



转载自知乎
1. 先定义归一化函数
默认是将正向指标归一化到 [0,1] :
## 定义归一化函数
rescale = function(x, type = "pos", a = 0, b = 1) {
rng = range(x, na.rm = TRUE)
switch (type,
"pos" = (b - a) * (x - rng[1]) / (rng[2] - rng[1]) + a,
"neg" = (b - a) * (rng[2] - x) / (rng[2] - rng[1]) + a)
}测试函数:
x = c(1, 2, 3, NA, 5)
rescale(x)
rescale(x, type = "neg")![]()
![]()
2. 定义熵权法赋权函数
因为熵权法归一化值不能出现 0 或 1,所以在做归一化时多往内收缩一下到 [0.002, 0.996], 需要的话可自行修改。
Entropy_Weight = function(X, index = NULL) {
# 实现用熵权法计算各指标(列)的权重及各数据行的得分
# X为原始指标数据, 一行代表一个样本, 每列对应一个指标
# index指示各指标列的正负向, "pos"表示正向, "neg"表示负向, 默认都是正向指标
# s返回各行(样本)得分,w返回各列权重
if(is.null(index)) index = rep("pos", ncol(X))
pos = which(index == "pos")
neg = which(index == "neg")
# 数据归一化
X[,pos] = lapply(X[,pos, drop = FALSE], rescale, a = 0.002, b = 0.996)
X[,neg] = lapply(X[,neg, drop = FALSE], rescale, type = "neg", a = 0.002, b = 0.996)
# 计算第j个指标下,第i个样本占该指标的比重p(i,j)
P = data.frame(lapply(X, \(x) x / sum(x)))
# 计算第j个指标的熵值e(j)
e = sapply(P, \(x) sum(x * log(x)) *(-1/log(nrow(P))))
d = 1 - e # 计算信息熵冗余度
w = d / sum(d) # 计算权重向量
# 计算样本得分
s = as.vector(100 * as.matrix(X) %*% w)
list(w = w, s = s)
}测试函数:
仍使用上一篇文章同样的数据:shang_datas.xlsx, 为 2014 年 31 个省份的就业与劳动保障数据, 包含 5 个指标:社会养老保险参保率、医疗保险参保率、失业保险参保率、工伤保险参保率、工伤事故发生率, 其中第 5 个指标为负向指标。
library(readxl)
data = read_xlsx("datas/shang_datas.xlsx")
X = data[, 2:6]
ind = c(rep("pos",4), "neg")
Entropy_Weight(X, ind)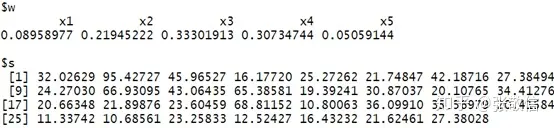
结果与上篇文章也完全一样。


















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











