






 文章介绍了Elasticsearch的基础概念,如文档、字段、索引和映射,以及与MySQL的对比。详细阐述了如何部署单点ES和Kibana,包括网络创建、数据卷挂载和端口映射。此外,还讲解了安装IK分词器的步骤,并展示了Java操作ES的客户端RestHighLevelClient的使用,包括创建、删除索引库,以及文档的增删改查操作。
文章介绍了Elasticsearch的基础概念,如文档、字段、索引和映射,以及与MySQL的对比。详细阐述了如何部署单点ES和Kibana,包括网络创建、数据卷挂载和端口映射。此外,还讲解了安装IK分词器的步骤,并展示了Java操作ES的客户端RestHighLevelClient的使用,包括创建、删除索引库,以及文档的增删改查操作。
初识ES
文档,词条:
每一条数据就是一个文档,对文档中的内容分词,得到的词语就是词条;
正向索引、倒排索引:
正向索引类似于数据库中基于ID创建的索引,在检索的时候如果搜索的是非索引字段,必须得逐行扫描进行检索再进行匹配(先找文档,再根据文档判断是否包含词条);
倒排索引与正向索引相反,它创建的索引是对内容进行分词,得到词条对词条创建索引,然后记录词条所在的文档的信息,查询的时候先根据词条找到文档的ID,然后再根据ID找到文档;
ES索引、映射
ES索引就是相同类型文档的集合;(类似于数据库里的表)这种结构在数据库中叫表结构,在ES中称为索引的映射;(映射mapping:索引中文档字段的约束信息,类似于表的结构约束)
ES与数据库对比:
概念: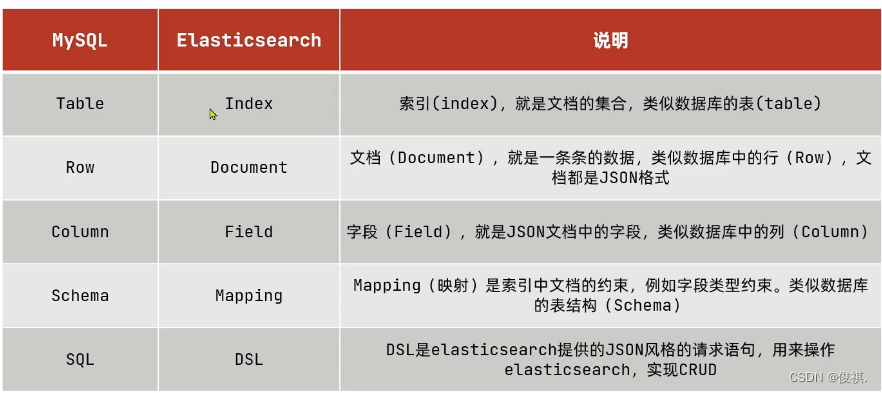
架构:
MYSQL:擅长事务类型操作,可以确保数据的安全和一致性;
ES:擅长海量数据的搜索,分析,计算;
(一般搭配使用,增删改mysql,查询es)
总结:
文档:一条数据就是一个文档,es中是json格式的;
字段:就是json中的一个个字段,字段会有约束称为映射mapping
索引:同类型文档的集合
映射:索引中文档的约束,比如字段名称,类型
es与数据库的关系:互补关系,数据库负责事务类型操作,es负责海量数据搜索、分析、计算;
(对于业务量比较大,搜索需求比较复杂的场景,才需要实现两个搭配使用,简单的查询比如根据id查询,用数据库就行了)
部署
1.部署单点es:
1.1创建网络
docker network create es-net
1.2加载镜像
docker pull elasticsearch:7.12.1
(或者下载tar包解压安装)docker load -i es.tar
同理,kibana的tar包也需要这样做(kibanan主要是为了方便些DSL语句)
1.3运行docker命令,部署单点es
docker run -d \ # 运行,-d后台运行;
--name es \ # 给容器起的名字;
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ # -e设置环境变量 配置JVM的堆内存大小,默认值是1G,ES对内存的消耗比较大,512M不能再小了,否则可能会出现问题;
-e "discovery.type=single-node" \ # 运行模式,单点模式,集群的话这里要改
-v es-data:/usr/share/elasticsearch/data \ # 数据卷挂载 data将来es数据的保存目录
-v es-plugins:/usr/share/elasticsearch/plugins \ # # 数据卷挂载 plugins插件目录
--privileged \
--network es-net \ # 让es容器加入到这个网络当中
-p 9200:9200 \ # 暴露端口 9200暴露的http协议端口,供用户访问用
-p 9300:9300 \ # es容器各个节点互联的端口
elasticsearch:7.12.1 # 镜像名称
2.部署kibana
kibana要和es在同一个网络当中,就上上面我们创建的网络es-net
2.1:拉取镜像
docker pull kibana:7.12.1
2.2:运行docker命令,部署单点kibana
docker run -d \ # 运行,后台运行;
--name kibana \ # 给容器起名;
-e ELASTICSEARCH_HOSTS=http://es:9200 \ # 环境变量,指定ES的地址,这里的es就是刚才创建es容器的名称;因为在同一个网络,所以可以用容器名互联;未来kibana要操作es所以要知道es容器的名称和地址;
--network=es-net \ # 加入和es相同的网络
-p 5601:5601 \ # 端口
Kinbana:7.12.1 # kibana版本,kibana版本一定要和es版本一致;
运行比较慢,可以用命令:
docker logs -f kibana
查看日志
3.安装分词器
3.1:安装IK插件(在线安装)
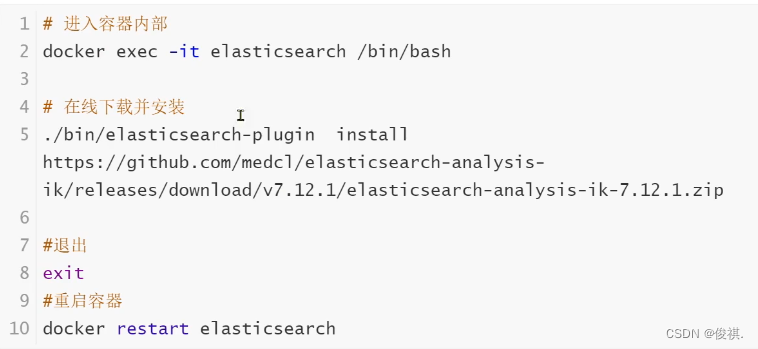
或离线安装(比较快(推荐))
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
显示结果:
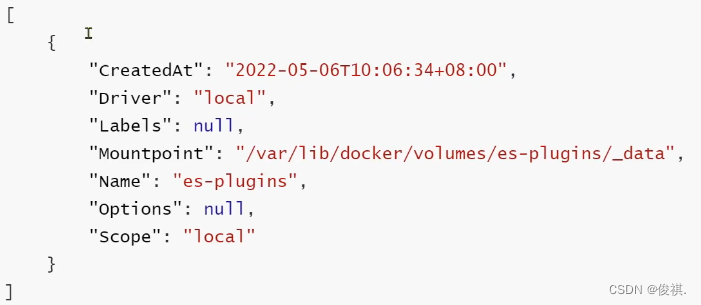
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中;然后解压分词器的安装包,重命名为ik,再上传到对应的目录中,最后重启容器;
docker restart es
ik分词器包含两种模式:
ik_smart:最少切分(粗粒度,分词少)
ik_max_word:最细切分(细粒度,分词多)
ik分词器词典词语扩展和停用:
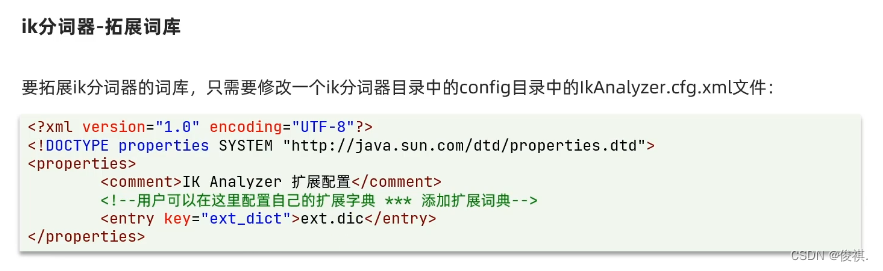
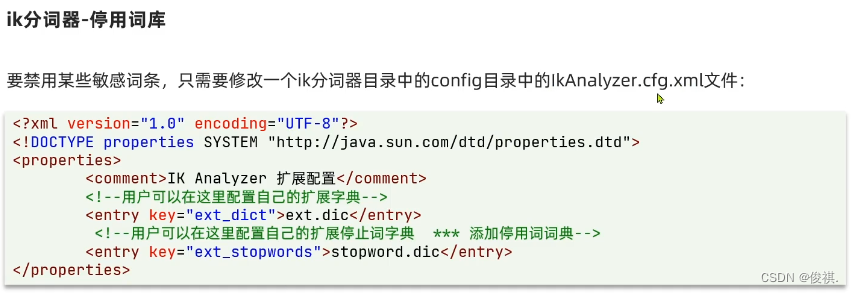 打开ik分词器的config目录下的ikAnalyzer.cfg.xml文件
打开ik分词器的config目录下的ikAnalyzer.cfg.xml文件 
给以下两个标签添加扩展词典和停用词典的文件
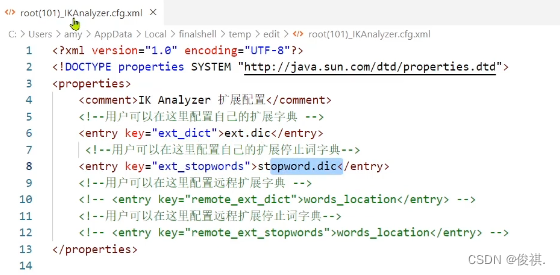
在ik/config目录下创建对应的扩展词的.dic文件,创建后打开并把扩展词添加进去

停用词文件打开,添加自定义停用词,后期分词就不会用这些词了;
配置好之后重启es即可生效。
总结:
索引库映射属性:




索引库创建:

文档操作相关语法:

Java操作ES的客户端RestClient
初始化JavaRestClient:
1.引入es的RestHighLevelClient依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>
2.因为springBoot默认ES版本是7.6.2,所以需要覆盖默认的ES版本
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3.初始化RestHighLevelClient:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.37.128:9200"),
HttpHost.create("http://192.168.37.128:9200"),
HttpHost.create("http://192.168.37.128:9200")
//如果是集群的话这里可以指定多个地址
));
操作索引库相关:restHighLevelClient.indices()对索引库相关操作
创建索引库
public class Test {
@Autowired
private RestHighLevelClient client;
@Test
public void createXXXIndex() throws IOException {
//1.创建Request对象;
CreateIndexRequest request = new CreateIndexRequest("XXX索引库名称");
//2.准备请求的参数:DSL语句
request.source("创建索引库的DSL语句", XContentType.JSON);
//3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
}
删除索引库
public class Test01 {
@Autowired
private RestHighLevelClient client;
@Test
public void deleteIndex() throws IOException {
//1.创建request对象
DeleteIndexRequest request = new DeleteIndexRequest("索引库名称");
//2.发起请求
client.indices().delete(request,RequestOptions.DEFAULT);
}
}
判断索引库是否存在
@Autowired
private RestHighLevelClient client;
@Test
public void existsIndex() throws IOException {
//1.创建request对象
GetIndexRequest request = new GetIndexRequest("索引库名称");
//2.发起请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
//3.输出
System.err.println(exists?"索引库存在":"索引库不存在");
}
}
文档操作相关:
给索引库中添加文档:restHighLevelClient.index()对索引库中文档相关操作
public class Test01 {
@Autowired
private RestHighLevelClient client;
@Test
public void testIndexDoc() throws IOException {
//1.准备index
IndexRequest request = new IndexRequest("索引库名称").id("1");
//2.准备json文档
request.source("JSON文档数据",XContentType.JSON);
//3.发送请求
client.index(request,RequestOptions.DEFAULT);
}
}
根据id在索引库中查询文档:(文档为JSON所需要用到反序列化)
public class Test01 {
@Autowired
private RestHighLevelClient client;
@Test
public void testGetDocById() throws IOException {
//1.创建request
GetRequest request = new GetRequest("索引库名称","id");
//2.发送请求,得到结果
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3.解析结果
String jsonString = response.getSourceAsString();
//4.反序列化为对象
User user = JSON.parseObject(jsonString, User.class);
//输出
System.out.println(user);
}
}
根据id修改索引库中的文档:

根据id删除文档:
public class Test01 {
@Autowired
private RestHighLevelClient client;
@Test
public void testDelDocById() throws IOException {
//1.准备request
DeleteRequest request = new DeleteRequest("索引库名称","id");
//2.发送请求
client.delete(request,RequestOptions.DEFAULT);
}
}
总结:文档操作的基本流程

批量导入文档:
思路:1.利用Mybatis-Plus查询所有数据;2.将查询的数据转化成文档类型数据;3.利用restHighLevelClient中的Bulk批处理,实现批量新增文档。
public class Test01 {
@Autowired
private RestHighLevelClient client;
@Autowired
private UserService userService;
@Test
public void testDelDocById() throws IOException {
//批量查询数据
List<User> list = userService.list();
//准备request
BulkRequest request = new BulkRequest();
for (User user : list) {
//转换为文档类型
UserDoc userDoc = new UserDoc(user);
//添加数据
request.add(new IndexRequest("索引库名称")
.id(userDoc.getId().toString())
.source(JSON.toJSONString(userDoc),XContentType.JSON));
}
//request.add(new IndexRequest("索引库名称").id("id").source("文档的JSON字符串",XContentType.JSON));
//request.add(new IndexRequest("索引库名称").id("id").source("文档的JSON字符串",XContentType.JSON));
//request.add(new IndexRequest("索引库名称").id("id").source("文档的JSON字符串",XContentType.JSON));
//发送请求
client.bulk(request,RequestOptions.DEFAULT);
}
}


















 7140
7140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









