






文章目录
目录
前言
哨兵模式保证了系统的高可用. 但是真正用来存储数据的还是 数据(master 和 slave) 节点. 所有的数据都需要存储在单个 master 和 slave 节点中. 如果数据量很大, 接近超出了 master / slave 所在机器的物理内存, 就可能出现严重问题了
Redis集群
Redis 的集群就是引入多组 Master / Slave , 每一组 Master / Slave 存储数据全集的一部分, 从而构成一个更大的整体, 称为 Redis 集群 (Cluster).
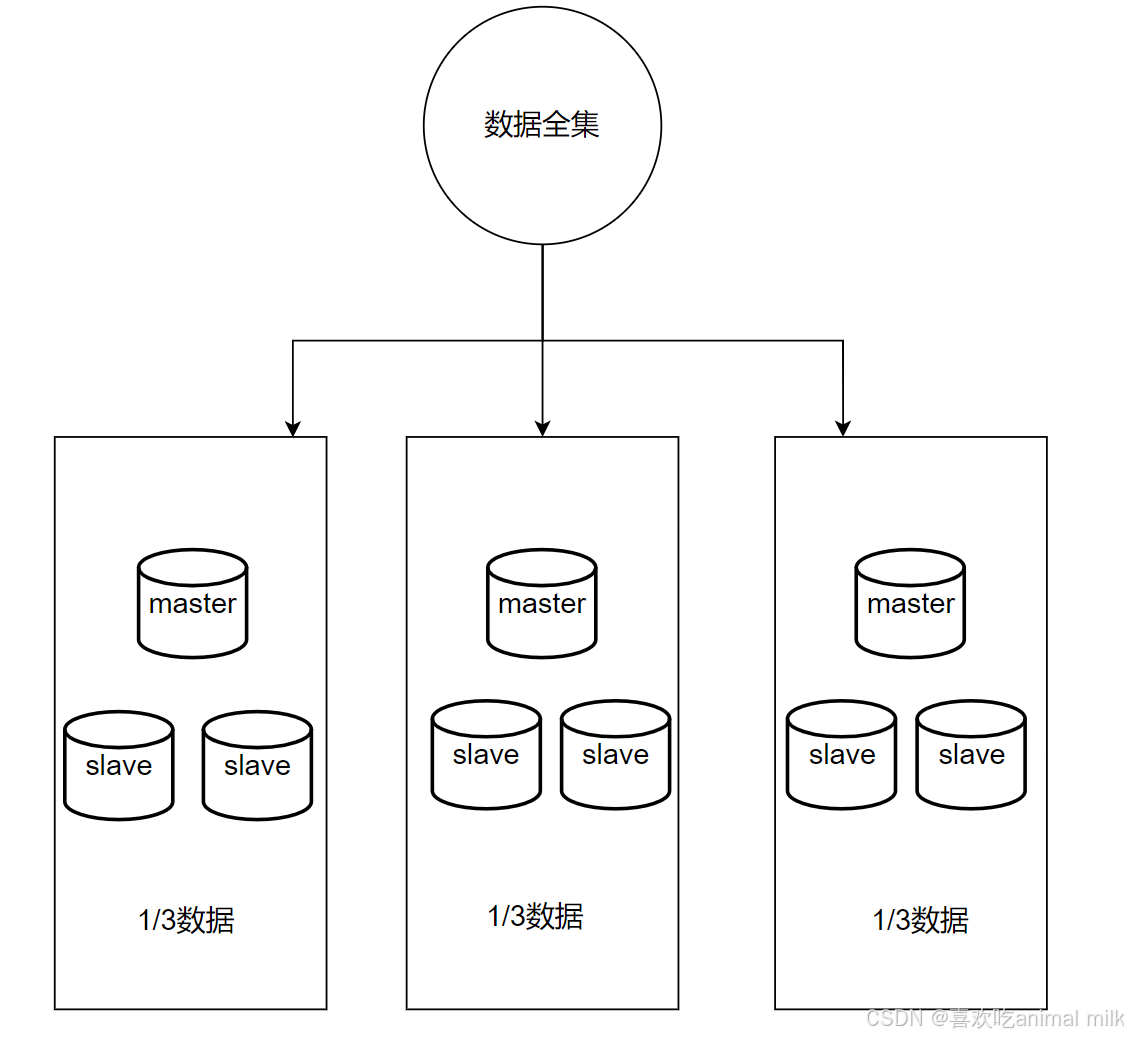
- Master1 和 Slave11 和 Slave12 保存的是同样的数据. 占总数据的 1/3
- Master2 和 Slave21 和 Slave22 保存的是同样的数据. 占总数据的 1/3
- Master3 和 Slave31 和 Slave32 保存的是同样的数据. 占总数据的 1/3
每个部分都可以称为是一个 分片 (Sharding). 如果全量数据进一步增加, 只要再增加更多的分片, 即可解决。
数据分片算法
Redis cluster 的核心思路是用多组机器来存数据的每个部分. 那么接下来的核心问题就是, 给定一个数 据 (⼀个具体的 key), 那么这个数据应该存储在哪个分片上? 读取的时候又应该去哪个分片读取?
1) 哈希求余
设有 N 个分片, 使用 [0, N-1] 这样序号进行编号.
针对某个给定的 key, 先计算 hash 值, 再把得到的结果 % N, 得到的结果即为分片编号.
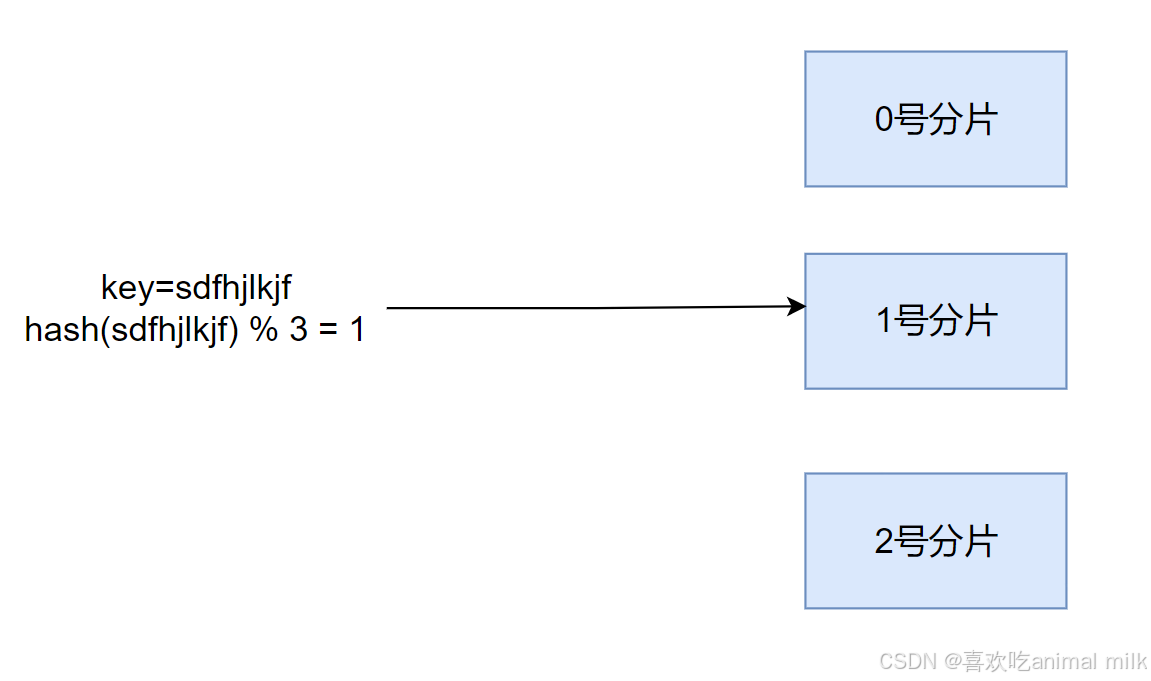
优点: 简单高效, 数据分配均匀
缺点: 扩容时数据搬运多,开销大
2) 一致性哈希
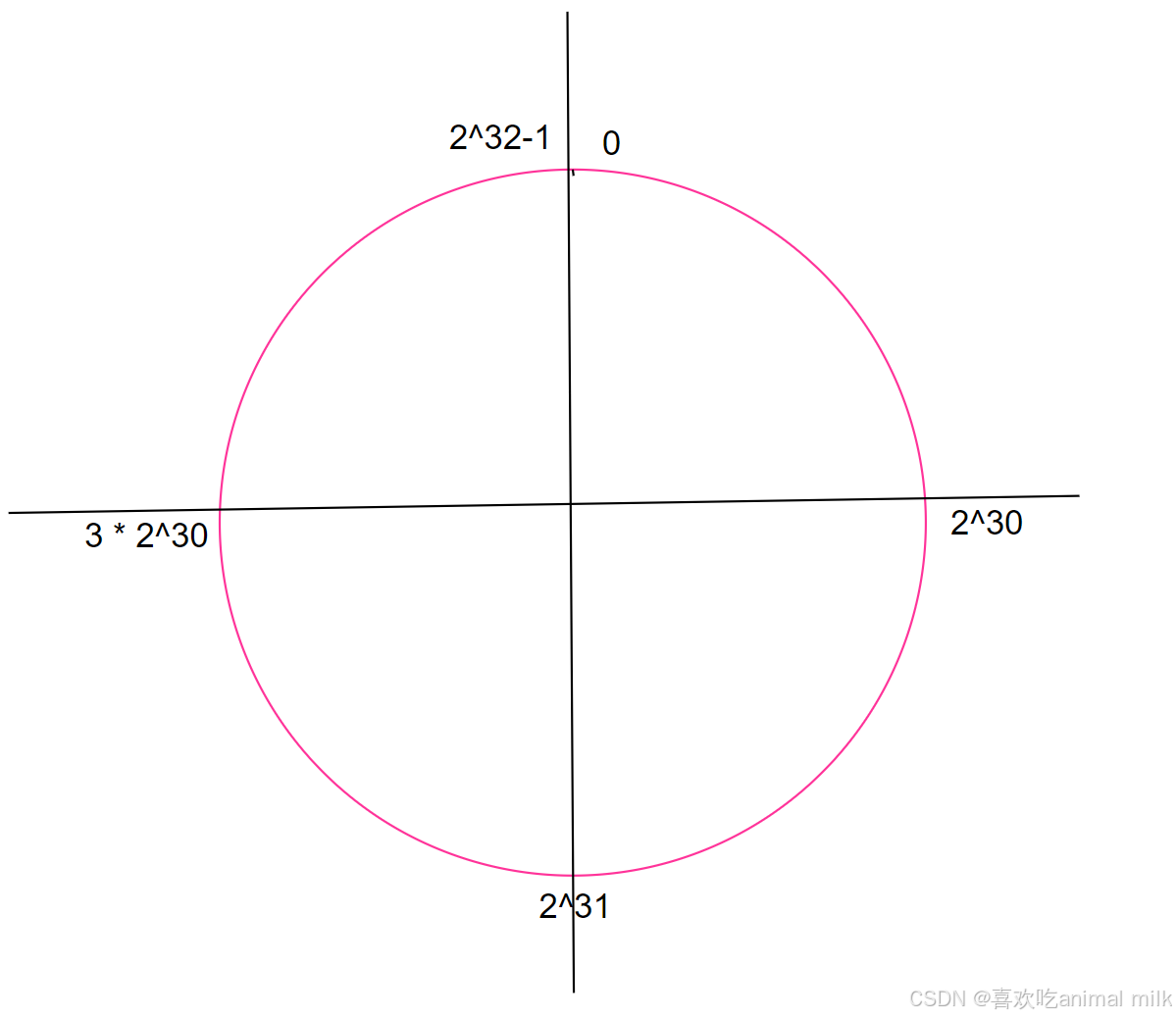
第⼀步, 把 0 -> 2^32-1 这个数据空间, 映射到一个圆环上. 数据按照顺时针方向增长.
第二步, 假设当前存在三个分片, 就把分片放到圆环的某个位置上.
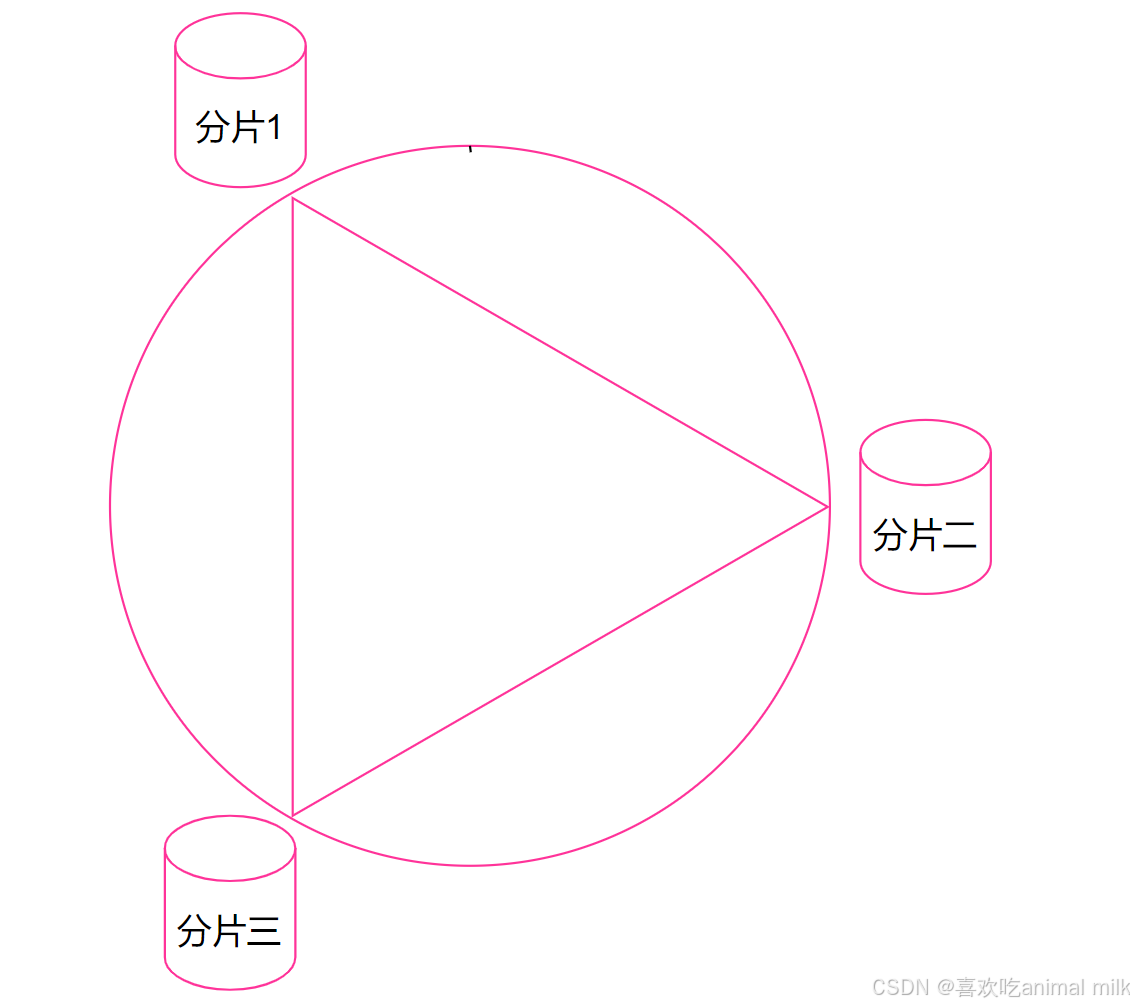
第三步, 假定有一个 key, 计算得到 hash 值 H, 那么这个 key 映射到哪个分片呢? 规则很简单, 就是从 H 所在位置, 顺时针往下找,找到的第一个分片,就是key所在的分片。
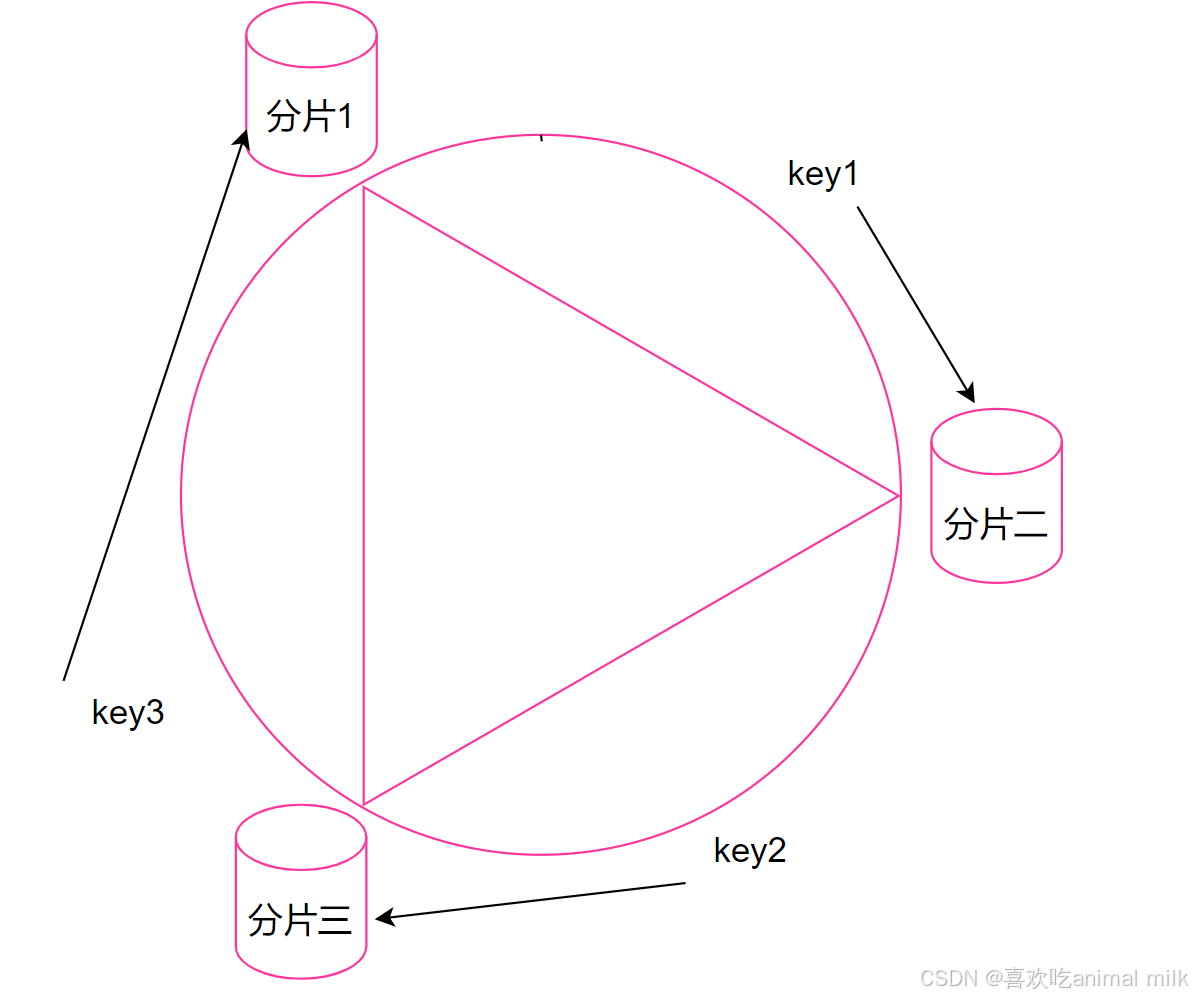
优点: 大大降低了扩容时数据搬运的规模, 提高了扩容操作的效率.
缺点: 数据分配不均匀 (有的多有的少, 数据倾斜).
3) 哈希槽分区算法(Redis使用)
为了解决上述问题 (搬运成本高 和 数据分配不均匀), Redis cluster 引入了哈希槽 (hash slots) 算法.
hash_slot = crc16(key) % 1638416384 其实是 16 * 1024, 也就是 2^14
相当于是把整个哈希值, 映射到 16384 个槽位上, 也就是 [0, 16383]. 然后再把这些槽位比较均匀的分配给每个分片. 每个分片的节点都需要记录自己持有哪些分片.
这⾥的分片规则是很灵活的. 每个分片持有的槽位也不一定连续. 每个分片的节点使用 位图 来表⽰自己持有哪些槽位. 对于 16384 个槽位来说, 需要 2048 个字 节(2KB) 大小的内存空间表示。
总结
以上就是这篇博客的主要内容了,大家多多理解,下一篇博客见!


















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











