






目录
进程创建
fork函数初识
在之前进程概念的学习的时候,我们就已经使用到了fork函数,它就是创建子进程的。
下面是其具体的信息:
头文件#include <unistd.h>使用方法:pid_t fork(void);返回值:自进程中返回 0 ,父进程返回子进程 id ,出错返回 -1
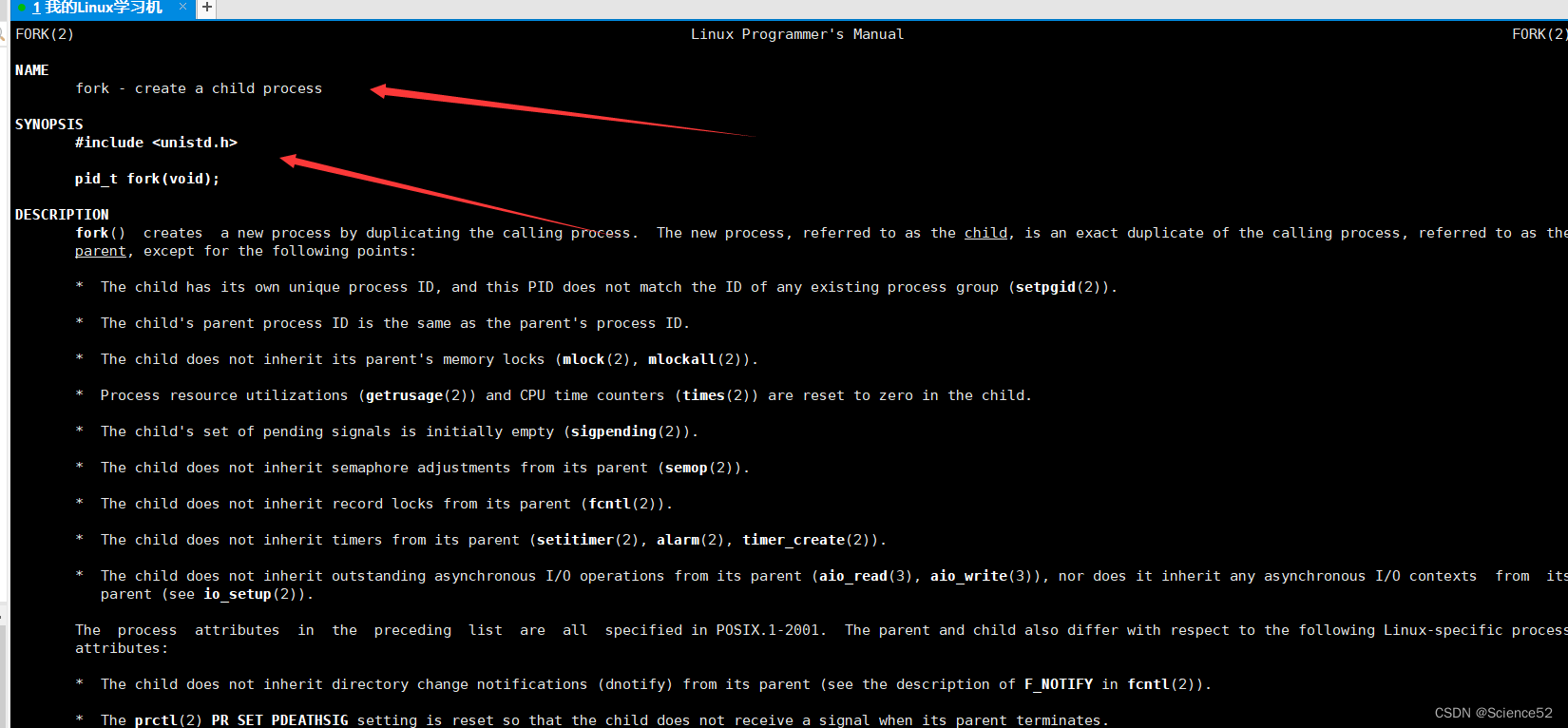
那怎么创建子进程的呢?
进程调用 fork ,当控制转移到内核中的 fork 代码后,内核做:分配新的内存块和内核数据结构给子进程将父进程部分数据结构内容拷贝至子进程添加子进程到系统进程列表当中fork返回,开始调度器调度
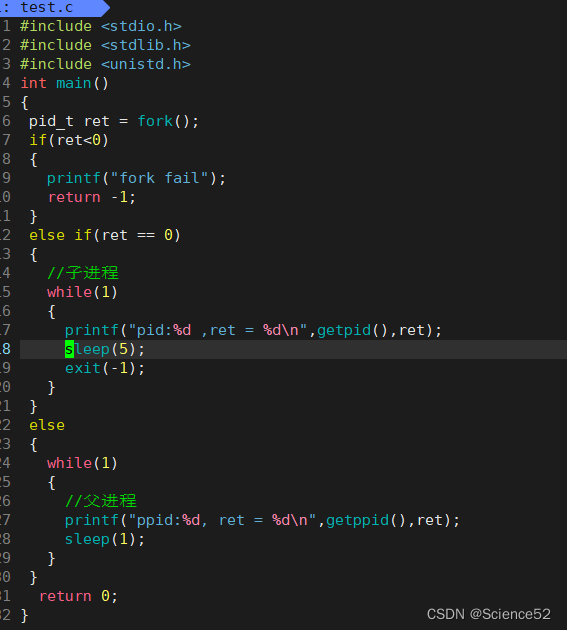
这是之前写过的代码,之前也解释了为什么两个死循环能同时进行,就是因为两个进程互相独立的执行着各自的代码。
这里看看结果:

fork函数返回值
子进程返回0,父进程返回的是子进程的pid 。你可能会问为什么一个函数会有两个返回值?这是因为在创建子进程的时候会做一系列的工作,而在函数中子进程就已经被创建完成了,所以父子进程都要返回,所以其实是 在函数中两个进程就已经独立运行了。
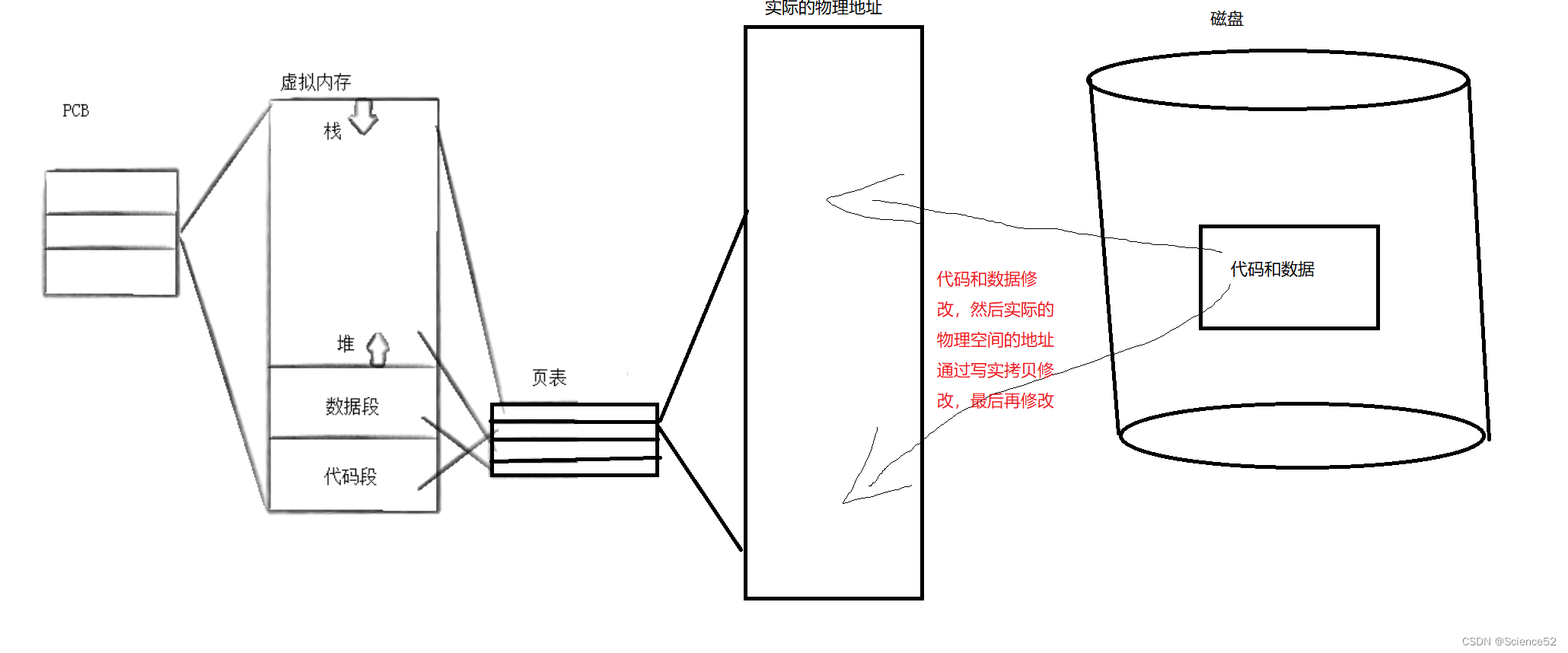
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。在之前讲解进程地址空间的时候也提到了写实拷贝,下面通过画图来理解: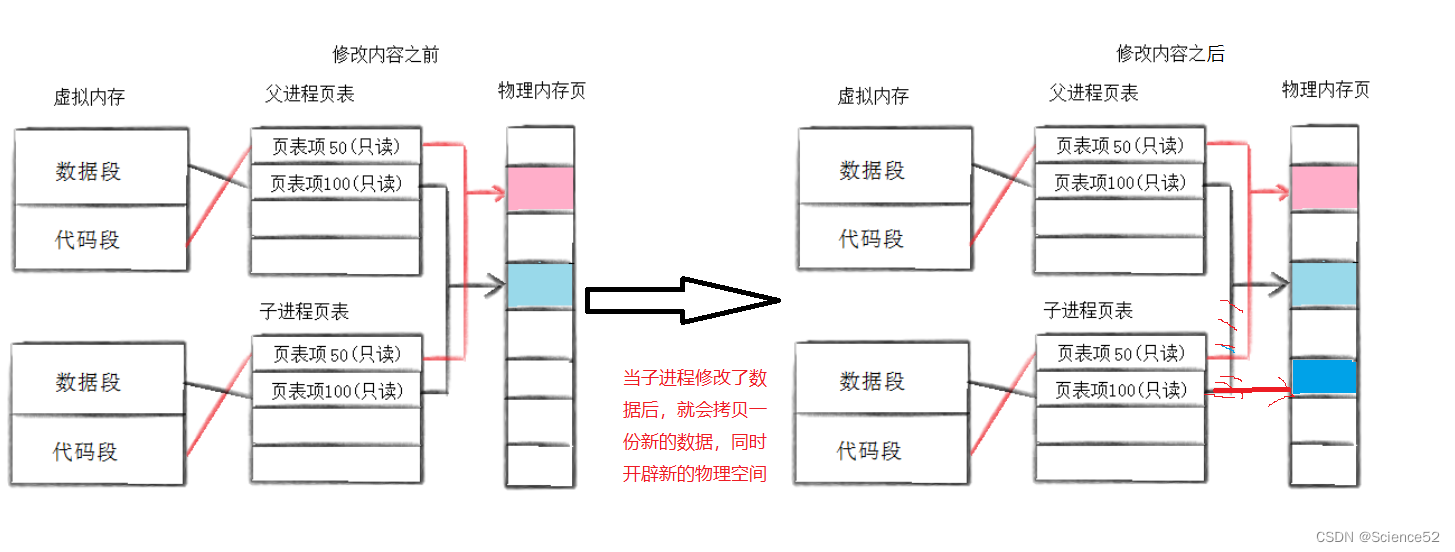
fork常规用法
fork调用失败的原因
进程终止
在介绍进程终止的之前,先讲讲C/C++中,为什么最后main函数都要return 0呢?
这里的return 0其实是表示程序正常退出的意思。当然也可以返回其他值,只是说返回的这个值对你这个函数的实现用处不是很大罢了,但是main函数返回值是可以在系统中的找到的。这样可以知道你的程序是正常退出还是其他原因退出。那怎么在我们的系统中查看我们执行完的函数的返回值呢?
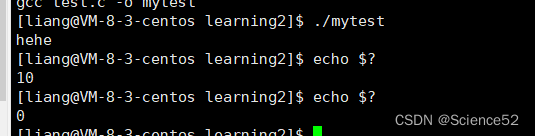
我们可以通过echo $?来查看我们最近一次返回的结果
但是我们再次执行以下刚才的命令,我们就会发现一个现象:
为什么是0呢?
因为echo其实也是一个程序,我们知道指令是由c语言以及汇编语言写的。所以echo其实也是有返回值的,它返回的就是0;

在了解了程序退出码之后,我们来了解进程终止
进程退出场景
一共有3种结果:代码运行完毕,结果正确代码运行完毕,结果不正确代码异常终止
进程常见退出方法
_exit函数
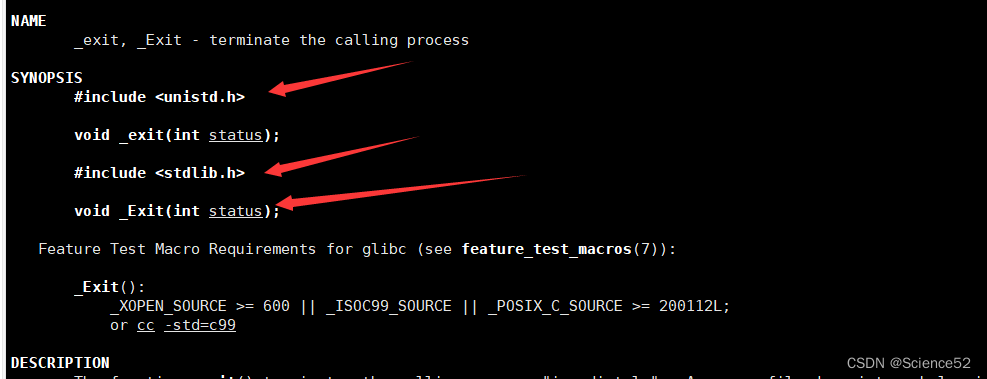
我们先看看man手册中的介绍:
我们可以得到一些有用的信息:
头文件:#include <unistd.h>使用方式:void _exit(int status);参数: status 定义了进程的终止状态,父进程通过 wait 来获取该值,后面会介绍到wait。说明: 虽然status是int,但是仅有低8位可以被父进程所用 。所以 _exit(-1) 时,在终端执行 $? 发现返回值是255 。这个后面也会介绍
exit函数
头文件:#include <unistd.h>使用方式:void exit(int status);那我们这个库里实现的exit和系统接口提供的_exit有什么区别呢?下面一段代码看出其中的区别: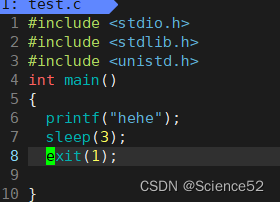

我们可以看到这个在休眠3秒之后还是会刷新出缓存区的内容的。
下面是_exit的结果:
可以看到最后结果是系统提供的接口不会帮我们把缓存区的内容刷新出来,但是库里提供的exit是会帮我们把缓冲区的内容刷新出来的。
当然还会做其他工作:
1. 执行用户通过 atexit或on_exit定义的清理函数。2. 关闭所有打开的流,所有的缓存数据均被写入3. 调用_exit因为exit会调用_exit,我们就可以知道缓冲区是在系统接口之上的,也就是用户级别的缓冲区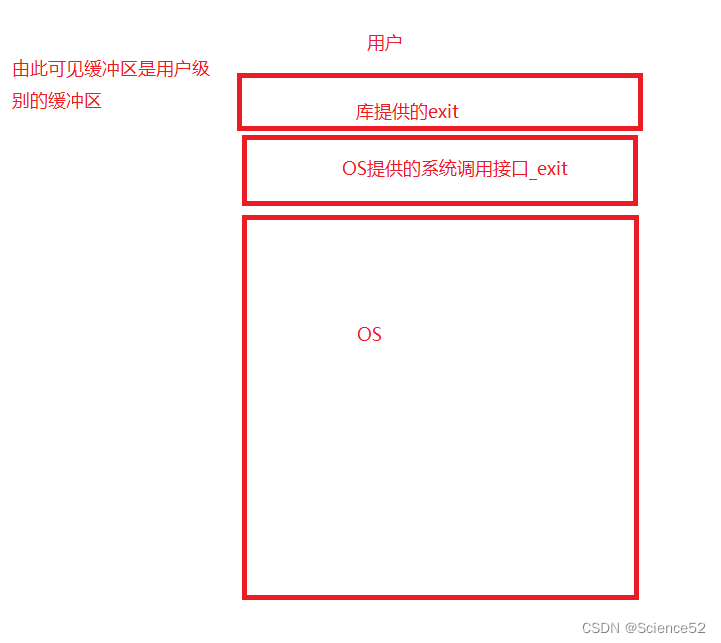

return退出
进程等待
进程等待必要性
进程等待的方法
wait方法
头文件:#include<sys/types.h>#include<sys/wait.h>使用方式:pid_t wait(int*status);返回值:成功返回被等待进程pid,失败返回-1。参数:输出型参数,获取子进程退出状态,不关心则可以设置成为NULL
我们先看看wait的代码使用:
通过脚本可以一直打印我们进程的状态,从而更好的观察:
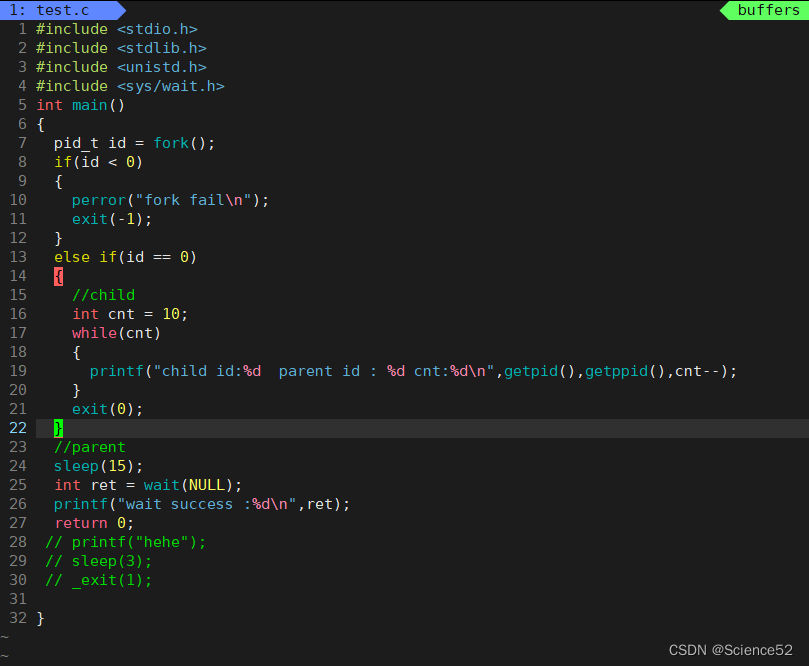
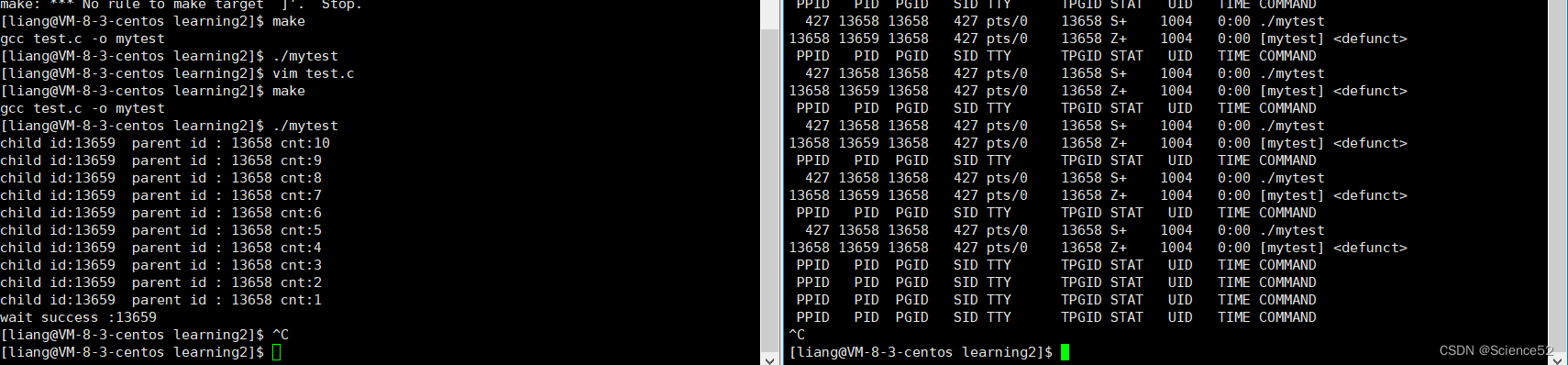
通过运行结果我们就可以大概知道了这个wait是怎么使用的。而且可以看看wait确实能够很好的解决子进程僵尸状态的问题,从而可以避免内存泄露的问题。
waitpid方法
函数使用方式:pid_ t waitpid(pid_t pid, int *status, int options);
返回值:当正常返回的时候 waitpid 返回收集到的子进程的进程 ID ;如果设置了选项 WNOHANG, 而调用中 waitpid 发现没有已退出的子进程可收集 , 则返回 0 ;如果调用中出错 , 则返回 -1, 这时 errno 会被设置成相应的值以指示错误所在;参数:pid :Pid=-1, 等待任一个子进程。与 wait 等效。Pid>0. 等待其进程 ID 与 pid 相等的子进程。status:WIFEXITED(status): 若为正常终止子进程返回的状态,则为真 。(查看进程是否是正常退出)WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。 (查看进程的退出码)options:WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID。
获取子进程status
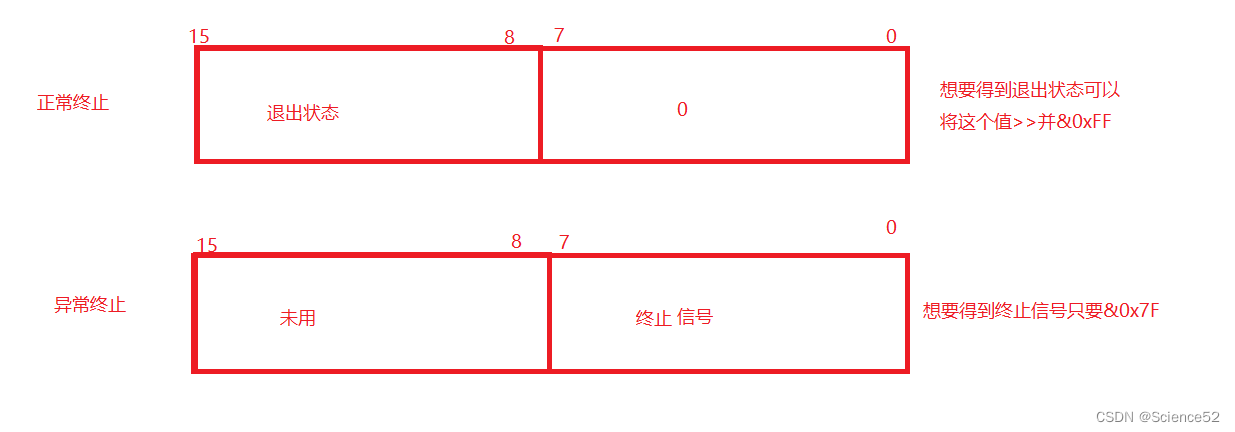
在了解的status的使用之后,我们就可以看看waitpid的使用:
在使用waitpid之前,我们要知道父进程可以进行阻塞等待,以及非阻塞等待。为什么有这两种结果呢?首先阻塞等待就是父进程全程等待子进程,知道子进程结束,父进程获得子进程的退出信息。而非阻塞等待就是父进程虽然在等待子进程,但是不是全程都等待,而是等待一会,然后再去执行其他的事情。可能你会想那阻塞等待有什么用,不如直接使用非阻塞等待不是更好吗,效率不是更高吗?但事实上,阻塞等待和非阻塞等待都是存在的,这表明了他们各自都着应用场景。
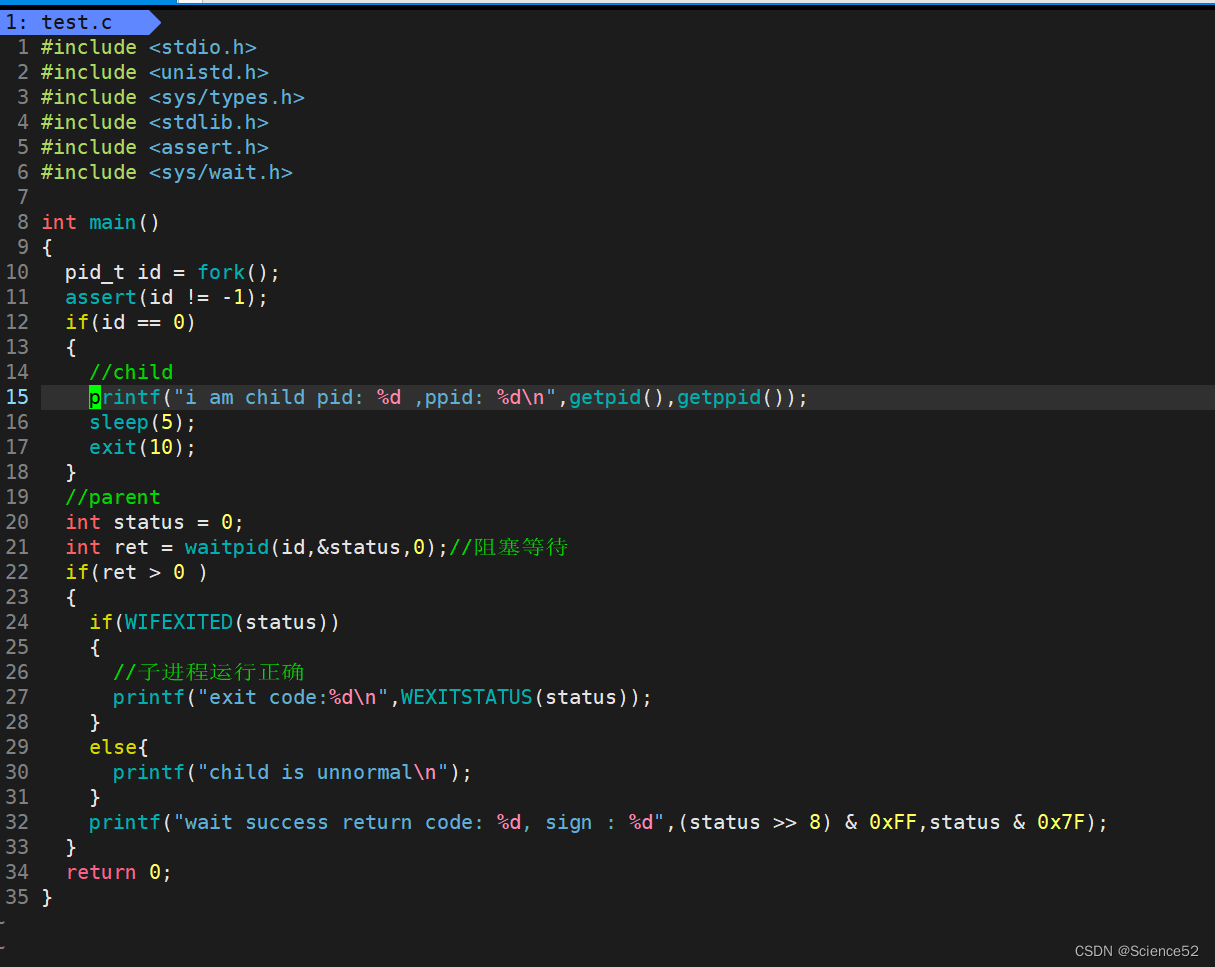
阻塞等待:
我们可以让父进程等待子进程,然后在父进程返回的时候查看子进程的信息。
下面是代码实现:
看看结果:
我们发现父进程正好等到了子进程退出,并获取到了它的退出码。
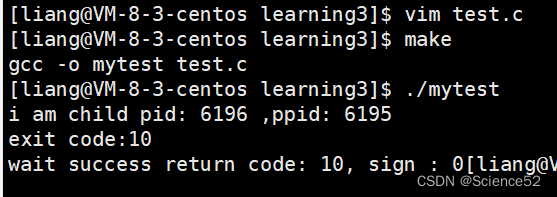
非阻塞等待:
非阻塞等待就是父进程在子进程执行的时候也同时做的自己的事情
下面我们就在子进程在运行的时候,让父进程做一点其他的事情。
我们可以看到代码的结果:在子进程运行的时候,父进程也在做自己的事情:

进程程序替换
首先我们先回答一个问题:为什么要创建子进程?
我们创建子进程有两个目的:1.帮助父进程执行部分代码,从而提高效率
2.父子进程分别完成不同的工作,从让子进程执行一个全新的代码。
而这里的方法2就是进程程序替换。
替换原理
替换函数
头文件:#include <unistd.h>
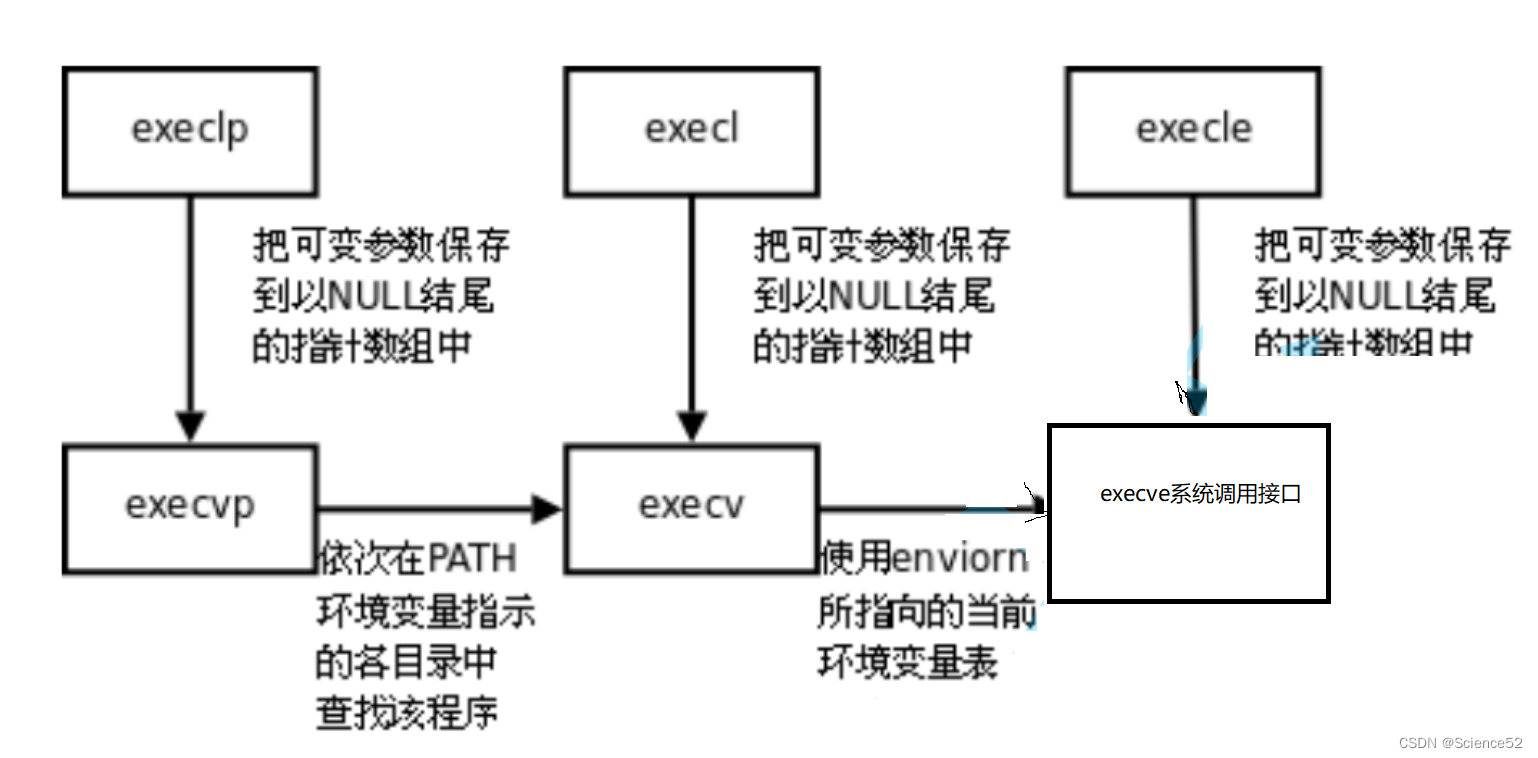
5个替换函数:
int execl(const char *path, const char *arg, ...);int execlp(const char *file, const char *arg, ...);int execle(const char *path, const char *arg, ...,char *const envp[]);int execv(const char *path, char *const argv[]);int execvp(const char *file, char *const argv[]);记忆方法:
函数解释
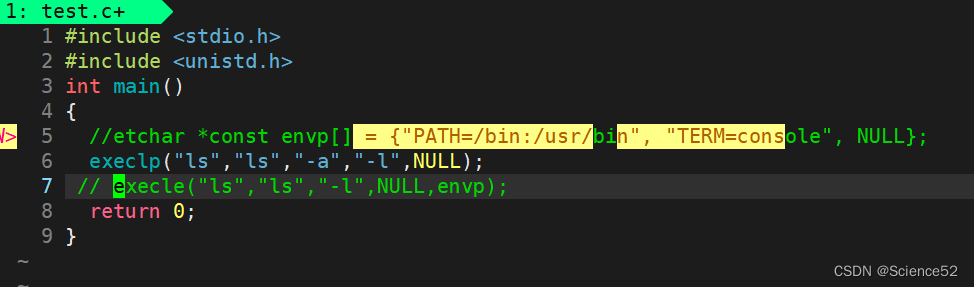
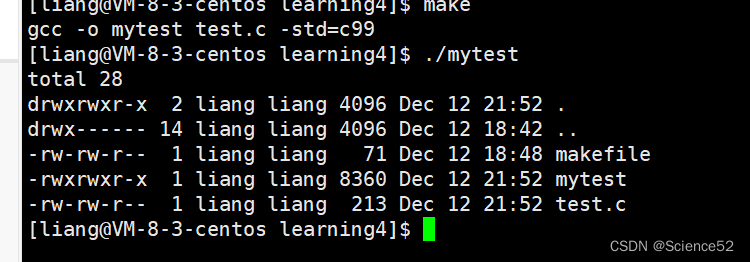
我们可以看到通过使用execlp的接口就可以帮我们完成程序替换,最后输出ls -a -l的结果。
其他几个接口也是大致这样的使用方式
execl:
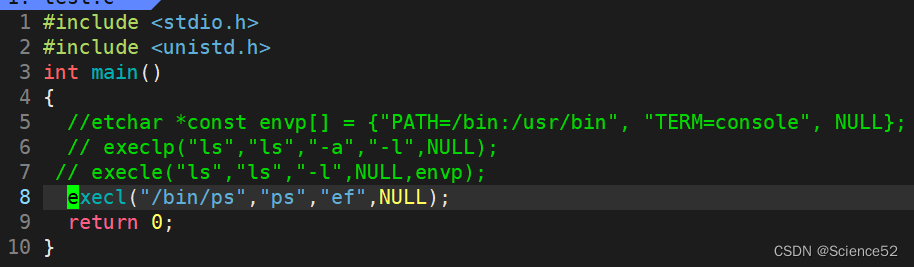

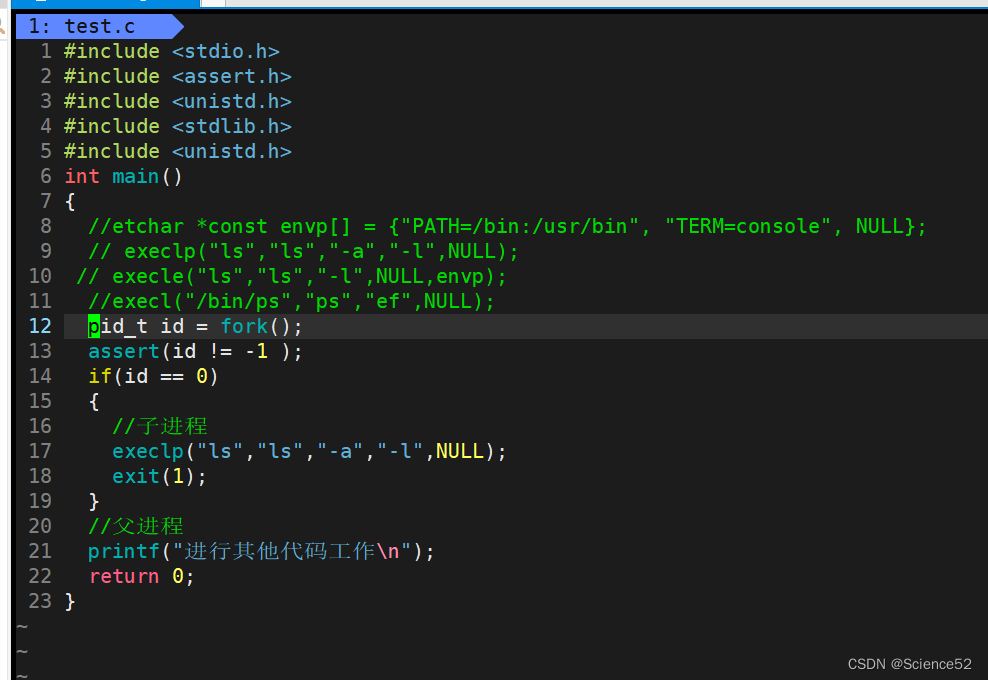
父子进程分别做着不同的事情:
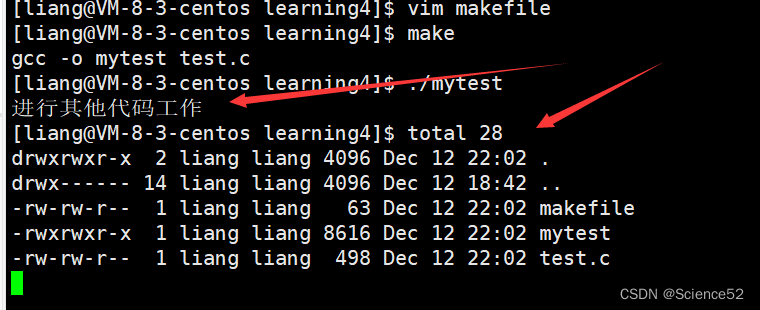
他们之间的关系:
做一个简易的shell
首先我们要明确思路:考虑到这个系统和用户的对话:
因此我们需要做到的这5个步骤:
1. 获取命令行2. 解析命令行3. 建立一个子进程(fork)4. 替换子进程(execvp)5. 父进程等待子进程退出(wait)我们可以通过画图的形式来确定我们大概了流程: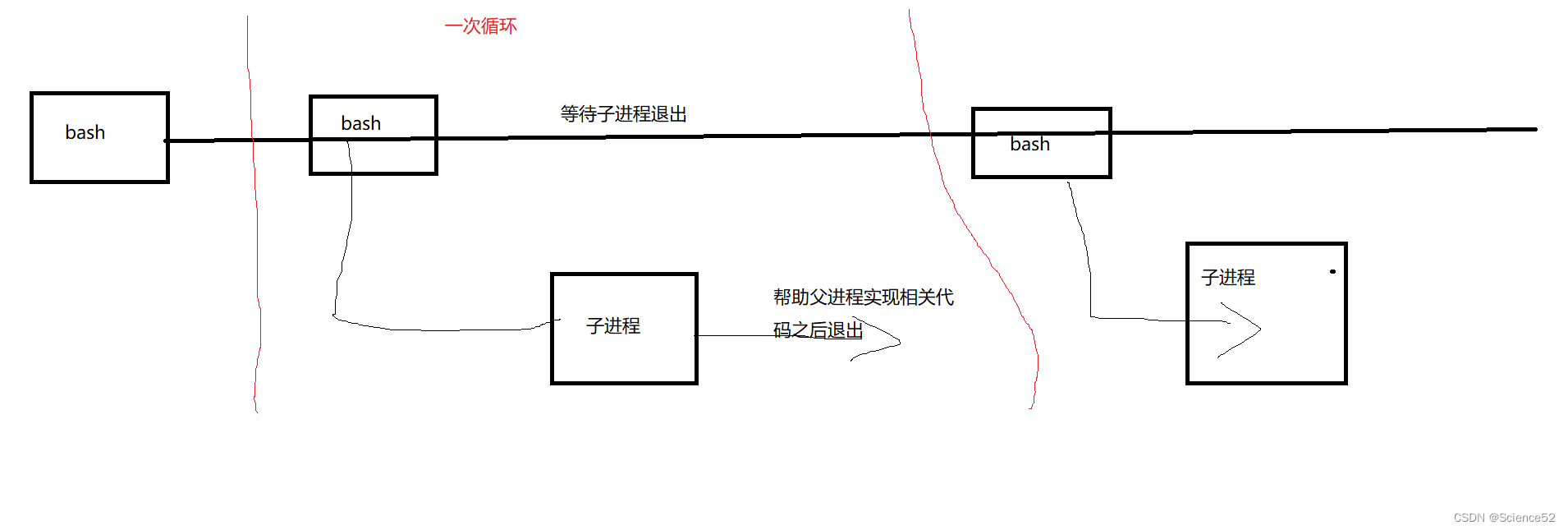
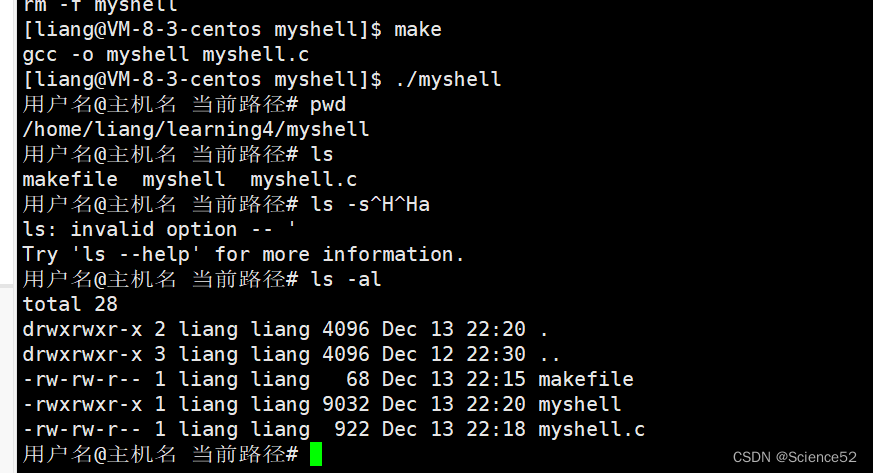
下面我们进行相关的代码实现:
看看结果:
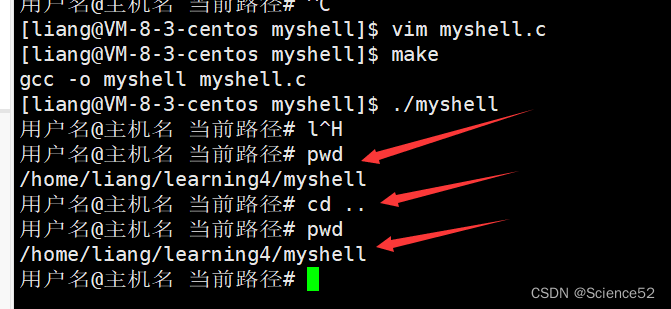
但是有一个问题:使用cd命令的时候就有点问题:
为什么会出现这个问题呢?就要说到我们的文件的相关的知识了,后面 我们下一节再来完善这个shell


















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









