






变量
$n变量与$#
#!/bin/bash
echo "$0 $1 $2 $3"
echo $#
:<<'end'
$0表示文件名
$1表示该文件第一个参数
$2表示该文件第二个参数,以此类推
需要注意,$后的数字只可使用0-9,若比9大,则需要{}
例如 ${11}
$#是用于统计变量个数
end
以parameter.sh作为案例,将上面内容填入后运行该脚本
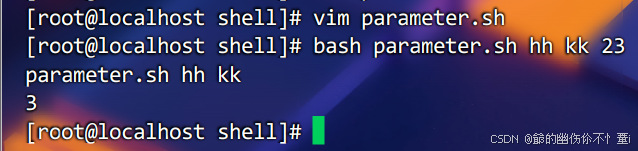
$*和$@和$?
#!/bin/bash
echo "$0 $1 $2 $3"
echo $#
echo $*
echo $@
:<<'end'
$0表示文件名
$1表示该文件第一个参数
$2表示该文件第二个参数,以此类推
需要注意,$后的数字只可使用0-9,若比9大,则需要{}
例如 ${11}
$#是用于统计变量个数
$*代表命令行中的所有参数,把所有参数看做一个整体
$@代表命令行中的所有参数,把所有参数区别对待
end
执行以上脚本后得到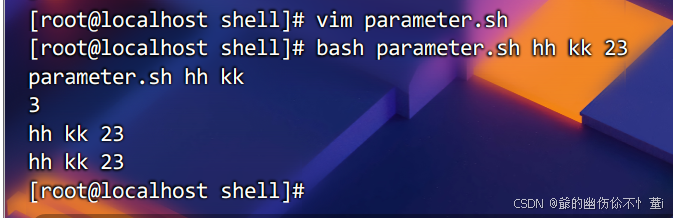
$?用于判断上一条命令是否正确执行,返回0则说明正确执行

简单运算
一、expr方式
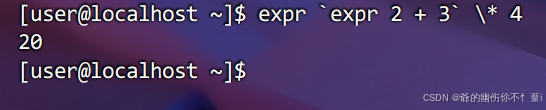
例如计算2+3再乘4
expr `expr 2 + 3` \* 4需要注意的是,对于加减乘除运算,数字之间需要有空格,如果要进行除法运算,bash解释器会默认去掉小数点后的数字(默认向下取整),要精确计算则需要使用别的库
二、$[运算式]
这种运算方式比较符合我们的日常使用
条件判断
格式:[ condition ],条件成立返回0,条件不成立则返回其他
常见比较
整数比较:=字符串比较
-lt:小于 -gt:大于 -le:小于等于 -ge:大于等于
-eq:等于 -nq:不等于
文件权限比较:
-r:有读的权限 -w:有写的权限 -x:有执行的权限
文件类型比较:
-f:常规文件 -e:文件存在 -d:文件存在且是文件夹
实例:
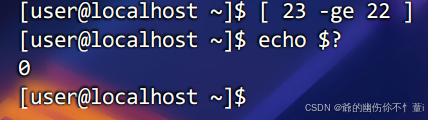
23是否大于等于22
、
判断文件类型
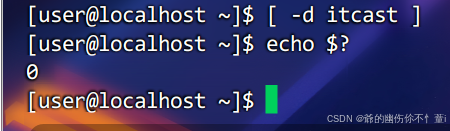
判断文件权限
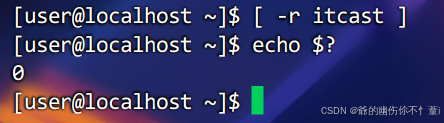
多条件判断:
&& 上一条命令执行成功才执行后一条命令
|| 上一条命令执行失败才执行后一条命令

if语句
#格式如下
#!/bin/bash
if [ condition ]
then
"命令式"
elif [ condition ]
then
"命令式"
fi
建立以下脚本举例说明
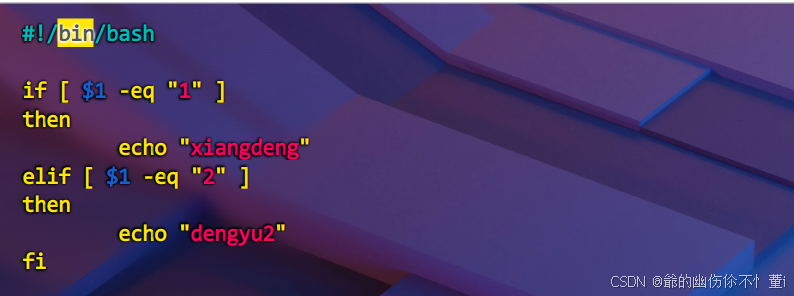
执行后得到以下结果

case语句
case 变量名 in
模式1)
# 如果变量值匹配模式1,则执行这里的命令
;;
模式2)
# 如果变量值匹配模式2,则执行这里的命令
;;
...
*)
# 默认模式,如果变量值不匹配任何模式,则执行这里的命令
;;
esac举个例子
#!/bin/bash
# 读取用户输入的月份
read -p "请输入月份(1-12): " month
# 使用case语句根据月份判断季节
case $month in
1|2|12)
echo "冬季"
;;
3|4|5)
echo "春季"
;;
6|7|8)
echo "夏季"
;;
9|10|11)
echo "秋季"
;;
*)
echo "无效的月份,请输入1到12之间的数字"
;;
esac运行后可得:
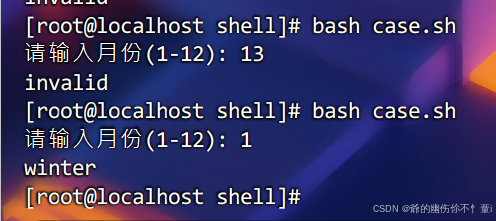
for循环
for 变量 in 列表
do
# 循环体
done举个例子,输出1-5的数字
#!/bin/bash
for i in {1..5}
do
echo "Number $i"
done对字符串做遍历
#!/bin/bash
for name in Alice Bob Charlie
do
echo "Hello, $name!"
done效果如下
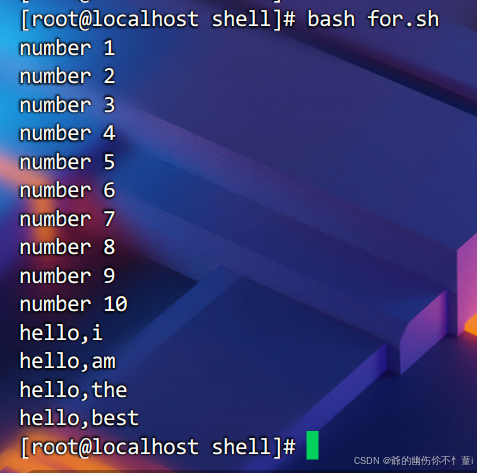
对文件做遍历,该脚本使用了-f判断变量$file是否为文件,并且会输出指定目录内的文件的路径
#!/bin/bash
for file in /home/user*
do
if [ -d "$file" ]; then
echo "File: $file"
fi
done执行效果如下

while循环
while [ 条件表达式 ]
do
# 执行命令
done循环输出数字1-5
#!/bin/bash
i=1
while [ $i -le 5 ]
do
echo "$i"
((i++))
done效果如下
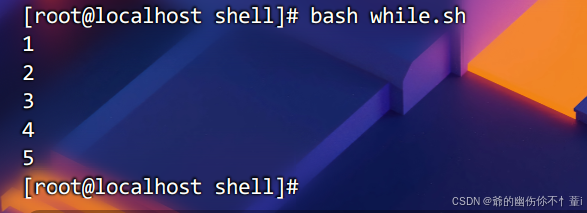
read语句
read [-options] [variables]
option:
-p: 在命令行中显示提示信息
-t: 在read命令设置超时时间(以秒为单位)。如果用户在指定的时间内没有输入任何内容,则read命令会返回一个非零退出状态,并且不会将任何内容赋值给变量
案例如下:
#!/bin/bash
if read -t 10 -p "Enter your first name and last name:" first last; #read可读取多参数
then
echo "hello,$first $last"
else
echo "Timeout"
fi效果如图
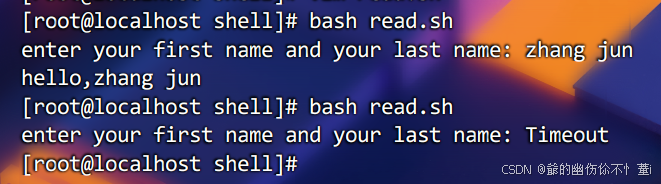
函数
系统函数basename
在Shell中,basename命令是一个非常实用的工具,它用于去除文件路径中的目录部分,
只保留文件名。这对于处理文件路径和脚本编程时非常有用。
basename [OPTION]... [文件路径] [后缀]
实例如下
basename /path/to/your/file.txt
-->> file.txt
basename /path/to/your/file.txt .txt
-->> file
处理多个文件:
basename -a /path/to/file1.txt /path/to/another/file2.ext
-->> file.txt file2.ext
dirname
dirname 文件绝对路径
用于从该文件路径中去除文件名,返回剩下路径(目录部分)示例如下:

自定义函数
#!/bin/bash
function 函数名()
{
}实例如下
#!/bin/bash
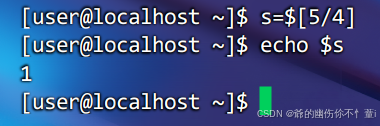
function sum(){
s=0
s=$[$1+$2]
echo $s
}
read -p "input your first number:" p1
read -p "input your second number:" p2
sum $p1 $p2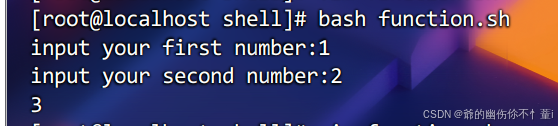
shell工具
cut工具
用于按列或字符来截取文本文件中的内容。它可以非常灵活地从文本或数据流中提取出你所需要的信息。
cut OPTION... [FILE]...
其中,OPTION... 是 cut 命令的选项,用来指定如何截取文本,而 [FILE]... 是要处理
的文件名列表,如果省略文件名,则默认从输入行读取数据。
常用选项
-b:按字节(byte)截取。可以指定字节范围。
-c:按字符(character)截取。与 -b 类似,但-c选项会考虑到多字节字
符,适用于包含非ASCII字符的文本。
-d:指定字段的分隔符,默认是制表符(tab)。
-f:指定要显示的字段编号,多个字段之间用逗号分隔。
--complement:补集,显示未由 -f 选项指定的字段。按字节截取:-b
实例如下,从cut.txt中按字节截取1-3字节的内容
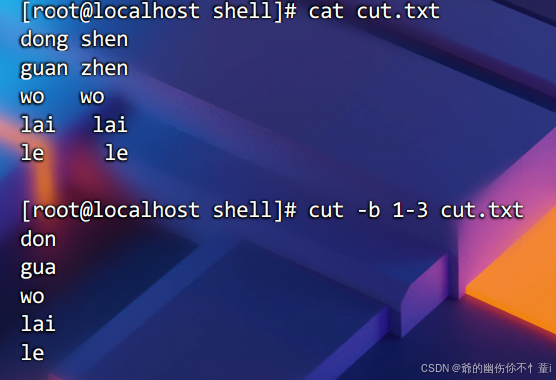
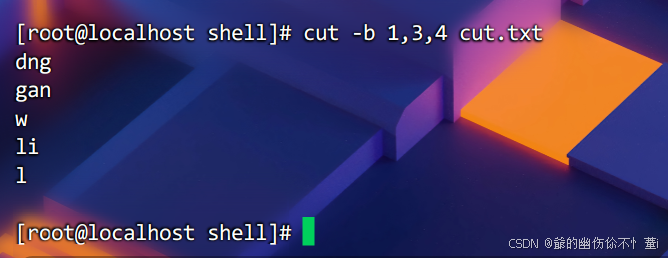
也可以截取指定字节,比如截取1,3,4字节,则需要用逗号隔开
如果所截取的内容,还包括汉字,那么则需要-n选项,比如:
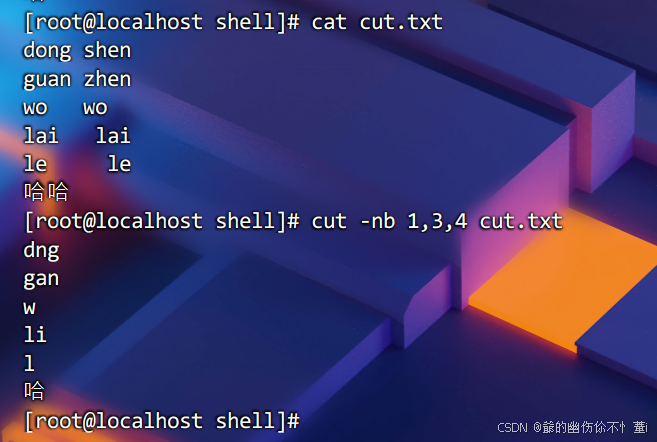
值得一提的是,汉字在部分编码集里,至少要用3个字节来表示一个汉字的,所以要用上-n
按字符截取:-c
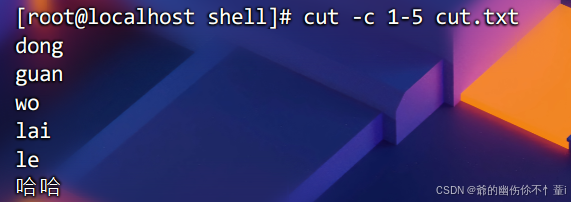
-c用法则如下(按字符分割),从1-5中截取字符
按字段截取:-d
通常与-f搭配使用,以下案例则是以空格为分隔符,截取第二个字段(读到空格了,那么下一个字段则是第二个字段);-f 2 是指截取第二个字段。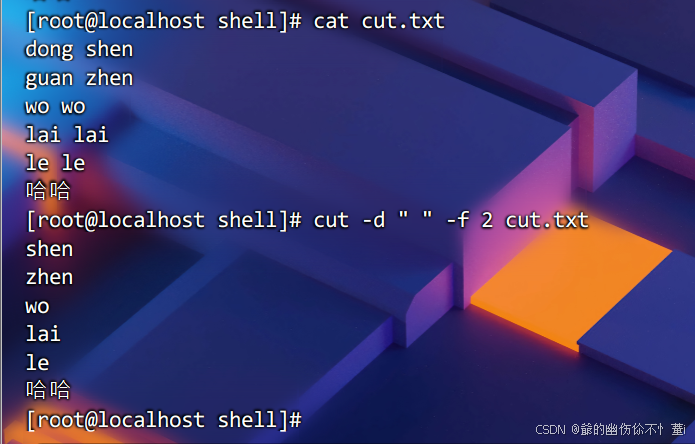
sed工具
sed(stream editor)是一种强大的文本处理工具,它允许你执行文本替换、删除、新增、插入等操作,而不需要打开并编辑文件本身。sed命令按照指定的脚本(或命令)来处理文本流中的每一行数据,并将结果输出到标准输出(通常是屏幕),但它也可以修改文件内容(使用-i选项)
sed [选项]... '{命令}' [输入文件]...常用选项
-n:不输出处理过程中的内容到标准输出,除非使用p命令。-e:允许对输入数据应用多个sed编辑命令。-i:直接修改文件内容,而不是输出到标准输出。-f:从文件中读取sed脚本。
常用命令
p:打印模式空间的内容。d:删除模式空间的内容,并立即开始新的一轮循环。s/原字符串/新字符串/g:替换文本中的字符串,g表示全局替换。a\:在指定行后面追加文本。i\:在指定行前面插入文本。c\:用新文本替换指定行的文本。
实例如下
将sed.txt的dong换成hh
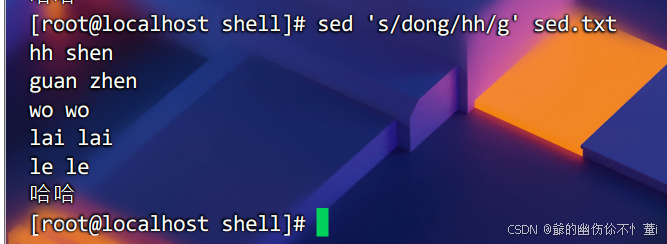
注意,这个操作不会修改源文件。
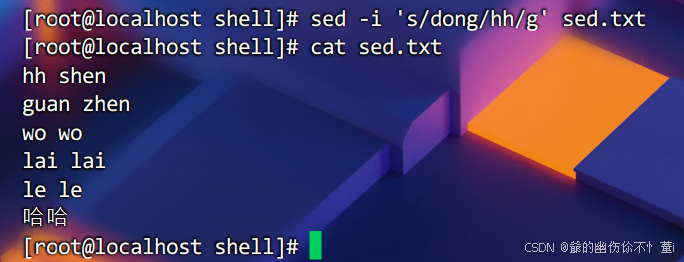
修改文件内容
直接修改文件内容,这次修改会直接反映到file.txt文件中。
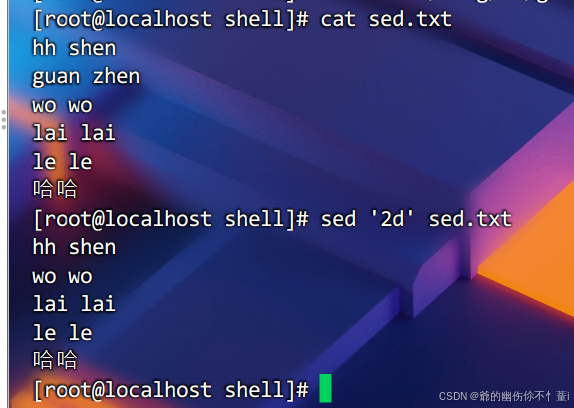
删除指定文件特定行
实例操作为删除指定文件的第二行
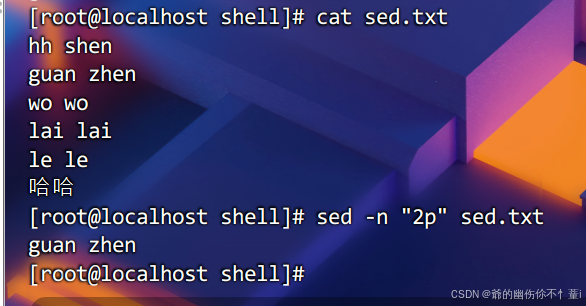
打印指定行
需要使用-n选项与命令p,实例则是打印第二行
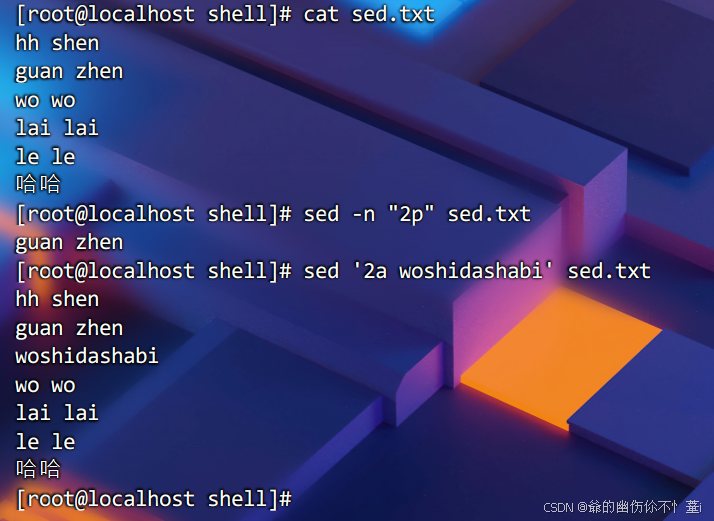
在文件中特定行后追文本
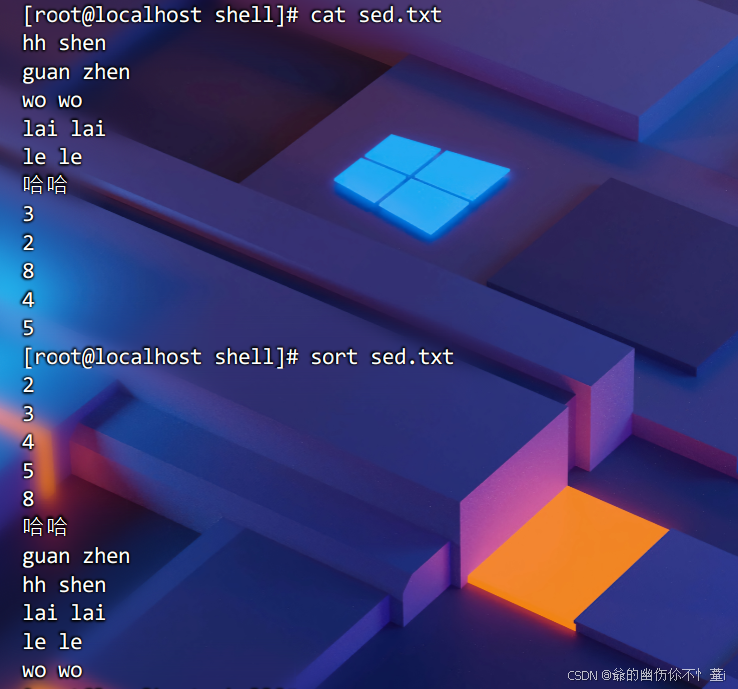
sort工具
sort 命令在 Unix/Linux shell 中用于对文本文件的行进行排序。它可以按照字典顺序、数字大小或者是根据你指定的字段进行排序。sort 命令非常灵活,提供了许多选项来满足不同的排序需求。
sort [选项]... [文件]...如果没有指定文件,sort 会从标准输入(stdin)读取数据。
常用选项
-n:按照数字大小进行排序,而不是按照字典顺序。-r:逆序排序(从大到小)。-t:指定字段分隔符,默认为空白字符(空格或制表符)。-k:指定排序的字段,-k选项后面可以跟一个或多个字段号,字段号之间用逗号分隔。字段号从1开始。-u:去重,只显示排序后结果中的唯一行。-b:忽略每行前面的空白部分。-f:忽略大小写。-M:按照月份名进行排序(仅当输入行符合月份名的格式时有效)。-o:将排序后的结果输出到指定的文件中,而不是标准输出。
实例如下
顺序排序
按照字典abcd顺序来对文件内容进行顺序排序
逆序排序 -r
按照字典dcba顺序来对文件内容进行顺序排序
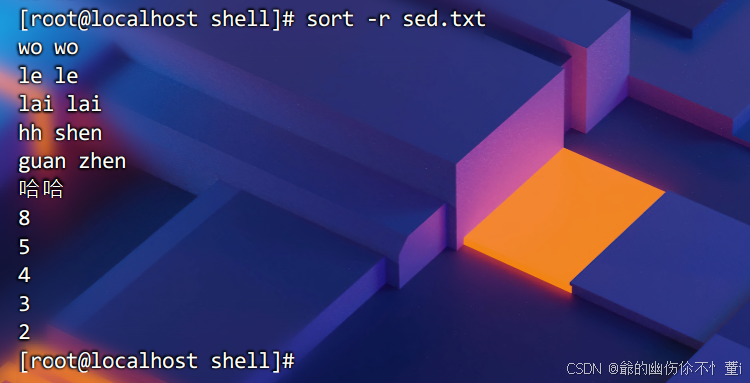
数字排序 -n
对文件内的数字做递增排序,如果文件内容有字符串,则对字符串的首字母做顺序排序(字母转ASCII码,字母越靠前数值越小,故顺序排序)
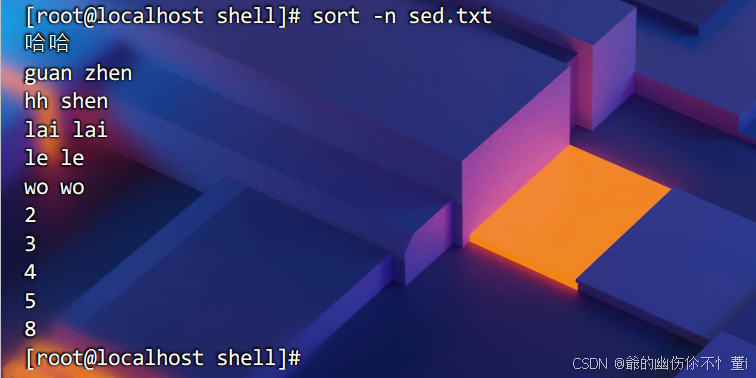
去重排序 -u
对文件内容的行进行排序,并只输出唯一的行
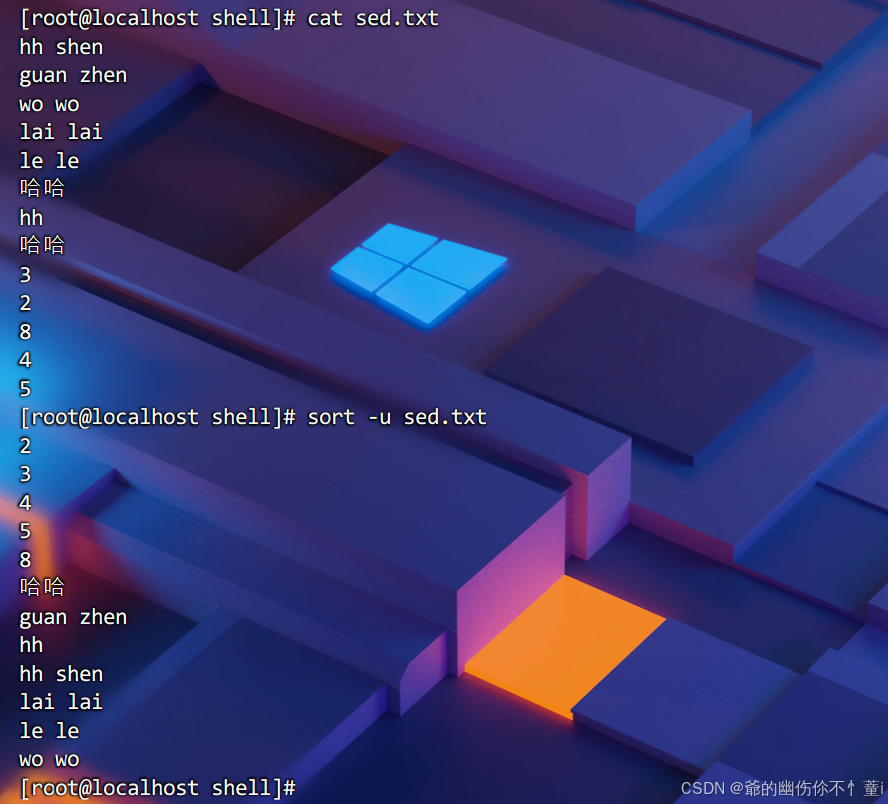
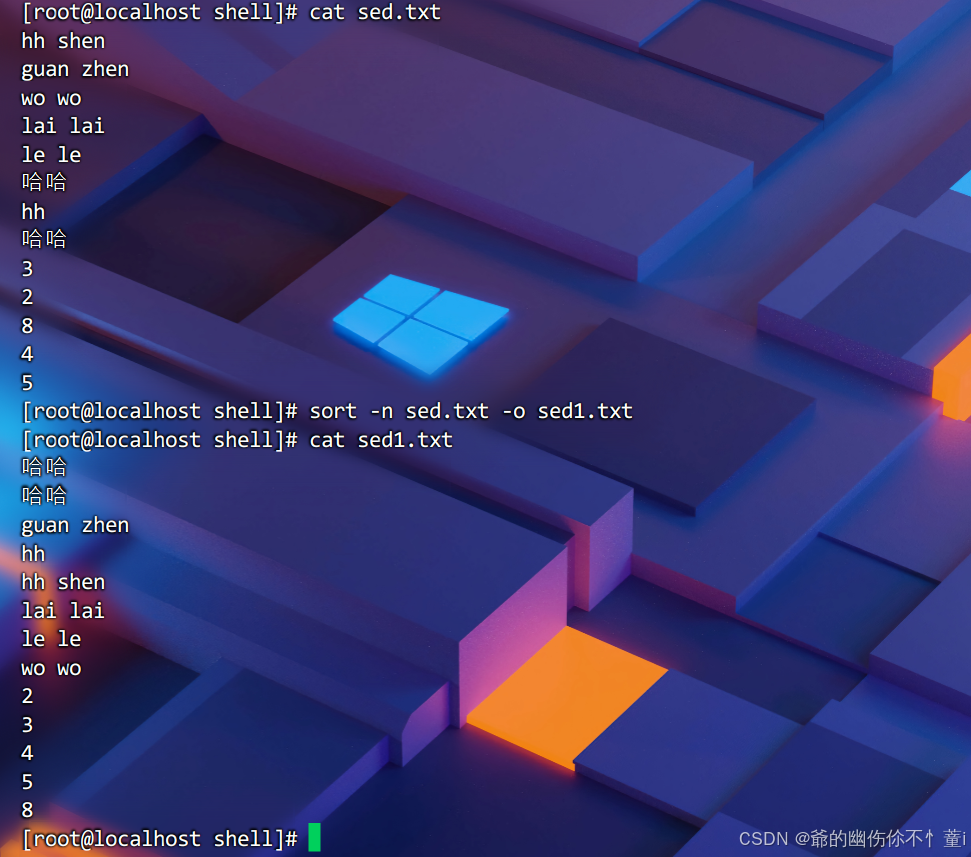
将排序结果保存到文件 -o
将排序结果保存到新文件中
awk工具
awk 是一个功能强大的文本处理工具,它用于在 Linux/Unix 系统中对文本和数据进行处理。awk 程序通常由一个或多个模式(pattern)和对应的动作(action)对组成。模式用于匹配输入的文本行,而动作则定义了当匹配到模式时要执行的命令,awk工具也是逐行匹配的。
awk 'pattern { action }' input_file
pattern:是一个条件表达式,用于指定哪些行应该被处理。如果省略,则处理所有行。{ action }:是一组命令,当指定行匹配模式时执行。如果省略{ action },则默认打印匹配的行。input_file:是输入文件的名称。如果省略,则默认从标准输入(stdin)读取。
按列打印文件内容
$1表示第一列数据,$2同理。以此类推,但如果要打印最后一列呢?
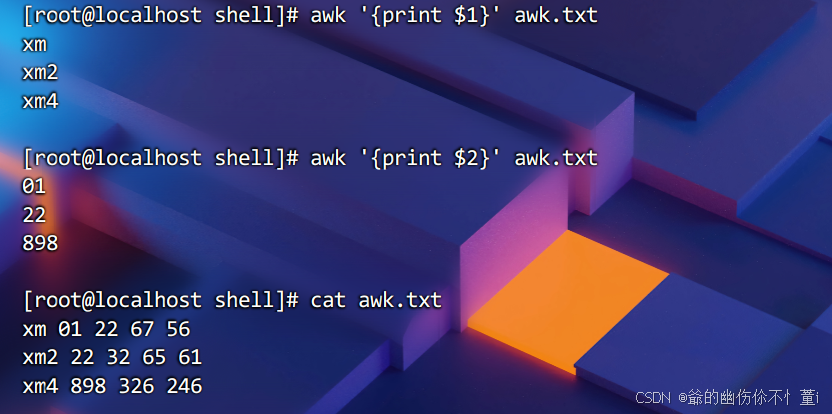
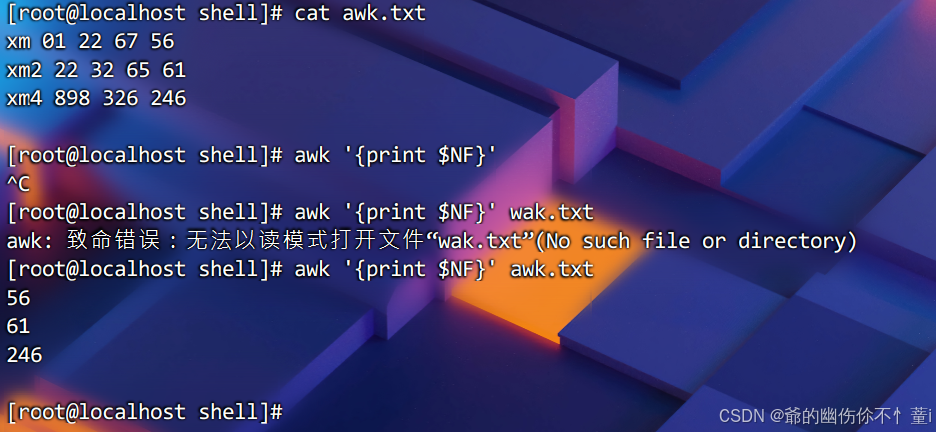
在awk工具里,NF(number of field)则表示最后一列的意思,同理,NF-1则表示倒数第二列
内置变量
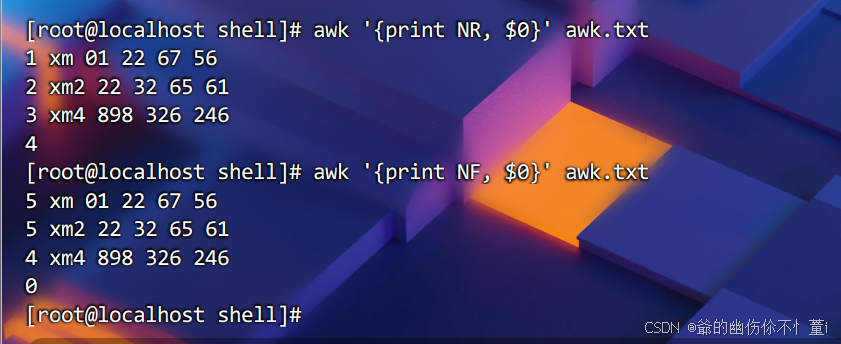
NF与NR:
awk有一些内置变量,如 NR(当前记录号,即行号)和 NF(当前记录中的字段数)。示例如下。
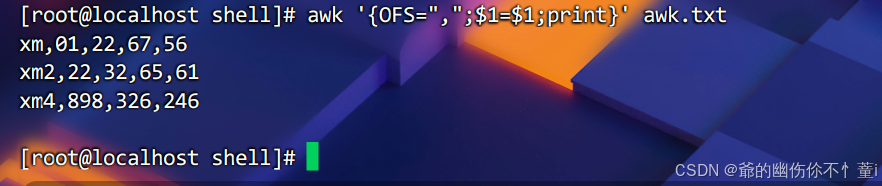
OFS变量(OFS,ouput filed separator)
假设我要用逗号分隔所有数据,则可以使用OFS,即Output Field Separator的缩写,它是一个非常重要的内置变量,它定义了awk在处理输出时字段之间的分隔符。默认情况下,OFS的值是空格(一个空格字符),但你可以根据需要将其设置为任何字符串,包括单个字符或多个字符的序列。
示例如下,值得一提的是,"$1=$1"是用于刷新变量的,修改完OFS需要刷新后才生效。
也可以通过-v选项来修改OFS变量,但是个人感觉不如上面这个。。

RS变量(record separator)
RS变量定义了输入记录的分隔符。默认情况下,RS是一个换行符(\n),这意味着awk会将输入的每一行视为一个记录。你可以根据需要更改RS的值,以便awk能够按照不同的规则来识别记录。
FS变量(Filed Separator)
FS变量定义了字段的分隔符。默认情况下,FS是一个空白字符(空格或制表符),这意味着awk会将输入行中由空格或制表符分隔的文本视为不同的字段。但是,你可以根据需要更改FS的值,以便awk能够按照不同的规则来分割字段。
示例如下
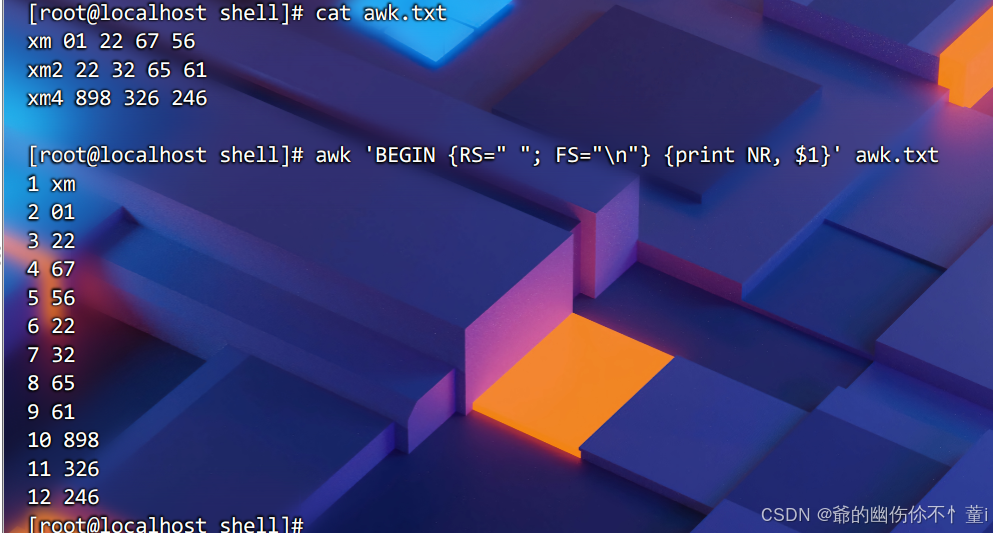
实例的命令则是:RS=“ ”,将输入的文件,按照空格分辨记录,读到空格,则更新一次记录;FS=“\n”,则为一个字段,也就是说,例子中xm——56则为一个字段,显示行号并打印所有内容。
简单实例
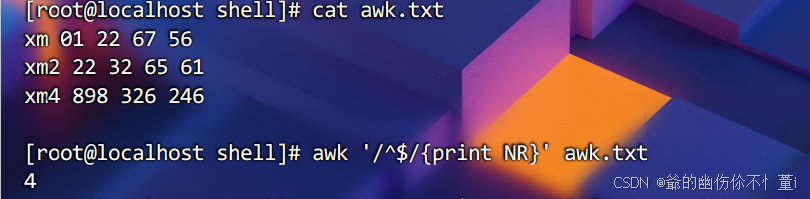
1.用linux查询awk.txt中空行的行号。
2.用linux计算文件awk.txt中第三列的数据之和

3.编写脚本判断文件是否存在
#!/bin/bash
read -p "请输入所需查询的文件" file
if [ -f $file ];
then
echo "exist"
else
echo "unexist"
fi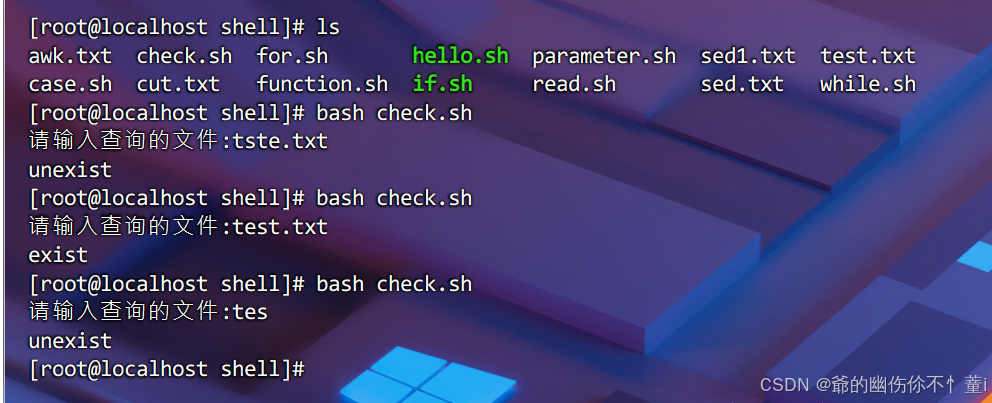

















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









