







jvm的垃圾回收是针对于堆内存的。
一、
1、程序计数器
程序计数器相当于给这个对象定一个计数器,当这个对象有被其他对象或者变量调用的时候,这个程序计数器就会加一,计数器数字为0的对象默认当成垃圾处理。当然,这样做是有缺点的。比如说,两个对象相互调用的时候,但是这两个对象已经被我们抛弃了,jvm也不会把他们当作垃圾处理掉,所以才有了后面的可达性分析这一说。
2、可达性分析
可达性分析,从根节点出发,指向被调用的对象或者变量,直到最后一个。如果说,某个对象,并没有从根节点出发所被指向,说明他会被视为垃圾处理。这样就很好的解决了程序计数器的弊端。
二、垃圾回收的四种方式
1、碎片标记法
可以通过对这些垃圾对象进行标记,针对于这些被标记的对象做回收处理。但是这种做法会造成大量的空间碎片,性能不高。
2、复制算法
当内存空间不足的时候,会额外开辟一个空间,是原来空间的两倍,把不是垃圾对象放在右边,左边做清除释放。这样做也有弊端,就是我可能只需要几个新空间,但是给我开了原空间一倍的空间,造成了不必要的浪费。
3、碎片整理法
就是在碎片标记法的基础上,做了整理的操作,这样可以使空间碎片很好的被利用,但是,这里的搬运内存的开销很大。
4、分代回收
依据不同种类的对象,采取不同的方式
引入概念:对象的年龄
- JVM 中,有专门的线程负责周期性扫描/释放
- 一个对象如果被线程扫描了一次,可达了(不是垃圾),年龄就+1(初始年龄相当于是 0)
JVM 中就会跟对象年龄的差异,把整个堆内存分为两个大的部分:新生代(年龄小的对象)/老年代(年龄大的对象)
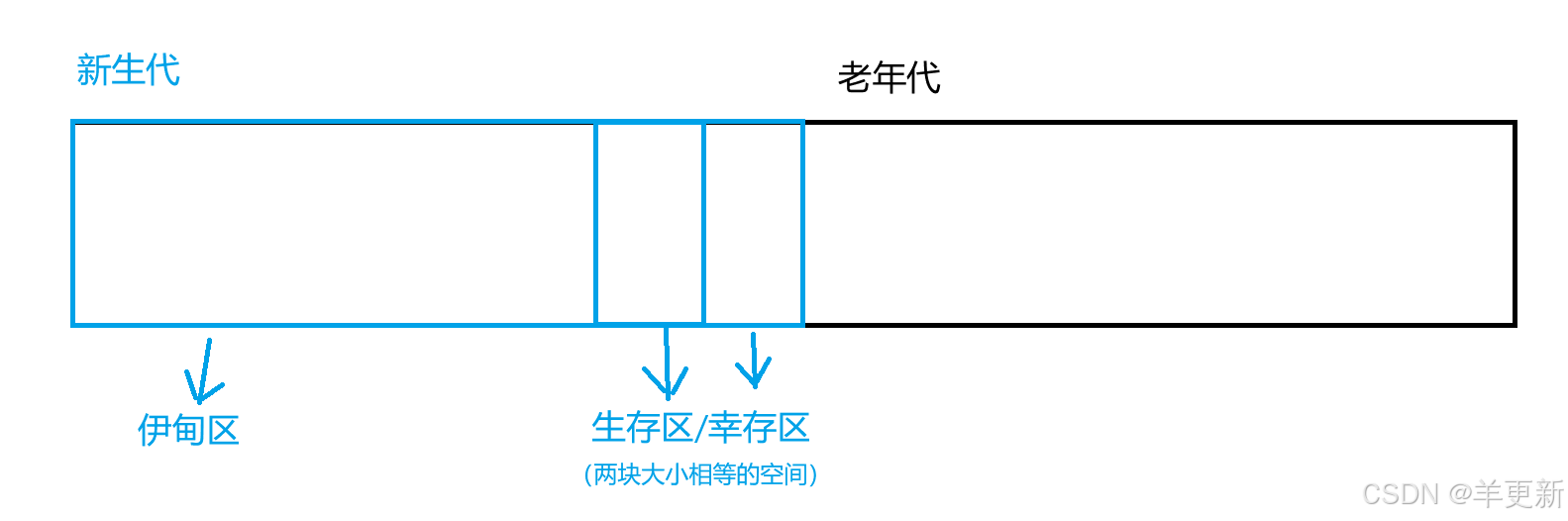
三、
回收器都有哪些呢,
早期的serial,serial old:这些是处理单线程的——>stw——>
中期的Parallel Scavenge Parallel old这些是处理多线程的
过渡期的Par new 还有cms,Parnew就是对Parallel Scavenge做了一次改装 主要是为了适配cms
也是多线程进行回收,但是因为是多线程,可能标记的会遗漏,所以会再次做一次标记,再并发清除垃圾。
最后就是G1 还有 ZGC了,G1可以控制stw的时间,采取了2048块分区处理垃圾,分为伊甸区、幸存者区、老年区。
- 并行与并发,G1 能充分利用多 CPU、多核环境下的硬件优势,使用多个 CPU 来缩短 Stop-The-World 停顿的时间,部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 Java 程序继续执行。
- 分代收集,G1 依然是一个分代收集器,但是它可以独立管理整个堆(包括新生代和老年代),而不需要与其他收集器搭配。
- 空间整合,G1 从整体来看是基于 “标记 - 整理” 算法实现的收集器,从局部(两个 Region 之间)上来看是基于 “复制” 算法实现的,但无论如何,都不会产生内存碎片。
- 可预测的停顿,G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









