






Elasticsearch
文章目录
介绍
目前全文搜索引擎的首选,其基于倒排索引机制可以快速的存储,搜索和分析海量数据
Elastic的底层是开源库Lucene
https://www.cnblogs.com/buchizicai/p/17093719.html
用途
- 搜索引擎
- 日志处理分析
- 指标和容器监测
- 性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
基本概念
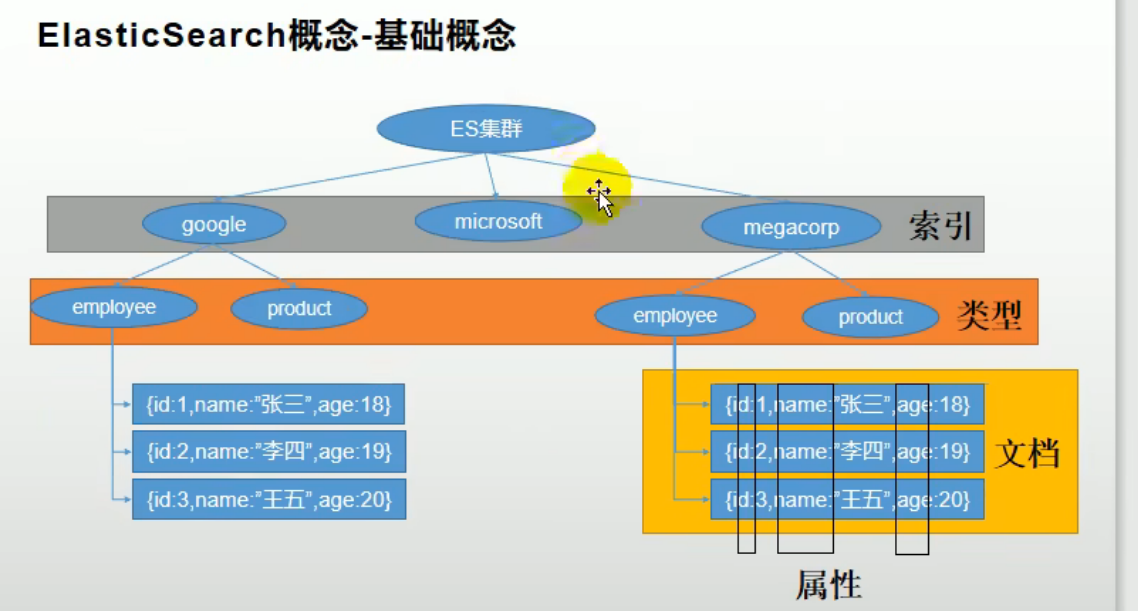
-
索引(Index)
做动词,相当于mysql中的insert名词,相当于mysql中的Database
-
类型(Type)
在一个Index中可以定义一个或者多个类型。
有点像数据库中的表(Table)
每一种类型的数据放在一起
-
文档(Document)
保存于某个Index下,某种Type的一个数据Document,文档是Json格式
相当于mysql中的某个Table里面的内容
用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
-
词条(Term)
对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
-
倒排索引机制
-
概念:将文档中的词语term映射到包含该词语的文档集合
-
与传统的正排索引不同,倒排索引将词语和文档的映射关系倒转,便于快速查找包含特定词语的文档
-
原理:
文档1:
Elasticsearch is a distributed search engine文档2:
Elasticsearch provides full-text search倒排索引示例如下:
词语 文档ID(包含该词语的文档) Elasticsearch 1, 2 is 1 a 1 distributed 1 search 1, 2 engine 1 provides 2 full-text 2 工作原理:
1.分词:
在将文档加入倒排索引之前首先会对文档进行分词处理,即将文本分割成一个个的单词,再小写化,去除停用词,词干提取
2.建立倒排索引:
将这些词条与包含他们的文档ID建立映射关系- 词条(term)。
- 包含该词条的文档ID列表。
- 每个词条在文档中的出现频率(term frequency)。
- 词条在文档中的位置(position)。
例如,对于词
Elasticsearch,倒排索引将会记录它在文档 1 和文档 2 中都出现过。3.查询过程:
当用户发起查询时,Elasticsearch 会根据查询中的词条查找倒排索引,找到包含这些词条的文档ID集合。接着,它会对这些文档进行排序(根据相关性评分等因素),最终返回最匹配的文档。
-
安装
1.安装ES
-
下载镜像
docker pull elasticsearch:7.4.2 -
创建本地挂载目录
mkdir -p /mydata/elasticsearch/config mkdir -p /mydata/elasticsearch/data mkdir -p /mydata/elasticsearch/plugins -
配置ES可以被远程的任何机器访问
echo "http.host: 0.0.0.0">> /mydata/elasticsearch/config/elasticsearch.yml -
更改文件权限
[root@hgwtencent elasticsearch]# chmod -R 777 /mydata/elasticsearch/ [root@hgwtencent elasticsearch]# ll 总用量 12 drwxrwxrwx 2 root root 4096 3月 24 19:50 config drwxrwxrwx 2 root root 4096 3月 24 19:50 data drwxrwxrwx 2 root root 4096 3月 24 19:57 plugins -
运行es命令
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2说明:
--name : 为容器起一个名字为elasticsearch,-p暴露两个端口 9200 9300, 9200是发送http请求——restapi的端口; 9300是es在分布式集群状态下,结点之间的通信端口, -e "discovery.type=single-node" : 是以单节点方式运行, -e ES_JAVA_OPTS="-Xms64m -Xmx128m" : 指定初始64m,最大占用128m; ES_JAVA_OPTS不指定的话,es一启动,会将内存全部占用,整个虚拟机就卡死了, -v : 进行挂载,目录中配置,数据等一一关联 -d 后台启动es使用指定的镜像 -
查看是否开启
访问 “ip:9200”
2.安装ES可视化工具kibadn
-
下载镜像
docker pull kibana:7.4.2 -
运行
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://ip:9200 -p 5601:5601 -v /path/to/your/kibana.yml:/usr/share/kibana/config/kibana.yml -d kibana:7.4.2这个IP要改为es的运行地址
修改kibana.yml文件并添加配置,重启之后可以实现汉化
i18n.locale: "zh-CN" -
验证是否成功
访问5601端口
初步检索
Elasticsearch 是一个基于 Lucene 的分布式搜索和分析引擎,广泛应用于实时搜索、日志分析、数据挖掘等场景。你提到的几个概念是 Elasticsearch 中常见的操作,下面是对它们的简要讲解:
1. _cat(Cat API)
Elasticsearch 提供了一个名为 _cat 的 API,用于快速获取集群的状态、节点信息、索引状态等,以便进行诊断和管理。_cat API 返回的是易于阅读的文本格式,通常用于监控和调试。
常用的 _cat 命令包括:
GET /_cat/indices:列出所有索引的状态、文档数量等信息。GET /_cat/nodes:列出集群节点的状态、内存、磁盘等信息。GET /_cat/health:返回集群的健康状态(例如,绿色、黄色、红色)。GET /_cat/master:查看主节点
2. 索引一个文档
在 Elasticsearch 中,PUT 和 POST 方法都可以用于索引文档,但它们之间的主要区别在于 是否指定文档的 ID 和 用法的语义。以下是两者的具体区别和适用场景:
1. PUT 方法
- 语义:
PUT方法表示一种幂等操作。多次执行相同的PUT请求,其结果是相同的(不会产生重复的文档)。 - 是否需要指定 ID:使用
PUT索引文档时,必须显式指定文档的 ID。 - 用法:适用于你希望自己控制文档 ID 的场景。
示例:
PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30
}
响应:
{
"_index": "my_index", // 索引名称,表示文档属于 "my_index" 索引
"_type": "_doc", // 文档类型,Elasticsearch 7.x 之后固定为 "_doc"
"_id": "1", // 文档唯一标识符,表明操作的是 ID 为 "1" 的文档
"_version": 2, // 文档版本号,表示这是该文档的第 2 个版本
"result": "updated", // 操作结果,此处表示文档已被更新
"_shards": { // 分片处理信息
"total": 2, // 涉及的分片总数(主分片和副本分片)
"successful": 1, // 成功写入的分片数,此处表示主分片写入成功
"failed": 0 // 失败的分片数,表示没有发生写入错误
},
"_seq_no": 1, // 分片中的操作顺序编号,用于内部版本控制(从 0 开始)
"_primary_term": 1 // 主分片的领导权变更次数,此处表示从未重新分配主分片
}
行为:
- 如果文档 ID 为
1的文档已存在,则会覆盖它(替换整个文档)。 - 如果不存在,则会创建一个新的文档。
2. POST 方法
- 语义:
POST方法表示一种非幂等操作。每次执行相同的POST请求可能会生成不同的结果(例如,会为每个文档生成不同的 ID)。 - 是否需要指定 ID:使用
POST索引文档时,可以让 Elasticsearch 自动生成文档 ID(这也是主要区别之一)。 - 用法:适用于你不关心文档 ID 或希望 Elasticsearch 自动生成唯一 ID 的场景。
- 不带id,或者带id但之前没数据为新增操作,带id并且之前有数据为修改操作
示例:
POST /my_index/_doc
{
"name": "Jane Doe",
"age": 25
}
行为:
- Elasticsearch 自动为该文档生成一个唯一的 ID。
- 不会覆盖已有文档,因为每次生成的 ID 都是新的。
3. 查询文档
Elasticsearch 提供了强大的查询功能,可以根据各种条件检索存储在索引中的文档。常用的查询 API 是 search API。
示例请求:
GET /索引/_doc/标识id
响应:
{
"_index": "my_index", // 索引名称,表明文档存储在 "my_index" 索引中
"_type": "_doc", // 文档类型(7.x 后固定为 "_doc")
"_id": "1", // 文档的唯一标识符,此处为 "1"
"_version": 3, // 文档的版本号,此文档已经被更新了两次
"_seq_no": 2, // 操作在分片中的顺序编号(从 0 开始)
"_primary_term": 1, // 主分片的领导权变更次数
"found": true, // 表示文档是否存在,true 表示找到该文档
"_source": { // 存储的文档内容(用户定义的数据部分)
"name": "John Doe", // 文档字段 "name",值为 "John Doe"
"age": 30 // 文档字段 "age",值为 30
}
}
-
并发控制字段:
Elasticsearch 提供了几个字段来帮助处理并发操作,以确保数据一致性,尤其是在多个客户端同时对同一文档执行更新、删除等操作时。这些字段包括:
- _version:
- 每次更新文档时,该字段会自动递增(从 1 开始)。
- 客户端可以通过指定
_version来控制并发写入。只有当客户端指定的版本与服务器上的版本一致时,操作才会成功;否则会报version_conflict_engine_exception错误。 - 用途:用于乐观锁(见下文)。
- _seq_no(操作顺序编号):
- 每个分片内的操作都有唯一的
_seq_no(从 0 开始)。 - 用于按顺序跟踪分片中的变更操作。
_seq_no主要在 Elasticsearch 内部使用,不需要客户端手动指定。
- 每个分片内的操作都有唯一的
- _primary_term(主分片变更次数):
- 用于跟踪主分片的领导权变更。
- 当主分片迁移到另一个节点时,该值会递增。
- 与
_seq_no一起确保分布式系统中的数据一致性。
- _version:
-
乐观锁:
概念:一种控制并发写入的机制,依赖于version或seq_no+primary_term的一致性检查来确保数据不被覆盖。如何工作?
- 乐观假设:认为在处理过程中,数据通常不会被其他线程修改。
- 检查一致性:更新操作前,客户端会验证当前数据的版本号是否与预期一致。
- 如果一致,执行更新操作。
- 如果不一致,则表示数据已经被其他客户端修改(此时需要重新获取_seq_no),更新操作会失败。
通过 _seq_no 和 _primary_term 使用乐观锁-
Elasticsearch 6.x 引入了基于
_seq_no和_primary_term的乐观锁,7.x 开始取代_version。 -
客户端需要指定
if_seq_no和if_primary_term:PUT /my_index/_doc/1?if_seq_no=2&if_primary_term=1 { "name": "John Doe", "age": 35 } -
只有当分片的
_seq_no为2且_primary_term为1时,更新操作才会成功。
4. 更新文档
全量修改
直接覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成新增操作了
语法
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
增量修改
修改指定id匹配的文档中的部分字段
带_update就会对比原来的数据,如果与原来的一样就什么都不做,version,seq_no都不变
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
5. 删除文档&索引
删除单个文档
DELETE /<index>/_doc/<id>
删除指定 ID 的文档。
{
"_index": "my_index", // 文档所属的索引
"_type": "_doc", // 文档类型(7.x 后固定为 _doc)
"_id": "1", // 被删除文档的 ID
"_version": 2, // 文档的版本号,删除后版本号会递增
"result": "deleted", // 表示删除成功
"_shards": { // 分片信息
"total": 2, // 总分片数
"successful": 1, // 成功执行操作的分片数
"failed": 0 // 失败的分片数
},
"_seq_no": 2, // 操作在分片中的顺序号
"_primary_term": 1 // 主分片的领导权变更次数
}
删除索引中的所有文档
1.重建索引
示例请求删除索引:
DELETE /my_index
删除整个索引及其所有文档。
再创建:
PUT /my_index
2.使用_delete_by_query
根据查询条件删除符合条件的文档(可以删除整个索引内的所有文档)。
POST /my_index/_delete_by_query
{
"query": {
"match_all": {} // 匹配所有文档,等同于清空索引
}
}
6. bulk 批量 API
批量操作可以提高执行多个操作的效率,bulk API 允许一次性执行多个索引、更新、删除操作。
示例请求:
POST /_bulk
{ "index": { "_index": "my_index", "_id": 1 } }
{ "name": "John Doe", "age": 31 }
{ "delete": { "_index": "my_index", "_id": 2 } }
在这个例子中,批量请求会执行两项操作:索引一个新文档和删除一个文档。bulk API 非常适合用在需要处理大量文档的场景中,比如导入数据、日志处理等。
进阶检索
SearchApi检索文档
通过REST request uri发送请求参数
GET bank/_search?q=*&sort=account_number:asc
GET bank/_search:检索bank下所有信息,包括type和docsq=*: 查询所有sort:排序字段asc:升序
响应:
{
"took": 4, // 查询耗时(毫秒),表示从请求到响应所用的时间。
"timed_out": false, // 查询是否超时,false 表示未超时。
"_shards": { // 分片信息,包含查询操作涉及的分片详情。
"total": 1, // 总分片数,此次查询涉及的分片总数为 1。
"successful": 1, // 成功响应的分片数,此处为 1。
"skipped": 0, // 跳过的分片数,通常在跨索引查询时会发生。
"failed": 0 // 查询失败的分片数,此处为 0,表示所有分片查询成功。
},
"hits": { // 查询匹配到的文档相关信息。
"total": { // 匹配到的文档总数。
"value": 1, // 匹配的文档数,此处为 1。
"relation": "eq" // 匹配关系,eq 表示精确匹配的数量。
},
"max_score": null, // 最大相关性得分,排序不是基于相关性时为 null。
"hits": [ // 匹配到的文档数组,每个元素表示一条文档。
{
"_index": "my_index", // 文档所在的索引名称。
"_type": "_doc", // 文档的类型,在 Elasticsearch 7.x 及以上版本中固定为 _doc。
"_id": "1", // 文档的唯一标识符。
"_score": null, // 相关性得分,由于排序基于其他字段,此处为 null。
"_source": { // 文档的具体内容。
"name": "John Doe", // 文档中 name 字段的值。
"age": 30 // 文档中 age 字段的值。
},
"sort": [ // 排序依据字段的值,此查询按 age 字段排序。
30 // 排序字段 age 的值为 30。
]
}
]
}
}
通过REST request body发送请求参数
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" },
{ "balance":"desc"}
],
"from": 10,
"size": 10
}
响应结果的格式和第一种方法是一样的
DSL语言
概念:domain Specialed Lanaguage 在特定领域的语言
查询所有(match_all)
GET /index/_search
{
"query": {
"match_all": {}
},
"sort": [
{ "age": { "order": "asc" } } // 按年龄升序排序
]
"from": 0, // 跳过的文档数
"size": 5 // 返回的文档数
}
响应结果:
{
"took": 5, // 查询耗时(毫秒)
"timed_out": false, // 查询是否超时
"_shards": { // 分片的执行情况
"total": 1, // 总分片数
"successful": 1, // 成功的分片数
"skipped": 0, // 跳过的分片数
"failed": 0 // 失败的分片数
},
"hits": {
"total": { // 总命中文档数
"value": 2, // 文档总数
"relation": "eq" // 总数关系("eq" 表示精准)
},
"max_score": 1.0, // 最高得分(在 match_all 查询中,所有文档的 _score 默认是 1,因为没有筛选条件,也没有相关性计算)
"hits": [ // 匹配的文档列表
{
"_index": "my_index", // 索引名称
"_type": "_doc", // 文档类型(7.x 后始终为 "_doc")
"_id": "1", // 文档 ID
"_score": 1.0, // 文档相关性得分
"_source": { // 文档的实际内容
"name": "John Doe",
"age": 30
}
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"name": "Jane Doe",
"age": 25
}
}
]
}
}
匹配查询(match)
用于精确控制以及全文检索
GET /index/_search
{
"query": {
"match": {
"字段名": "查询内容"
}
}
}
match 查询 是 Elasticsearch 中的一种常用查询类型,专用于执行全文搜索(Full-Text Search)。它支持对文本字段进行模糊匹配,并根据查询词的相关性计算匹配结果的得分。
match 查询的特点
- 用于全文搜索,支持分词。
- 适用于
text类型字段。 - 会对查询内容进行分词处理,再匹配文档中的分词结果。
- 默认计算相关性得分,结果按相关性排序。
match 查询的基本语法
{
"query": {
"match": {
"字段名": "查询内容"
}
}
}
- 字段名:指定要查询的字段名(必须是
text类型或支持全文搜索的字段)。 - 查询内容:输入的查询字符串,Elasticsearch 会对其进行分词处理。
示例
假设索引中的文档结构如下:
{
"title": "Elasticsearch is a powerful search engine",
"content": "It supports full-text search and analytics."
}
查询字段 content 包含 full-text search 的文档:
{
"query": {
"match": {
"content": "full-text search"
}
}
}
# 查询内容会被分词为 `["full-text", "search"]`。
# Elasticsearch 会匹配 `content` 字段中是否包含这些分词,并计算得分。
match 查询的参数
1. 操作符(operator)
- 默认值:
OR。 - 决定查询词是否都需要匹配(
AND),还是只需匹配一个(OR)。
示例:
{
"query": {
"match": {
"content": {
"query": "full-text search",
"operator": "AND"
}
}
}
}
operator: OR:查询的文档只需要包含full-text或search。operator: AND:查询的文档必须同时包含full-text和search。
2. 最小匹配百分比(minimum_should_match)
- 指定查询结果中必须匹配的最小查询词比例或数量。
示例:
{
"query": {
"match": {
"content": {
"query": "full-text search powerful",
"minimum_should_match": "75%"
}
}
}
}
解释:
- 查询内容分词为
["full-text", "search", "powerful"]。 minimum_should_match: 75%表示至少匹配 2 个词(总词数的 75%)。
3. 查询提升(boost)
- 增加某个字段的权重,提高其在查询结果中的优先级。
示例:
{
"query": {
"match": {
"content": {
"query": "full-text search",
"boost": 2.0
}
}
}
}
解释:
boost: 2.0表示content字段的得分会乘以 2,使其更重要。
响应结果解释
以下是一个 match 查询的响应结果:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.23,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.23,
"_source": {
"content": "full-text search and analytics are supported."
}
}
]
}
}
关键字段解释:
- took:查询耗时(毫秒)。
- hits.total.value:匹配的文档总数。
- max_score:最高相关性得分。
hits:匹配的文档列表。- _score:当前文档的相关性得分。
- _source:返回的文档内容。
注意事项
- 分词机制:
match查询会使用字段定义的分词器(analyzer)进行分词。- 如果字段是
keyword类型,不会分词,建议使用term查询。
- 性能优化:
- 对大字段使用
match查询可能会影响性能,建议通过分页或限制返回结果数量优化。
- 对大字段使用
- 适用场景:
- 用于全文检索。
- 查询含模糊匹配的文本内容。
短语匹配(match_phrase)
GET /index/_search
{
"query": {
"match_phrase": {
"字段": "短语"
}
}
}
多字段查询(multi_match)
{
"query": {
"multi_match": {
"query": "搜索内容",
"fields": ["字段1", "字段2", "字段3"]
}
}
}
type参数
指定查询类型,常见的值包括:
best_fields(默认):返回最佳匹配字段的分数。most_fields:结合所有匹配字段的分数。cross_fields:将多个字段视为一个整体进行分词匹配。phrase:短语匹配。phrase_prefix:短语前缀匹配。
例如:
{
"query": {
"multi_match": {
"query": "Elasticsearch Basics",
"fields": ["title", "description"],
"type": "phrase"
}
}
}
字段权重
为某些字段设置更高的优先级(权重),使用 ^ 指定权重值。
示例:让 title 字段的权重是 description 字段的 2 倍。
{
"query": {
"multi_match": {
"query": "Elasticsearch",
"fields": ["title^2", "description"]
}
}
}
bool查询
基本语法:
{
"query": {
"bool": {
"should": [
{ "match": { "字段1": "搜索内容" } },
{ "match": { "字段2": "搜索内容" } }
]
# should:条件中的任意一个匹配即返回。
# must:所有条件必须匹配。
# must_not:条件必须不匹配。
}
}
}
结果过滤(filter)
一种高效的查询机制,主要用于返回符合条件的文档,而无需计算相关性评分(_score)。filter 通常用于布尔查询(bool 查询)中的 filter 子句。由于过滤器不计算相关性评分,因此性能更高,特别适合需要精确匹配或者限定范围的场景。
用法:
{
"query": {
"bool": {
"filter": [
{ "term": { "字段名": "值" } },
{ "range": { "字段名": { "gte": 值, "lte": 值 } } }
]
}
}
}
-
示例一:精确匹配
{ "query": { "bool": { "filter": { "term": { "status": "active" } } } } }使用
term查询字段status,只匹配精确等于"active"的文档。不计算
_score,只返回符合条件的文档。 -
示例二:范围查询
{ "query": { "bool": { "filter": { "range": { "age": { "gte": 20, "lte": 30 } } } } } }使用
range查询字段age,限制范围为 20 到 30。gte表示大于等于,lte表示小于等于。 -
示例三:组合查询
{ "query": { "bool": { "filter": [ { "term": { "status": "active" } }, { "range": { "age": { "gte": 20, "lte": 30 } } } ] } } }filter子句中可以包含多个条件,必须全部匹配。查询的结果包含满足所有过滤条件的文档。
-
示例四:exists查询
{ "query": { "bool": { "filter": { "exists": { "field": "email" } } } } }使用
exists过滤器,查找包含字段email的文档。
执行聚合(aggregations)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL GROUP BY和SQL聚合函数。在ES中,具有执行搜索返回hits(命中结果),并且同时返回聚合结果,把一个响应中的所有hits分隔开的能力。可以执行查询和多个聚合,并且再一次使用中得到各自的返回结果,使用一次简洁和API来避免网络往返
聚合语法:
"aggs":{ # 聚合
"aggs_name":{ # 这次聚合的名字,方便展示在结果集中
"AGG_TYPE":{} # 聚合的类型(avg,terms)
}
}
-
terms:看值的可能性分布,会合并锁查字段,给出计数即可
-
avg:看值的分布平均
-
简单例子:
-
搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情:
GET /bank/_search { "query": { # 查询出包含mill的 "match": { "address": "mill" } }, "aggs": { # 基于查询聚合 "ageAgg": { # 查询的名字,随便起 "terms": { # 看值的可能性分配 "field": "age", "size": 10 } }, "ageAvg":{ "avg": { # 看age值的平均 "field": "age" } } }, "size": 0 # 不看详情 }查询结果为:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, // 命中4条 "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "ageAgg" : { // 第一个聚合的结果 "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : 38, // age为38的有2条 "doc_count" : 2 }, { "key" : 28, "doc_count" : 1 }, { "key" : 32, "doc_count" : 1 } ] }, "ageAvg" : { // 第二个聚合的结果 "value" : 34.0 // 平均年龄 34 } } }
-
聚合分类:
- Metric Aggregations(指标聚合):计算数据指标,如平均值、最大值、最小值等。
- Bucket Aggregations(桶聚合):将文档分组到不同的“桶”中,每个桶代表一组匹配条件的文档。
- Pipeline Aggregations(管道聚合):基于其他聚合结果进行计算(如对某个指标聚合的结果再求平均)。
- Matrix Aggregations(矩阵聚合):处理多维数据(例如协方差)。
子聚合:
- 桶聚合可以包含子聚合,子聚合的作用是进一步分析每个桶中的数据。
- 子聚合既可以是指标聚合,也可以是桶聚合,允许嵌套结构。
执行顺序:
- 先执行桶聚合,将文档分组到不同的桶。
- 再在每个桶中执行指定的子聚合。
Elasticsearch 的 Aggregations(聚合) 提供了一种强大的功能,用于对数据进行统计分析和分组处理。通过聚合,用户可以快速生成类似 SQL 分组与聚合的统计数据,同时支持更加灵活和复杂的嵌套分析。
聚合的核心概念
- 聚合分类:
- Metric Aggregations(指标聚合):计算数据指标,如平均值、最大值、最小值等。
- Bucket Aggregations(桶聚合):将文档分组到不同的“桶”中,每个桶代表一组匹配条件的文档。
- Pipeline Aggregations(管道聚合):基于其他聚合结果进行计算(如对某个指标聚合的结果再求平均)。
- Matrix Aggregations(矩阵聚合):处理多维数据(例如协方差)。
- 子聚合:
- 桶聚合可以包含子聚合,子聚合的作用是进一步分析每个桶中的数据。
- 子聚合既可以是指标聚合,也可以是桶聚合,允许嵌套结构。
- 执行顺序:
- 先执行桶聚合,将文档分组到不同的桶。
- 再在每个桶中执行指定的子聚合。
基础聚合
1. 简单的指标聚合
计算文档中字段 price 的平均值:
{
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
- aggs:聚合的顶层关键字。
- average_price:聚合的名字,用户可以自定义。
- avg:聚合类型,表示计算平均值。
- field:指定需要统计的字段。
2. 桶聚合
将文档按 category 字段进行分组,并计算每个组中的文档数量:
{
"aggs": {
"group_by_category": {
"terms": {
"field": "category.keyword"
}
}
}
}
- terms:桶聚合类型,用于分组统计。
- field:指定分组的字段。
子聚合
1. 桶聚合 + 指标聚合
在每个分组(桶)中计算 price 的平均值:
{
"aggs": {
"group_by_category": {
"terms": {
"field": "category.keyword"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
解释:
- 在
group_by_category桶聚合中,嵌套了一个名为average_price的子聚合。 - 子聚合会对每个分组的文档执行
avg计算。
示例响应:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"aggAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 463,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"ageAvg" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"ageAvg" : {
"value" : 25269.583333333332
}
},
{
"key" : 26,
"doc_count" : 59,
"ageAvg" : {
"value" : 23194.813559322032
}
},
{
"key" : 32,
"doc_count" : 52,
"ageAvg" : {
"value" : 23951.346153846152
}
},
{
"key" : 35,
"doc_count" : 52,
"ageAvg" : {
"value" : 22136.69230769231
}
},
{
"key" : 36,
"doc_count" : 52,
"ageAvg" : {
"value" : 22174.71153846154
}
},
{
"key" : 22,
"doc_count" : 51,
"ageAvg" : {
"value" : 24731.07843137255
}
},
{
"key" : 28,
"doc_count" : 51,
"ageAvg" : {
"value" : 28273.882352941175
}
},
{
"key" : 33,
"doc_count" : 50,
"ageAvg" : {
"value" : 25093.94
}
},
{
"key" : 34,
"doc_count" : 49,
"ageAvg" : {
"value" : 26809.95918367347
}
}
]
}
}
}
2. 多层子聚合
统计每个 category 下的 brand,并计算 price 的最大值:
{
"aggs": {
"group_by_category": {
"terms": {
"field": "category.keyword"
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand.keyword"
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
}
}
}
}
解释:
- 第一层
group_by_category:将文档按category字段分桶。 - 第二层
group_by_brand:对每个category桶中的文档,按brand再次分桶。 - 第三层
max_price:对每个brand桶中的文档,计算price的最大值。
复杂子聚合示例
1. 日期直方图 + 子聚合
按日期将文档分组,并计算每组中字段 price 的平均值:
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
- date_histogram:根据日期字段进行分桶(每个月一个桶)。
- 子聚合
average_price计算每个月的平均价格。
2. 过滤器聚合 + 子聚合
统计字段 status 为 active 的文档,并计算 price 的最小值:
{
"aggs": {
"active_status": {
"filter": {
"term": { "status": "active" }
},
"aggs": {
"min_price": {
"min": {
"field": "price"
}
}
}
}
}
}
- filter:只对满足条件的文档进行聚合。
- 子聚合
min_price计算过滤结果中的最小值。
3. 聚合管道(Pipeline Aggregation)
基于聚合结果进行进一步分析。例如,计算每个月销售额的增长率。
按月统计销售额,并计算增长率:
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "sales"
}
},
"sales_growth": {
"derivative": {
"buckets_path": "total_sales"
}
}
}
}
}
}
- derivative:计算桶之间的差异,表示增长率。
- buckets_path:指定计算差异的目标路径。
响应结果示例
请求:
{
"aggs": {
"group_by_category": {
"terms": {
"field": "category.keyword"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
响应:
{
"aggregations": {
"group_by_category": {
"buckets": [
{
"key": "Electronics",
"doc_count": 10,
"average_price": {
"value": 200.5
}
},
{
"key": "Books",
"doc_count": 15,
"average_price": {
"value": 30.2
}
}
]
}
}
}
- buckets:包含每个分组(桶)的数据。
- key:桶的分组值(
category值)。 - doc_count:属于该分组的文档数量。
- average_price:每个桶中计算的平均值。
示例:
请求:
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"年龄分类": {
"terms": {
"field": "age",
"size": 2
},
"aggs": {
"年龄段平均薪资": {
"avg": {
"field": "balance"
}
},
"性别分类": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"各性别平均薪资": {
"avg": {
"field": "balance"
}
}
}
}
}
}
},
"size": 0
}
响应:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"年龄分类" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 879,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"年龄段平均薪资" : {
"value" : 28312.918032786885
},
"性别分类" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 35,
"各性别平均薪资" : {
"value" : 29565.628571428573
}
},
{
"key" : "F",
"doc_count" : 26,
"各性别平均薪资" : {
"value" : 26626.576923076922
}
}
]
}
},
{
"key" : 39,
"doc_count" : 60,
"年龄段平均薪资" : {
"value" : 25269.583333333332
},
"性别分类" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "F",
"doc_count" : 38,
"各性别平均薪资" : {
"value" : 26348.684210526317
}
},
{
"key" : "M",
"doc_count" : 22,
"各性别平均薪资" : {
"value" : 23405.68181818182
}
}
]
}
}
]
}
}
}
聚合的应用场景
- 统计分析: 计算总和、平均值、最大值、最小值等。
- 分组统计:根据字段值分组,并进一步统计组内指标。
- 时间序列分析: 按时间段分组,分析数据变化趋势。
- 动态过滤: 基于过滤条件的分组统计。
- 嵌套数据分析: 对嵌套字段或复杂结构进行聚合。
Mapping映射
Mapping(映射)是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。比如:使用maping来定义:
- 哪些字符串属性应该被看做全文本属性(full text fields);
- 哪些属性包含数字,日期或地理位置;
- 文档中的所有属性是否都能被索引(all 配置);
- 日期的格式;
- 自定义映射规则来执行动态添加属性;
查看映射
1. 查看索引的映射
使用 _mapping API:
GET /my_index/_mapping
返回索引 my_index 的完整映射。
示例:
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
2. 查看所有索引的映射
GET /_mapping
返回集群中所有索引的映射。
创建映射
创建索引并指定映射
PUT /my_index
{
"mappings": {
"properties": {
"字段名1":{
"type": "字段类型1"
},
"字段名2":{
"type": "字段类型2"
},
......
"字段名n ":{
"type": "字段类型2"
}
}
}
}
添加新的字段映射
PUT /my_index/_mapping
{
"properties": {
"字段名1":{
"type": "字段类型1"
"index": true/false # 检索
},
......
"字段名n ":{
"type": "字段类型n"
"index": true/false # 检索
}
}
}
更新映射
对于已存在的映射字段,我们不能更新。更新必须创建新的索引进行数据迁移
数据迁移
分为两步:
-
创建新索引的正确映射
-
使用固定写法进行数据迁移
6.0以后的写法
POST /reindex { "source":{ "index":"twitter" }, "dest":{ "index":"new_twitters" } }老版本写法
POST /reindex { "source":{ "index":"twitter", "type":"tweet" }, "dest":{ "index":"new_twitters" } }
IK分词器
由于ES内置的分词器不能对中文进行分词,故需要安装一个额外的分词器
IK分词器概述
所谓分词,即将一段话划分成一个个的关键字
IK提供了两个分词算法 : ik_smart 和 ik_max_work , 其中
- ik_smart 为最少切分 ,
- ik_max_word为最细粒度划分 .
安装IK分词器
- 下载与自己es版本一致的ik分词器
https://release.infinilabs.com/analysis-ik/
- 将下载的zip文件解压并重命名为ik之后放到linux服务器上elasticsearch容器挂载目录的plugins目录下面
- 设置ik文件夹的权限
chmod -R 777 plugins/ik
- 重启elasticsearch容器
docker restart elasticsearch
-
测试ik分词器
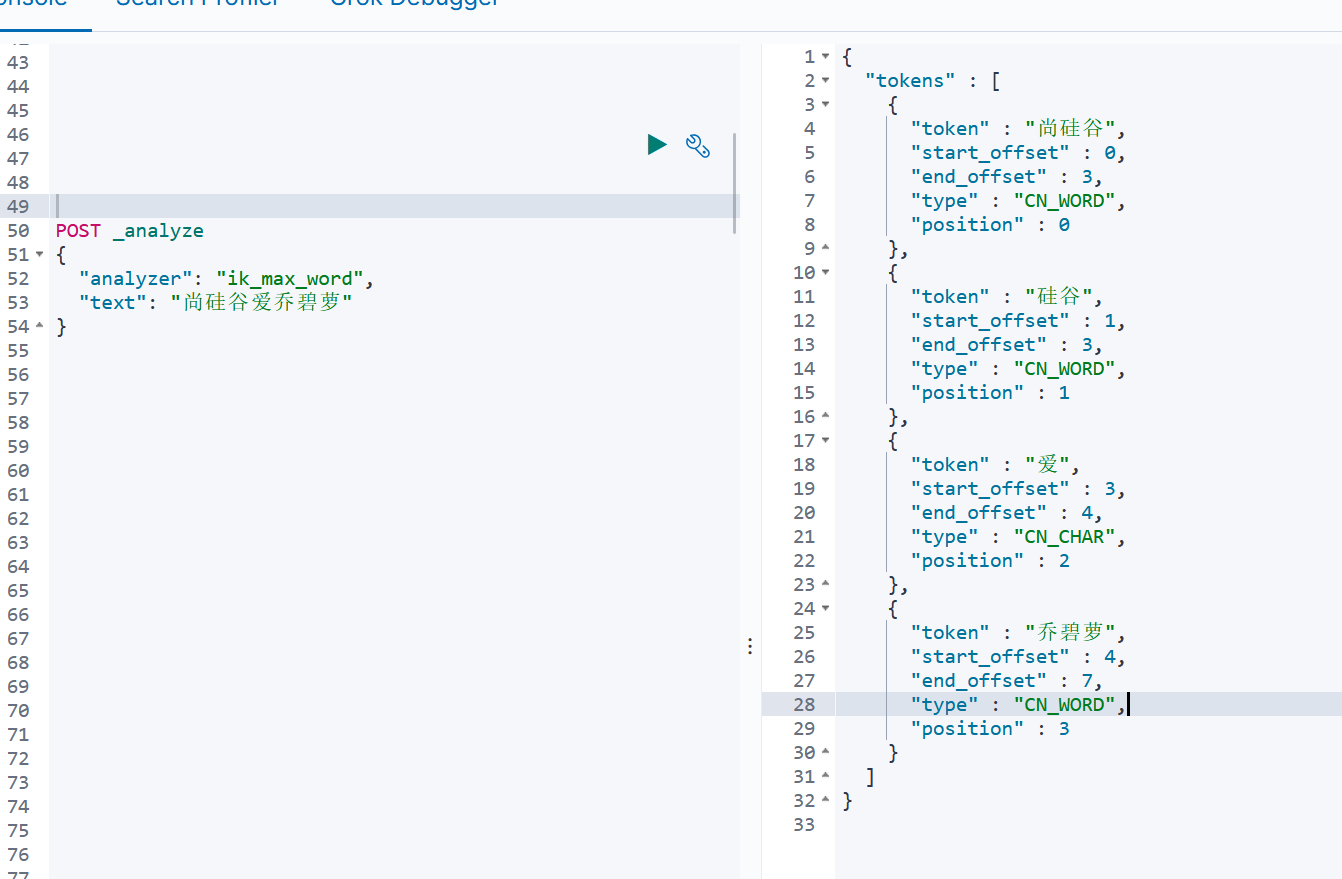
自定义拓展词库
由于ik自带的词库不是实时更新的,不能识别一些新的词,因此需要自定义拓展词库
-
安装nginx服务
-
拉取nginx镜像
docker pull nginx -
随便运行一个nginx容器以获取nginx配置
docker run -p 80:80 --name nginx -d nginx:latest -
将这个nginx容器里面的配置文件复制到虚拟机目录
[root@localhost mydata]# docker container cp nginx:/etc/nginx .停止并删除当前的nginx容器
[root@localhost ~]# docker stop nginx [root@localhost ~]# docker rm nginx -
重命名并移动从nginx容器中复制的配置目录
[root@localhost mydata]# ls elasticsearch mysql nginx redis [root@localhost mydata]# mv nginx conf [root@localhost mydata]# ls conf elasticsearch mysql redis [root@localhost mydata]# mkdir nginx [root@localhost mydata]# mv conf nginx/ [root@localhost mydata]# ls elasticsearch mysql nginx redis [root@localhost mydata]# cd nginx [root@localhost nginx]# pwd /mydata/nginx [root@localhost nginx]# ls conf -
运行新的nginx容器并挂载相应的目录
docker run -p 80:80 --name nginx \ > -v /mydata/nginx/html:/usr/share/nginx/html \ > -v /mydata/nginx/logs:/var/log/nginx \ > -v /mydata/nginx/conf:/etc/nginx \ > -d nginx -
打开挂载的nginx目录,并配置拓展的词库
[root@localhost mydata]# cd nginx/html [root@localhost html]# ls es index.html [root@localhost html]# cd es在这个es目录下面创建一个fenci.txt文件,里面的每一行为一个要新添加的拓展词
-
配置es的ik分词的配置文件,设置远程词库
/mydata/elasticsearch/plugins/ik/config
修改IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://192.168.198.131/es/fenci.txt</entry> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> -
重启elasticsearch容器
docker restart elasticsearch
-
java操作Elasticsearch
java操作es有两种方式
9300: TCP
spring-data-elasticsearch:transport-api.jar;
springboot版本不同,ransport-api.jar不同,不能适配es版本
7.x已经不建议使用,8以后就要废弃
9200: HTTP
有诸多包
jestClient: 非官方,更新慢;
RestTemplate:模拟HTTP请求,ES很多操作需要自己封装,麻烦;
HttpClient:同上;
Elasticsearch-Rest-Client:官方RestClient,封装了ES操作,API层次分明,上手简单;
最终选择Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
spring boot整合ES
创建模块gulimall-search,在创建时选择依赖spring web
配置基本的项目
导入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
版本需要选择与自己的es对应的版本
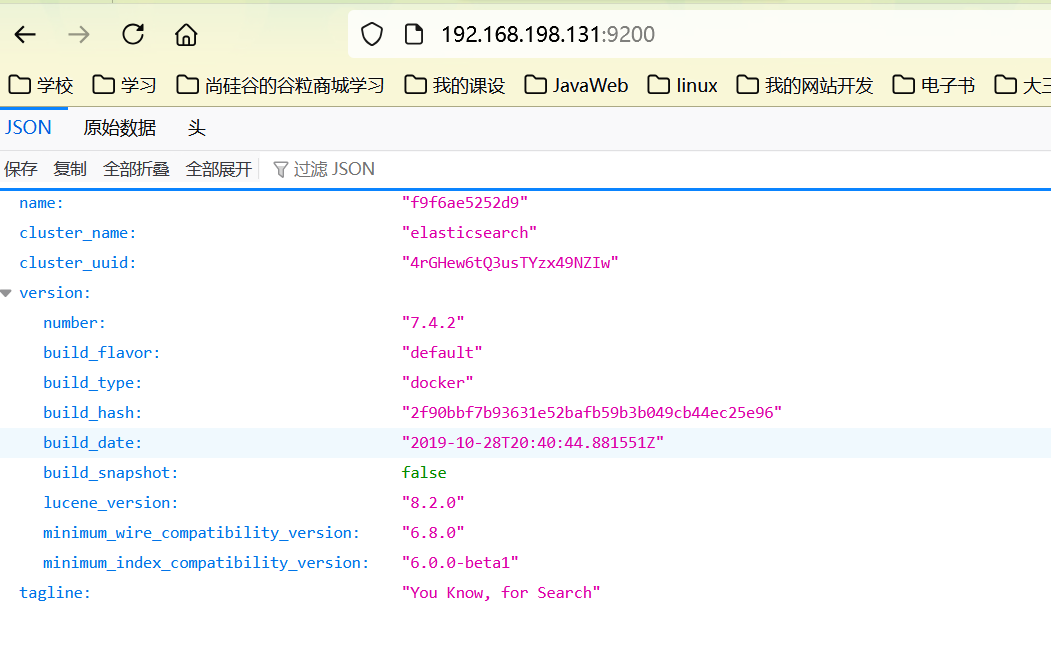
查看实际下载的elasticsearch版本是否与elasticsearch-rest-high-level-client版本一致(有些spring boot版本会默认指定elasticsearch的版本),若不一致需要手动指定:
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.1.8.RELEASE</spring-boot.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
<spring-cloud.version>Greenwich.SR3</spring-cloud.version>
<elasticsearch.rest.client.version>7.4.2</elasticsearch.rest.client.version>
</properties>
有些还需要在依赖版本的管理中加上:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.rest.client.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
最后再检查模块下载的依赖项是否是相同版本的
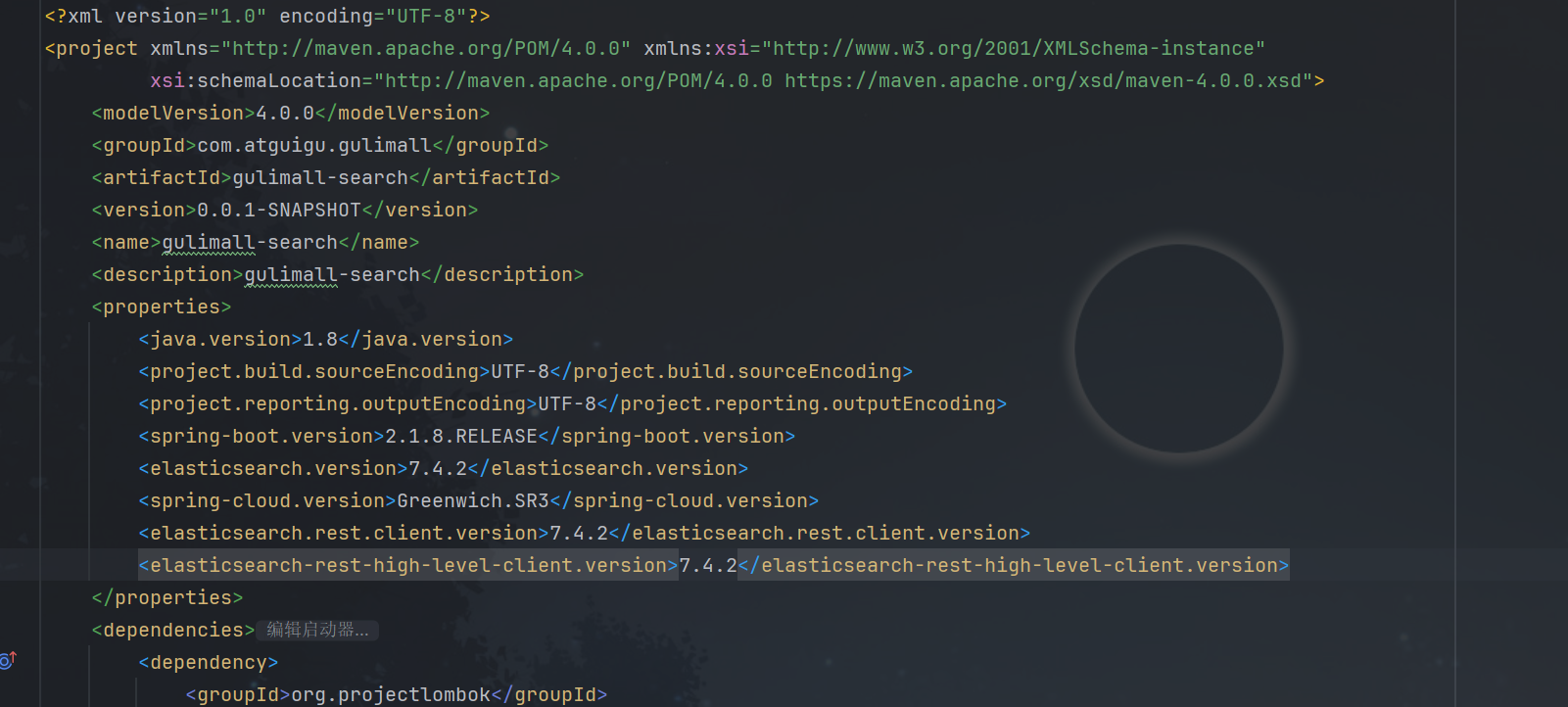
这里必须要全是7.4.2版本,否则后面其他的测试会报错
编写配置
编写配置,给容器注入一个RestHighLevelClient
@Configuration // 这个注解表示当前类是一个Spring配置类
public class GulimallElasticSearchConfig {
// 定义一个静态常量,用于存储Elasticsearch请求的默认选项
public static final RequestOptions COMMON_OPTIONS;
// 静态代码块,用于初始化 COMMON_OPTIONS
static {
// 创建一个 RequestOptions 的构建器,并使用默认配置进行初始化
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// 使用构建器创建最终的 RequestOptions 实例
COMMON_OPTIONS = builder.build();
// 目前没有对 RequestOptions 进行任何修改
}
// 通过 @Bean 注解,Spring容器会将此方法返回的对象注册为一个 Bean,可以在其他地方注入使用
@Bean
public RestHighLevelClient esRestClient() {
// 创建 RestHighLevelClient 对象,用于与 Elasticsearch 进行交互
RestHighLevelClient client = new RestHighLevelClient(
// RestClient 是低级的 HTTP 客户端,负责与 Elasticsearch 的 HTTP 接口通信
RestClient.builder(
// 设置 Elasticsearch 集群的主机地址、端口和协议
new HttpHost("192.168.198.131", 9200, "http")
// 这里指定了 Elasticsearch 节点的地址和端口
)
);
// 返回创建的 RestHighLevelClient 实例
return client;
// 这个实例会作为 Bean 被注入到 Spring 上下文中
}
}
具体的APi测试
对索引进行CRD操作
@SpringBootTest
@RunWith(SpringRunner.class)
public class GulimallSearchApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
public void testCreateIndex() throws IOException {
// 创建索引
CreateIndexRequest createIndexRequest = new CreateIndexRequest("suqi_test_index");
// 发送创建索引请求并获取创建索引的结果
CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println("Create Index Response: " + createIndexResponse.isAcknowledged());
}
@Test
public void testGetIndex() throws IOException {
// 获取索引
GetIndexRequest getIndexRequest = new GetIndexRequest();
getIndexRequest.indices("suqi_test_index");
// 判断索引是否存在
boolean indexExists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("Index exists: " + indexExists);
}
// 测试删除索引
@Test
public void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("suqi_test_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
}
对文档进行CRUD操作
@Data
static class User {
private String name;
private String gender;
private Integer age;
}
// 创建文档
@Test
public void testCreateDocument() throws IOException {
String index = "suqi_test_index"; // 索引名
String id = "1"; // 文档ID
// 创建请求体内容
User user = new User();
user.setName("suqi_YYDS");
user.setGender("男");
user.setAge(21);
String UserJson = JSON.toJSONString(user);
// 创建IndexRequest
IndexRequest indexRequest = new IndexRequest(index)
.id(id) // 指定文档ID
.timeout(TimeValue.timeValueSeconds(1))
.timeout("1s") // 设置超时时间
.source(UserJson, XContentType.JSON); // 设置文档内容
// 执行请求
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("Create Response: " + indexResponse.getResult());
}
// 读取文档
@Test
public void testGetDocument() throws IOException {
String index = "suqi_test_index"; // 索引名
String id = "1"; // 文档ID
// 创建GetRequest
GetRequest getRequest = new GetRequest(index, id);
// 执行请求
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
// 输出文档内容
if (getResponse.isExists()) {
System.out.println("Document found: " + getResponse.getSourceAsString());
} else {
System.out.println("Document not found.");
}
}
// 更新文档
@Test
public void testUpdateDocument() throws IOException {
String index = "suqi_test_index"; // 索引名
String id = "1"; // 文档ID
// 创建请求体内容
User user = new User();
user.setName("suqi");
user.setGender("男");
user.setAge(21);
String UserJson = JSON.toJSONString(user);
// 创建UpdateRequest
UpdateRequest updateRequest = new UpdateRequest(index, id)
.doc(UserJson, XContentType.JSON); // 更新内容
// 执行请求
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("Update Response: " + updateResponse.getResult());
}
// 删除文档
@Test
public void testDeleteDocument() throws IOException {
String index = "suqi_test_index"; // 索引名
String id = "1"; // 文档ID
// 创建DeleteRequest
DeleteRequest deleteRequest = new DeleteRequest(index, id);
// 执行请求
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println("Delete Response: " + deleteResponse.getResult());
}
检索
普通检索:
/**
* SearchRequest 搜索请求
* SearchSourceBuilder 条件构造
* HighlightBuilder 构建高亮
* TermQueryBuilder 精确查询
* MatchAllQueryBuilder 匹配所有
* XXXQueryBuilder 对应所有命令
*/
@Test
public void testSearch() throws IOException {
// 1、创建检索的请求
SearchRequest searchRequest = new SearchRequest("bank");
// 2、封装检索的构建
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 2.1)构件检索条件
sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 3、构建放到请求里面
searchRequest.source(sourceBuilder);
// 4、执行请求
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSON(searchResponse.getHits()));
System.out.println("=====================");
for (SearchHit hit : searchResponse.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
复杂检索
@Data
public static class Acount {
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
/**
* 检索地址中带有 mill 的人员年龄分布和平均薪资
*/
@Test
void searchData() throws IOException {
// 1. 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定 DSL 检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 1.1 构建检索条件 address 包含 mill
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// 1.2 按照年龄值分布进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
searchSourceBuilder.aggregation(ageAgg);
// 1.3 计算平均薪资
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
searchSourceBuilder.aggregation(balanceAvg);
System.out.println("检索条件:" + searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
// 2. 执行检索, 获得响应
SearchResponse searchResponse = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 3. 分析结果
// 3.1 获取所有查到的记录
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// 数据字符串
String jsonString = hit.getSourceAsString();
//System.out.println(jsonString);
// 可以通过上面打印的 json 转换成实体类对象 json.cn
Acount account = JSON.parseObject(jsonString, Acount.class);
System.out.println(account);
}
// 3.2 获取检索的分析信息(聚合数据等)
Aggregations aggregations = searchResponse.getAggregations();
// for (Aggregation aggregation : aggregations.asList()) {
// System.out.println("当前聚合名:" + aggregation.getName());
// }
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄:" + keyAsString + " 岁的有 " + bucket.getDocCount() + " 人");
}
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资: " + balanceAvg1.getValue());
}
谷粒商城使用ES
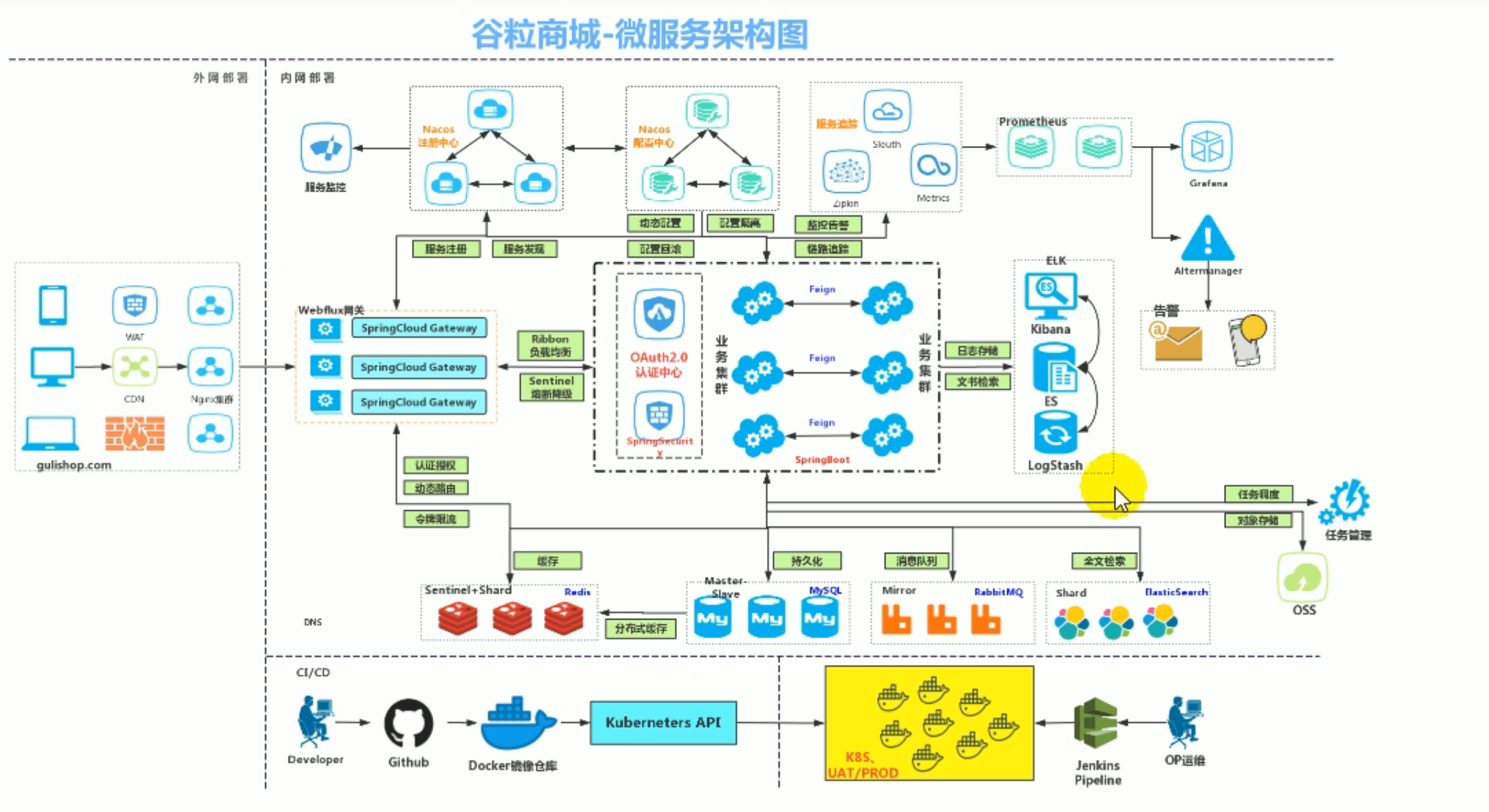
ES在该项目中主要用于:
- 全文检索引擎:承担项目里面的全文检索功能,可以按照名字全文检索商品,也可以按照商品的不同规格属性进行全文检索
- 日志分析检索:项目需要对日志进行快速定位,日志也有检索需求,将日志存储到ES里面,有一个技术栈ELK logStash负责收集日志并存入到ES里面
检索使用ES而不是用MYSQL的原因:
- 性能差异:MYSQL的全文检索功能没有ES强大,复杂的检索分析数据,MYSQL的性能远远不及es。
- es支持分布式:es数据虽然是存入内存中的,但是es天然支持分布式,一个es不够可以多装几个es分布在不同服务器里面,将数据分片存储,容量不够,数量来凑
商品上架
所谓商品上架,即将商品从数据库保存到es里面的这一过程
sku在es中的存储模型的分析
前端的商城项目要检索需要在es中检索商品数据,那么需要在es中保存那些数据呢?
首先第一点,只保留页面有用的数据,比如说已经通过es查到skuid了,想要查看sku的全部图片,以及商品的完整介绍,只需要去数据库中查一遍即可。
第二点根据搜索的角度考虑,用户搜索商品时可能搜索的是sku的标题,也可能根据sku的价格区间或者销量进行检索,也就是说sku的一些基本信息都是要用的,还要保存当前sku对象的规格信息
总的来说,对于每一个sku,需要在es中保存其skuid,spuid,skutitle,price,saleCount,attrs
确定需要保存那些信息了,还需要确定其在es中的存储方式,存储方式有两种:

-
缺点:会产生冗余字段,对于相同类型的商品,attrs 属性字段会重复,空间占用大
-
好处:方便检索

-
缺点:选择公共属性attr时,会检索当前属性的所有商品分类,然后再查询当前商品分类的所有可能属性导致耗时长。
-
好处:空间利用率高
对于上面这两种存储方式,给定一个场景,检索手机的时候,每选中一个规格,比如说选中了一个屏幕,5.49寸,再选中一个高清HD+,剩下又是一些可选规格
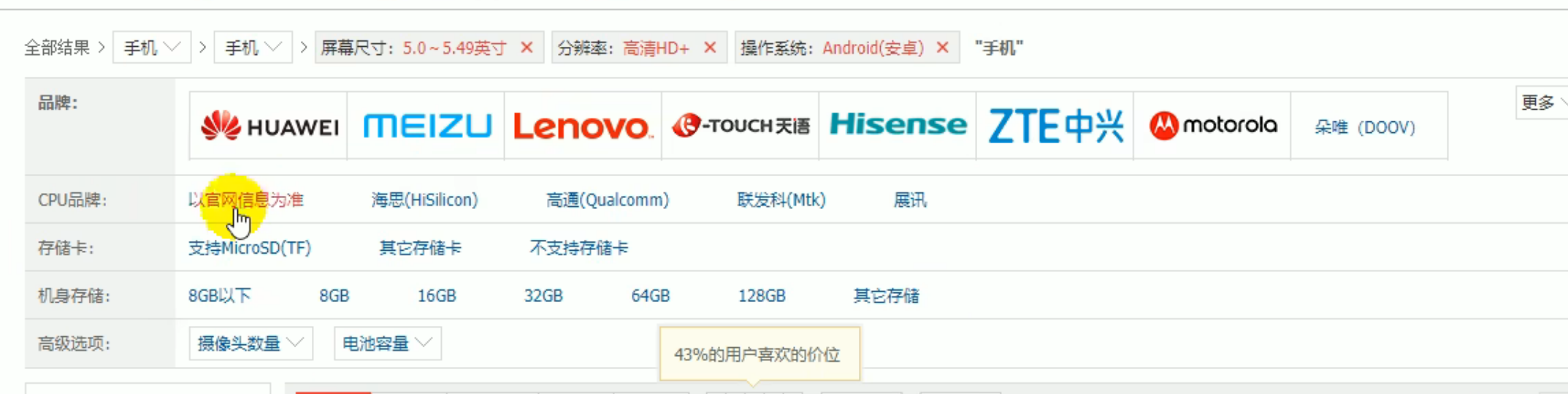
这些可选规格在不断变化,比如又选了个安卓,它有一个最大的特点,这些所列举的属性查询出来的商品一定是拥有的,所以上面的这些可选规格都是通过动态计算出来的,即首先通过商品的标题检索手机时,会找到所有标题里面包含手机的商品,会把所有的商品聚合起来,分析一下所有商品涉及的所有属性,以及所有的属性值,点进去某一个属性值,就会保证下面的商品都会拥有它。
假设需要完成上面这种动态计算,那么对于10000个人搜索,第二种方式需要集群光数据传输都会有320mb数据,百万并发,就是32GB数据,不谈性能,光是阻塞时间就会非常长,虽然第二种方式也是可以的,但是造成的时间浪费是巨大的。
第一种浪费空间但是节省时间,第二种节省空间,但是分配到了两个索引下,一定会造成一些时间的浪费
## 一、商品上架
上架的商品才可以在网站展示。
上架的商品需要可以被检索。
1、商品Mapping
分析:商品上架在es中是存sku还是spu?
1)、检索的时候输入名字,是需要按照sku的title进行全文检索的
2)、检索使用商品规格,规格是spu的公共属性,每个spu是一样的
3)、按照分类id进去的都是直接列出spu的,还可以切换。
4)、我们如果将sku的全量信息保存到es中(包括spu属性)就太多量字段了。
5)、我们如果将spu以及他包含的sku信息保存到es中,也可以方便检索。
但是sku属于spu的级联对象,在es中需要nested模型,这种性能差点。
6)、但是存储与检索我们必须性能折中。
7)、如果我们分拆存储,spu和attr一个索引,sku单独一个索引可能涉及的问题。
检索商品的名字,如“手机”,对应的spu有很多,我们要分析出这些spu的所有关联属性,再做一次查询,
就必须将所有spuid都发出去。假设有1万个数据,数据传输一次就10000*4=4MB;
并发情况下假设1000检索请求,那就是4GB的数据,传输阻寒时间会很长,业务更加无法继续。
所以,我们如下设计,这样才是文档区别于关系型数据库的地方,宽表设计,不能去考虑数据库范式。
PUT product
{
"mappings": {
"properties": {
"skuId": { "type": "long" },
"spuId": { "type": "keyword" },
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": { "type": "keyword" },
"skuImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount":{ "type":"long" },
"hasStock": { "type": "boolean" },
"hotScore": { "type": "long" },
"brandId": { "type": "long" },
"catalogId": { "type": "long" },
"brandName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg":{
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {"type": "long" },
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": { "type": "keyword" }
}
}
}
}
}
mapping字段说明:
"mappings": {
"properties": {
"skuId": { "type": "long" },
"spuId": { "type": "keyword" }, # 精确检索,不分词,后续会用到一个数据折叠功能
"skuTitle": {
"type": "text", # 全文检索 唯一需要全文匹配的就是skuTitle,使用分词器
"analyzer": "ik_smart" # 分词器
},
"skuPrice": { "type": "keyword" },# 防止数据精度问题使用keyword
"skuImg": {
"type": "keyword",
"index": false, # false 不可被检索,但是查询的时候是可以带的,相当于一个冗余存储字段(为了只查一次就能看到图片)
"doc_values": false # 默认为true,为false表示不可被聚合,排序。加上这个字段es就不会维护一些额外检索,更能节省空间
# 即所有做冗余存储的字段(减少查询次数),就会标上这两个为false
},
"saleCount":{ "type":"long" }, # 商品销量
"hasStock": { "type": "boolean" }, # 商品是否有库存
# 为何设计为一个boolean类型的,而不是long类型的表示库存的多少?因为使用boolean的话就无需每天在数据库核查库存的时候修改库存数量,只要修改数据,es就会重新把他索引一次,维护整片索引是一个很慢的过程,所以只有商品没库存的时候才把它修改一下,只要上来库存就把他改为true,这样比实时更新库存要好的多
"hotScore": { "type": "long" }, # 商品热度评分
"brandId": { "type": "long" }, # 品牌id
"catalogId": { "type": "long" }, # 分类id
"brandName": { # 品牌名,只用来查看,不用来检索和聚合
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg":{ # 品牌图片,只用来查看,不用来检索和聚合
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": { # 分类名,只用来查看,不用来检索和聚合
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": { # 属性对象,表示当前的这个商品所有的规格属性,是一个数组,数组里面是对象,而且要按照对象里面某些值进行检索,相当于是内部的属性,标志nested,嵌入式的
"type": "nested", # 嵌入式,内部属性
"properties": {
"attrId": {"type": "long" },
"attrName": { # 属性名
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": { "type": "keyword" } # 属性值
}
}
}
}
nested数据类型场景
假设一个商品有多个规格参数,每个规格参数包括名称和值。这些规格参数需要独立查询和过滤。
数据结构:
PUT my_index/_doc/1
{
"product_id": "123",
"name": "Smartphone",
"specs": [
{"name": "Color", "value": "Black"},
{"name": "Storage", "value": "128GB"}
]
}
实际上在es中是这么存储的:
{
"product_id": "123",
"name": "Smartphone",
"specs.name": ["Color","Storage"],
"specs.value": ["Black","128GB"]
}
GET my_index/_search
{
"query": {
"bool": {
"must": [
{ "match": { "specs.name": "Color" }},
{ "match": { "specs.value": "128GB" }}
]
}
}
}
查询结果:
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"product_id" : "123",
"name" : "Smartphone",
"specs" : [
{
"name" : "Color",
"value" : "Black"
},
{
"name" : "Storage",
"value" : "128GB"
}
]
}
}
]
}
}
如果 specs 使用普通 object 类型,查询 name:Color 和 value:128GB 会错误匹配到 Color: Black 和 Storage: 128GB。

使用 nested 类型可以保证查询时保持字段的独立性。
官方解决方案:
为对象数组使用嵌套字段
若需索引对象数组并保持数组中每个对象的独立性,应当使用 nested(嵌套)数据类型而非 object(对象)数据类型。在内部机制中,嵌套对象会将数组内的每个对象作为单独的隐藏文档进行索引。这意味着,通过 nested query(嵌套查询),每个嵌套对象可以独立于数组中的其他对象被单独查询。
# 删除旧索引(如果存在)并创建新索引,明确指定 specs 为 nested 类型
DELETE my_index
PUT my_index
{
"mappings": {
"properties": {
"product_id": { "type": "keyword" },
"name": { "type": "text" },
"specs": {
"type": "nested", // 关键点:使用 nested 类型
"properties": {
"name": { "type": "keyword" },
"value": { "type": "keyword" }
}
}
}
}
}
# 重新插入数据
PUT my_index/_doc/1
{
"product_id": "123",
"name": "Smartphone",
"specs": [
{"name": "Color", "value": "Black"},
{"name": "Storage", "value": "128GB"}
]
}
# 使用 Nested Query 正确查询
GET my_index/_search
{
"query": {
"nested": {
"path": "specs",
"query": {
"bool": {
"must": [
{ "match": { "specs.name": "Color" }},
{ "match": { "specs.value": "128GB" }}
]
}
}
}
}
}
上架功能具体实现
@Data
public class SkuEsModel {
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private Long saleCount;
private Boolean hasStock;
private Long hotScore;
private Long brandId;
private Long catalogId;
private String brandName;
private String brandImg;
private String catalogName;
private List<Attrs> attrs;
@Data
//为了第三方工具能对它序列化反序列化,设置为可访问的权限
public static class Attrs {
private Long attrId;
private String attrName;
private String attrValue;
}
}
/**
* 商品上架
* @param spuId
*/
@Override
public void up(Long spuId) {
// 1.查出当前spuid对应的所有sku信息
List<SkuInfoEntity> skus = skuInfoService.getSkusBySpuId(spuId);
List<Long> skuIdList = skus.stream().map(SkuInfoEntity::getSkuId).collect(Collectors.toList());
// 2.4查询当前sku的所有可以用来被检索的规格属性
List<ProductAttrValueEntity> baseAttrs = productAttrValueService.baseAttrListForSpu(spuId);
List<Long> attrIds = baseAttrs.stream().map(ProductAttrValueEntity::getAttrId).collect(Collectors.toList());
// 查询需要被检索的属性Id
List<Long> searchAttrIds = attrService.selectSearchAttrIds(attrIds);
// 将需要被检索的属性ID转化成集合
Set<Long> idSet = new HashSet<>(searchAttrIds);
List<SkuEsModel.Attrs> attrsList = baseAttrs.stream().filter(item -> {
// 过滤出需要被检索的属性实体
return idSet.contains(item.getAttrId());
}).map(itme -> {
// 将属性实体转化成检索属性实体
SkuEsModel.Attrs attr = new SkuEsModel.Attrs();
BeanUtils.copyProperties(itme, attr);
return attr;
}).collect(Collectors.toList());
// 2.1发送远程调用,库存系统查询是否有库存
Map<Long, Boolean> stockMap = null;
try{
R skuHasStock = wareFeignService.getSkuHasStock(skuIdList);
stockMap = skuHasStock.getData(new TypeReference<List<SkuHasStockVo>>(){}).stream().collect(Collectors.toMap(SkuHasStockVo::getSkuId, SkuHasStockVo::getHasStock));
}catch (Exception e){
log.error("库存查询服务异常:原因{}",e);
}
// 2.封装每个sku信息
Map<Long, Boolean> finalStockMap = stockMap;
List<SkuEsModel> skuEsModels = skus.stream().map(sku -> {
// 组装需要的数据
SkuEsModel esModel = new SkuEsModel();
BeanUtils.copyProperties(sku, esModel);
esModel.setSkuPrice(sku.getPrice());
esModel.setSkuImg(sku.getSkuDefaultImg());
// 2.1发送远程调用,库存系统查询是否有库存
if (finalStockMap == null) {
esModel.setHasStock(true);
} else {
esModel.setHasStock(finalStockMap.get(sku.getSkuId()));
}
// TODO 2.2设置热度评分,默认0
esModel.setHotScore(0L);
// 2.3查询品牌和分类的名字信息
BrandEntity brandEntity = brandService.getById(esModel.getBrandId());
esModel.setBrandName(brandEntity.getName());
esModel.setBrandImg(brandEntity.getLogo());
CategoryEntity categoryEntity = categoryService.getById(esModel.getCatalogId());
esModel.setCatalogName(categoryEntity.getName());
// 2.4设置检索属性
esModel.setAttrs(attrsList);
return esModel;
}).collect(Collectors.toList());
// 3.将数据发送给es进行保存 gulimall-search
R r = searchFeignService.productStatusUp(skuEsModels);
if (r.getCode() == 0) {
// 远程调用成功
// 修改spu的状态
baseMapper.updateSpuStatus(spuId, ProductConstant.StatusEnum.SPU_UP.getCode());
} else {
// 远程调用失败 TODO 考虑重复上架 接口幂等性
}
}
}
@Slf4j
@Service
public class ProductSaveServiceImpl implements ProductSaveService{
@Autowired
RestHighLevelClient restHighLevelClient;
/**
* 将sku文档模型存入ES
* @param skuEsModels
*/
@Override
public boolean productStatusUp(List<SkuEsModel> skuEsModels) throws IOException {
// 1. 首先需要给 Elasticsearch 中建立索引 "product"(商品索引),以及建立映射关系。
// 这里假设在其他地方已经配置好索引的建立与映射关系。
// 2. 创建一个 BulkRequest 实例,用于批量提交多个 Elasticsearch 请求。
BulkRequest bulkRequest = new BulkRequest();
// 3. 遍历传入的 SKU 模型列表,构造批量索引请求。
for (SkuEsModel model : skuEsModels) {
// 4. 创建一个 IndexRequest,用于将数据保存到指定的索引中。
IndexRequest indexRequest = new IndexRequest(EsContant.PRODUCT_INDEX);
// 5. 设置每个商品(SKU)的 ID,通常是 SKU 的唯一标识符。
// 这里使用 model.getSkuId().toString() 将 SKU ID 转换为字符串作为文档 ID。
indexRequest.id(model.getSkuId().toString());
// 6. 将 SkuEsModel 对象转换为 JSON 字符串,准备存储到 Elasticsearch 中。
String s = JSON.toJSONString(model);
// 7. 使用 IndexRequest 的 source 方法指定文档内容,这里使用 JSON 格式。
indexRequest.source(s, XContentType.JSON);
// 8. 将每个索引请求添加到批量请求中。
bulkRequest.add(indexRequest);
}
// 9. 执行批量请求,将数据提交到 Elasticsearch 中。
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 10. 检查批量请求是否有失败的项。
boolean b = bulk.hasFailures();
// 11. 如果有失败的项,收集失败项的 ID,并记录错误日志。
// 这里获取每个失败的项的 ID,然后使用日志记录这些失败的商品。
// 获取每个请求的 ID
List<String> collect = Arrays.stream(bulk.getItems()).map(BulkItemResponse::getId).collect(Collectors.toList());
log.info("商品上架完成:{}", collect);
// 12. 返回批量请求是否有失败。
// 如果批量请求中存在失败项,返回 true;否则,返回 false。
return b;
}
}
/**
* 查询sku列表的对应sku是否有库存
* @param skuIds
* @return
*/
// @Override
// public List<SkuHasStockVo> getSkuHasStock(List<Long> skuIds) {
// List<SkuHasStockVo> collect = skuIds.stream().map(item -> {
// SkuHasStockVo vo = new SkuHasStockVo();
// // 根据skuId查询当前sku的库存总量
// // select sum(stock - stock_locked) from `wms_ware_sku` where `sku_id` = ?
// long count = baseMapper.getSkuStock(item);
// vo.setSkuId(item);
// vo.setHasStock(count > 0);
// return vo;
// }).collect(Collectors.toList());
// return collect;
// }
@Override
public List<SkuHasStockVo> getSkuHasStock(List<Long> skuIds) {
// 一次性查询所有sku的库存信息
List<WareSkuEntity> skuStockList = baseMapper.getSkuStockList(skuIds);
// 将查询结果映射到一个Map中,方便根据skuId快速查找库存信息
Map<Long, Integer> skuStockMap = skuStockList.stream()
.collect(Collectors.toMap(WareSkuEntity::getSkuId, WareSkuEntity::getStock));
// 使用skuIds中的数据,直接返回对应的库存信息
return skuIds.stream().map(skuId -> {
SkuHasStockVo vo = new SkuHasStockVo();
vo.setSkuId(skuId);
// 获取库存数据,判断是否有库存
Integer stock = skuStockMap.get(skuId);
vo.setHasStock(stock != null && stock > 0);
return vo;
}).collect(Collectors.toList());
}
<select id="getSkuStockList" resultType="com.atguigu.gulimall.ware.entity.WareSkuEntity">
SELECT sku_id, SUM(stock - stock_locked) AS stock
FROM wms_ware_sku
WHERE sku_id IN
<foreach item="skuId" collection="skuIds" open="(" separator="," close=")">
#{skuId}
</foreach>
GROUP BY sku_id;
</select>


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









