






一、损失函数的概念
损失函数(loss function)是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y | f(x))来表示,损失函数越小,模型的性能就越好。
简单的理解就是每一个样本经过模型后会得到一个预测值,得到的预测值和真实值的差值就称为损失,损失越小,说明预测值越接近真实值。
损失函数的使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新模型的参数(也就是各个卷积核里的数值),来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
二、常用的损失函数
1. 基于距离度量的损失函数
基于距离度量的损失函数通常将输入数据映射到基于距离度量的特征空间上,如欧氏空间、汉明空间等,将映射后的样本看作空间上的点,采用合适的损失函数度量特征空间上样本真实值和模型预测值之间的距离。特征空间上两个点的距离越小,模型的预测性能越好。
-
均方误差损失函数(MSE)
均方误差损失函数用于度量样本点到回归曲线的距离,通过最小化平方损失使样本点可以更好地拟合回归曲线。均方误差损失函数(MSE)的值越小,表示预测模型描述的样本数据具有越好的精确度。由于无参数、计算成本低和具有明确物理意义等优点,MSE已成为一种优秀的距离度量方法。尽管MSE在图像和语音处理方面表现较弱,但它仍是评价信号质量的标准,在回归问题中,MSE常被作为模型的经验损失或算法的性能指标。
公式如下:
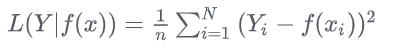
-
L1损失函数
L1损失又称为曼哈顿距离,表示残差的绝对值之和。L1损失函数对离群点有很好的鲁棒性,但它在残差为零处却不可导。另一个缺点是更新的梯度始终相同,也就是说,即使很小的损失值,梯度也很大,这样不利于模型的收敛。针对它的收敛问题,一般的解决办法是在优化算法中使用变化的学习率,在损失接近最小值时降低学习率。
公式如下:
![]()
-
L2损失函数
L2损失又被称为欧氏距离,是一种常用的距离度量方法,通常用于度量数据点之间的相似度。它是回归问题、模式识别、图像处理中最常使用的损失函数。
公式如下:
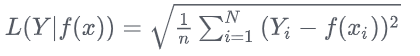
2. 基于概率分布度量的损失函数
基于概率分布度量的损失函数是将样本间的相似性转化为随机事件出现的可能性,即通过度量样本的真实分布与它估计的分布之间的距离,判断两者的相似度,一般用于涉及概率分布或预测类别出现的概率的应用问题中,在分类问题中尤为常用。
-
交叉熵损失函数
交叉熵是信息论中的一个概念,最初用于估算平均编码长度,引入机器学习后,用于评估当前训练得到的概率分布与真实分布的差异情况。为了使神经网络的每一层输出从线性组合转为非线性逼近,以提高模型的预测精度,在以交叉熵为损失函数的神经网络模型中一般选用sigmoid、softmax或ReLU作为激活函数。
交叉熵损失函数刻画了实际输出概率与期望输出概率之间的相似度,也就是交叉熵的值越小,两个概率分布就越接近,特别是在正负样本不均衡的分类问题中,常用交叉熵作为损失函数。目前,交叉熵损失函数是卷积神经网络中最常使用的分类损失函数,它可以有效避免梯度消散。在二分类情况下也叫做对数损失函数。
公式如下:
![]()
-
softmax损失函数
从标准形式上看,softmax损失函数应归到对数损失的范畴,在监督学习中,由于它被广泛使用,所以单独形成一个类别。softmax损失函数本质上是逻辑回归模型在多分类任务上的一种延伸,常作为CNN模型的损失函数。softmax损失函数的本质是将一个k维的任意实数向量x映射成另一个k维的实数向量,其中,输出向量中的每个元素的取值范围都是(0,1),即softmax损失函数输出每个类别的预测概率。由于softmax损失函数具有类间可分性,被广泛用于分类、分割、人脸识别、图像自动标注和人脸验证等问题中,其特点是类间距离的优化效果非常好,但类内距离的优化效果比较差。
softmax损失函数具有类间可分性,在多分类和图像标注问题中,常用它解决特征分离问题。在基于卷积神经网络的分类问题中,一般使用softmax损失函数作为损失函数,但是softmax损失函数学习到的特征不具有足够的区分性,因此它常与对比损失或中心损失组合使用,以增强区分能力。
公式如下:
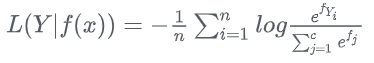
三、softmax激活函数,softmax损失函数,交叉熵损失函数的区别
神经网络的输出通常称为logit,也就是全连接层输出的结果,其范围是不确定的,处于负无穷至正无穷之间。而softmax激活函数恰好可以将这样的输出转换为0到1之间。将logit用softmax转换为概率值就可以用来计算交叉熵。
交叉熵是损失函数,softmax损失函数是使用了softmax激活函数的交叉熵损失。
参考来源:
损失函数(lossfunction)的全面介绍(简单易懂版)-优快云博客
深度学习之常见损失函数(详细讲解定义、数学公式、实现代码)_基于距离度量的损失函数-优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









