







 超级会员免费看
超级会员免费看
第一部分:解决的问题
深度神经网络中存在多个最小值(minima),这些最小值对应的模型在训练数据上表现良好,但在未见过的数据(测试数据)上表现差异很大,即泛化能力不同。
具体例子: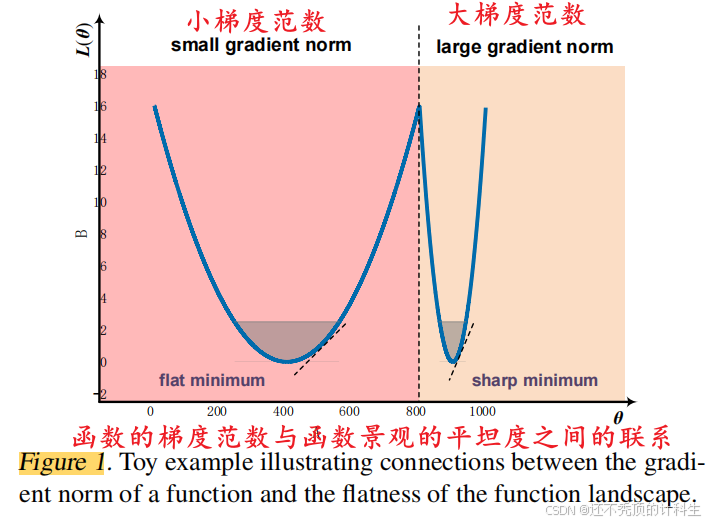

第二部分:idea
论文提出的惩罚梯度范数的方法,目的是引导优化器找到那些具有更好泛化能力的最小值。
论文提出了一种新的正则化方法,通过惩罚梯度范数来改善模型的泛化能力。
-
惩罚梯度范数:在这篇论文中,除了优化常见的损失函数外,作者还提出对损失函数的一个特定属性——梯度范数施加额外的惩罚。
-
寻找平坦最小值的动机:惩罚损失函数的梯度范数的动机是

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











