entry大小为了存储大量数据,我们可以创建多个ZipList来分片存储数据,但是拆分后很难查找管理,通过使用QuickList,他是一个双端链表,每一个节点都是ZipList
QuickList 通过list-max-ziplist-size来限制,通过list-compress-depth控制压缩
SkipList
是链表但是有差异 + 元素按照升序排列存储
+ 包含多个指针,跨度不同
RedisObject
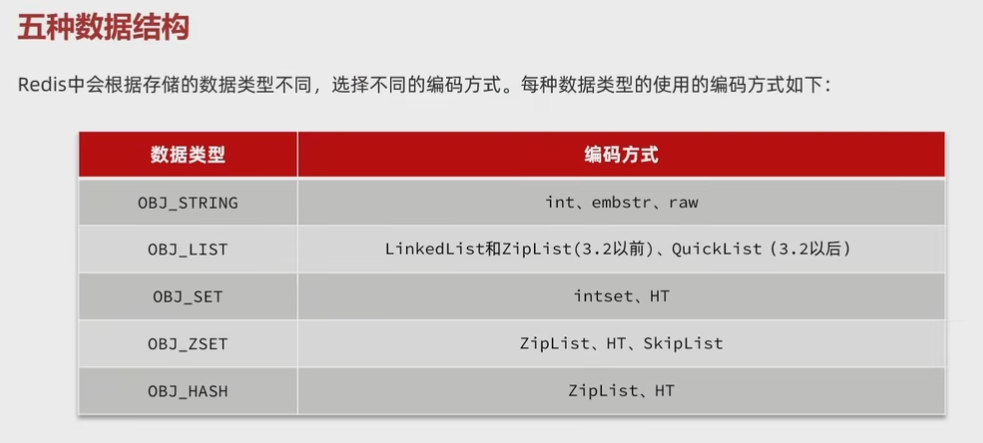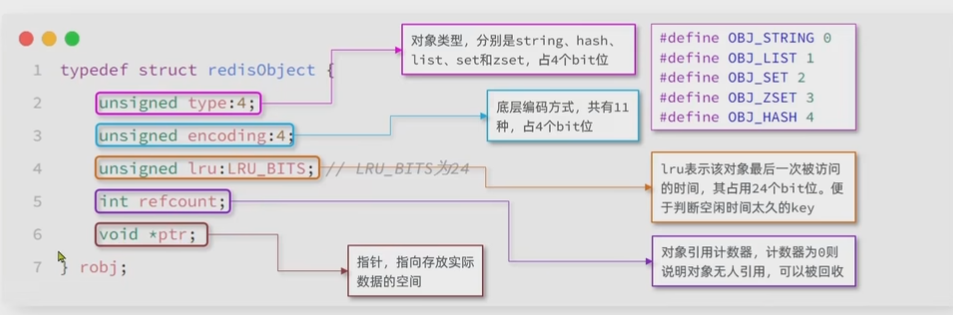
五种数据类型
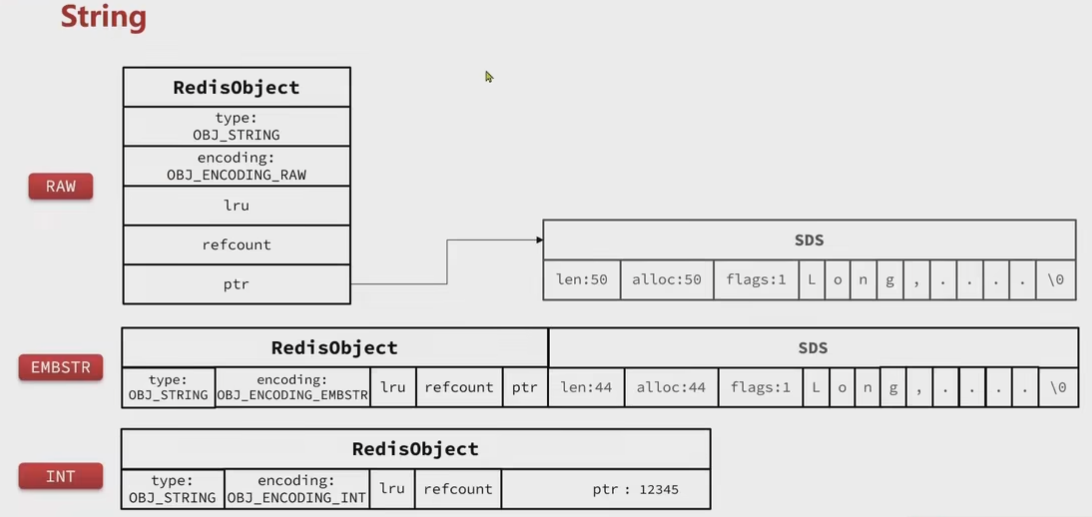
String
RAW编码形式,基于简单动态字符串SDS实现,存储上限512MB。SDS长度小于44字节,使用EMBSTR编码,此时object和SDS是连续空间,调用只需要一次分配内存
如果字符串时整数,大小在LONG_MAX范围内,采用int编码,直接保存在ptr中
List
C源码没看懂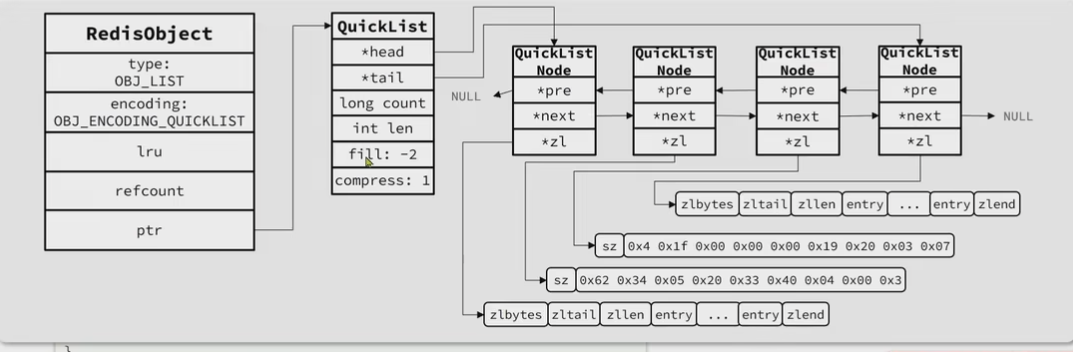
Set
对查询效率要求高 - 不保证有序性
- 数据唯一
- 求交并差
使用Dict,key用来存储数据,value设置为null,如果都是整数可以用IntSet

















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









