






 本文介绍了如何在阿里云服务器上通过Docker容器化部署MySQL,配置Prometheus监控Mysql性能,并通过Grafana可视化监控数据,包括创建用户权限、安装探针及配置Grafana主题。
本文介绍了如何在阿里云服务器上通过Docker容器化部署MySQL,配置Prometheus监控Mysql性能,并通过Grafana可视化监控数据,包括创建用户权限、安装探针及配置Grafana主题。
阿丹:
在开发和生产环境中有可能会出现慢mysql等问题,那么这里就需要我们优秀的程序员来进行监控和解决,那么如何借助云原生的监控系统来完成这个操作呢?
环境描述:
使用一台空白的阿里云服务器2核4G。
服务器基本安装配置-docker容器化
关闭防火墙
systemctl stop firewalld安装流程按照我之前写的文章来进行,我这里直接附上文章链接
安装docker
配置Linux服务器华为云耀云服务器之docker安装,以及环境变量安装 java (虚拟机一样适用)_华为云安装docker-优快云博客
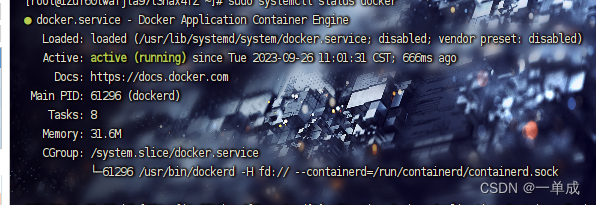
安装Mysql5:7
配置Linux服务器华为云耀云服务器之docker中Mysql5.7、redis安装 (虚拟机一样适用)_云耀云服务器开放3306-优快云博客
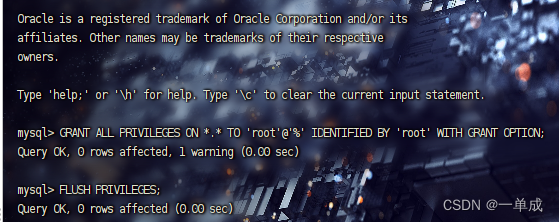
安装普罗米修斯并监控mysql
Prometheus安装挂载数据卷
Prometheus技术文档--基本安装-docker安装并挂载数据卷-《十分钟搭建》_一单成的博客-优快云博客
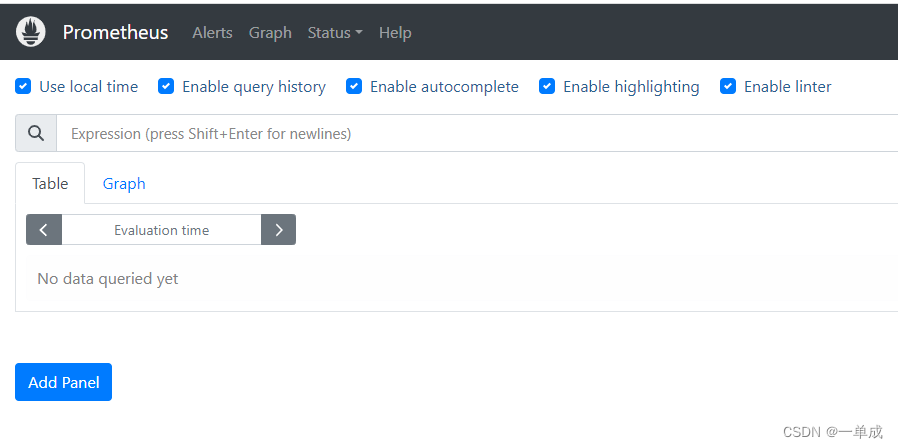
访问ip+9090出现以下页面完成安装
Grafana安装挂载数据卷
Grafana技术文档--基本安装-docker安装并挂载数据卷-《十分钟搭建》-附带监控服务器_一单成的博客-优快云博客
访问ip+3000,出现页面完成Grafana安装
在这一步的时候使用Grafana,在上面搜索框直接搜索Data sources将普罗米修斯设置为数据源,因为上面链接中有这里就不过多的说了。
docker中拉取mysql的探针
docker pull prom/mysqld-exporter
运行探针
首先创建一个专门用来监控的用户并授权
进入docker的mysql容器
docker exec -it 容器的id bash登录root用户
mysql -u root -p输入密码后执行下面的指令
CREATE USER 'mysql_monitor'@'%' IDENTIFIED BY 'adn666' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysql_monitor'@'%';
FLUSH PRIVILEGES;
EXIT
这段SQL语句用于在MySQL数据库中创建一个名为'mysql_monitor'的用户,并给予该用户一些权限。让我逐行解释一下:
-
CREATE USER 'mysql_monitor'@'%' IDENTIFIED BY 'adn666' WITH MAX_USER_CONNECTIONS 3;- 这行代码创建一个名为'mysql_monitor'的用户,并且定义了用户的身份验证方式(密码)为'adn666'。
'localhost'指定了该用户只能从本地主机连接到MySQL服务器。WITH MAX_USER_CONNECTIONS 3限制了该用户可以同时建立的最大连接数为3个。
-
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysql_monitor'@'localhost';- 这行代码将一些权限授予'mysql_monitor'用户。
PROCESS权限允许该用户查看当前正在运行的MySQL进程。REPLICATION CLIENT权限允许该用户连接到MySQL复制服务器以获取复制相关的信息。SELECT权限允许该用户在所有的数据库和表上执行SELECT查询语句。
-
FLUSH PRIVILEGES;- 这行代码用于刷新MySQL权限表,以使新的用户和权限设置生效。
-
EXIT- 这行代码用于退出MySQL命令行终端。
这些语句的目的是创建一个具有特定权限的MySQL用户,并确保这些权限生效。你可以根据自己的需求修改用户名、密码和授权的权限。
使用我们创建好的用户来启动探针
docker直接运行探针(出现问题)
GitHub - percona/mysqld_exporter: Exporter for MySQL server metrics
下面的这个就是官网提供的但是阿丹运行报错
docker network create my-mysql-network
docker pull prom/mysqld-exporter
docker run -d \
-p 9104:9104 \
--network my-mysql-network \
-e DATA_SOURCE_NAME="user:password@(hostname:3306)/" \
prom/mysqld-exporter 根据实践总是出现有这个.my.cnf的配置文件找不到。在这里留个坑希望有大神可以解答一下。
根据实践总是出现有这个.my.cnf的配置文件找不到。在这里留个坑希望有大神可以解答一下。
使用从官网上下拉代码
wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.12.1/mysqld_exporter-0.12.1.linux-amd64.tar.gz解压
tar xf mysqld_exporter-0.12.1.linux-amd64.tar.gz -C /usr/local/移动
ln -sv /usr/local/mysqld_exporter-0.12.1.linux-amd64/ /usr/local/prometheus_mysqld编写配置文件,根据刚才我们新建的用户来完成配置
#编辑配置文件
vim /usr/local/prometheus_mysqld/.my.cnf
#配置文件中内容
[client]
user=mysql_monitor #刚才新建的用户
password=adn666 #密码
port=3306 #端口号,如果不写ip地址(host)的话默认就是本机
配置systemd启动mysqld_exporter
vim /lib/systemd/system/mysqld_exporter.service下面为配置文件
[Unit]
Description=Mysqld_exporter
After=network.target
[Service]
ExecStart=/usr/local/prometheus_mysqld/mysqld_exporter --config.my-cnf=/usr/local/prometheus_mysqld/.my.cnf
[Install]
WantedBy=multi-user.target加入并启动,系统
systemctl daemon-reloadsystemctl start mysqld_exportersystemctl enable mysqld_exporter检查是否正常运行
ss -lnpt|grep 9104 出现如下项目没有问题
使用ip地址+9104出现以下页面
确认监控指标正常
curl http://localhost:9104/metrics|grep mysql_up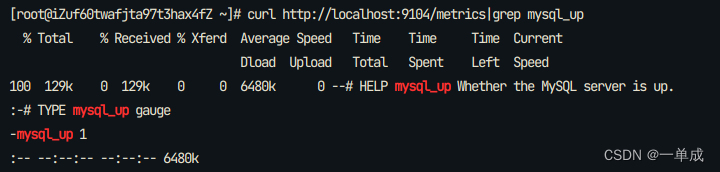
那么我们下面就是在我们普罗米修斯中配置这个任务
在普罗米修斯中配置文件
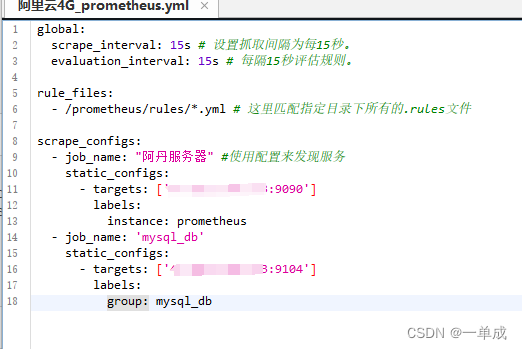
修改这个配置
- job_name: 'mysql_db'
static_configs:
- targets: ['mysqlIP:9104']
labels:
group: mysql_db修改配置之后重启普罗米修斯的docker容器
访问ip+9090//targets查看
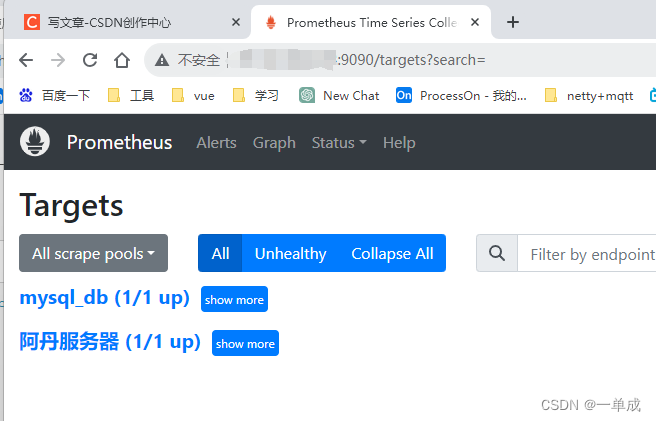
出现如上页面就是可以了!
开始配置Grafana的主题-使用导入json的形式
阿丹:
我这里准备了一个别人整理好的,我这里就直接拿过来使用了。
这个json文件我放在本文章的资源中了。直接拿取就可以,然后我们就使用上就可以了跟着我的步骤来。
注意:
有两个方式来发现,一种是图表的形式来使用的,另外一种是使用配置预警规则来警告的。这里我们使用是监控图表的方式。(第二种方式阿丹后期会更新的)
我们可以直接在上面搜索这里直接搜索import
直接将本文章中的json文件拖入就可以了,(前提是在安装的时候已经将数据来源设置为了我们安装好的普罗米修斯)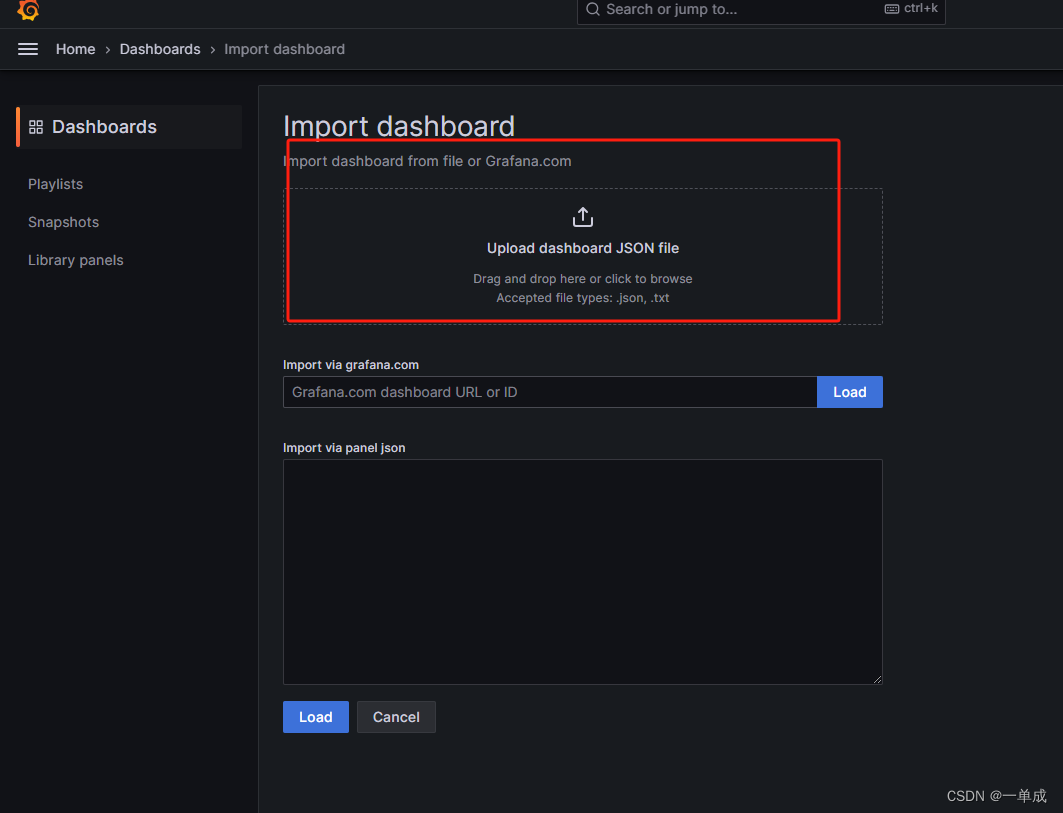
这里就是配置好了出现的面板
其中我们要使用到的就是这里!!



















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









