







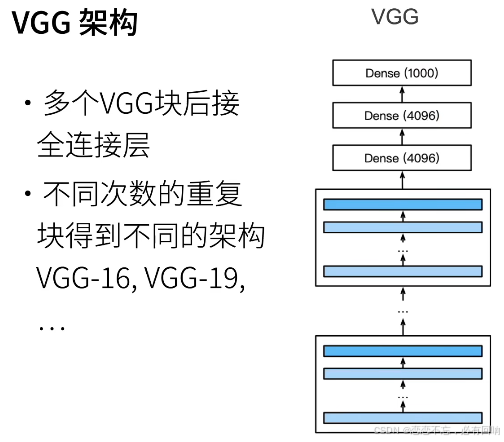
VGG
AlexNet 最大的问题就是长的不规则,就是模型架构很随意,结构不是很清晰
- AlexNet比 LeNet更深更大来得到更好的精度
- 能不能更深和更大?
- 选项
- 更多的全连接层(太贵)
- 更多的卷积层
- 将卷积层组合成块
VGG 块
- 深vs.宽?
- 5x5卷积
- 3x3 卷积
- 深但窄效果更好
- VGG 块
- 3x3卷积(填充1) (n 层, m 通道)
- 2x2最大池化层(步幅2)
进度
- LeNet (1995)
- 2卷积+池化层
- 2全连接层
- AlexNet
- 更大更深
- ReLu, Dropout,数据增强
- VGG
- 更大更深的AlexNet(重复的VGG块)
总结
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
代码实现
首先需要实现 VGG 块:
import torch
from torch import nn
from d2l import torch as d2l
# vgg 最大的特点就是将部分卷积层封装为块。
def vgg_block(num_convs, in_channels, out_channels):
# 第一个参数表示当前卷积块中要堆叠的卷积层数,后面的参数表示输入通道数,输出通道数
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
# 确保后续卷积层的输入通道数与前一层的输出通道数一致
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
VGG 网络
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = [] #用于存储所有的卷积块
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分,和 AlexNet 一样
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)
)
net = vgg(conv_arch)
观察每个层输出的形状:
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)
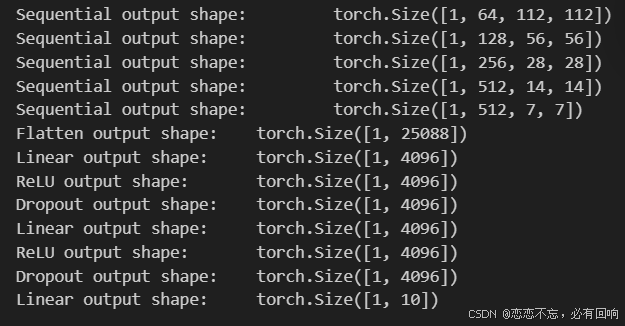
由于VGG-11比AlexNet计算量更大,因此构建了一个通道数较少的网络,足够用于训练Fashion-MNIST数据集。
ratio = 4 # 将通道数除以4,相当于计算量减少了16倍
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
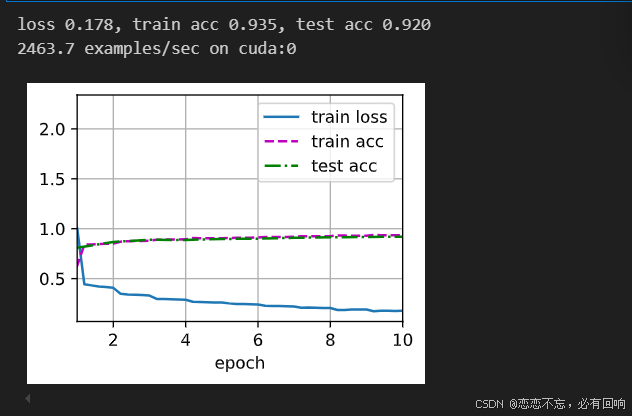
模型训练
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
QA 思考
Q1:训练loss一直下降测试Ioss从开始起就一点不降成水平状是什么原因呢?
A1:主要有两个问题:
- 测试代码写错了
- Overfitting 了,表示测试集和训练集长得非常不一样。
Q2:为什么 VGG(1,1,224,224) 的输入高宽减半后,这通道数是64?
A2:在架构时选择的第一个块的卷积层的输出就是 64.
后记
写了一段代码,在colab上训练的大概20分钟
from matplotlib import pyplot as plt
from torch import nn
import time
import numpy as np
import torch
from torchvision import transforms, datasets
from torch.utils import data
from tqdm import tqdm # 导入 tqdm
# 定义 VGG 块
def vgg_block(num_convs, in_channels, out_channels):
"""
创建一个 VGG 块,包含多个卷积层和一个池化层。
:param num_convs: 卷积层数量
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:return: 包含卷积层和池化层的 Sequential 模块
"""
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
# 定义 VGG 架构
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
"""
根据给定的架构创建 VGG 网络。
:param conv_arch: 卷积块的配置列表,每个元素是 (num_convs, out_channels)
:return: VGG 网络模型
"""
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels=in_channels, out_channels=out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)
)
# 初始化网络
net = vgg(conv_arch)
# 动画绘制类
class Animator:
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5)):
if legend is None:
legend = []
self.xlabel = xlabel
self.ylabel = ylabel
self.legend = legend
self.xlim = xlim
self.ylim = ylim
self.xscale = xscale
self.yscale = yscale
self.fmts = fmts
self.figsize = figsize
self.X, self.Y = [], []
def add(self, x, y):
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
def show(self):
plt.figure(figsize=self.figsize)
for x_data, y_data, fmt in zip(self.X, self.Y, self.fmts):
plt.plot(x_data, y_data, fmt)
plt.xlabel(self.xlabel)
plt.ylabel(self.ylabel)
if self.legend:
plt.legend(self.legend)
if self.xlim:
plt.xlim(self.xlim)
if self.ylim:
plt.ylim(self.ylim)
plt.xscale(self.xscale)
plt.yscale(self.yscale)
plt.grid()
plt.show()
# 计时器类
class Timer:
def __init__(self):
self.times = []
self.start()
def start(self):
self.tik = time.time()
def stop(self):
self.times.append(time.time() - self.tik)
return self.times[-1]
def sum(self):
return sum(self.times)
def avg(self):
return sum(self.times) / len(self.times)
def cumsum(self):
return np.array(self.times).cumsum().tolist()
# GPU 检测函数
def try_gpu(i=0):
"""如果存在 GPU,则返回 cuda:i,否则返回 cpu"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
# 数据加载函数
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
fashion_mnist_train = datasets.FashionMNIST("../data", train=True, transform=trans, download=True)
fashion_mnist_test = datasets.FashionMNIST("../data", train=False, transform=trans, download=True)
return (
data.DataLoader(fashion_mnist_train, batch_size=batch_size, shuffle=True),
data.DataLoader(fashion_mnist_test, batch_size=batch_size, shuffle=False)
)
# 累加器类
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 准确率计算函数
def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
# 测试数据集上的准确率评估函数
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
# 训练函数
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = Timer(), len(train_iter)
# 使用 tqdm 显示 epoch 进度
with tqdm(total=num_epochs * num_batches, desc="Training Progress") as pbar:
for epoch in range(num_epochs):
metric = Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
pbar.update(1) # 更新 tqdm 进度条
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
animator.show()
# 调整架构以减少计算量
ratio = 4 # 将通道数除以 4,相当于计算量减少了 16 倍
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
# 设置超参数
lr, num_epochs, batch_size = 0.05, 10, 128
# 加载数据
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)
# 开始训练
train_ch6(net, train_iter, test_iter, num_epochs, lr, try_gpu())


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









