







!!!!!!!!!
选题不知道怎么选 不清楚自己适合做哪块内容 都可以免费来问我 避免后期給自己答辩找麻烦 增加难度(部分学校只有一次答辩机会 没弄好就延迟毕业了)
会持续一直更新下去 有问必答 一键收藏关注不迷路
源码获取:https://pan.baidu.com/s/1aRpOv3f2sdtVYOogQjb8jg?pwd=jf1d 提取码: jf1d
!!!!!!!!!
项目介绍
随着互联网的快速发展和数字阅读习惯的普及,网络小说已经成为许多人获取娱乐和知识的重要途径之一。面对海量的网络小说资源,如何从中筛选出高质量的作品,以及如何更好地理解读者的兴趣偏好,成为了出版商、作者乃至读者自身都非常关注的问题。为了应对这一挑战,一个功能全面、用户友好的基于大数据平台的小说数据分析系统应运而生。
该系统旨在通过先进的数据挖掘技术和算法模型,为网络小说行业提供深度的内容分析、读者行为洞察以及作品推广策略等服务,帮助各方参与者做出更加科学合理的决策。具体来说,本项目的目标是解决传统网络小说分析中存在的数据碎片化、用户画像模糊等问题,满足行业内外对于高效、精准数据服务的需求。
核心功能模块:
- 个人账户管理:支持用户注册、登录和个人信息编辑;提供密码找回及账号安全保护措施,确保用户信息安全。
- 小说数据采集:从各大网络文学平台、社交媒体及其他公开来源自动抓取小说文本、评论、评分等多维度数据,形成丰富的内容数据库。
- 实时更新监测:跟踪热门小说的最新章节发布情况,以及读者反馈和互动数据,帮助作者和出版社及时调整创作方向或营销策略。
- 阅读趋势分析:基于大量用户的行为数据,分析不同类别小说的流行趋势,识别潜在的爆款题材,指导新作品的开发。
- 读者偏好建模:运用机器学习算法深入挖掘用户的阅读偏好,构建个性化推荐系统,提高用户粘性和满意度。
- 作品价值评估:结合内容质量、市场表现等多个维度对小说进行全面评价,为版权交易、IP开发等商业决策提供依据。
- 定制化报告生成:根据客户需求输出包含详细图表和分析结果的专业报告,适用于内部决策支持或对外合作洽谈。
- 社区互动交流:设立专门的讨论区,促进读者、作者及出版方之间的交流互动,共同探讨行业发展动向。
技术栈
1.运行环境:python3.7/python3.7
2.IDE环境:pycharm+mysql8.0;
3.数据库工具:Navicat15
技术栈
后端:python+django
前端:vue+CSS+JavaScript+jQuery+elementui
项目截图
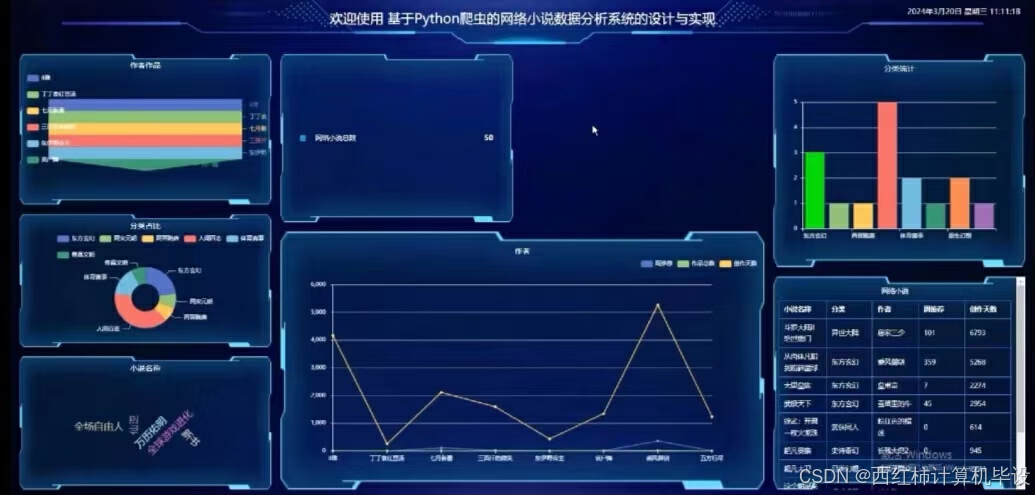
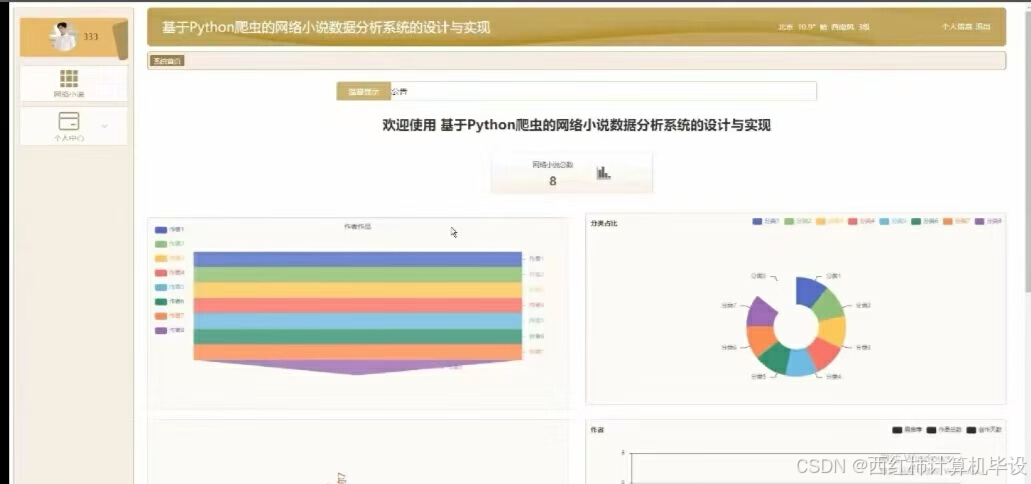
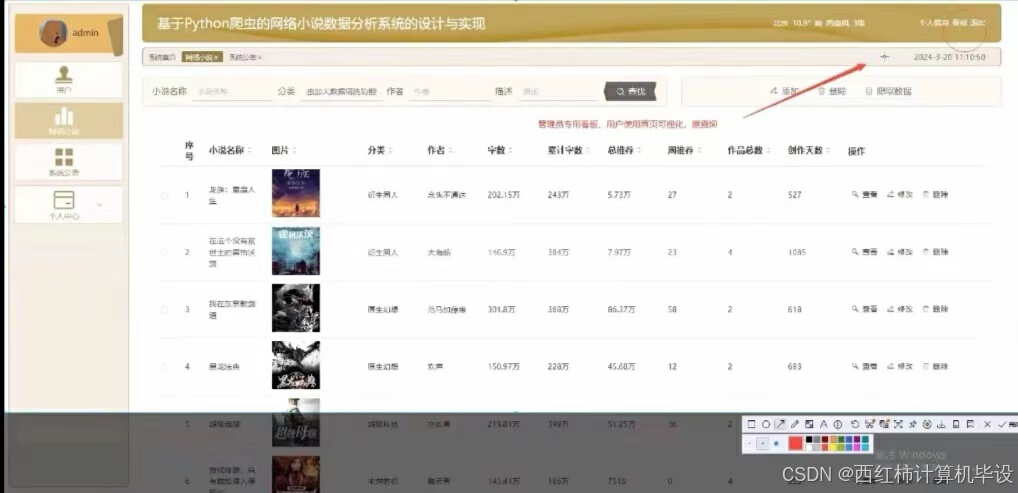
核心代码
# coding:utf-8
# author:ila
import click,py_compile,os
from configparser import ConfigParser
from configs import configs
from utils.mysqlinit import Create_Mysql
from api import create_app
from api.exts import db
from api.models.user_model import *
from api.models.config_model import *
from api.models.brush_model import *
@click.group()
def sub():
pass
@click.command()
@click.option("-v", default=0.1, type=float)
def verr(v):
# VERSION = 0.1
click.echo("py sub system version:{}".format(v))
@click.command()
def run():
app = create_app(configs)
app.debug = configs['defaultConfig'].DEBUG
app.run(
host=configs['defaultConfig'].HOST,
port=configs['defaultConfig'].PORT,
threaded=configs['defaultConfig'].threaded,
processes=configs['defaultConfig'].processes
)
@click.command()
def create_all():
app = create_app(configs)
with app.app_context():
print("creat_all")
db.create_all()
@click.command()
@click.option("--ini", type=str)
def initsql(ini):
cp = ConfigParser()
cp.read(ini)
sqltype = cp.get("sql", "type")
database= cp.get("sql", "db")
if sqltype == 'mysql':
cm = Create_Mysql(ini)
cm.create_db("CREATE DATABASE IF NOT EXISTS `{}` /*!40100 DEFAULT CHARACTER SET utf8 */ ;".format(database))
with open("./db/mysql.sql", encoding="utf8") as f:
createsql = f.read()
createsql = "DROP TABLE" + createsql.split('DROP TABLE', 1)[-1]
cm.create_tables(createsql.split(';')[:-1])
cm.conn_close()
elif sqltype == 'mssql':
cm = Create_Mysql(ini)
cm.create_db("CREATE DATABASE IF NOT EXISTS `{}` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;".format(database))
with open("./db/mssql.sql", encoding="utf8") as f:
createsql = f.read()
createsql = "DROP TABLE" + createsql.split('DROP TABLE', 1)[-1]
cm.create_tables(createsql.split(';')[:-1])
cm.conn_close()
else:
print('请修改当前面目录下的config.ini文件')
@click.command()
@click.option("--py_path", type=str)
def compile(py_path):
print("py_path====>",py_path)
py_compile.compile(py_path)
@click.command()
def replace_admin():
filePath=os.path.join(os.getcwd(),"api/templates/front/index.html")
if os.path.isfile(filePath):
print(filePath)
with open(filePath,"r",encoding="utf-8") as f:
datas=f.read()
datas=datas.replace('baseurl+"admin/dist/index.html#"','"http://localhost:8080/admin"')
datas=datas.replace('baseurl+"admin/dist/index.html#/login"','"http://localhost:8080/admin"')
with open(filePath,"w",encoding="utf-8") as f:
f.write(datas)
sub.add_command(verr)
sub.add_command(run,"run")
sub.add_command(create_all,"create_all")
sub.add_command(initsql,"initsql")
sub.add_command(replace_admin,"replace_admin")
if __name__ == "__main__":
sub()
获取源码
!!!!!!!!!
源码获取:https://pan.baidu.com/s/1aRpOv3f2sdtVYOogQjb8jg?pwd=jf1d 提取码: jf1d
!!!!!!!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









