







第一部分:需求分析
本篇是为了研究使用神经网络一个非线性回归问题,即拟合一个具有二次关系的合成数据集。数据集的目标是通过不同的神经网络模型来预测一个变量(x)和其平方的关系(即 y = x^2 + 1,并带有一定的噪声)。探讨通过训练和评估不同复杂度的神经网络模型来分析模型的拟合能力,以及如何通过模型结构来控制欠拟合、正常拟合和过拟合的问题。
第二部分:三种神经网络的参数详解


第三部分:损失函数和优化器
损失函数使用的是MSE均方误差
优化器受用的是梯度下降
第四部分:代码实现
(1)导包
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
(2)导入数据集
# 设置随机数种子
np.random.seed(32)
# 生成满足 y = x^2 + 1 的数据集
num_samples = 100 # 100个样本点
X = np.random.uniform(-5, 5, (num_samples, 1)) # 生成均匀分布
Y = X ** 2 + 1 + 5 * np.random.normal(0, 1, (num_samples, 1)) # 正态分布噪声
# 将 NumPy 数组转化为 PyTorch 张量
X = torch.from_numpy(X).float()
Y = torch.from_numpy(Y).float()
# 绘制数据点图像
plt.scatter(X, Y)
plt.show()
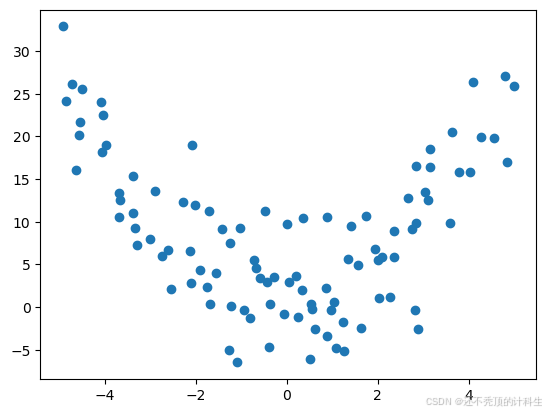
(3)划分数据集
# 将数据集分为训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.3, random_state=0)
# 将数据封装成批量处理格式
train_dataloader = DataLoader(TensorDataset(train_X, train_Y), batch_size=32, shuffle=True)
test_dataloader = DataLoader(TensorDataset(test_X, test_Y), batch_size=32, shuffle=False)
(4)定义三种模型(欠拟合+正常拟合+过拟合)
class LinearRegression(nn.Module):#欠拟合
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
class MLP(nn.Module):#正常拟合
def __init__(self):
super().__init__()
self.hidden = nn.Linear(1, 8)
self.output = nn.Linear(8, 1)
def forward(self, x):
x = torch.relu(self.hidden(x))
return self.output(x)
class MLPOverfitting(nn.Module):#过拟合
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(1, 256)
self.hidden2 = nn.Linear(256, 256)
self.output = nn.Linear(256, 1)
def forward(self, x):
x = torch.relu(self.hidden1(x))
x = torch.relu(self.hidden2(x))
return self.output(x)
(5)辅助函数(训练模型并计算损失函数和反向传播优化)
def plot_errors(models, num_epochs, train_dataloader, test_dataloader):
loss_fn = nn.MSELoss()
train_losses = []
test_losses = []
for model in models:
optimizer = torch.optim.SGD(model.parameters(), lr=0.005)
train_losses_per_model = []
test_losses_per_model = []
for epoch in range(num_epochs):
model.train()
train_loss = 0
for inputs, targets in train_dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_dataloader)
train_losses_per_model.append(train_loss)
model.eval()
test_loss = 0
with torch.no_grad():
for inputs, targets in test_dataloader:
outputs = model(inputs)
loss = loss_fn(outputs, targets)
test_loss += loss.item()
test_loss /= len(test_dataloader)
test_losses_per_model.append(test_loss)
train_losses.append(train_losses_per_model)
test_losses.append(test_losses_per_model)
return train_losses, test_losses
#开始调用函数
num_epochs = 200
models = [LinearRegression(), MLP(), MLPOverfitting()]
train_losses, test_losses = plot_errors(models, num_epochs, train_dataloader, test_dataloader)
(6)绘图展示(训练轮数和损失值的变化情况)
from pylab import mpl
# 设置中文显示字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 绘制训练和测试误差曲线
for i, model in enumerate(models):
plt.figure(figsize=(8, 4))
plt.plot(range(num_epochs), train_losses[i], label=f"Train {model.__class__.__name__}")
plt.plot(range(num_epochs), test_losses[i], label=f"Test {model.__class__.__name__}")
plt.legend()
plt.xlabel('训练轮数') # 正确的函数是 xlabel
plt.ylabel('均方误差') # 正确的函数是 ylabel
plt.ylim((0, 200))
plt.show()
①欠拟合图像
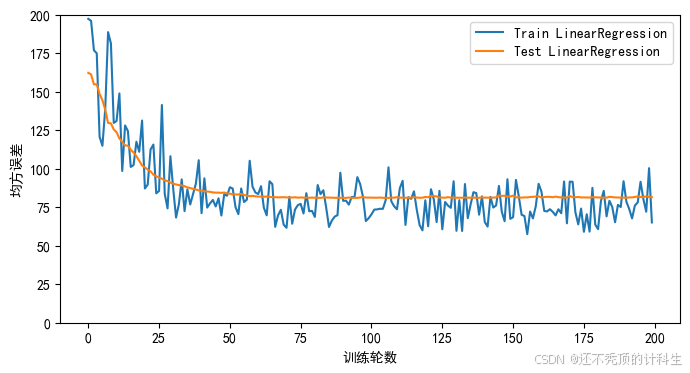
可以看到,模型在训练集上始终拟合较慢,而且训练集和测试集的图像偏差较大
②正常拟合图像
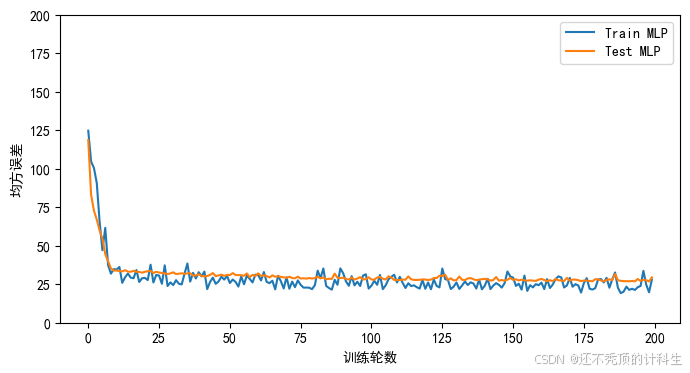
可以看到,训练效果在训练集和测试集上都非常好,而且没有明显的抖动
③过拟合图像
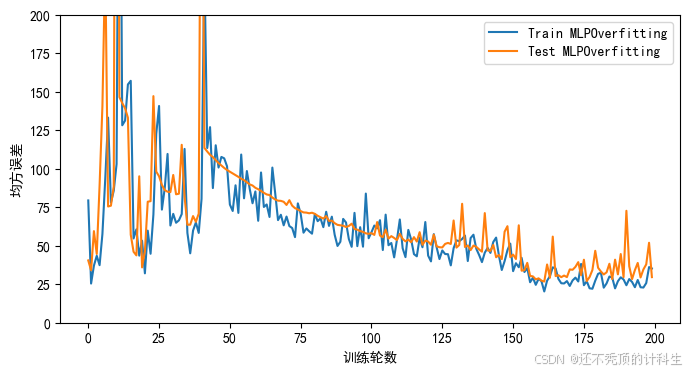
可以看到,在测试集上,数据的误差出现了大幅度的抖动
(7)完整pycharm代码汇总
# 第一部分:导包
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
# 第二部分:获取数据集
# 设置随机数种子
np.random.seed(32)
# 生成满足 y = x^2 + 1 的数据集
num_samples = 100 # 100个样本点
X = np.random.uniform(-5, 5, (num_samples, 1)) # 生成均匀分布
Y = X ** 2 + 1 + 5 * np.random.normal(0, 1, (num_samples, 1)) # 正态分布噪声
# 将 NumPy 数组转化为 PyTorch 张量
X = torch.from_numpy(X).float()
Y = torch.from_numpy(Y).float()
# 绘制数据点图像
plt.scatter(X, Y)
plt.show()
# 第三部分:划分数据集
# 将数据集分为训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.3, random_state=0)
# 将数据封装成批量处理格式
train_dataloader = DataLoader(TensorDataset(train_X, train_Y), batch_size=32, shuffle=True)
test_dataloader = DataLoader(TensorDataset(test_X, test_Y), batch_size=32, shuffle=False)
# 第四部分:模型定义
class LinearRegression(nn.Module):#欠拟合
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
class MLP(nn.Module):#正常拟合
def __init__(self):
super().__init__()
self.hidden = nn.Linear(1, 8)
self.output = nn.Linear(8, 1)
def forward(self, x):
x = torch.relu(self.hidden(x))
return self.output(x)
class MLPOverfitting(nn.Module):#过拟合
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(1, 256)
self.hidden2 = nn.Linear(256, 256)
self.output = nn.Linear(256, 1)
def forward(self, x):
x = torch.relu(self.hidden1(x))
x = torch.relu(self.hidden2(x))
return self.output(x)
# 第五部分:辅助函数
def plot_errors(models, num_epochs, train_dataloader, test_dataloader):
loss_fn = nn.MSELoss()
train_losses = []
test_losses = []
for model in models:
optimizer = torch.optim.SGD(model.parameters(), lr=0.005)
train_losses_per_model = []
test_losses_per_model = []
for epoch in range(num_epochs):
model.train()
train_loss = 0
for inputs, targets in train_dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_dataloader)
train_losses_per_model.append(train_loss)
model.eval()
test_loss = 0
with torch.no_grad():
for inputs, targets in test_dataloader:
outputs = model(inputs)
loss = loss_fn(outputs, targets)
test_loss += loss.item()
test_loss /= len(test_dataloader)
test_losses_per_model.append(test_loss)
train_losses.append(train_losses_per_model)
test_losses.append(test_losses_per_model)
return train_losses, test_losses
#开始调用函数
num_epochs = 200
models = [LinearRegression(), MLP(), MLPOverfitting()]
train_losses, test_losses = plot_errors(models, num_epochs, train_dataloader, test_dataloader)
# 第六部分:可视化展示
from pylab import mpl
# 设置中文显示字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 绘制训练和测试误差曲线
for i, model in enumerate(models):
plt.figure(figsize=(8, 4))
plt.plot(range(num_epochs), train_losses[i], label=f"Train {model.__class__.__name__}")
plt.plot(range(num_epochs), test_losses[i], label=f"Test {model.__class__.__name__}")
plt.legend()
plt.xlabel('训练轮数') # 正确的函数是 xlabel
plt.ylabel('均方误差') # 正确的函数是 ylabel
plt.ylim((0, 200))
plt.show()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











