







第一部分:张量的保存与加载
(1)创建保存的文件路径
在jupyter notebook当前运行目录下创建一个model文件夹。
(2)一个数的保存与加载
①创建
import torch
# 生成一个随机张量
a = torch.rand(6)
a
②保存
# 保存张量到指定路径
torch.save(a, "model/tensor_a")
③加载
# 加载张量
a = torch.load("model/tensor_a",weights_only=True)
a
![]()
(3)多个数的保存与加载
①创建
# 生成多个随机张量
a = torch.rand(6)
b = torch.rand(6)
c = torch.rand(6)
# 显示张量列表
[a, b, c]

②保存
# 保存多个张量到指定路径
torch.save([a, b, c], "model/tensor_abc")
③加载
# 加载保存的张量
torch.load("model/tensor_abc",weights_only=True)

(4)多个字典数的保存与加载
①创建
# 创建一个包含张量的字典
tensor_dict = {'a': a, 'b': b, 'c': c}
tensor_dict

②保存
# 保存张量字典到指定路径
torch.save(tensor_dict, "model/tensor_dict_abc")
③加载
# 加载保存的张量字典
loaded_dict = torch.load("model/tensor_dict_abc",weights_only=True)
loaded_dict

第二部分:模型的保存与加载
一个模型中包含大量的张量。
(1)创建一个多层感知机MLP的模型
from torchvision import datasets
from torchvision import transforms
import torch.nn as nn
import torch.optim as optim
# 定义 MLP 网络,继承 nn.Module
class MLP(nn.Module):
# 初始化方法
# input_size 输入数据的维度
# hidden_size 隐藏层节点大小
# num_classes 输出分类的数量
def __init__(self, input_size, hidden_size, num_classes):
super(MLP, self).__init__()
# 定义第1个全连接层
self.fc1 = nn.Linear(input_size, hidden_size)
# 定义激活函数
self.relu = nn.ReLU()
# 定义第2个全连接层
self.fc2 = nn.Linear(hidden_size, hidden_size)
# 定义第3个全连接层
self.fc3 = nn.Linear(hidden_size, num_classes)
# 定义 forward 函数
# x 输入的数据
def forward(self, x):
# 输入经过 fc1
out = self.fc1(x)
# 使用 ReLU 激活函数
out = self.relu(out)
# 通过 fc2 并再次激活
out = self.fc2(out)
out = self.relu(out)
# 将上一步结果传递给 fc3
out = self.fc3(out)
# 返回结果
return out
# 定义参数
input_size = 28 * 28 # 输入大小
hidden_size = 512 # 隐藏层大小
num_classes = 10 # 输出大小(类别数)
# 初始化 MLP
model = MLP(input_size, hidden_size, num_classes)
(2)方法1-保存和加载模型参数
①保存模型参数
torch.save(model.state_dict(), "model/mlp_state_dict.pth")
 ②加载模型参数
②加载模型参数
# 读取保存的模型参数
mlp_state_dict = torch.load("model/mlp_state_dict.pth",weights_only=True)
# 新实例化一个 MLP 模型
model_load = MLP(input_size, hidden_size, num_classes)
# 调用 load_state_dict 方法,载入读取的参数
model_load.load_state_dict(mlp_state_dict)
![]()
(3)方法2-保存和加载整个模型(不太推荐,因为一旦修改路径位置,就会报错)
①保存模型参数
torch.save(model, "model/mlp_model.pth")
 ②加载模型参数
②加载模型参数
mlp_load = torch.load("model/mlp_model.pth",weights_only=True)
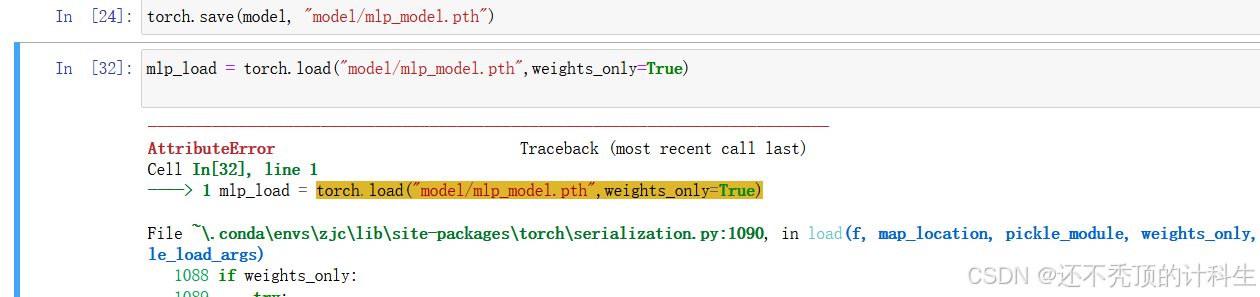
而且这种目前在我的电脑上也已经不能用了,所以大家不要用方法2,知道有这个方法就行了。
(4)方法3-checkpoint(保存的形式是字典)
这个的优点就是如果我们在训练过程中由于某些原因导致训练终止,那么我们就可以接着原先的继续训练。
①保存模型和优化器的状态
import torch
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设这些变量是在训练过程中计算得到的
epoch = 5
loss = 0.35 # 假设这是当前损失值
# 保存检查点
checkpoint_path = "model/mlp_checkpoint.pth"
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss
}, checkpoint_path)
②加载模型和优化器的状态
# 重新实例化模型和优化器
model = MLP(input_size, hidden_size, num_classes)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 加载检查点
checkpoint = torch.load(checkpoint_path,weights_only=True)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
# 切换模型到评估模式(如果需要继续训练,可以忽略这行)
model.eval()
print(f"模型加载成功,当前 epoch 为 {epoch},损失值为 {loss}")




















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











