






 本文深入探讨MapReduce的分布式模型,介绍了其外部物理结构,并详细解析了MapReduce 2.0的架构,帮助理解这一大数据处理的关键技术。
本文深入探讨MapReduce的分布式模型,介绍了其外部物理结构,并详细解析了MapReduce 2.0的架构,帮助理解这一大数据处理的关键技术。
1.MapReduce
特点
–
易于编程
–
良好的扩展性
–
高容错性
–
适合
PB
级以上海量数据的离线处理
2.MapReduce的分布式模型:

3.外部物理结构
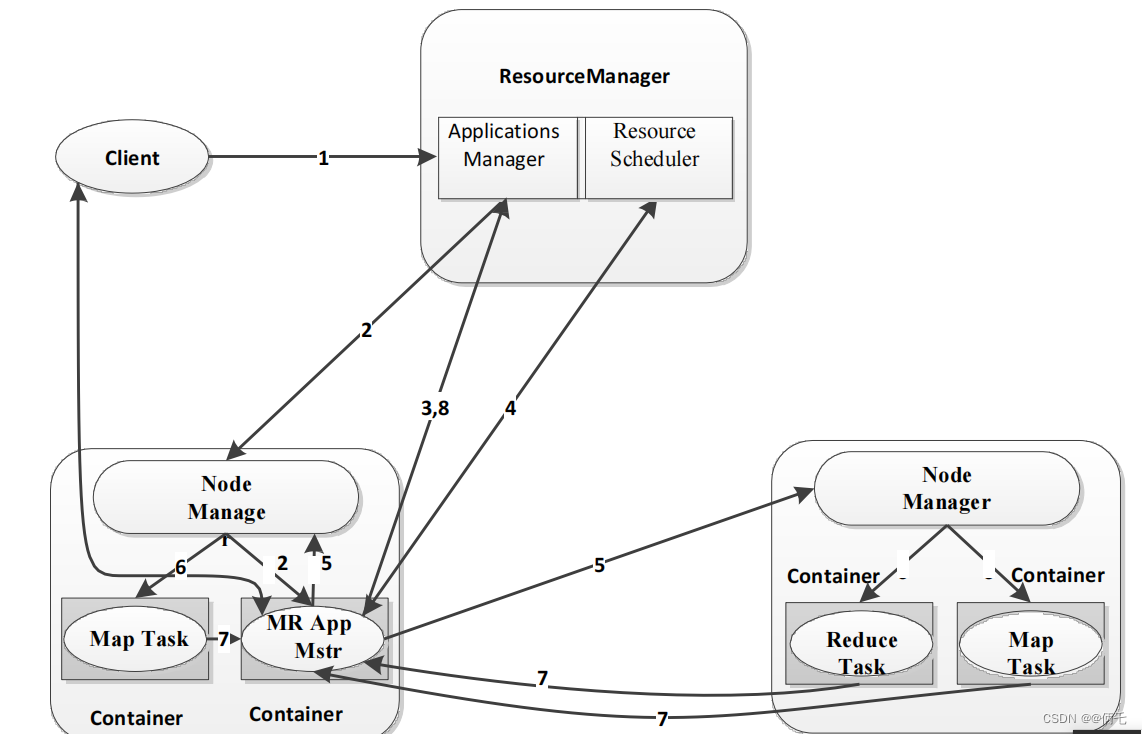
 4.MapReduce 2.0架构
4.MapReduce 2.0架构
•
Client
–
用户通过
Client
与
YARN
交互,提交
MapReduce
作业,查询
作业运行状态,管理作 业等
•
MRAppMaster
–
任务划分、资源申请并将资源二次分配给
Map Task
和
Reduce Task、进行任务状态监控和容错
5.MapReduce
计算框架:推测执行机制
•
作业完成时间取决于最慢的任务完成时间
–
一个作业由若干个
Map
任务和
Reduce
任务构成
–
因硬件老化、软件
Bug
等,某些任务可能运行非常慢
•
推测执行机制
–
发现某个任务运行速度远慢于任务平均速度就为拖后腿任务
启动一个备份任务,同时运行
–
谁先运行完,则采用谁的结果
•
不能启用推测执行机制
–
任务间存在严重的负载倾斜
–
特殊任务,比如任务向数据库中写数据
6.MapReduce
的限制(缺点)
•
不适合实时计算
–
要求毫秒级或者秒级内返回结果
•
不适合流式计算
–
MapReduce
的输入数据集是静态的,不能动态变化
–
MapReduce
自身的设计特点决定了数据源必须是静态的
•
不适合
DAG
计算
–
多个应用程序存在依赖关系,后一个应用程序的 输入为前一个的输出
7.常见
MapReduce
应用场景
•
简单的数据统计,比如网站
pv
、
uv
统计
•
搜索引擎建索引
•
海量数据查找
•
复杂数据分析算法实现
–
聚类算法
–
分类算法
–
推荐算法
–
图算法

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









