






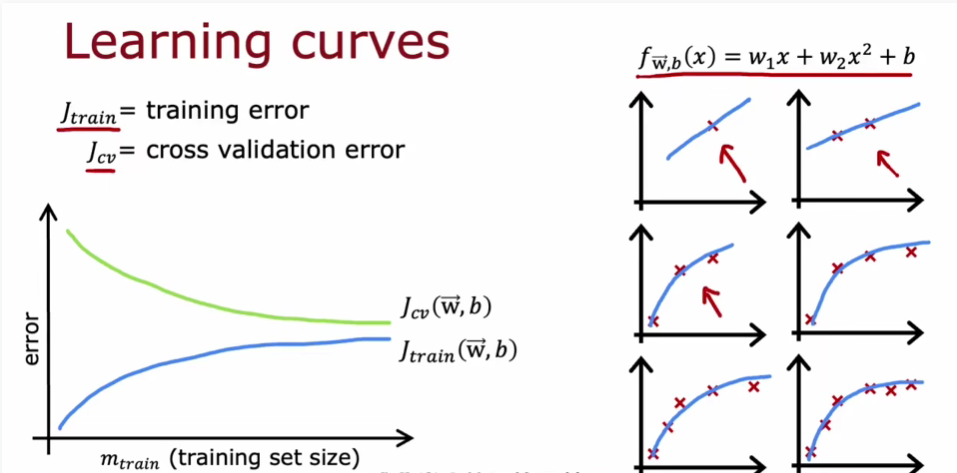
当我们在建立一个模型时,我们如何来判断模型的好与坏呢?此时我们就要运用一些模型评估方法。其中大致可以分为回归和分类两大块,回归模型可以运用一些比较常见的如MSE(均方误差)、MAE(平均绝对误差)RMSE(均方根误差),分类问题最常见的就是混淆矩阵。下图是学习曲线,随着训练集数据的增多,训练误差会逐渐变大,验证误差会逐渐变小。由左半部分可以观察出来,此处不过多讲述。
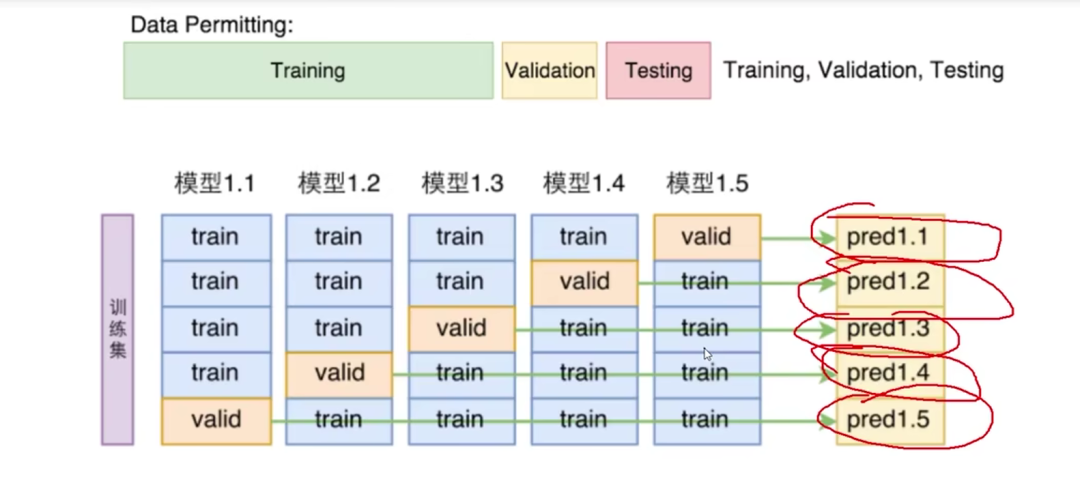
交叉验证
交叉验证可以很好的评估模型性能,通过将一个数据集拆分为三部分,分别为训练集、验证集、测试集,其中训练集就相当于高中练习册,不断去学习,验证集就相当于月考中考,看看我们之前学习的怎么样,也就是模型训练的怎么样,测试集就相当于高考了,真正来测验我们模型的性能。
其中k折交叉验证在模型评估中使用的最多,k折交叉验证就是将数据平均分为k份,使k份中的每一份都作为一次验证集,剩下的k-1份作为训练集,这样我们就有k个验证评估分数,然后取其平均值最为最后模型评估分数。
下面就是交叉验证代码案列,是我在训练一个GBDT分类器时用到的,GBDT是集成学习中的一个算法,后续我还会写,代码就不一行行说明了,就大致说一下cross_val_score中的参数,第一个gbt就是我们实例化的模型,然后x_train,y_train,cv就是我们要将数据集其分为几份,默认我记得是三份,scoring就是选择什么评估指标,我这里用的是ROC曲线,下面会说。
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
acc_cross=[]
for gbt in range(1,30):
gbt = GradientBoostingClassifier(max_depth=5,
n_estimators=gbt,
learning_rate=0.1,
random_state=42
)
#gbt.fit(x_train, y_train)
scores = cross_val_score(gbt, x_train, y_train, cv = 5,scoring='roc_auc')
gbt_cross =scores.mean()
acc_cross.append(gbt_cross)
#print(gbt_cross)混淆矩阵
混淆矩阵是分类问题中最常见的一种评估方法,我就拿MNIST(手写字体)数据集来解释。由于MNIST数据集是多分类问题,所以这里为了简单,我简化了成了一个二分类问题,判断是否为5。TN(true negative)负类的并且模型判断正确,就是不为5的数模型判断也不是5;TP(true positive)正类的并且模型判断正确,就是5的数模型也判断是5;FP(false positive)正类的但模型判断错误,就是是5 但是模型判断不是5,FN(false negitive)负类的模型判断错误,就是一些不是5的数模型判断是5。
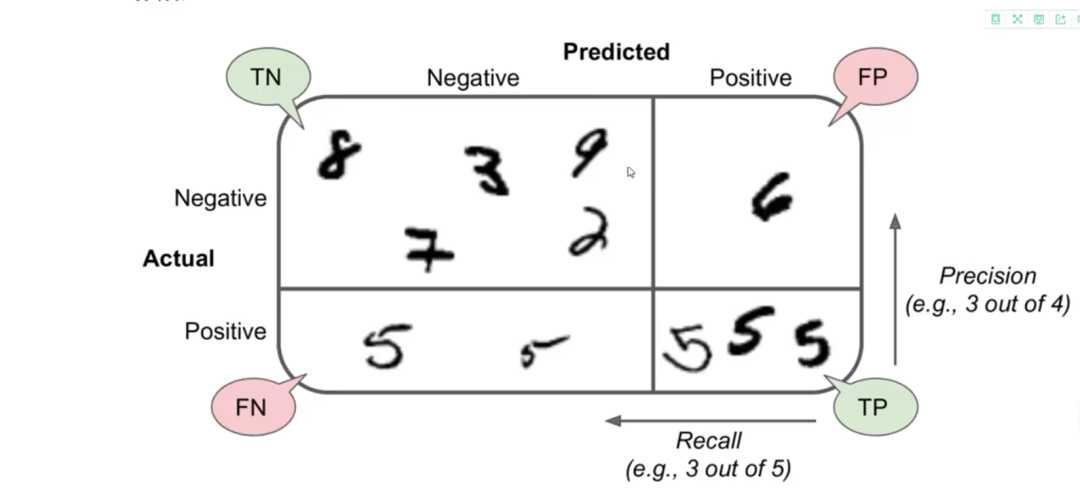
准确率(accuracy)
Accuracy = (TP+TN)/(TP+FN+FP+TN),即预测正确的数占样本总数的比例,即正确预测的正反例数 /总数。不要把准确率与精确度混为一谈,他们是两个不同的概念。
精确度(precision)
Precision = TP/(TP+FP) ,即正确预测的正例数 /预测正例总数
召回率(recall)
Recall = TP/(TP+FN),即正确预测的正例数 /实际正例总数
F1_score分数
F1分数主要用于评估模型的稳健性,Precision和Recall是一对矛盾的度量,一般来说,Precision高时,Recall值往往偏低;而Precision值低时,Recall值往往偏高。当分类置信度高时,Precision偏高;分类置信度低时,Recall偏高。为了能够综合考虑这两个指标,F1_score分数被提出(Precision和Recall的加权调和平均),很多推荐系统的评测指标就是用F值的。

from sklearn.metrics import precision_score,recall_score,f1_score
precision_score(y_true,y_pred)
recall_score(y_true,y_pred)
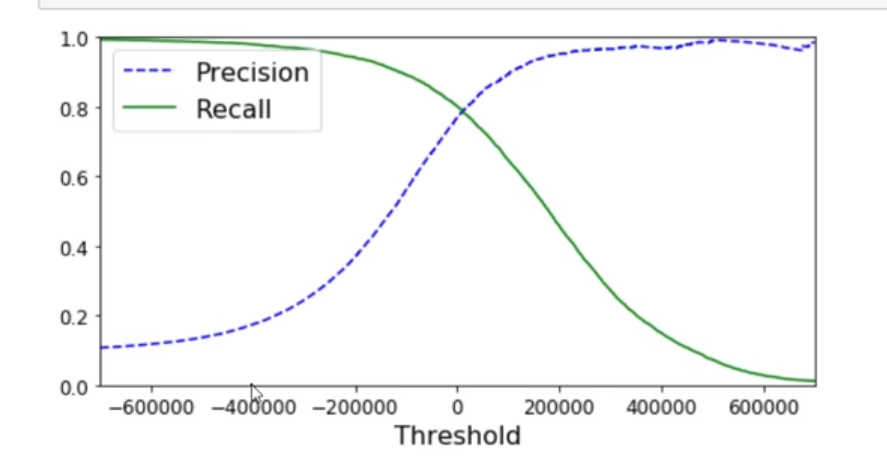
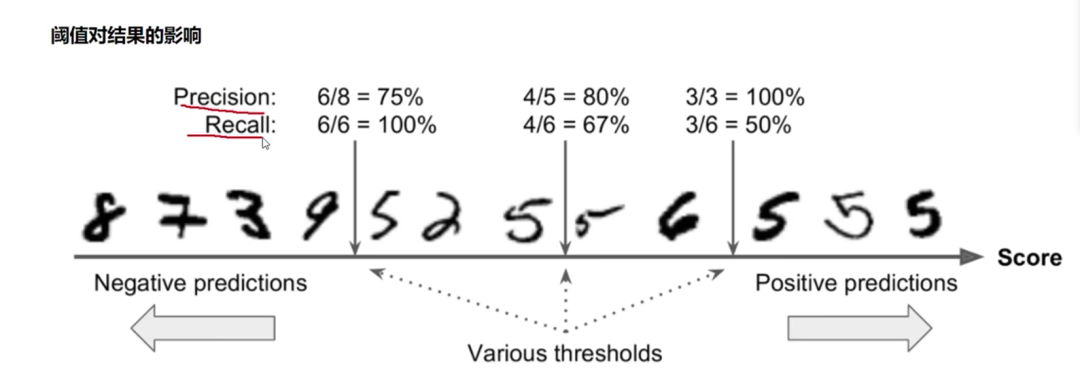
f1_score(y_true,y_pred)阈值对结果的影响
了解即可,此处不详细说明。
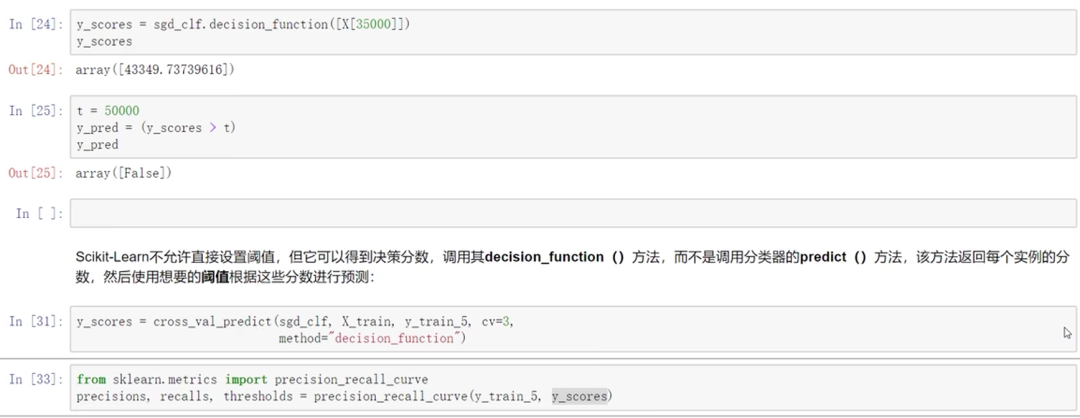
ROC曲线
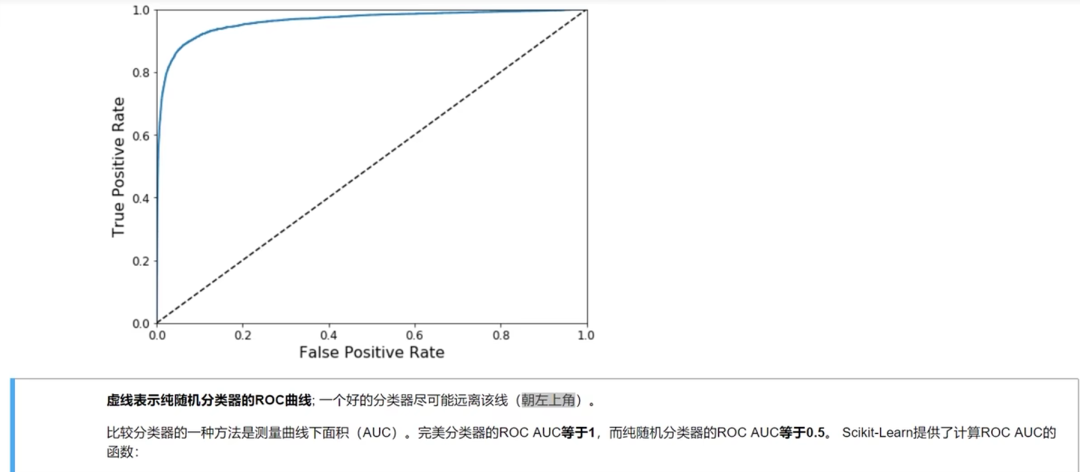
roc曲线是二分类中最常用的评估方法,曲线越接近左上角,表示模型效果越好。
AUC 是 Area Under Curve 的简称,顾名思义,它表示的是“曲线下的面积”。这里的“曲线”就是我们前面提到的 ROC 曲线。AUC 就是 ROC 曲线下的面积总和,该值能够量化反映分类算法的性能。计算 AUC 的值并不复杂,只需要沿着 ROC 曲线的横轴做积分(或累加求和)即可。通常,ROC 曲线都位于 y=x 这条线的上方(如果不是这样的,只需要把模型预测概率 P 反转成 1-P 能得到一个更好的分类器)。因此,AUC 的取值范围一般是 0.5~1。通常来说,AUC 越大表明分类器性能越好,因为它可以把真正的正类样本排在前面,降低误判率。
同时ROC曲线还特别适合我们样本点分类不均的适合衡量分类器的效能。

from sklearn.metrics import roc_auc_score
roc_auc_score()
















 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









