







🎙告诉你:Java是世界上最美好的语言
💎比较擅长的领域:前端开发
是的,我需要您的:
🧡点赞❤️关注💙收藏💛
是我持续下去的动力!
2025年6月4日进行测试,确认文章配置步骤有效!可以放心更着步骤来配置!
目录
一. 作者有话说
1.1 本平台需要准备
redis 你可以不用,但是不可以没有,因为若依一些配置和redis有关
mysql 一定要有,学到这个地步了mysql应该是有的吧
需要有软件 idea 和 vs
二. 若依的了解
2.1 若依的版本

三 .后端的配置
3.1 步骤

3.2 打开GitHub
3.3 复制地址

3.4 通过idea导入到vcs

3.5 执行代码
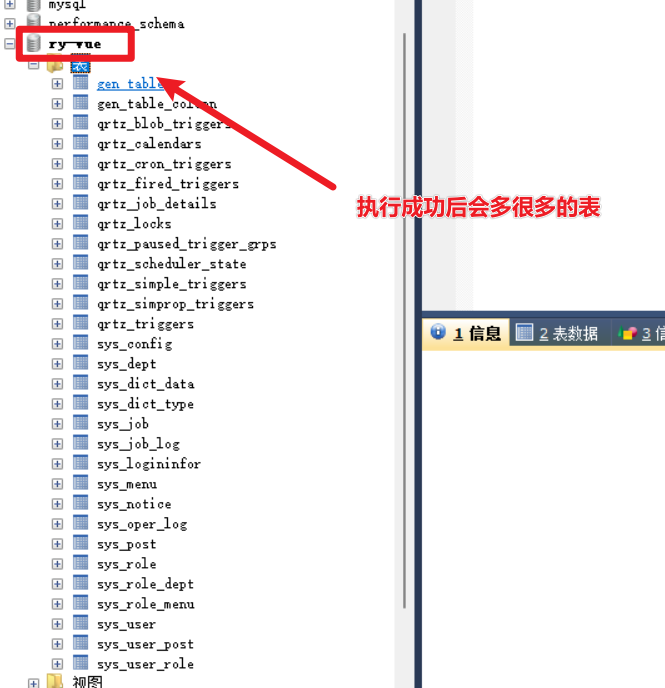
在vcs导入后的代码中,找到两个sql文件,到数据库中去一键执行。
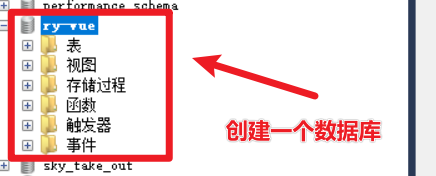
这里要在数据库中创建一个数据库【ry-vue】,然后找到下面的两个sql文件,执行这两个sql脚本

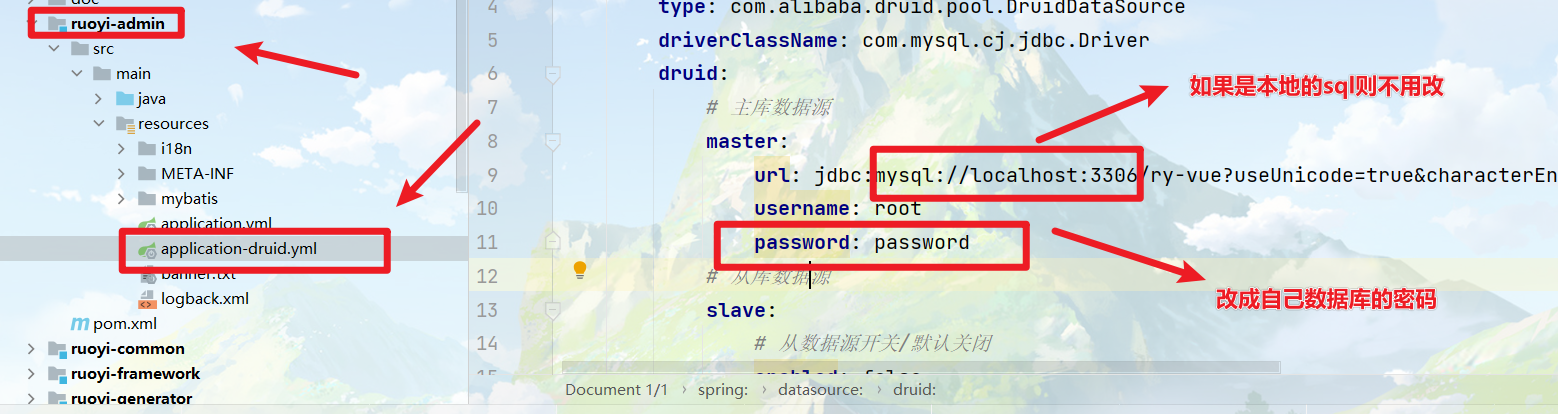
3.6 配置数据库的密码
自己按自身条件进行更改
【这里主要是改数据库的密码以你的为标准和数据库的名字】
3.7 启动redis
注意看,执行的是如下图的命令去打开redis,没有redis去下载redis,然后打开redis所在文件的终端,进行代码执行打开redis
到这个样子才算redis启动成功了

3.8 修改redis配置
注意默认是没密码的,下面的图默认的就可以了,这一步可以不用改。
找到77行代码,把你的redis密码改一改即可,没有密码则不用修改

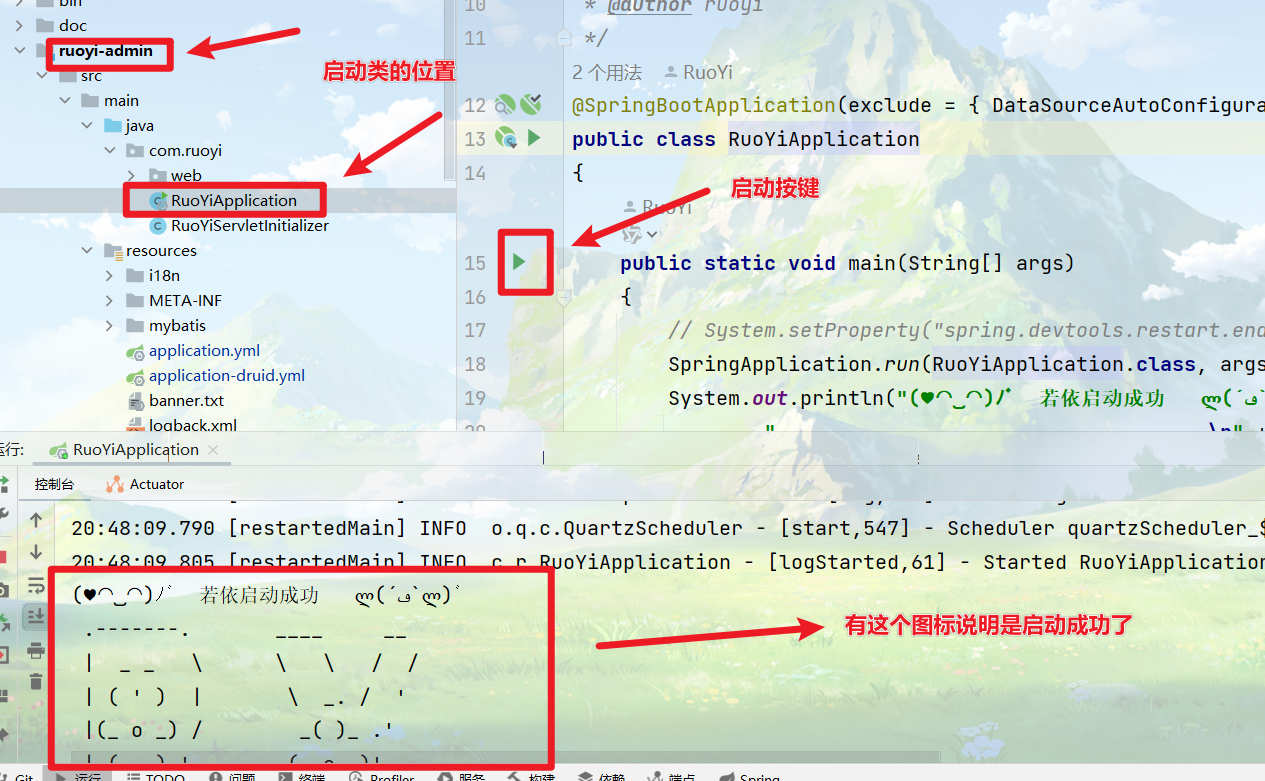
3.9 右键启动若依
在ruoyi-admin文件夹下

显示若依启动成功就是成功了,是中文!
四. 前端的配置
4.1 步骤

4.2 拿到地址,打开终端进行命令
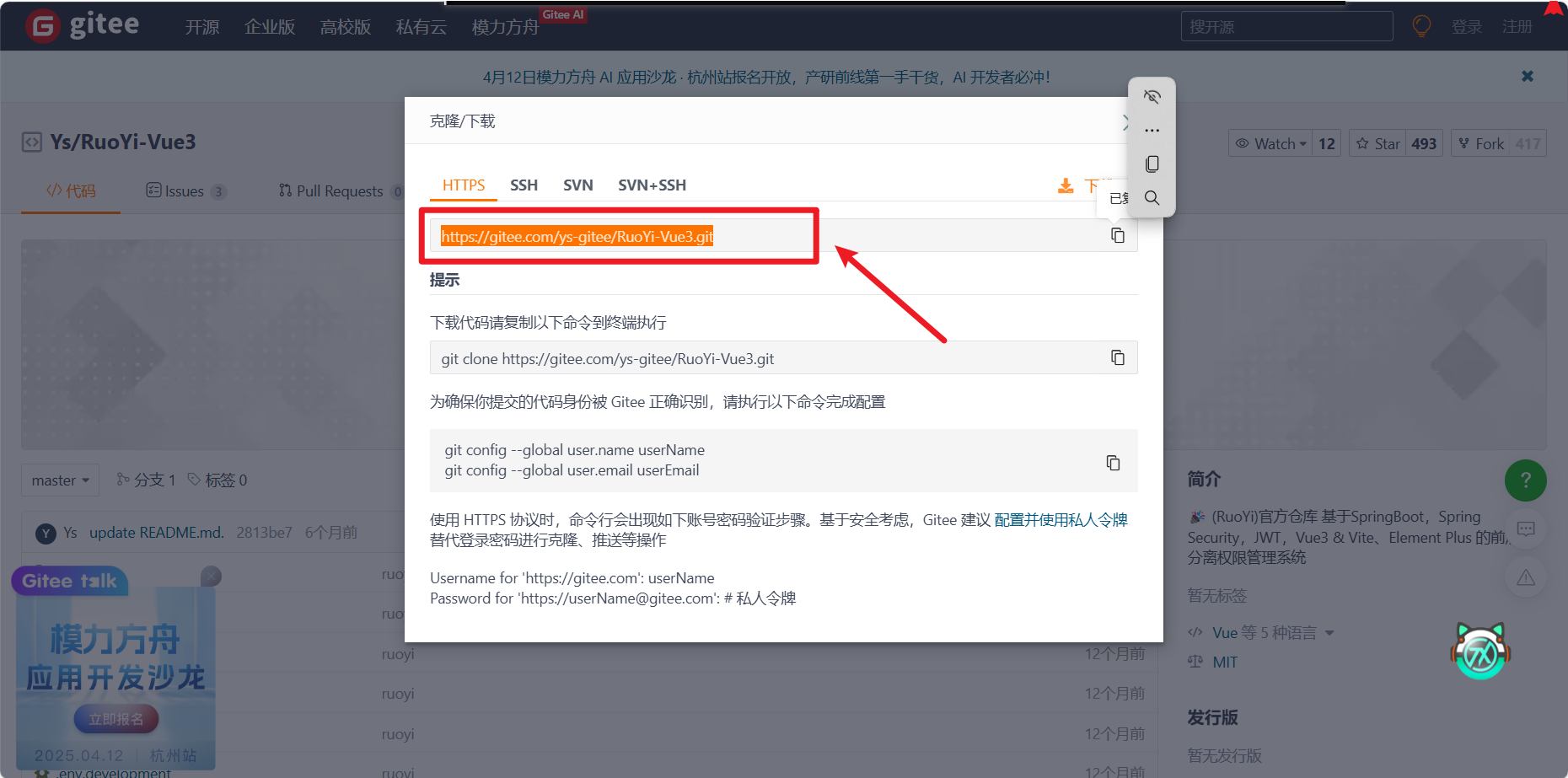
同样也是拿到地址,和后端不同的是执行的方式
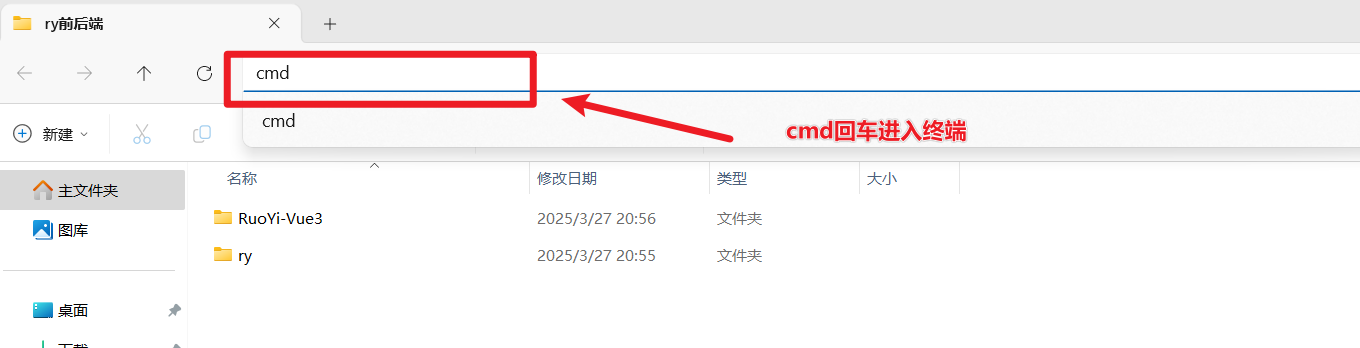
然后去你想要放若依前端的文件夹中,打开cmd
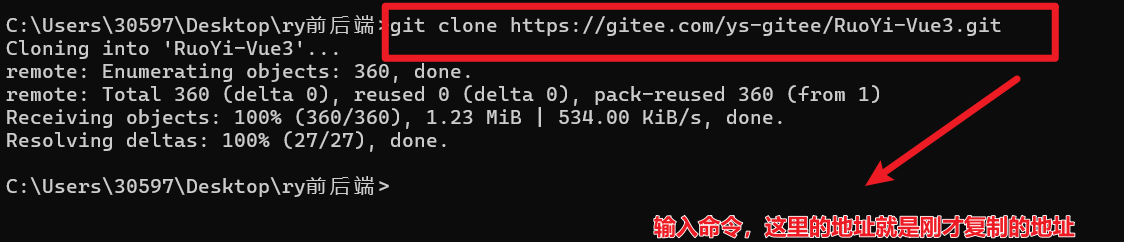
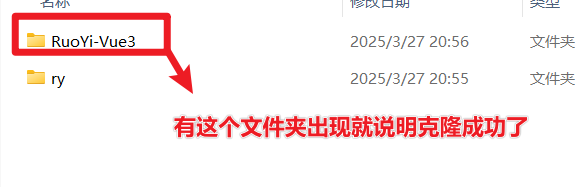
如果生成了若依的文件夹,就是说明成功了
4.3 然后进行安装依赖
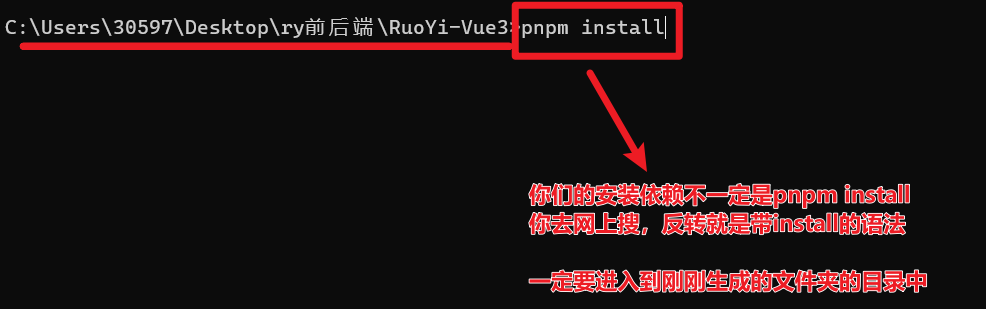
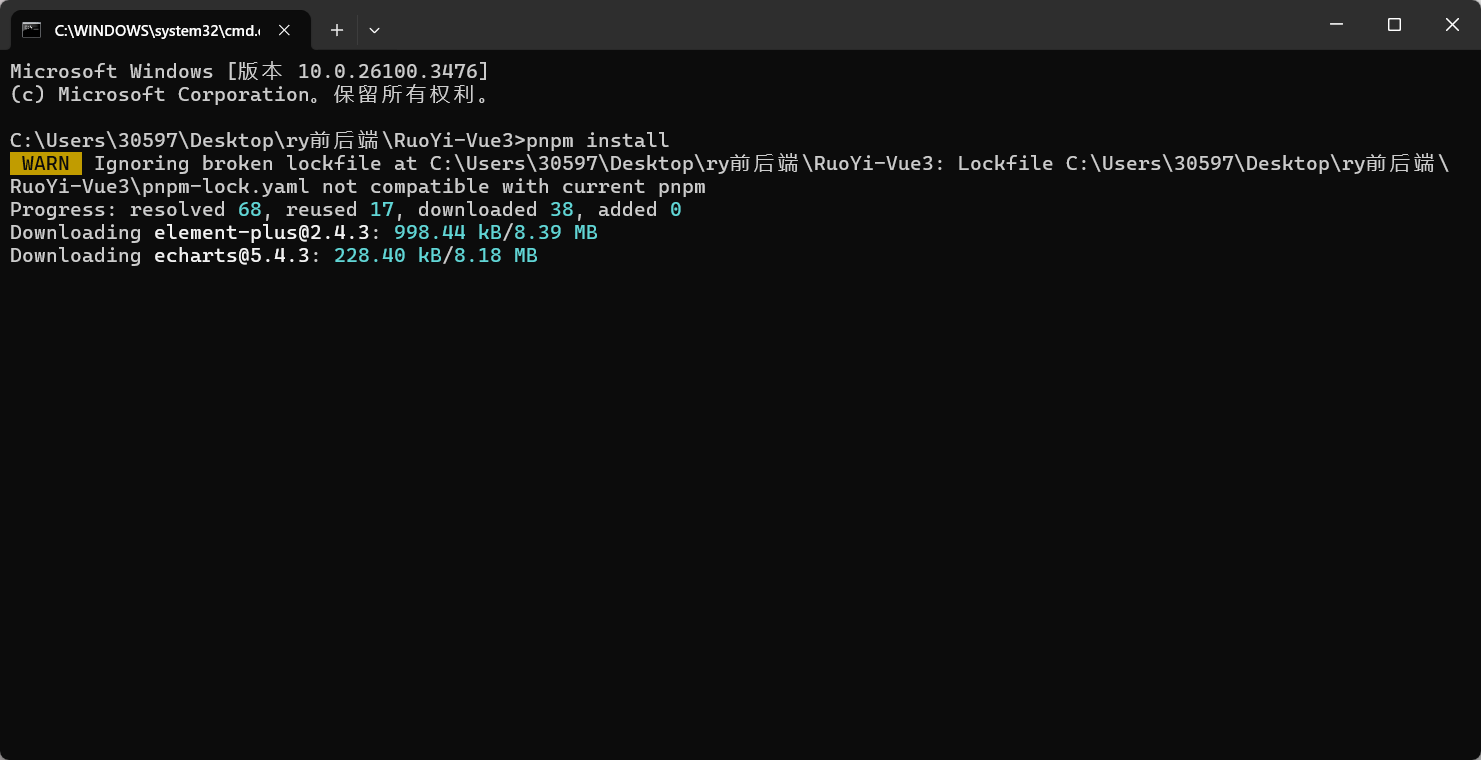
这样才算开始下载依赖:
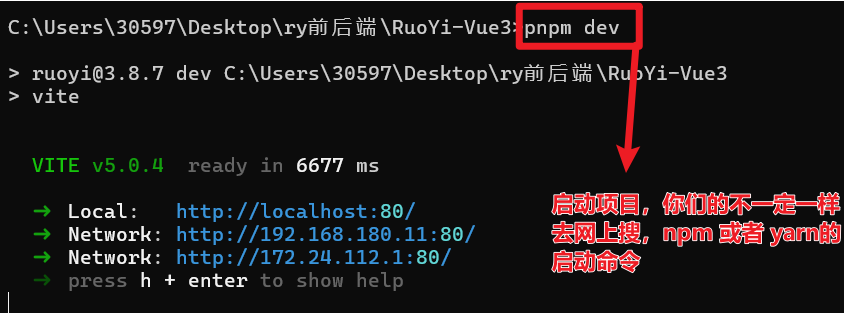
4.4 启动前端项目
启动前端项目:
4.5 打开项目
运行后:
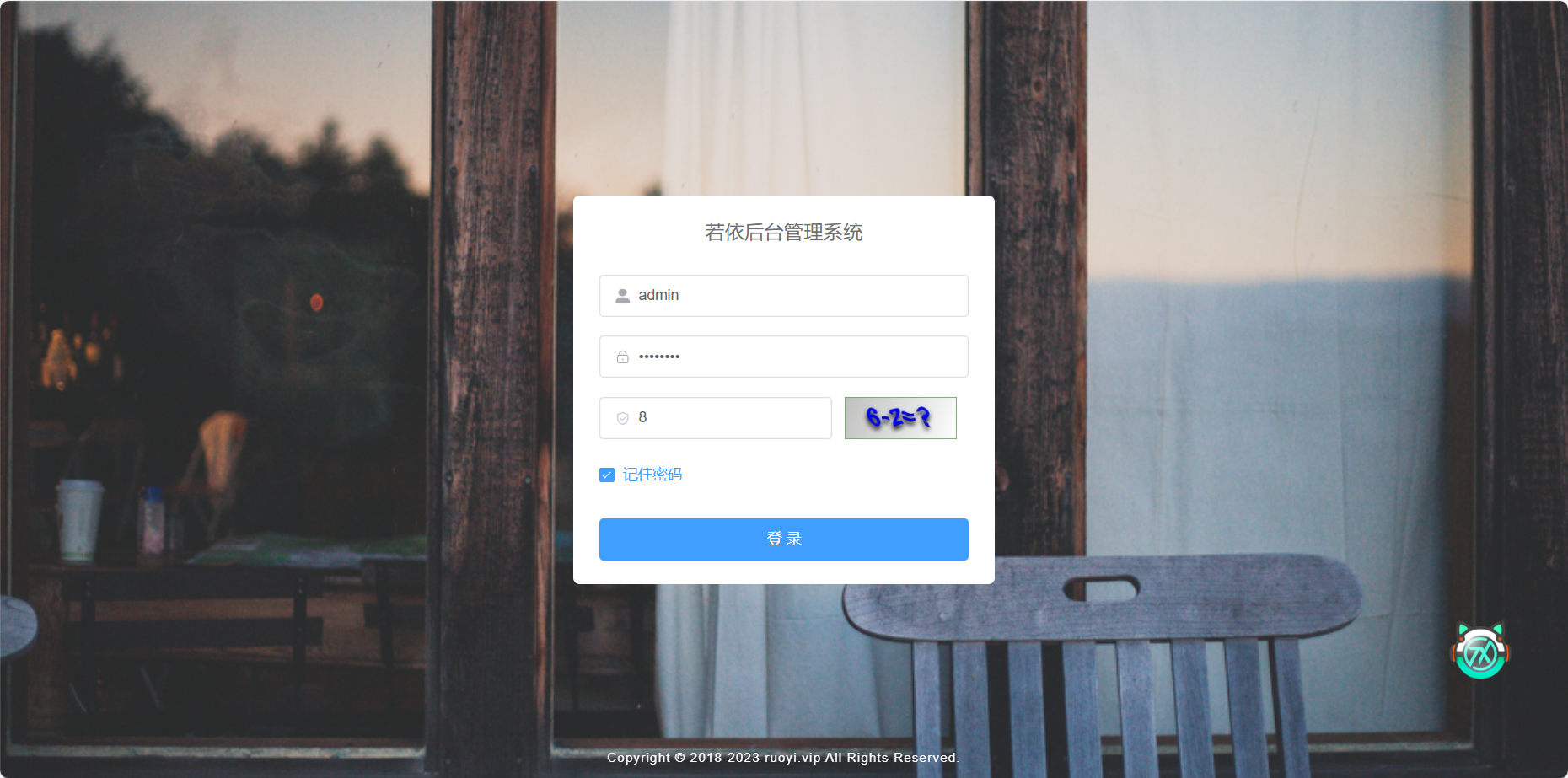
重要:如果登录成功,那么前端后端都配置成功了 ,一定要注意:redis要启动,后端要启动
前端就完成了 !!!到此为止都完成了!!!
4.6 判断是否配置完好
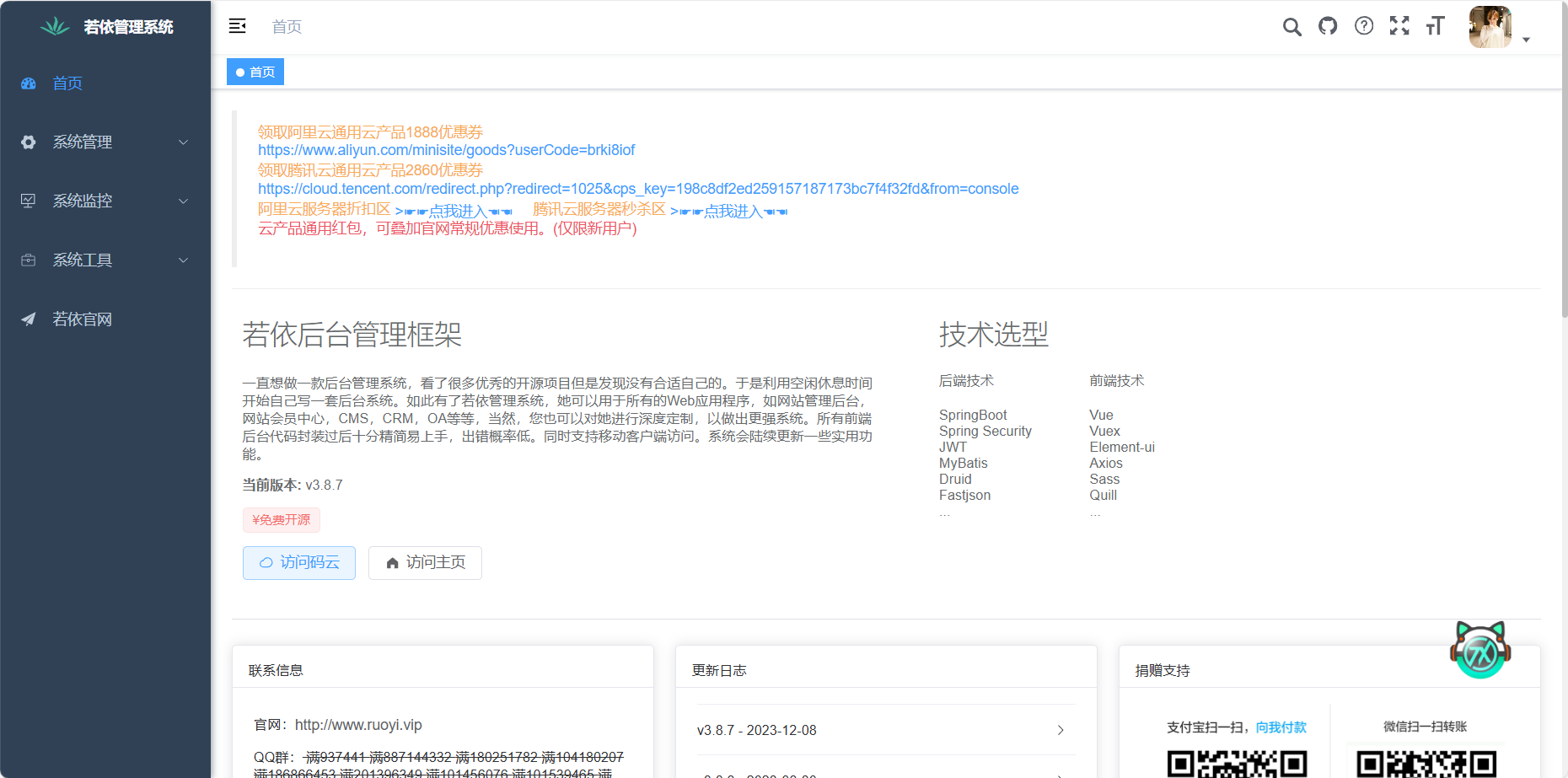
能登录成功若依就说明前端后端都配置好了
🎙座右铭:得之坦然,失之淡然。
💎擅长领域:前端
是的,我需要您的:
🧡点赞❤️关注💙收藏💛
是我持续下去的动力!



















 1982
1982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











