






JDK1.7中的HashMap底层使用了 数组+链表 的方式来构建哈希表
JDK1.8中的HashMap底层使用了 数组+链表+红黑树 的方式来构建哈希表
底层原理
初始化
在HashMap内部维护一个桶数组(bucket)来存储元素,其默认的初始容量大小为16,负载因子为0.75。(此处桶数组就是指哈希表)
当然也可以通过调用带参构造来指定数组的初始容量。不过使用带构建创建初始容量时,有可能不会创建出自已指定大小的容量,而是调整为大于等于指定值的最小2的幂次方。例如:当你指定大小为10时,实际创建容量为16(2^4)。当你指定大小为17时,实际创建容量为32(2^5)。
为什么数组长度始终为2的幂次方呢?
主要是便于通过位运算替代取模操作提升效率。
添加元素
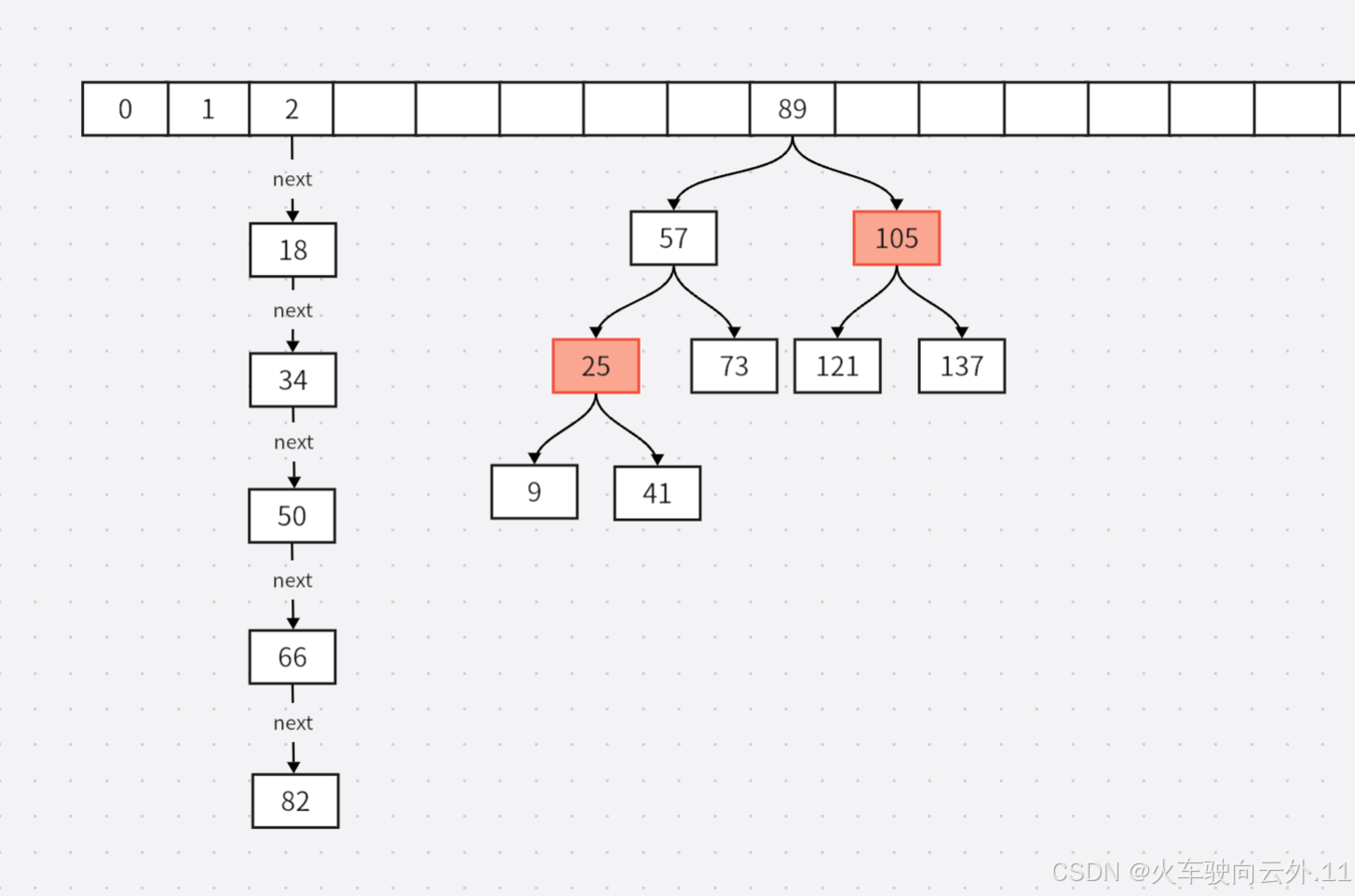
数组元素
在JDK8中,每一个数组元素都是一个叫 Node 的节点,如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}其中,hash存储的是元素键的值通过hashCode()计算后得出的值,因为它是 final 的,所以一旦被初始化,它的值就不能改变。
key和value存储的就是元素的键值对。
next 是指向下一个 Node 对象的引用,用于处理哈希冲突时的链表结构,
也就是HashMap 数组+链表 结构的由来。
元素添加过程
在每次添加元素时,会先进行hashCode() 计算,得出hash值,再通过用 (数组长度 - 1)& hash的位运算方式得出新添加元素所处的数组位置。如果当前数组位置为空则直接添加元素,若不为空则产生hash冲突,此时会将数组元素的 next 指向新添加的元素实现链表结构以解决hash冲突。
但是试想,当某一个桶(bucket)产生的hash冲突过多时,也就是桶中的链表结构过长时就会影响HashMap的查询效率,所以在JDK8时做出了改变。当某一个桶(bucket)中元素超过阈值8个时,会进行判断,如果当前桶数组(哈希表)的长度大于等于64时,桶中的链表结构会转换为红黑树(查询的时间复杂度降为logn),如果长度小于64时,链表结构不会发生转换,而是会触发HashMap的扩容机制。
为什么当链表长度大于8,哈希表长度小于64时不会将链表转为红黑树呢?
其主要原因是当前哈希表的长度过短,完全可以通过加长哈希表的长度来降低哈希冲突的概率,所以进行了扩容操作。
链表与红黑树转换:当链表长度超过阈值8,且数组长度大于等于64时,链表转换为红黑树以提升查询效率(时间复杂度从O(n)降至O(logn));当节点数量减少到6时恢复为链表。
桶数组中的元素数量如果超过 数组长度 * 负载因子 的大小时也会触发扩容机制。
扩容机制
创建一个新的哈希表,新哈希表的长度 = 原哈希表长度 << 1(也就是扩容为原哈希表长度的两倍)。但是将原数组中的元素转移至新数组的过程,JDK7和JDK8有所差别。
JDK7:7会将原哈希表中的所有元素的hash值,重新通过 (新数组长度 - 1)& hash 的位运算方式得到新的index下标,然后继续根据上述的元素添加过程构建出一个数组+链表的结构。
JDK8:8将7中的方法进行了优化,通过 (hash & 原数组长度) 的方式来判断哈希值的高位是否为1,如果为1则将该元素的下标变为 原下标+原容量,并放入对应的桶里,如果不为1,则当前元素的下标不变,还放到原来的位置,避免重新计算哈希值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









